Tomato yellow leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000858205.1 |
| Isolate | Spain:Almeria |
| Release date | 2015/2/13 |
| Submitter | Morilla,G., Janssen,D., Garcia-Andres,S., Moriones,E., Cuadrado,I.M., Bejarano,E.R. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
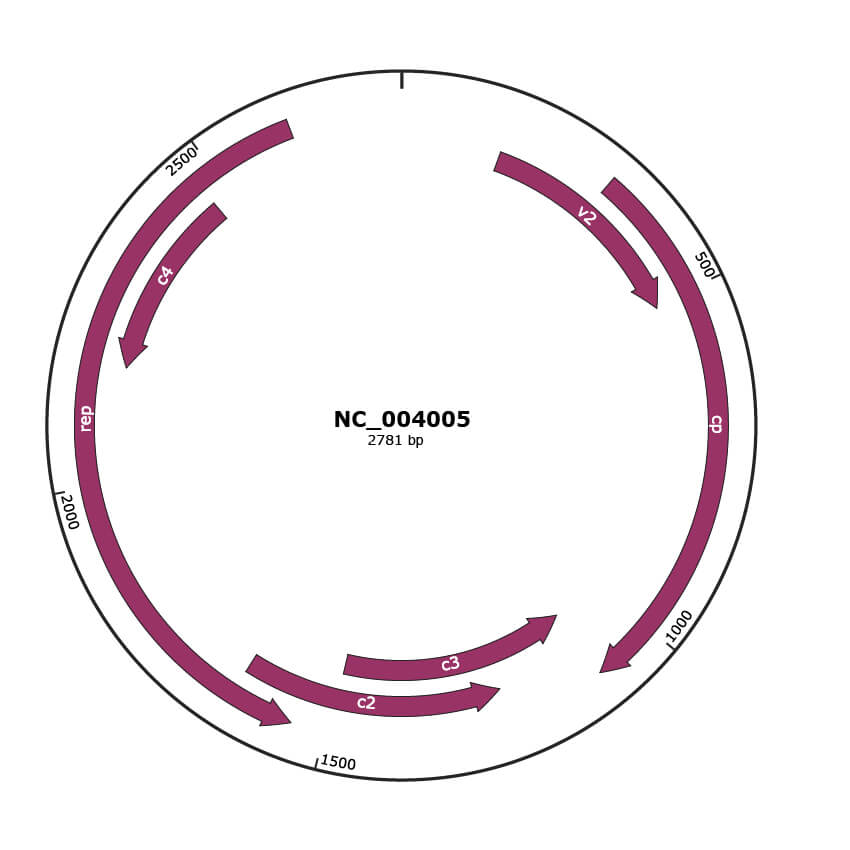
JBrowse
Genome
NC_004005
Gene Information
| NCBI Accession | NP_658991.1 |
|---|---|
| Location | 155-505 |
| Gene Name | v2 |
| Protein Name | precoat protein |
| Coding Region | ATGTGGGACCCACTTCTAAATGAATTTCCTGAATCTGTTCACGGATTTCGTTGTATGTTAGCTATTAAATATTTGCAGTCCGTTGAGGAAACTTACGAGCCCAATACATTGGGCCACGATTTAATTAGGGATCTTATATCTGTTGTAAGGGCCCGTGACTATGTCGAAGCGACCAGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGACGATCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPESVHGFRCMLAIKYLQSVEETYEPNTLGHDLIRDLISVVRARDYVEATRRYNHFHARLEGSPKAELRQPIQQPCCCPHCPRHKQATIMDVQAHVPKAQNIQNVSKP |
| NCBI Accession | NP_658992.1 |
|---|---|
| Location | 315-1091 |
| Gene Name | cp |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGACGATCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGATGTTCCCCGTGGATGTGAAGGCCCATGTAAAGTCCAGTCTTATGAGCAACGGGATGATATTAAGCACACTGGTATTGTTCGTTGTGTTAGTGATGTTACTCGTGGATCTGGAATTACTCACAGAGTGGGTAAGAGGTTCTGTGTTAAATCGATATATTTTTTAGGTAAAGTCTGGATGGATGAAAATATCAAGAAGCAGAATCACACTAATCAGGTCATGTTCTTTTTGGTCCGTGATAGAAGGCCCTATGGAAGCAGCCCAATGGATTTTGGACAGGTTTTTAATATGTTCGATAATGAGCCCAGTACCGCAACCGTGAAGAATGATTTGCGTGATAGGTTTCAAGTGATGAGAAAATTTCATGCAACAGTTATTGGTGGGCCCTCTGGAATGAAGGAACAGGCATTAGTTAAGAGATTTTTTAAAATTAACAGTCATGTAACTTATAATCATCAGGAGGCAGCCAAGTACGAGAACCATACTGAAAACGCCTTGTTATTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGTAACTATGAAAATACGCATCTATTTCTATGATTCAATATCAAATTAA |
| Protein Sequence | MSKRPGDIIISTPVSKVRRRLNFDSPYSSRAAVPIVQGTNKRRSWTYRPMYRKPRIYRMYRSPDVPRGCEGPCKVQSYEQRDDIKHTGIVRCVSDVTRGSGITHRVGKRFCVKSIYFLGKVWMDENIKKQNHTNQVMFFLVRDRRPYGSSPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMRKFHATVIGGPSGMKEQALVKRFFKINSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYVTMKIRIYFYDSISN |
| NCBI Accession | NP_658993.1 |
|---|---|
| Location | 1088-1492 |
| Gene Name | c3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCTCCTCAGGCAGAGAATGGCGTTTTTATTTGGGAGATAAACAATCCCCTCTATTTCAAGATAACAGAACACAGCCAGCGGCCATTTCTAATGAACCACGACATCATTTCCATTCAGATAAGATTCAACCACAACATCAGGAAGGTAATGGGGATTCACAAATGTTTTCTCAACTTCCGAATTTGGACGACATTACAGCCTCAGACTGGTCATTTCTTAAGAGTATTTAGATATGAAGTTCTTAAGTATTTAGATAGTCTTGGTGTAATTTCCATTAACAATGTAATCAGAGCAGTTGATCATGTATTGTATGATGTACTTGAAAACACAATAAATGTAACAGAAACTCATGATATAAAATATAAATTTTATTAA |
| Protein Sequence | MDSRTGELITAPQAENGVFIWEINNPLYFKITEHSQRPFLMNHDIISIQIRFNHNIRKVMGIHKCFLNFRIWTTLQPQTGHFLRVFRYEVLKYLDSLGVISINNVIRAVDHVLYDVLENTINVTETHDIKYKFY |
| NCBI Accession | NP_658994.1 |
|---|---|
| Location | 1233-1640 |
| Gene Name | c2 |
| Protein Name | C2 protein |
| Coding Region | ATGCAACCTTCGTCACCCTCTACGAGCCACTGTTCGCAAGTATCAATCAAGGTCCAACACAAGATAGCCAAGAAGAAACCAATAAGGCGTAAGCGTGTAGACCTAGACTGTGGCTGCTCATACTACCTCCACCTCAACTGCAACAATCATGGATTCACGCACAGGGGAACTCATCACTGCTCCTCAGGCAGAGAATGGCGTTTTTATTTGGGAGATAAACAATCCCCTCTATTTCAAGATAACAGAACACAGCCAGCGGCCATTTCTAATGAACCACGACATCATTTCCATTCAGATAAGATTCAACCACAACATCAGGAAGGTAATGGGGATTCACAAATGTTTTCTCAACTTCCGAATTTGGACGACATTACAGCCTCAGACTGGTCATTTCTTAAGAGTATTTAG |
| Protein Sequence | MQPSSPSTSHCSQVSIKVQHKIAKKKPIRRKRVDLDCGCSYYLHLNCNNHGFTHRGTHHCSSGREWRFYLGDKQSPLFQDNRTQPAAISNEPRHHFHSDKIQPQHQEGNGDSQMFSQLPNLDDITASDWSFLKSI |
| NCBI Accession | NP_658995.1 |
|---|---|
| Location | 1549-2622 |
| Gene Name | rep |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCTCGTTTATTTAAAATATATGCCAAAAATTATTTCCTAACATATCCCAATTGTTCTCTCTCTAAAGAGGAAGCACTTTCCCAATTAAAAAACCTAGAAACCCCAACAAATAAAAAATACATCAAAGTTTGCAGAGAACTCCACGAGAATGGGGAACCACATCTCCATGTGCTTATCCAATTCGAAGGCAAATACCAATGTAAGAACCAACGGTTCTTCGACCTGGTATCCCCAAACAGATCAGCACATTTCCATCCGAACATTCAGGCAGCTAAGAGCTCAACAGATGTCAAGACCTACGTGGAGAAAGACGGAGACTTCATTGATTTTGGAGTTTTCCAAATCGATGGCAGATCAGCTAGAGGAGGTCAGCAATCTGCCAACGACGCATATGCCGAAGCACTCAATTCAGGCAATAAATCCGAGGCCCTCAATATATTAAAAGAGAAGGCCCCAAAGGACTATATTTTACAATTTCATAATTTAAGTTCAAATTTAGATAGGATTTTTAGTCCTCCTTTAGAAGTTTATGTTTCTCCATTTCTTTCTTCTTCTTTTAATCAAGTTCCAGATGAACTTGAAGAGTGGGTCGCTGAGAACGTCGTGTCTTCCGCTGCGCGGCCATGGAGACCTAATAGTATTGTCATTGAGGGTGATAGCAGAACAGGCAAAACAATGTGGGCCAGGTCTCTAGGCCCACATAATTATTTATGTGGACATCTAGACCTAAGCCCAAAGGTGTACAGTAATGATGCGTGGTACAACGTCATTGATGACGTAGACCCGCATTATTTAAAGCACTTCAAGGAATTCATGGGGGCCCAGAGGGACTGGCAAAGCAACACAAAGTACGGGAAGCCCATTCAAATTAAAGGGGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCTACCTCCTCATATAGGGAATATCTAGACGAAGAAAAAAATATATCCTTGAAAAATTGGGCGCTCAAGAATGCAACCTTCGTCACCCTCTACGAGCCACTGTTCGCAAGTATCAATCAAGGTCCAACACAAGATAGCCAAGAAGAAACCAATAAGGCGTAA |
| Protein Sequence | MPRLFKIYAKNYFLTYPNCSLSKEEALSQLKNLETPTNKKYIKVCRELHENGEPHLHVLIQFEGKYQCKNQRFFDLVSPNRSAHFHPNIQAAKSSTDVKTYVEKDGDFIDFGVFQIDGRSARGGQQSANDAYAEALNSGNKSEALNILKEKAPKDYILQFHNLSSNLDRIFSPPLEVYVSPFLSSSFNQVPDELEEWVAENVVSSAARPWRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYREYLDEEKNISLKNWALKNATFVTLYEPLFASINQGPTQDSQEETNKA |
| NCBI Accession | NP_658996.1 |
|---|---|
| Location | 2178-2471 |
| Gene Name | c4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCACATCTCCATGTGCTTATCCAATTCGAAGGCAAATACCAATGTAAGAACCAACGGTTCTTCGACCTGGTATCCCCAAACAGATCAGCACATTTCCATCCGAACATTCAGGCAGCTAAGAGCTCAACAGATGTCAAGACCTACGTGGAGAAAGACGGAGACTTCATTGATTTTGGAGTTTTCCAAATCGATGGCAGATCAGCTAGAGGAGGTCAGCAATCTGCCAACGACGCATATGCCGAAGCACTCAATTCAGGCAATAAATCCGAGGCCCTCAATATATTAA |
| Protein Sequence | MGNHISMCLSNSKANTNVRTNGSSTWYPQTDQHISIRTFRQLRAQQMSRPTWRKTETSLILEFSKSMADQLEEVSNLPTTHMPKHSIQAINPRPSIY |
References More References in PubMed
| 1 |
Tomato Yellow Leaf Curl Virus: Impact, Challenges, and Management. Prasad A, et al. Trends Plant Sci. 2020 Sep;25(9):897-911. doi: 10.1016/j.tplants.2020.03.015. Epub 2020 May 1. PMID: 32371058 |
|---|---|
| 2 |
Tomato yellow leaf curl virus: Characteristics, influence, and regulation mechanism. Cao X, et al. Plant Physiol Biochem. 2024 Aug;213:108812. doi: 10.1016/j.plaphy.2024.108812. Epub 2024 Jun 8. PMID: 38875781 |
| 3 |
Natural resistance of tomato plants to Tomato yellow leaf curl virus. H El-Sappah A, et al. Front Plant Sci. 2022 Dec 19;13:1081549. doi: 10.3389/fpls.2022.1081549. eCollection 2022. PMID: 36600922 |
| 4 |
Zhou Y, et al. Lett Appl Microbiol. 2022 May;74(5):640-646. doi: 10.1111/lam.13611. Epub 2021 Dec 14. PMID: 34822723 |
| 5 |
Tomato Yellow Leaf Curl Virus (TYLCV) Promotes Plant Tolerance to Drought. Shteinberg M, et al. Cells. 2021 Oct 25;10(11):2875. doi: 10.3390/cells10112875. PMID: 34831098 |
| 6 |
Tomato yellow leaf curl virus, an emerging virus complex causing epidemics worldwide. Moriones E, et al. Virus Res. 2000 Nov;71(1-2):123-34. doi: 10.1016/s0168-1702(00)00193-3. PMID: 11137167 |
| 7 |
Xie Y, et al. Virology. 2024 Jun;594:110040. doi: 10.1016/j.virol.2024.110040. Epub 2024 Mar 5. PMID: 38471198 |
| 8 |
Gibberellin Positively Regulates Tomato Resistance to Tomato Yellow Leaf Curl Virus (TYLCV). Zhang C, et al. Plants (Basel). 2024 May 6;13(9):1277. doi: 10.3390/plants13091277. PMID: 38732492 |
| 9 |
Tomato Yellow Leaf Curl Virus Infection in a Monocotyledonous Weed (Eleusine indica). Kil EJ, et al. Plant Pathol J. 2021 Dec;37(6):641-651. doi: 10.5423/PPJ.FT.11.2021.0162. Epub 2021 Dec 1. PMID: 34897255 |
| 10 |
Yang Y, et al. PLoS Pathog. 2019 Jan 22;15(1):e1007534. doi: 10.1371/journal.ppat.1007534. eCollection 2019 Jan. PMID: 30668603 |