Tomato yellow leaf distortion virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000896215.1 |
| Isolate | Cuba |
| Release date | 2015/2/22 |
| Submitter | Fiallo-Olive,E., Martinez-Zubiaur,Y., Rivera-Bustamante,R.F., Hernandez-Zepeda,C., Trejo-Saavedra,D., Carrillo-Trip,J., Rivera-Bustamante,R. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
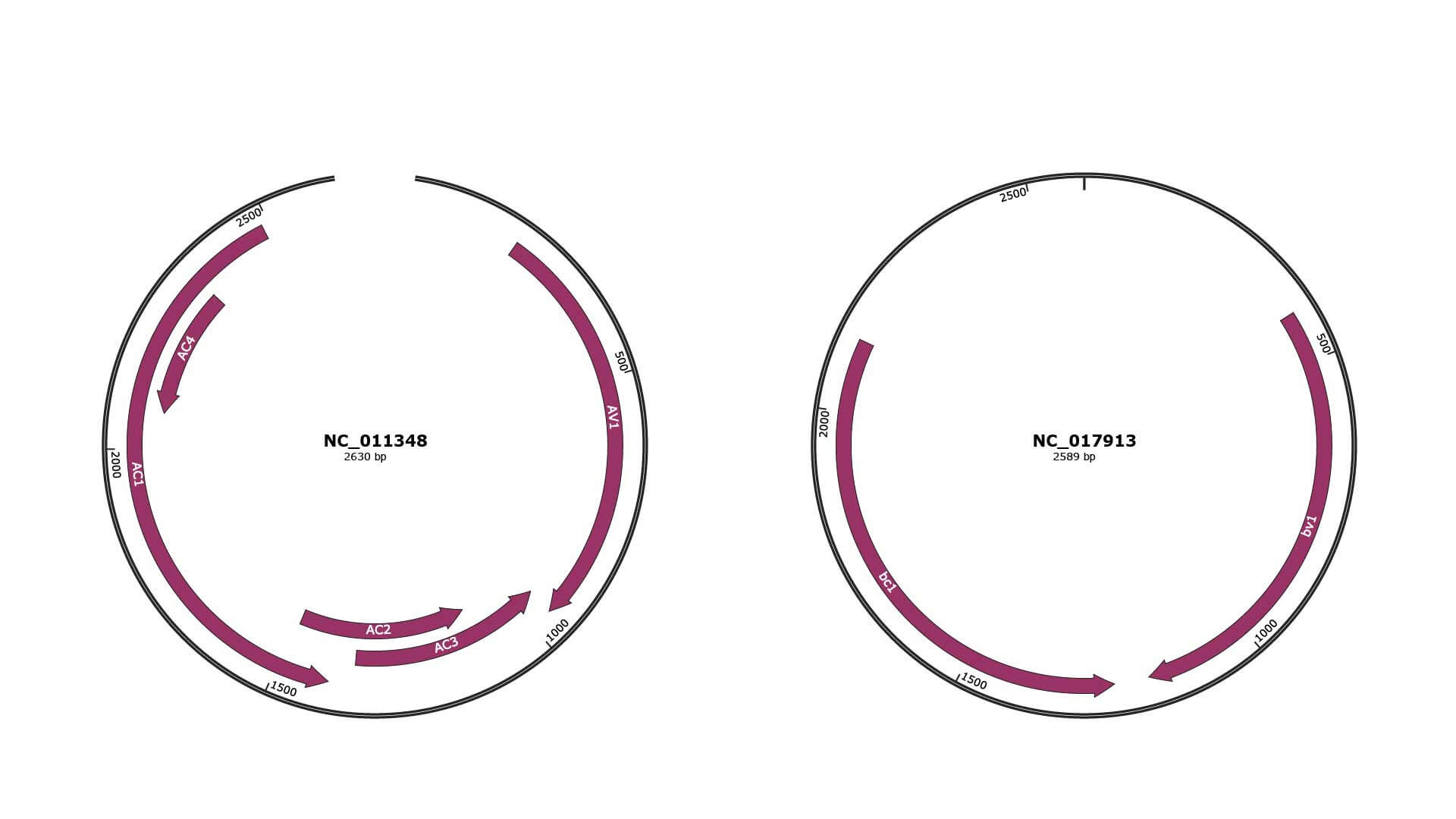
JBrowse
Genome
NC_011348
NC_017913
Gene Information
| NCBI Accession | YP_002268202.1 |
|---|---|
| Location | 204-959 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATCTTCCATGGCGCTCGATCGCGGGAACGTCAAAGGTGAGCCGCAATGCGAATTACTCACCACGTGGCGGTATGGGCCCAAAATTCAACAAGGCCCAGGCTTGGGTTGATCGGCCTATGTTCAAGAAGCCCAGGATATATCGGACTTTGACCAGTCCAGATGTGCCACGAGGCTGTGAAGGGCCTTGTAAGATCCAGTCGTTTGAGCAAAGGCATGACATCTCTCATGTCGGTAAGGTCATGTGTATATCCGATGTCACACGTGGCAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGTTAAGGTATGGATGGATGAGAACATCAAGCTCAAGAATCACACGAACAGTGTGATGTTCTGGTTGGTCCGAGACCGTCGACCGTATGGTACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGACAACGAGCCTAGTACAGCCACGGTTAAGAACGATCTGCGTGATCGTTTCCAGGTATTGCACAAGTTCTACTCGAAGGTGACAGGTGGACAGTATGCCAGTAATGAACAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAATACTCGTGTCGTCTACAACCACCAGGAAGCCGCTAAGTACGAGAATCATACGGAGAACGCCCTGTTATTGTACATGGCATGTACTCATGCCTCTAACCCCGTGTATGCAACCTTGAAGATTCGGATCTATTTTTACGATTCGATCATGAATTAA |
| Protein Sequence | MPKRDLPWRSIAGTSKVSRNANYSPRGGMGPKFNKAQAWVDRPMFKKPRIYRTLTSPDVPRGCEGPCKIQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILVKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVLHKFYSKVTGGQYASNEQALVKRFWKVNTRVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_002268203.1 |
|---|---|
| Location | 956-1354 |
| Gene Name | AC3 |
| Protein Name | replication enhancement protein |
| Coding Region | ATGGATTCACGCACCGGGGAACTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATACCTGGGAGATAGAAAATCCCCTGTATTTCAAGATGTACAGGGTAGAGGATCCGTTGTACACCAGGACAAGGGTCTACCATATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGAAAGCTTCTGGGTCAACTTATTTAATTAGGTTTAGACATTTAGTTAACATGTACTTAGATCAGTTAGGCGTGATTTGCATAAACAATGTAATCAGAGCTGTTCGATTCGCGACAGACAGATCGTATGTGAGTCATGTACTGGAAAATCATTCAATAAAATTTAAATTTTATTAA |
| Protein Sequence | MDSRTGELITARQAENGVYTWEIENPLYFKMYRVEDPLYTRTRVYHIQIRFNHNLRRALHLHKAYLNFQVWTTSMKASGSTYLIRFRHLVNMYLDQLGVICINNVIRAVRFATDRSYVSHVLENHSIKFKFY |
| NCBI Accession | YP_002268204.1 |
|---|---|
| Location | 1101-1490 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCGATCTTCATCACCCTCACATCCGCCCTCTATCAAGAAGGCACACAGGCAGGCCAAGAAGAGGGCGATCAGGAGGAGGCGGATTGATCTGGAGTGCGGTTGCTCCATCTACTTCCACATAGGCTGCACGGGACATGGATTCACGCACCGGGGAACTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATACCTGGGAGATAGAAAATCCCCTGTATTTCAAGATGTACAGGGTAGAGGATCCGTTGTACACCAGGACAAGGGTCTACCATATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGAAAGCTTCTGGGTCAACTTATTTAATTAG |
| Protein Sequence | MRSSSPSHPPSIKKAHRQAKKRAIRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPVFQDVQGRGSVVHQDKGLPYPDTVQPQPEESVASPQSLPELPSLDDIDESFWVNLFN |
| NCBI Accession | YP_002268205.1 |
|---|---|
| Location | 1402-2487 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCATCGGTTAAGCGTTTCAAAGTCTCAGCCAAAAACTATTTCCTCACTTATCCACAGTGCTCTCTGACAAAAGAAGAGGCACTTTCCCAATTACAAAACCTTGAAACACCAGTTAACAAGAAGTTCATCAAAATCTGCAGAGAGCTTCATGAGAATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGAAAATACCAATGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGCAAGCAGTCTGCTAATGATTCATATGCCAAGGCGTTAAATGCAGATTCTGTTCAATCTGCCATGGCGGTTTTAAGGGAAGAACAGCCAAAAGATTTCGTCTTGCAGAATCATAACATCCGCTCCAATCTAGAGAGGATATTCAAAAAGGCTCCGGAACCGTGGGTTCCTCCGTTTCAACTCTCGTCCTTCACTAACGTTCCCGATGAGATGCAGGAGTGGGCGGATGATTATTTTGGAAGAGGTTCCGCTGCGCGGCCACAGAGACCATTGAGTATCATCGTAGAAGGTGATTCAAGGACAGGGAAGACCATGTGGGCTCGTGCGTTAGGCCCACATAATTATCTAAGTGGACACCTGGACTTCAATGGTCGAGTCTTTTCGAATGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGATCGGGGCCCAAAAAGACTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGTGGAATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCTAGCTATAAAGCTTTCCTGGACAAAGAGGAAAACGCATCTCTCAGGAACTGGACTGTCAAGAATGCGATCTTCATCACCCTCACATCCGCCCTCTATCAAGAAGGCACACAGGCAGGCCAAGAAGAGGGCGATCAGGAGGAGGCGGATTGA |
| Protein Sequence | MPSVKRFKVSAKNYFLTYPQCSLTKEEALSQLQNLETPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGKQSANDSYAKALNADSVQSAMAVLREEQPKDFVLQNHNIRSNLERIFKKAPEPWVPPFQLSSFTNVPDEMQEWADDYFGRGSAARPQRPLSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVFSNEVEYNVIDDVAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKAFLDKEENASLRNWTVKNAIFITLTSALYQEGTQAGQEEGDQEEAD |
| NCBI Accession | YP_002268206.1 |
|---|---|
| Location | 2073-2336 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAGAATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGAAAATACCAATGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGCAAGCAGTCTGCTAATGATTCATATGCCAAGGCGTTAA |
| Protein Sequence | MRMGSLISMCSYSSKENTNARITDSSIWSPQPGQHISIRTYRELNPAPTSSPTSTRTEIHWNGENSRSTADLLEEASSLLMIHMPRR |
| NCBI Accession | YP_006331058.1 |
|---|---|
| Location | 415-1182 |
| Gene Name | bv1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATCCTTTGAGAAGTAAACGTGGTTCATTTTTTACGCCACGTCGTTTTTATCCACGTAACACTGTCCTCAAGCGTTCAACCTCGTCGAAGAGACATGACTCGAAACGTCGACTTGTTAATTCCAACAAGCCCAGTGATGAGCCCAAGATGTCAGTCCAACGCATTCATGAGAATCAGTATGGGCCAGATTTCTCTATGGCCCATAATTCAGCTGTCTCGACGTATGTCAGTTATCCTAGCCTGGGAAAGTCCGAACCCAACCGAAGCAGGTCCTATATTAAGTTGAAACAGCTACGTTTCAAAGGGACTGTGAAGATTGAACGTGTTCAGACGGACCTGAACATGGACGGTTCTACCCCCAAGTTGAAGAGTCTTCTCCATGTGATTGTTGTGGATCGCAAACCCCACTTGGGTCCTTCTGGATGTCTACATACGTTTGACGAGCTATTCGGTGCTAGGATCCACAGTCATGGTAACCTCAGCGTTACCCCTTCCTTGAAAGATCGTTATTACATCCGCCACGTGTGCAAACGTGTATTATCTGTCGAGAAGGATACGCTTATGGTAGACGTGGAAGGATCTATTTCACTCTCTAACAGGCGTTTTAGTTGTTGGTCTACGTTTAAGGATCTTGATCGTGATTCGTGCAAGGGTGTTTATGATAATATAAGCAAGAACGCCCTACTAGTTTATTACTGCTGGATGTCCGATACGCCTTCAAAGGCATCGACATTTGTATCATTTGATCTTGATTACGTTGGTTAA |
| Protein Sequence | MYPLRSKRGSFFTPRRFYPRNTVLKRSTSSKRHDSKRRLVNSNKPSDEPKMSVQRIHENQYGPDFSMAHNSAVSTYVSYPSLGKSEPNRSRSYIKLKQLRFKGTVKIERVQTDLNMDGSTPKLKSLLHVIVVDRKPHLGPSGCLHTFDELFGARIHSHGNLSVTPSLKDRYYIRHVCKRVLSVEKDTLMVDVEGSISLSNRRFSCWSTFKDLDRDSCKGVYDNISKNALLVYYCWMSDTPSKASTFVSFDLDYVG |
| NCBI Accession | YP_006331059.1 |
|---|---|
| Location | 1243-2124 |
| Gene Name | bc1 |
| Protein Name | movement protein |
| Coding Region | ATGGAGTCTCAGTTAGCTAATCCTCCGAACGCTTTCAACTACATAGAGTCACACCGTGACGAGTACCAGCTTTCCCATGACTTAACTGAGATCGTACTGCAATTTCCGTCGACGGCGTCTCAGTTGACAGCTAGACTCAGTCGTAGCTGCATGAAGATCGATCACTGCGTCATAGAGTACAGGCAACAAGTGCCGATTAACGCAACCGGGTCGGTAATTGTGGAGATCCACGACAAGAGGATGACAGACAACGAGTCATTACAGGCGTCGTGGACCTTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCCTTGAAAGACCCAATTCCATGGAAGTTGTACTACAGGGTTTCCGATACGAATGTTCATCAGAGGACCCACTTCGCCAAGTTCAAAGGGAAACTGAAACTATCAACGGCGAAGCATTCCGTCGACATCCCATTCCGAGCACCGACAGTAAAGATCCTGTCGAAACAGTTCACCGATAAAGATGTGGACTTCAACCATGTCGACTACGGGAAATGGGAAAGGAAGCCCATTAGATGCGCGTCCATGTCAAGGCTTGGAATAAGAGGCCCAATTGAGATAAGGCCTGGAGAGTCATGGGCTTCCAGGAGTACTATAGGAACAGGCCTGTCAGAGGCGGATTCAGAGGTGGAGAACGAGCTCCATCCATACAGGCACCTCAACAGGCTAGGGACCAGCGTTATGGATCCGGGAGAGTCTGCCTCCATTGTAGGGGCCCAGAGAGCCGAGTCCAATATCACGATGTCTATGGCCCAATTAAATGATTTGGTTAGGACAACTGTCCAAGAGTGTATTAACAATAACTGTCAGGCTTCCAAGCCCAAATCATTTCAATAA |
| Protein Sequence | MESQLANPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFNHVDYGKWERKPIRCASMSRLGIRGPIEIRPGESWASRSTIGTGLSEADSEVENELHPYRHLNRLGTSVMDPGESASIVGAQRAESNITMSMAQLNDLVRTTVQECINNNCQASKPKSFQ |
References More References in PubMed
| 1 |
Xie Y, et al. Virology. 2024 Jun;594:110040. doi: 10.1016/j.virol.2024.110040. Epub 2024 Mar 5. PMID: 38471198 |
|---|---|
| 2 |
First Report of Tomato yellow leaf curl virus Infecting Tomato, Tomatillo, and Peppers in Guatemala. Salati R, et al. Plant Dis. 2010 Apr;94(4):482. doi: 10.1094/PDIS-94-4-0482C. PMID: 30754504 |
| 3 |
Molecular characterization and pathogenicity of tomato yellow leaf curl virus in China. Zhang H, et al. Virus Genes. 2009 Oct;39(2):249-55. doi: 10.1007/s11262-009-0384-8. PMID: 19590945 |
| 4 |
Zambrano K, et al. Arch Virol. 2011 Dec;156(12):2263-6. doi: 10.1007/s00705-011-1093-x. Epub 2011 Aug 19. PMID: 21853328 |
| 5 |
Introduction of the Exotic Monopartite Tomato yellow leaf curl virus into West Coast Mexico. Brown JK, et al. Plant Dis. 2006 Oct;90(10):1360. doi: 10.1094/PD-90-1360A. PMID: 30780952 |
| 6 |
First record of tomato yellow leaf curl Sardinia virus (TYLCSV) on pepper in Italy. Fanigliulo A, et al. Commun Agric Appl Biol Sci. 2008;73(2):297-302. PMID: 19226766 |
| 7 |
Alabi OJ, et al. Plant Dis. 2017 Jul;101(7):1094-1102. doi: 10.1094/PDIS-01-17-0118-RE. Epub 2017 Apr 19. PMID: 30682949 |
| 8 |
Chen LF, et al. Mol Plant Pathol. 2009 May;10(3):415-30. doi: 10.1111/j.1364-3703.2009.00541.x. PMID: 19400843 |
| 9 |
Zhou YC, et al. Arch Virol. 2008;153(4):693-706. doi: 10.1007/s00705-008-0042-9. Epub 2008 Feb 16. PMID: 18278427 |
| 10 |
A distinct seed-transmissible strain of tomato leaf curl New Delhi virus infecting Chayote in India. Sangeetha B, et al. Virus Res. 2018 Oct 15;258:81-91. doi: 10.1016/j.virusres.2018.10.009. Epub 2018 Oct 15. PMID: 30336187 |