Capraria yellow spot virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000911775.1 |
| Isolate |
Mexico: Yucatan, Conkal |
| Release date |
2015/2/22 |
| Submitter |
Torres-Herrera,I., Cardenas-Conejo,Y., Ambriz-Granados,S., Mauricio-Castillo,J.A., Moreno-Valenzuela,O., Arguello-Astorga,G.R. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
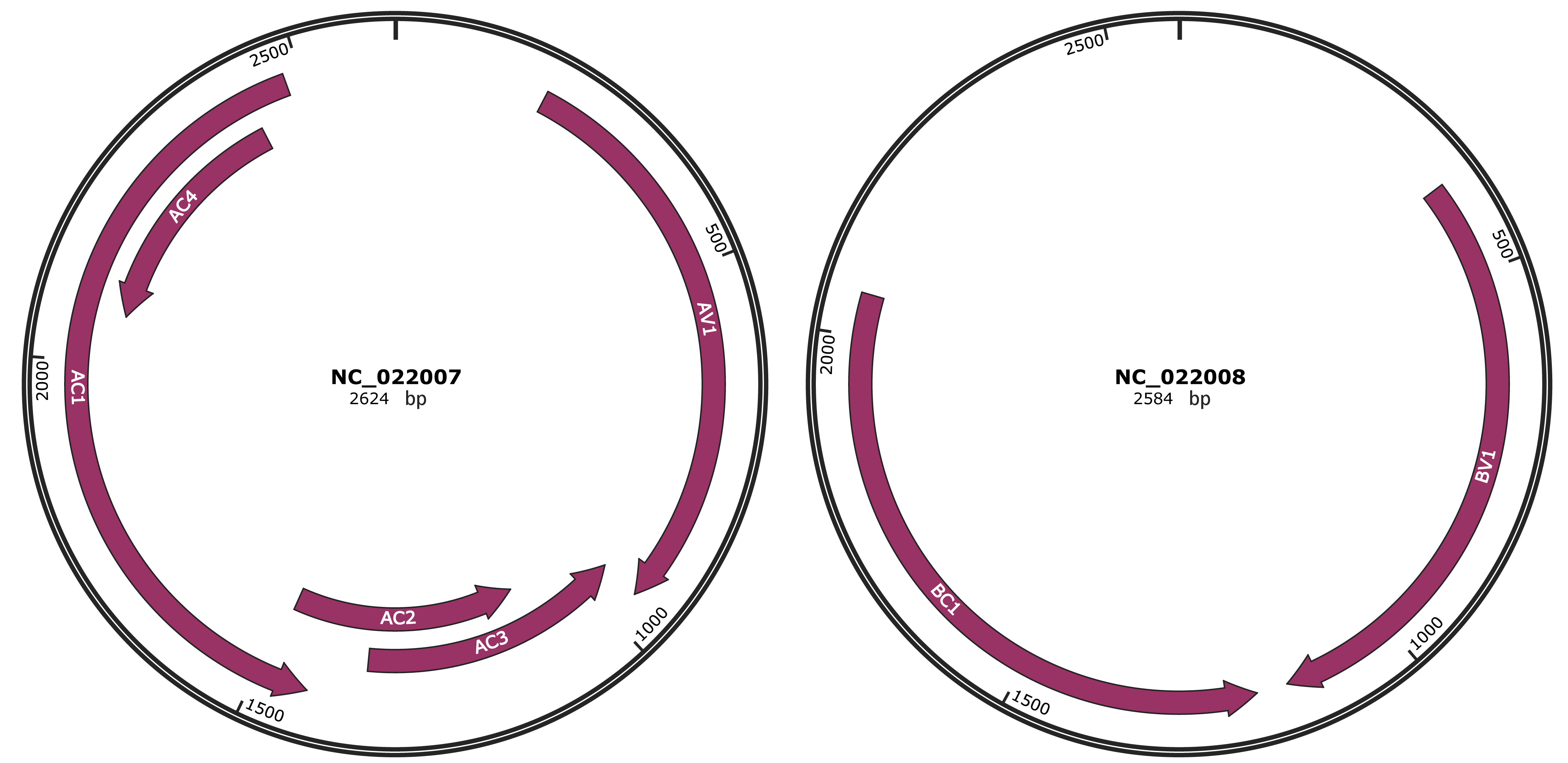
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTGGAGTCCTGTCCGTACCCACTTGCTCTCGCTTTATTTTCATCCTGGGCCCACAGATAAGATGAAAATCTCACGGACCAATGACATGCCTCCTGTGGAGCCTAGTTATCTATTACTTGCTGACTAAGTGTGGTCCCTGCCTATTAAAGCACTGACAGTTTCATCTTTTGCTTTAATTCGAAATGCCTAAGCGCGATGCCCCATGGCGCTTAATGGCGGGGACCTCTAAGGCGTCCCGCTCTGCCAACTATACGCCTCGTGGAGTTGTTGGGCCTAAAATTGATAAGGCCGCTGCTTGGGTTAACAGGCCCATGTACAGAAAGCCCAGGATATATCGGACTTTGAGAAGCCCAGATGTTCCCAGAGGGTGTGAAGGGCCTTGTAAGGTCCAGTCCTTCGAGCAGCGGCATGATATATCTCATGTTGGCAAGGTGCTGTGCATTTCTGACGTGACACGAGGCAATGGCATTACCCATCGTGTTGGTAAGCGTTTCTGCGTCAAGTCTGTGTACATATTGGGCAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTCCGTGACCGTAGACCCTACGGCACCCCCATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAACCCAGTACTGCCACTGTGAAGAACGATCTTCGTGATCGTTTTCAGGTCATGCACAAGTTCTATGCTAAGGTGACTGGTGGACAGTACGCGAGCAATGAGCAGGCGTTGGTCAAACGGTTCTGGAAGGTGAACAACTACGTCGTCTACAACCATCAAGAGGCAGGGAAATACGAGAATCATACGGAGAATGCTTTGTTATTGTACATGGCATGTACTCATGCCTCTAATCCTGTATATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAAATTTGTATTTTATTTCATGATTCTCGAGTACATCTGTTACATAATGTCTGTCTGTTGCGAAACGAACAGCTCGGATTACATTGTTTATTCCAATAGCTCCTAAGCTATCTAAGTAAGACATTACAAGAAATTTGAATCTACTTAAATATGTCCGTCCAGAAGCTGTCATCGAAGTCGTCCAGATTTGGAAGTTGAAGTACGCTTTGTGGAGACCCAACGCTCTCCTCACGTTGTGGTTGAACCGGACTTCGATGTGGTATATTCTTGTTCTCGTGAACATGGGGTTCTCTACGAACCGTATCCTTGAAAAGAGGGAATTGGAACCCTCCCAGGTAAAAACGGAACTCTCTGCATGATCCGCAGTGATGCTCTCCCCGGTGCGTGAATCCATTGTCTGCGCAGTTGATGTGGAGGTATATGGTACATCCACAGTTCAAATCTATGCGTCTTCGACGAACAGCCCTTTTCTTAGCAATCCTGTGCTGTGCTTTGATAGAGGGGGGCGTTGAGGAAGATGAATTTTGCATTTTTTAATGTCCAGTTCCTCGGTGATGTATTTTCCTTTTTATCGAGGAAATCTTTATAGCTGGCCCCCTCTCCTGGATTGCACAGCACGATTGATGGTATGCCACCTTTAATTTGAACTGGTTTTCCGTATTTGCAATTTGTTTGCCAGTTCATCTGGGCCCCAATCAACTCTTTCCAGTGCTTTAGCTTTAGGTAGTGCGGAGCTACGTCATCAATGACGTTATACTCCACATCATTTGAATAGACCCTAGAATTGAAGTCTAGGTGACCACTCAAGTAATTATGCCTACCTAGAGCACGAGCCCACATCGTCTTGCCAGTCCTCGAATCACCTTCGACGATGATACTAATAGCTCTAATTGGCCGCGCAGCGGAACCTCTTCCAAAATACTCATCAGCCCACTCTTGCATCTCGTCTGGCACGTTAGTGAAGGAAGAGAGTCGGAACGGAGGAACCCATGGTTCCGGAGCCTTTTGAAAGAGGCGATCGAGGTTAGGCACTAAGTTATGGTAGTTAACAATGAACGATTTTGGATCTCCGGCTCTTATAAGCTCGAGAGCCTCTCCAGCACTTGCTGCATTTACGACGTTGTGGTAGACGTCGTCCTTATTGGCTTTGGAACCCCCAGACACCTTATACTGCCCGGATTCACAATAATCACCCTCTTTGGTGATGTAATTTCTGACGGCGTTGGTGTCTTTGGCAGCTTGGATATTTGGGTGAAAACGGGCAGACCTTCTGGGGTGAGTAAGGTCGAAAAATCCAGCATCCTTGATGTTGGACTTGCCGGAGAGTTGGAGGAGACAGTGTAAATGGGGGAACCCGTCTGAATGTTCCTCTCTTGAGACTCGTATGTATAAGGGCTTGACGATTGCCCAGTGCAGAGATTGAAGCATCTGAAGAGCTTCATCCTTGGGTATATCACACTGGGCATATGTTAGGAAGATATTATTGGCTTGAAGACGGAAGGAATTAGGGTTTCTAGGCATTATTGTTTGGGACTCTAAGCTGGGACTCCAGGGATGGCTATCTCAAAAACCTATTGTTTGTGGAGTCCTGGAGTCCTATATATACATAAAGCCTCTAGGACTCTAAGTACACGTGGGATCACTTTCGGCCATCCGATATAATATT
ACCGAACGGCCGCGATTTTTGGAGTCCTCCGTTAAGATTGTTACACGTGTCCTCCCGCCCTCTCACTTGGAGTAGTGCGCGGGGACCACTCACCCAAAGGAAATCCAACGGGCCAATCACATATCGCCTTGGCAGCCTCTTTATTTGTTAAGCTGGGCCCACCTAAGTTGAATAGTCTGCGCGATATGTGTCAGAAGACCACGTGCTTAAAGATAAATGTGGTGTGACCAATATACCCCCGTATCCGACGTGGTCCAATTAAAACTGAGATGGTAGTATATGTTAATTCCTACTTACAGCCATATACTCTATATAATTGTATTGAGTTTTAATTGTTAAATCGTCTTTAATACTAAGTTGTATAGGCGGGCATCACAACATGATCCCGATTAAGTACAGACGTGGGTCATCATACTCTCAGAGACGATTTTATCCACGTAATCATCTGTTTAAGAGAAATGGTTCTGTGAAACGTAACGACGGTAAGCGTCGTTCAATTCAGGTGAACAAGGTTCACGACGAGCCGAAGTTGTCGTCTCAACGCATACATGAGAACCAATATGGACCTGAATTTGTAATGTCTCATAATTCAGCCATTTCAACTTTCATCAACTTCCCAGCTGTTGGAAAGACTCTACCCAATCGAAGCAGGTCCTATATTAAGTTGAAACGTCTACGTTTCAAGGGTACTGTTAAGATCGAGCGTGTGCATGCTGATTTGAACATGGACGGATTGAGTCCTAAGATTGAAGGTGTTTTCTCTCTGGTCATCGTTGTTGATCGTAAACCCCACCTAAGTTCCTCGGGTTGTCTTCACACGTTCGACGAGATATTTGGTGCGAGGATTCACAGTCATGGGAACTTGGCAATTACCCCATCTTTGAAAGATCGGTACTACTTACGTCATGTTTTGAAGCGCGTATTGTCAGTCGAGAAAGATAGTGTCATGGTGGACCTCGAAGGATCCACTTCATTTACTAATAAGCGCTTCAATTGTTGGTCTTCGTTTAAGGACCTTGAATCCGATTCATGTAATGGTGTTTATGCCAACATAAGCAGAAATGCCGTATTAGTTTACTATTGCTGGATGTCGGATGTTATGTCTAAGGCATCGACATTTGTATCATTTGACCTGGATTATGTTGGGTGATTATGAATAAAATGAATATTTTATTACACGCAATGACATCTTATTGAAGAGATTTAGGCTGTGTGGGATTACAATTACTATTGATACACTCTTGGACCGTTGTTCTTACAAGCTCGTTGATTTGAGCCATTGACATGGTAATGTGAGAATGAGCTCTCTGTAATCCCACTTGTGATGCTGAATCACCCGGGTCTAATACGCTCCCTCCCAGTCGGTTGAGGTATCTGTACGGGTGTATCTCTGAATCCTGATCCGTCCTTCCTATAGTGCTCTTGGAAGCCCATGACTCGCCTGGTTTCAATTCTATTGGGCCTGTGAGCCCAAGTCGTGACATGGACCTGTTTATTATGGGCTTCCTCTCCCATGGGCCGTAATCCACGTGAGAAAAGTCCACGTCCCTATGGGAGAACTGTTTGGAAAGTATCTTGACAGTGGGGGCCCTGAATGGTATTTCTACAGAGTGCTTAGCTGTCGACAGCTTTAACTTTCCTTTGAACTTGGCGAAATGTGTCCTCTGGTGCACATTCGTGTCGGACACTCTGTAGTACAATTTCCATGGAATTGGGTCCTTGAGTGAGAAGAATGACGATGAGAAGTAGTGGAGGTCTATGTTGCATCTGATCGGGAAAGTCCAAGACGCCTGCAACGACTCGTTGTCCGTCATTCTTCTGTCGTGAATTTCCACGATTACCGACCCAGCTGCGTTAATCGGCACCTGCTGCCTGTACTCAATTACGCAGTGGTCGATCTTCATACAGCTCCGATTGAGCCTTGCAGTTATTTGGGACGCAGTTGAGGGAAATTCAAGAACAATCTCAGTTAGGTCATGCGACAGCTGGTACTCGTCCCTATGGGACTCTATGTAATTAAAGGCACTCGGTGCACTTGCTAACTGAGAATCCATATATGAAGAATTGGCCGCGCAGCGGAACAGCTTGAAGAACAAGATGAGGAGAACAGCTTGAAGATCTGGATGAGGATCTTTAAAATTTGAAGATGAATATGGAACGACACCGTTTGAAGAACGGGTTGAGTTTGTTATGGAGGTTCTGCTGTTTCAGAACCGATTTAAGGTTAAGAATGACAATGAACGTTGTCTTCTGGGTTGAGCAATATAAGAATTATTTGGAATTGAAGAGTCTCAGCCTTTAAAGATTATGAAGGTGTCTTGAACAGGGAGATGAAGGTAAGATAAACTTCATCGATATTGGCTCTTATATAGGCATTTGATCTTTGTTAGGTATTGTTTTAGCTTGCACATATGTTTGAGGGGCATATTGGTAAAAATGACTGGGACTCCGCCTCAGGACTCCAACCGTACACGCTTCAAAAACCTATTGTTGTTGGAGTCCTGGAGTCCTCCATTAAGATTATTACACGTAAGCTATTTAGGGACAGATGGCAATCATCCAGCGGCCGTTCGACTATAATATT
Gene Information
|
NCBI Accession
|
YP_008400128.1
|
|
Location
|
202-957 |
|
Gene Name
|
AV1 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCATGGCGCTTAATGGCGGGGACCTCTAAGGCGTCCCGCTCTGCCAACTATACGCCTCGTGGAGTTGTTGGGCCTAAAATTGATAAGGCCGCTGCTTGGGTTAACAGGCCCATGTACAGAAAGCCCAGGATATATCGGACTTTGAGAAGCCCAGATGTTCCCAGAGGGTGTGAAGGGCCTTGTAAGGTCCAGTCCTTCGAGCAGCGGCATGATATATCTCATGTTGGCAAGGTGCTGTGCATTTCTGACGTGACACGAGGCAATGGCATTACCCATCGTGTTGGTAAGCGTTTCTGCGTCAAGTCTGTGTACATATTGGGCAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTCCGTGACCGTAGACCCTACGGCACCCCCATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAACCCAGTACTGCCACTGTGAAGAACGATCTTCGTGATCGTTTTCAGGTCATGCACAAGTTCTATGCTAAGGTGACTGGTGGACAGTACGCGAGCAATGAGCAGGCGTTGGTCAAACGGTTCTGGAAGGTGAACAACTACGTCGTCTACAACCATCAAGAGGCAGGGAAATACGAGAATCATACGGAGAATGCTTTGTTATTGTACATGGCATGTACTCATGCCTCTAATCCTGTATATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKASRSANYTPRGVVGPKIDKAAAWVNRPMYRKPRIYRTLRSPDVPRGCEGPCKVQSFEQRHDISHVGKVLCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_008400129.1
|
|
Location
|
954-1352 |
|
Gene Name
|
AC3 |
|
Protein Name
|
rep-interacting protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAGAGCATCACTGCGGATCATGCAGAGAGTTCCGTTTTTACCTGGGAGGGTTCCAATTCCCTCTTTTCAAGGATACGGTTCGTAGAGAACCCCATGTTCACGAGAACAAGAATATACCACATCGAAGTCCGGTTCAACCACAACGTGAGGAGAGCGTTGGGTCTCCACAAAGCGTACTTCAACTTCCAAATCTGGACGACTTCGATGACAGCTTCTGGACGGACATATTTAAGTAGATTCAAATTTCTTGTAATGTCTTACTTAGATAGCTTAGGAGCTATTGGAATAAACAATGTAATCCGAGCTGTTCGTTTCGCAACAGACAGACATTATGTAACAGATGTACTCGAGAATCATGAAATAAAATACAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGESITADHAESSVFTWEGSNSLFSRIRFVENPMFTRTRIYHIEVRFNHNVRRALGLHKAYFNFQIWTTSMTASGRTYLSRFKFLVMSYLDSLGAIGINNVIRAVRFATDRHYVTDVLENHEIKYKFY |
|
NCBI Accession
|
YP_008400130.1
|
|
Location
|
1099-1488 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcription activator |
|
Coding Region
|
ATGCAAAATTCATCTTCCTCAACGCCCCCCTCTATCAAAGCACAGCACAGGATTGCTAAGAAAAGGGCTGTTCGTCGAAGACGCATAGATTTGAACTGTGGATGTACCATATACCTCCACATCAACTGCGCAGACAATGGATTCACGCACCGGGGAGAGCATCACTGCGGATCATGCAGAGAGTTCCGTTTTTACCTGGGAGGGTTCCAATTCCCTCTTTTCAAGGATACGGTTCGTAGAGAACCCCATGTTCACGAGAACAAGAATATACCACATCGAAGTCCGGTTCAACCACAACGTGAGGAGAGCGTTGGGTCTCCACAAAGCGTACTTCAACTTCCAAATCTGGACGACTTCGATGACAGCTTCTGGACGGACATATTTAAGTAG |
|
Protein Sequence
|
MQNSSSSTPPSIKAQHRIAKKRAVRRRRIDLNCGCTIYLHINCADNGFTHRGEHHCGSCREFRFYLGGFQFPLFKDTVRREPHVHENKNIPHRSPVQPQREESVGSPQSVLQLPNLDDFDDSFWTDIFK |
|
NCBI Accession
|
YP_008400131.1
|
|
Location
|
1430-2479 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rolling-circle initiation protein |
|
Coding Region
|
ATGCCTAGAAACCCTAATTCCTTCCGTCTTCAAGCCAATAATATCTTCCTAACATATGCCCAGTGTGATATACCCAAGGATGAAGCTCTTCAGATGCTTCAATCTCTGCACTGGGCAATCGTCAAGCCCTTATACATACGAGTCTCAAGAGAGGAACATTCAGACGGGTTCCCCCATTTACACTGTCTCCTCCAACTCTCCGGCAAGTCCAACATCAAGGATGCTGGATTTTTCGACCTTACTCACCCCAGAAGGTCTGCCCGTTTTCACCCAAATATCCAAGCTGCCAAAGACACCAACGCCGTCAGAAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGGCAGTATAAGGTGTCTGGGGGTTCCAAAGCCAATAAGGACGACGTCTACCACAACGTCGTAAATGCAGCAAGTGCTGGAGAGGCTCTCGAGCTTATAAGAGCCGGAGATCCAAAATCGTTCATTGTTAACTACCATAACTTAGTGCCTAACCTCGATCGCCTCTTTCAAAAGGCTCCGGAACCATGGGTTCCTCCGTTCCGACTCTCTTCCTTCACTAACGTGCCAGACGAGATGCAAGAGTGGGCTGATGAGTATTTTGGAAGAGGTTCCGCTGCGCGGCCAATTAGAGCTATTAGTATCATCGTCGAAGGTGATTCGAGGACTGGCAAGACGATGTGGGCTCGTGCTCTAGGTAGGCATAATTACTTGAGTGGTCACCTAGACTTCAATTCTAGGGTCTATTCAAATGATGTGGAGTATAACGTCATTGATGACGTAGCTCCGCACTACCTAAAGCTAAAGCACTGGAAAGAGTTGATTGGGGCCCAGATGAACTGGCAAACAAATTGCAAATACGGAAAACCAGTTCAAATTAAAGGTGGCATACCATCAATCGTGCTGTGCAATCCAGGAGAGGGGGCCAGCTATAAAGATTTCCTCGATAAAAAGGAAAATACATCACCGAGGAACTGGACATTAAAAAATGCAAAATTCATCTTCCTCAACGCCCCCCTCTATCAAAGCACAGCACAGGATTGCTAA |
|
Protein Sequence
|
MPRNPNSFRLQANNIFLTYAQCDIPKDEALQMLQSLHWAIVKPLYIRVSREEHSDGFPHLHCLLQLSGKSNIKDAGFFDLTHPRRSARFHPNIQAAKDTNAVRNYITKEGDYCESGQYKVSGGSKANKDDVYHNVVNAASAGEALELIRAGDPKSFIVNYHNLVPNLDRLFQKAPEPWVPPFRLSSFTNVPDEMQEWADEYFGRGSAARPIRAISIIVEGDSRTGKTMWARALGRHNYLSGHLDFNSRVYSNDVEYNVIDDVAPHYLKLKHWKELIGAQMNWQTNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKKENTSPRNWTLKNAKFIFLNAPLYQSTAQDC |
|
NCBI Accession
|
YP_008400132.1
|
|
Location
|
2071-2424 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGCCCAGTGTGATATACCCAAGGATGAAGCTCTTCAGATGCTTCAATCTCTGCACTGGGCAATCGTCAAGCCCTTATACATACGAGTCTCAAGAGAGGAACATTCAGACGGGTTCCCCCATTTACACTGTCTCCTCCAACTCTCCGGCAAGTCCAACATCAAGGATGCTGGATTTTTCGACCTTACTCACCCCAGAAGGTCTGCCCGTTTTCACCCAAATATCCAAGCTGCCAAAGACACCAACGCCGTCAGAAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGGCAGTATAAGGTGTCTGGGGGTTCCAAAGCCAATAAGGACGACGTCTACCACAACGTCGTAA |
|
Protein Sequence
|
MPSVIYPRMKLFRCFNLCTGQSSSPYTYESQERNIQTGSPIYTVSSNSPASPTSRMLDFSTLLTPEGLPVFTQISKLPKTPTPSEITSPKRVIIVNPGSIRCLGVPKPIRTTSTTTS |
|
NCBI Accession
|
YP_008400133.1
|
|
Location
|
380-1150 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear transporter |
|
Coding Region
|
ATGATCCCGATTAAGTACAGACGTGGGTCATCATACTCTCAGAGACGATTTTATCCACGTAATCATCTGTTTAAGAGAAATGGTTCTGTGAAACGTAACGACGGTAAGCGTCGTTCAATTCAGGTGAACAAGGTTCACGACGAGCCGAAGTTGTCGTCTCAACGCATACATGAGAACCAATATGGACCTGAATTTGTAATGTCTCATAATTCAGCCATTTCAACTTTCATCAACTTCCCAGCTGTTGGAAAGACTCTACCCAATCGAAGCAGGTCCTATATTAAGTTGAAACGTCTACGTTTCAAGGGTACTGTTAAGATCGAGCGTGTGCATGCTGATTTGAACATGGACGGATTGAGTCCTAAGATTGAAGGTGTTTTCTCTCTGGTCATCGTTGTTGATCGTAAACCCCACCTAAGTTCCTCGGGTTGTCTTCACACGTTCGACGAGATATTTGGTGCGAGGATTCACAGTCATGGGAACTTGGCAATTACCCCATCTTTGAAAGATCGGTACTACTTACGTCATGTTTTGAAGCGCGTATTGTCAGTCGAGAAAGATAGTGTCATGGTGGACCTCGAAGGATCCACTTCATTTACTAATAAGCGCTTCAATTGTTGGTCTTCGTTTAAGGACCTTGAATCCGATTCATGTAATGGTGTTTATGCCAACATAAGCAGAAATGCCGTATTAGTTTACTATTGCTGGATGTCGGATGTTATGTCTAAGGCATCGACATTTGTATCATTTGACCTGGATTATGTTGGGTGA |
|
Protein Sequence
|
MIPIKYRRGSSYSQRRFYPRNHLFKRNGSVKRNDGKRRSIQVNKVHDEPKLSSQRIHENQYGPEFVMSHNSAISTFINFPAVGKTLPNRSRSYIKLKRLRFKGTVKIERVHADLNMDGLSPKIEGVFSLVIVVDRKPHLSSSGCLHTFDEIFGARIHSHGNLAITPSLKDRYYLRHVLKRVLSVEKDSVMVDLEGSTSFTNKRFNCWSSFKDLESDSCNGVYANISRNAVLVYYCWMSDVMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_008400134.1
|
|
Location
|
1191-2054 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 |
|
Coding Region
|
ATGGATTCTCAGTTAGCAAGTGCACCGAGTGCCTTTAATTACATAGAGTCCCATAGGGACGAGTACCAGCTGTCGCATGACCTAACTGAGATTGTTCTTGAATTTCCCTCAACTGCGTCCCAAATAACTGCAAGGCTCAATCGGAGCTGTATGAAGATCGACCACTGCGTAATTGAGTACAGGCAGCAGGTGCCGATTAACGCAGCTGGGTCGGTAATCGTGGAAATTCACGACAGAAGAATGACGGACAACGAGTCGTTGCAGGCGTCTTGGACTTTCCCGATCAGATGCAACATAGACCTCCACTACTTCTCATCGTCATTCTTCTCACTCAAGGACCCAATTCCATGGAAATTGTACTACAGAGTGTCCGACACGAATGTGCACCAGAGGACACATTTCGCCAAGTTCAAAGGAAAGTTAAAGCTGTCGACAGCTAAGCACTCTGTAGAAATACCATTCAGGGCCCCCACTGTCAAGATACTTTCCAAACAGTTCTCCCATAGGGACGTGGACTTTTCTCACGTGGATTACGGCCCATGGGAGAGGAAGCCCATAATAAACAGGTCCATGTCACGACTTGGGCTCACAGGCCCAATAGAATTGAAACCAGGCGAGTCATGGGCTTCCAAGAGCACTATAGGAAGGACGGATCAGGATTCAGAGATACACCCGTACAGATACCTCAACCGACTGGGAGGGAGCGTATTAGACCCGGGTGATTCAGCATCACAAGTGGGATTACAGAGAGCTCATTCTCACATTACCATGTCAATGGCTCAAATCAACGAGCTTGTAAGAACAACGGTCCAAGAGTGTATCAATAGTAATTGTAATCCCACACAGCCTAAATCTCTTCAATAA |
|
Protein Sequence
|
MDSQLASAPSAFNYIESHRDEYQLSHDLTEIVLEFPSTASQITARLNRSCMKIDHCVIEYRQQVPINAAGSVIVEIHDRRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVEIPFRAPTVKILSKQFSHRDVDFSHVDYGPWERKPIINRSMSRLGLTGPIELKPGESWASKSTIGRTDQDSEIHPYRYLNRLGGSVLDPGDSASQVGLQRAHSHITMSMAQINELVRTTVQECINSNCNPTQPKSLQ |