Tomato yellow leaf curl Thailand virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000857225.1 |
| Release date | 2015/2/13 |
| Submitter | Attathom,S., Chiemsombat,P., Kositratana,W., Sae-Ung,N. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
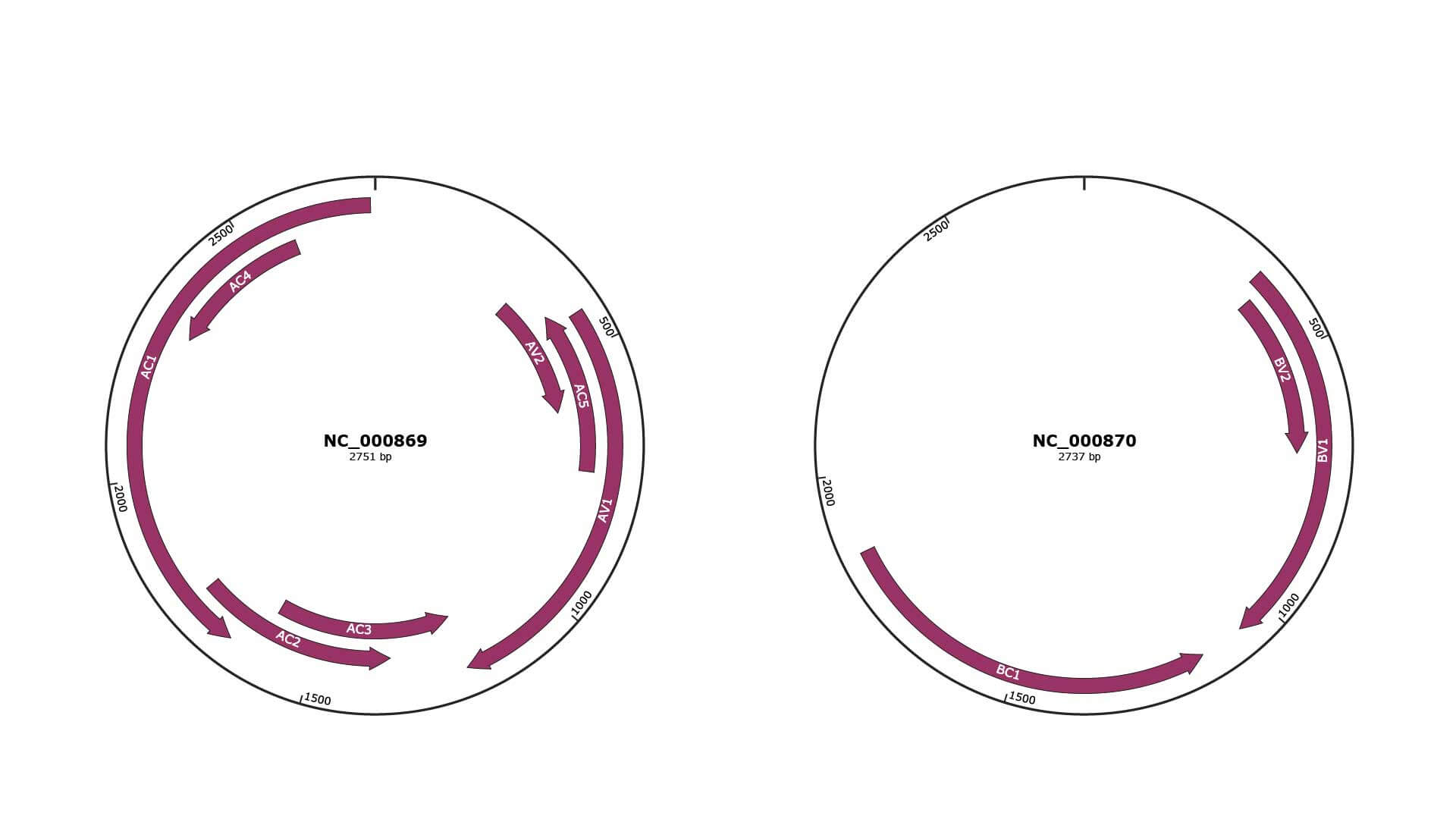
JBrowse
Genome
NC_000869
NC_000870
Gene Information
| NCBI Accession | NP_049913.1 |
|---|---|
| Location | 327-611 |
| Gene Name | AV2 |
| Protein Name | precoat protein |
| Coding Region | ATGTTAGCGGTGAAGTATCTGCAAGCGGTCGAGAAGACTTATTCCCCTGATACTCTAGGGTTTGATCTCATCCGTGATCTCATCGGTGTAATTCGTGCGAAGAACTATGTCGAAGCGTCCAGCAGATATTCTCATTTCCACTCCCGTCTCGAAAGTACGTCGCCGTCTGAACTTCGACAGCCCATACAACAGCCGTGCTGCTGTCCCCACTGTCCGCGTCACAAAAGGGCAGGTATGGAAGAACCGACCTGCATACAGAAAGCCCAGGATCTACAGAATGTATAG |
| Protein Sequence | MLAVKYLQAVEKTYSPDTLGFDLIRDLIGVIRAKNYVEASSRYSHFHSRLESTSPSELRQPIQQPCCCPHCPRHKRAGMEEPTCIQKAQDLQNV |
| NCBI Accession | NP_049914.1 |
|---|---|
| Location | 406-741 |
| Gene Name | AC5 |
| Protein Name | AC5 protein |
| Coding Region | ATGAGTAAGCCCAATACCACGGGTAACGTCATACAGACATATTACCTTGCCCATATGTCCAATGTCGTTCTTCGCATCGAAAGATTGGACCTTACATGGGCCCTCACATCCCTTAGGGACATCAGGGCTTCTATACATTCTGTAGATCCTGGGCTTTCTGTATGCAGGTCGGTTCTTCCATACCTGCCCTTTTGTGACGCGGACAGTGGGGACAGCAGCACGGCTGTTGTATGGGCTGTCGAAGTTCAGACGGCGACGTACTTTCGAGACGGGAGTGGAAATGAGAATATCTGCTGGACGCTTCGACATAGTTCTTCGCACGAATTACACCGATGA |
| Protein Sequence | MSKPNTTGNVIQTYYLAHMSNVVLRIERLDLTWALTSLRDIRASIHSVDPGLSVCRSVLPYLPFCDADSGDSSTAVVWAVEVQTATYFRDGSGNENICWTLRHSSSHELHR |
| NCBI Accession | NP_049915.1 |
|---|---|
| Location | 433-1203 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGTCCAGCAGATATTCTCATTTCCACTCCCGTCTCGAAAGTACGTCGCCGTCTGAACTTCGACAGCCCATACAACAGCCGTGCTGCTGTCCCCACTGTCCGCGTCACAAAAGGGCAGGTATGGAAGAACCGACCTGCATACAGAAAGCCCAGGATCTACAGAATGTATAGAAGCCCTGATGTCCCTAAGGGATGTGAGGGCCCATGTAAGGTCCAATCTTTCGATGCGAAGAACGACATTGGACATATGGGCAAGGTAATATGTCTGTATGACGTTACCCGTGGTATTGGGCTTACTCATCGAGTTGGCAAGCGTTTCTGTGTGAAGTCACTTTATTTTGTCGGGAAGATCTGGATGGATGAAAATATTAAGGTTAAGAATCATACTAACACCGTTTTATTCTGGATAGTTAGGGATCGCAGTCCTACTGGAACGCCTTATGATTTTCAGCAGGTCTTTAATGTATATGATAATGAACCCAGCACTGCTACTGTGAAGAACGACCAGCGTGATCGTTTCCAGGTTATAAGGAGGTTCCAGGCAACAGTTACTGGTGGACAATATGCAGCTAAGGAGCAGGCGATTATTAGAAAGTTTTATCGTGTTAATAATTATGTAGTTTATAATCACCAGGAAGCTGGGAAGTATGAGAACCATACTGAAAATGCTTTGTTGTTATATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACTTTGAAAGTCAGGAGTTATTTCTATGACTCAGTGACGAATTAA |
| Protein Sequence | MSKRPADILISTPVSKVRRRLNFDSPYNSRAAVPTVRVTKGQVWKNRPAYRKPRIYRMYRSPDVPKGCEGPCKVQSFDAKNDIGHMGKVICLYDVTRGIGLTHRVGKRFCVKSLYFVGKIWMDENIKVKNHTNTVLFWIVRDRSPTGTPYDFQQVFNVYDNEPSTATVKNDQRDRFQVIRRFQATVTGGQYAAKEQAIIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
| NCBI Accession | NP_049916.1 |
|---|---|
| Location | 1200-1604 |
| Gene Name | AC3 |
| Protein Name | AC3 protein |
| Coding Region | ATGGATTCACGCACCGGGGAACTACTCACTGCAACTCAATCAGAGAGTGGCGTATATATCTGGACGGTCAAAAATCCCCTATATTTCAAGATAACCAGGCACCTAGAGAGACCATTCCAGAGGAACCACGACATAATCACGTTACAAATCCAGTTCAACTACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAGCCTGCAAAATCTGGACTCATTTACATCCTCAGACCTCGCGTTTCTTAAGAGTATTTAAATATCAATGTAATAAATATTTAAATAGATTAGGCGTGATTAGTATAAACAATGTAATTAGGGCAATATCTCATGTATTGTACAATGTATTAGAAGGAACAATTGATGTAATTGAAGAACATGATATAAAATTTAATATTTATTAA |
| Protein Sequence | MDSRTGELLTATQSESGVYIWTVKNPLYFKITRHLERPFQRNHDIITLQIQFNYNLRKALGIHKCFLACKIWTHLHPQTSRFLRVFKYQCNKYLNRLGVISINNVIRAISHVLYNVLEGTIDVIEEHDIKFNIY |
| NCBI Accession | NP_049917.1 |
|---|---|
| Location | 1345-1755 |
| Gene Name | AC2 |
| Protein Name | AC2 protein |
| Coding Region | ATGCGATCTTCGTCACCCTCGAAGGCCCACTGTACTCAGGTACCTATCAAGGTGCAACACCGAATAGCCAAGAGGACAACCAGACGACGGAGAGTTGATCAACCTTGTGGATGTTCGTACTTGTGCATAGCTGTCACATATTGTCACAATAATGGATTCACGCACCGGGGAACTACTCACTGCAACTCAATCAGAGAGTGGCGTATATATCTGGACGGTCAAAAATCCCCTATATTTCAAGATAACCAGGCACCTAGAGAGACCATTCCAGAGGAACCACGACATAATCACGTTACAAATCCAGTTCAACTACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAGCCTGCAAAATCTGGACTCATTTACATCCTCAGACCTCGCGTTTCTTAAGAGTATTTAA |
| Protein Sequence | MRSSSPSKAHCTQVPIKVQHRIAKRTTRRRRVDQPCGCSYLCIAVTYCHNNGFTHRGTTHCNSIREWRIYLDGQKSPIFQDNQAPRETIPEEPRHNHVTNPVQLQPEESVGDTQMFSSLQNLDSFTSSDLAFLKSI |
| NCBI Accession | NP_049918.1 |
|---|---|
| Location | 1658-2743 |
| Gene Name | AC1 |
| Protein Name | rep protein |
| Coding Region | ATGCCTCCTTCAAAGAAATTTCTAATAAATGCCAAGAATTATTTCCTCACATACCCACACTGCTCACTCACCAAAGAAGAAGAAGCACTCTCCCAAATATTAAACCTATCAACTCCAACTAATAAATTAATCATCAGAATCTGCAGGGAACTCCATGAAGATGGGACTCCTCACCTGCATCTCCTCATCCAATTCGAAGGAAAATTCAAATGCCAAAATAACCGATTCTTCGATCTCACATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAACAGATGTTAAAGCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAATTTTCCAAATCGATGGAAGATCGGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAGGCTTCGGCCCTCAATATACTGAGGGAAAAGGCCCCTAAAGATTTTGTTTTACAATTTCACAATTTAAATTCTAATTTAGATAGGATTTTTACTCCTCCAATAGAGGAATATATTTCTCCCTTTTCTTCTTCTTCTTTCAATCAAGTTCCCGAAGAACTTGAAGAGTGGGCTTGTAATAATGTTCTCAGTCGTGCGCGGCCATTGAGACCAATAACTATAGTCATTGAGGGTGATAGCAGAACAGGGAAGACGATGTGGGCTAGGTCATTGGGACCACATAATTATCTGTGTGGCCATTTAGATTTAAGTCCAAAAGTGTATAATAATGATGCGTGGTTCAACGTCATCGATGACGTCGATCCGCATTATCTAAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAATACGGCAAACCAGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCTGGACCAAACTCCAGCTATAAAGAGTACTTGGAAGAGGAAAAGAACTCCGCACTTAGAAACTGGGCTATAAAAAATGCGATCTTCGTCACCCTCGAAGGCCCACTGTACTCAGGTACCTATCAAGGTGCAACACCGAATAGCCAAGAGGACAACCAGACGACGGAGAGTTGA |
| Protein Sequence | MPPSKKFLINAKNYFLTYPHCSLTKEEEALSQILNLSTPTNKLIIRICRELHEDGTPHLHLLIQFEGKFKCQNNRFFDLTSPTRSAHFHPNIQGAKSSTDVKAYMEKDGDVLDHGIFQIDGRSARGGCQSANDAYAEAINSGSKASALNILREKAPKDFVLQFHNLNSNLDRIFTPPIEEYISPFSSSSFNQVPEELEEWACNNVLSRARPLRPITIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYNNDAWFNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLEEEKNSALRNWAIKNAIFVTLEGPLYSGTYQGATPNSQEDNQTTES |
| NCBI Accession | NP_049919.1 |
|---|---|
| Location | 2290-2589 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAGATGGGACTCCTCACCTGCATCTCCTCATCCAATTCGAAGGAAAATTCAAATGCCAAAATAACCGATTCTTCGATCTCACATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAACAGATGTTAAAGCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAATTTTCCAAATCGATGGAAGATCGGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAGGCTTCGGCCCTCAATATACTGA |
| Protein Sequence | MKMGLLTCISSSNSKENSNAKITDSSISHPQPGQHISIRTFRELKAQQMLKHTWKKTETCLIMEFSKSMEDRLEEVANLPTTHMPRQSIQGPRLRPSIY |
| NCBI Accession | NP_049920.1 |
|---|---|
| Location | 346-1062 |
| Gene Name | BV1 |
| Protein Name | BV1 protein |
| Coding Region | ATGAACCCCTCCTCCGGCGGTTCCTATGTCCGTTATAATTATCCCTACGCCAATTACTTTGGCAGGAGGGTTGGCAACCGTGTATATGGAATGCCCTTTGGTAGTACCACCTCTGTCCGGCGACCAATTAGAAGTACAGTTCGGAGGAATTTATTTTCCGACCAGTCTTCTTCAGGTAACAAGAGCCGTAAAACTATTGAGGAAGTGCATGATGGTTCTGACTATCTTCTTGGTAATAACACTTCGAAGGTGTCGTATATTAGTTATCCTCCTCTTAGTCGGTCGGAATTTGGTAACCGTCTTGACGCATTTGTCAAGATTTTGGGATTTAATGTTTCTGGTTCAGTTGCTGTGAGACATCTGGAACAGCGTGCCACTGGAGCAAGTCAAGGTATCCATGGCATATATTGCACAGCTGTTGTACGTGACAAGCGACCATGTCAGTTCTCCGCTGTGGAGCCTATTGTGCCATTTCCGGAGTTATTTGGTCTGGAGAAGATGGCATGCTCCTCATTACGTGTTAGGGATATTCATAGGAGTAGGTTTAGTCCAGTTTACCAGAAGAAAGTTGTTGTTAACAGCTCCCTTCCGACCCATGTTTTTAAGTTTAATATCCTGTTAAGTTTAATAGGTTTCCGTTCTGGGTGTCATTTAAAGATACCTCTGATTCTGAGCCAAGTGGCCGGTACAGCAACGTATCTAAGAATGCTCTCATAG |
| Protein Sequence | MNPSSGGSYVRYNYPYANYFGRRVGNRVYGMPFGSTTSVRRPIRSTVRRNLFSDQSSSGNKSRKTIEEVHDGSDYLLGNNTSKVSYISYPPLSRSEFGNRLDAFVKILGFNVSGSVAVRHLEQRATGASQGIHGIYCTAVVRDKRPCQFSAVEPIVPFPELFGLEKMACSSLRVRDIHRSRFSPVYQKKVVVNSSLPTHVFKFNILLSLIGFRSGCHLKIPLILSQVAGTATYLRMLS |
| NCBI Accession | NP_049921.1 |
|---|---|
| Location | 371-700 |
| Gene Name | BV2 |
| Protein Name | BV2 protein |
| Coding Region | ATGTCCGTTATAATTATCCCTACGCCAATTACTTTGGCAGGAGGGTTGGCAACCGTGTATATGGAATGCCCTTTGGTAGTACCACCTCTGTCCGGCGACCAATTAGAAGTACAGTTCGGAGGAATTTATTTTCCGACCAGTCTTCTTCAGGTAACAAGAGCCGTAAAACTATTGAGGAAGTGCATGATGGTTCTGACTATCTTCTTGGTAATAACACTTCGAAGGTGTCGTATATTAGTTATCCTCCTCTTAGTCGGTCGGAATTTGGTAACCGTCTTGACGCATTTGTCAAGATTTTGGGATTTAATGTTTCTGGTTCAGTTGCTGTGA |
| Protein Sequence | MSVIIIPTPITLAGGLATVYMECPLVVPPLSGDQLEVQFGGIYFPTSLLQVTRAVKLLRKCMMVLTIFLVITLRRCRILVILLLVGRNLVTVLTHLSRFWDLMFLVQLL |
| NCBI Accession | NP_049922.1 |
|---|---|
| Location | 1144-1857 |
| Gene Name | BC1 |
| Protein Name | BC1 protein |
| Coding Region | ATGCTTTTGGGAAAGTGTCTCAGAATTGACCACGTCATCCTCCAATACAGGAACCAAGTCCCTGTAAATGCAACTGGTCATGTGGTCATAGAAATGCACGACACAAGGTTACACGAAGGTGACTCGAAGCAGGCTGAGTTCACTATACCCATAGGGTGCAACTGCAACATACACTACTACTCCTCTTCCTATTTCTCCCCCAAAGACCCAAATCCATGGAGAGTACTGTACCGAGTGGACGACACTAACGTGGTAAATGGAGTTCACTTCTGCAGGATGCAAGGAAAATTAAAGATGTCATCTGCAAAACAGTCCTCGGAGATAACATTTAAATCCCCCAAGATTGAAATACTGTCAAAGGCGTATAACATGACCCACATAGACTTCTGGCATGTGCCTCAATCCAAGGTATCAAGGAAACCAGTCCAAGCCCTATCAAACATGAGGTCACAGTCTTCCAGATACACTACAGATGCCATTCCACAAGGGCATACTTGGGCTTCCGCAAGCACAGTCGTGAACCAATTGAACGAGGAATACCCATATAGACATTTGCATCAGCTACAAGATGCAACTCTCGATCCAGGCCCTTCGGCGTCGGAGGTTGTTGCAGGAAGCAACAAAGTAAATGACGATGTAATTAATATTATTAAAAAAACAGTTGAACTATGTATGGAAGGGAGTAATGTATCTTCAAATGCAAAGCAAATATAA |
| Protein Sequence | MLLGKCLRIDHVILQYRNQVPVNATGHVVIEMHDTRLHEGDSKQAEFTIPIGCNCNIHYYSSSYFSPKDPNPWRVLYRVDDTNVVNGVHFCRMQGKLKMSSAKQSSEITFKSPKIEILSKAYNMTHIDFWHVPQSKVSRKPVQALSNMRSQSSRYTTDAIPQGHTWASASTVVNQLNEEYPYRHLHQLQDATLDPGPSASEVVAGSNKVNDDVINIIKKTVELCMEGSNVSSNAKQI |
References More References in PubMed
| 1 |
Chang HH, et al. Plant Dis. 2023 Jul;107(7):2002-2008. doi: 10.1094/PDIS-09-22-2164-RE. Epub 2023 Jun 21. PMID: 36480735 |
|---|---|
| 2 |
Li WH, et al. Insects. 2021 Feb 20;12(2):181. doi: 10.3390/insects12020181. PMID: 33672688 |
| 3 |
Díaz-Pendón JA, et al. Mol Plant Pathol. 2010 Jul;11(4):441-50. doi: 10.1111/j.1364-3703.2010.00618.x. PMID: 20618703 |
| 4 |
Prabhakar SS, et al. Insects. 2025 Jul 15;16(7):721. doi: 10.3390/insects16070721. PMID: 40725351 |
| 5 |
First Report of Tomato yellow leaf curl Thailand virus in Taiwan. Jan FJ, et al. Plant Dis. 2007 Oct;91(10):1363. doi: 10.1094/PDIS-91-10-1363A. PMID: 30780543 |
| 6 |
Chang HH, et al. Methods Mol Biol. 2024;2844:239-245. doi: 10.1007/978-1-0716-4063-0_16. PMID: 39068344 |
| 7 |
Tsai WA, et al. Front Plant Sci. 2019 Jul 12;10:906. doi: 10.3389/fpls.2019.00906. eCollection 2019. PMID: 31354773 |
| 8 |
Fungal F8-Culture Filtrate Induces Tomato Resistance against Tomato Yellow Leaf Curl Thailand Virus. Chiu YS, et al. Viruses. 2021 Jul 23;13(8):1434. doi: 10.3390/v13081434. PMID: 34452299 |
| 9 |
Tzean Y, et al. Mol Plant Microbe Interact. 2020 Jan;33(1):87-97. doi: 10.1094/MPMI-06-19-0158-R. Epub 2019 Nov 21. PMID: 31638467 |
| 10 |
Chiu CW, et al. Plant Cell. 2022 Apr 26;34(5):1804-1821. doi: 10.1093/plcell/koac019. PMID: 35080617 |