Tomato yellow leaf curl Sardinia virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000844945.1 |
| Release date | 2015/2/12 |
| Submitter | Noris,E., Vaira,A.M., Caciagli,P., Masenga,V., Gronenborn,B., Accotto,G.P., Laufs,J., Schumacher,S., Geisler,N., Jupin,I., Desbiez,C., David,C., Mettouchi,A., Traut,W., Heyraud,F., Matzeit,V., Rogers,S.G., Schell,J., Kheyr-Pour,A., Bendahmane,M., Crespi,S. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
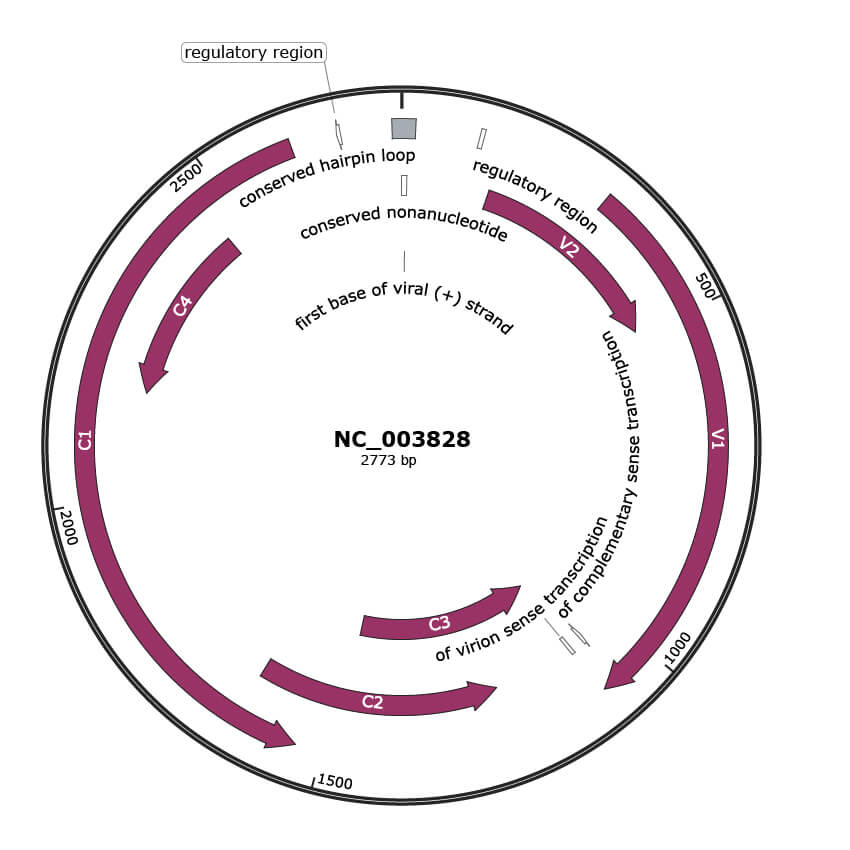
JBrowse
Genome
NC_003828
Gene Information
| NCBI Accession | NP_620737.1 |
|---|---|
| Location | 147-494 |
| Gene Name | V2 |
| Protein Name | V2 protein |
| Coding Region | ATGTGGGATCCATTATTAAATGAATTTCCTGATTCAGTCCATGGTCTCCGATGCATGCTCGCAATTAAATATTTGCAGCTAGTTGAAGAAACCTACGAACCTAATACCCTTGGTCACGACTTAATTAGGGATCTCATCTCCGTCATTCGTGCTCGTGACTATGCCGAAGCGAACCGGCGATATACTAATTTCAACGCCCGTCTCGAAGGTTCGTCGAAGACTGAACTTCGACAGCCCGTATACCAGCCGTGCTGCTGCCCCCACTGTCCAAGGCATCAAGCGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCGCGGATGTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPDSVHGLRCMLAIKYLQLVEETYEPNTLGHDLIRDLISVIRARDYAEANRRYTNFNARLEGSSKTELRQPVYQPCCCPHCPRHQASIMDLQAHVSKAADVQNVQKP |
| NCBI Accession | NP_620738.1 |
|---|---|
| Location | 307-1080 |
| Gene Name | V1 |
| Protein Name | capsid protein |
| Coding Region | ATGCCGAAGCGAACCGGCGATATACTAATTTCAACGCCCGTCTCGAAGGTTCGTCGAAGACTGAACTTCGACAGCCCGTATACCAGCCGTGCTGCTGCCCCCACTGTCCAAGGCATCAAGCGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCGCGGATGTACAGAATGTACAGAAGCCCTGATGTACCTCCGGGTTGTGAAGGTCCCTGTAAAGTGCAGTCGTACGAGCAGCGTGATGACGTCAAGCATACCGGTGTTGTGCGTTGTGTTAGTGATGTAACTAGGGGTTCTGGTATTACTCATAGAGTTGGTAAACGTTTTTGTATCAAGTCAATTTATATATTAGGAAAGATTTGGATGGATGAAAACATAAAAAAACAAAATCATACTAACCAAGTGATGTTTTTCCTTGTTCGAGACCGAAGGCCTTATGGAACTAGTCCTATGGATTTTGGTCAAGTTTTTAACATGTTTGATAATGAACCCAGTACTGCTACGGTGAAGAACGACTTACGGGATAGGTATCAAGTAATGAGGAAGTTTCATGCTACGGTTGTTGGAGGTCCGTCAGGGATGAAGGAGCAGTGTTTGCTGAAGAGATTTTTTAAAATTAATACCCATGTAGTTTATAATCACCAAGAGCAGGCGAAGTATGAAAATCATACTGAGAATGCCTTGTTATTGTATATGGCTTGTACTCATGCTTCTAACCCAGTGTACGCTACGTTGAAAATACGTATTTATTTTTATGATGCTGTAACAAATTAA |
| Protein Sequence | MPKRTGDILISTPVSKVRRRLNFDSPYTSRAAAPTVQGIKRRSWTYRPMYRKPRMYRMYRSPDVPPGCEGPCKVQSYEQRDDVKHTGVVRCVSDVTRGSGITHRVGKRFCIKSIYILGKIWMDENIKKQNHTNQVMFFLVRDRRPYGTSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMRKFHATVVGGPSGMKEQCLLKRFFKINTHVVYNHQEQAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
| NCBI Accession | NP_620739.1 |
|---|---|
| Location | 1077-1481 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTTACGCACAGGGGAGTACATCACTGCGCATCAAGCAACGAGTGGCGTTTATACCTTCGGGATAACAAATCCCCTATATTTCACGATAACCAGACACAATCAGAACCCATTCAACAACAAATACAACACACTAACATTCCAAATCAGATTCAACCACAACTTGAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCCACATCTGGACGACCTTACAGTCTCCGACTGGTCATTTTTTAAGAGTCTTTAAATATCAAGTCTGTAAATATTTGAATAATTTGGGTGTAATTTCTTTAAATAATGTTGTTAGAGCAGTTGATTATGTATTGTTTCATGTATTTGAAAGAACAATTGATGTAACTGAAAATCATGAAATAAAATTTAATTTTTATTAA |
| Protein Sequence | MDLRTGEYITAHQATSGVYTFGITNPLYFTITRHNQNPFNNKYNTLTFQIRFNHNLRKELGIHKCFLNFHIWTTLQSPTGHFLRVFKYQVCKYLNNLGVISLNNVVRAVDYVLFHVFERTIDVTENHEIKFNFY |
| NCBI Accession | NP_620740.1 |
|---|---|
| Location | 1222-1629 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCAATCTTCGTCACCATCCACCAGCCATTGTTCGCAGATACCAATCAAAATACAACATCACATCGCCAAGAAGAGGCAAGTGAGGCGTAGAAGGGTAGATCTGGACTGTGGCTGCTCTTATTACATACACTTAGACTGCATAAATCATGGATTTACGCACAGGGGAGTACATCACTGCGCATCAAGCAACGAGTGGCGTTTATACCTTCGGGATAACAAATCCCCTATATTTCACGATAACCAGACACAATCAGAACCCATTCAACAACAAATACAACACACTAACATTCCAAATCAGATTCAACCACAACTTGAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCCACATCTGGACGACCTTACAGTCTCCGACTGGTCATTTTTTAAGAGTCTTTAA |
| Protein Sequence | MQSSSPSTSHCSQIPIKIQHHIAKKRQVRRRRVDLDCGCSYYIHLDCINHGFTHRGVHHCASSNEWRLYLRDNKSPIFHDNQTQSEPIQQQIQHTNIPNQIQPQLEEGTGDSQMFSQLPHLDDLTVSDWSFFKSL |
| NCBI Accession | NP_620741.1 |
|---|---|
| Location | 1538-2617 |
| Gene Name | C1 |
| Protein Name | Rep protein |
| Coding Region | ATGCCAAGATCAGGTCGTTTTAGTATCAAGGCTAAAAATTATTTCCTTACATATCCCAAATGTGATTTAACAAAAGAAAATGCACTTTCCCAAATAACAAACCTACAAACACCCACAAACAAATTATTCATCAAAATTTGCAGAGAACTACATGAAAATGGGGAACCTCATCTCCATATTCTCATCCAATTCGAAGGAAAATACAATTGTACCAATCAACGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGATGTTCTTGAATGGGGTACTTTCCAGATCGACGGACGATCTGCTAGGGGAGGACAACAGACAGCCAACGACGCTTACGCAAAGGCAATTAACGCAGGAAGTAAGTCGCAGGCTCTTGATGTAATTAAAGAATTAGCGCCTAGAGATTACGTTCTACATTTTCATAATATAAATAGTAATTTAGATAAGGTTTTCCAGGTGCCTCCGGCACCTTATGTTTCTCCTTTTTTATCTTCTTCTTTCGATCAAGTTCCTGATGAACTTGAACACTGGGTTTCCGAGAACGTCATGGATGCCGCTGCGCGGCCTTGGAGACCGGTGAGTATAGTGATTGAGGGTGACAGCCGGACAGGAAAGACAACGTGGGCCCGTTCATTAGGCCCACATAATTATTTGTGCGGCCATCTTGACCTCAGTCAAAAAGTATACAGCAATAATGCTTGGTATAACGTCATTGATGACGTCGACCCGCATTATTTAAAACACTTTAAAGAATTTATGGGGGCCCAAAGAGATTGGCAAAGCAACACAAAGTATGGCAAGCCCATTCAAATTAAAGGAGGCATTCCCACTATCTTCCTATGCAATCCAGGCCCACAATCATCATTTAAAGAATATCTCGACGAAGAAAAAAATCAAGCATTAAAAAACTGGGCTACTAAGAATGCAATCTTCGTCACCATCCACCAGCCATTGTTCGCAGATACCAATCAAAATACAACATCACATCGCCAAGAAGAGGCAAGTGAGGCGTAG |
| Protein Sequence | MPRSGRFSIKAKNYFLTYPKCDLTKENALSQITNLQTPTNKLFIKICRELHENGEPHLHILIQFEGKYNCTNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDVLEWGTFQIDGRSARGGQQTANDAYAKAINAGSKSQALDVIKELAPRDYVLHFHNINSNLDKVFQVPPAPYVSPFLSSSFDQVPDELEHWVSENVMDAAARPWRPVSIVIEGDSRTGKTTWARSLGPHNYLCGHLDLSQKVYSNNAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPQSSFKEYLDEEKNQALKNWATKNAIFVTIHQPLFADTNQNTTSHRQEEASEA |
| NCBI Accession | NP_620742.1 |
|---|---|
| Location | 2170-2466 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGAAAATGGGGAACCTCATCTCCATATTCTCATCCAATTCGAAGGAAAATACAATTGTACCAATCAACGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGATGTTCTTGAATGGGGTACTTTCCAGATCGACGGACGATCTGCTAGGGGAGGACAACAGACAGCCAACGACGCTTACGCAAAGGCAATTAACGCAGGAAGTAAGTCGCAGGCTCTTGATGTAA |
| Protein Sequence | MKMGNLISIFSSNSKENTIVPINDSSTWYPQPGQHISIRTFRELNRAPTSSPISTRTEMFLNGVLSRSTDDLLGEDNRQPTTLTQRQLTQEVSRRLLM |
References More References in PubMed
| 1 |
Tomato Yellow Leaf Curl Sardinia Virus Increases Drought Tolerance of Tomato. Sacco Botto C, et al. Int J Mol Sci. 2023 Feb 2;24(3):2893. doi: 10.3390/ijms24032893. PMID: 36769211 |
|---|---|
| 2 |
Refining the emergence scenario of the invasive recombinant Tomato yellow leaf curl virus -IS76. Jammes M, et al. Virology. 2023 Jan;578:71-80. doi: 10.1016/j.virol.2022.11.006. Epub 2022 Nov 22. PMID: 36473279 |
| 3 |
Fortes IM, et al. Phytopathology. 2023 Jul;113(7):1347-1359. doi: 10.1094/PHYTO-09-22-0334-R. Epub 2023 Aug 29. PMID: 36690608 |
| 4 |
Pagliarani C, et al. Hortic Res. 2022 Jul 27;9:uhac164. doi: 10.1093/hr/uhac164. eCollection 2022. PMID: 36324645 |
| 5 |
Díaz-Pendón JA, et al. Viruses. 2019 Jan 9;11(1):45. doi: 10.3390/v11010045. PMID: 30634476 |
| 6 |
Díaz-Pendón JA, et al. Mol Plant Pathol. 2010 Jul;11(4):441-50. doi: 10.1111/j.1364-3703.2010.00618.x. PMID: 20618703 |
| 7 |
A New Tomato yellow leaf curl virus Strain in Southern Spain. Morilla G, et al. Plant Dis. 2003 Aug;87(8):1004. doi: 10.1094/PDIS.2003.87.8.1004B. PMID: 30812778 |
| 8 |
No Evidence for Seed Transmission of Tomato Yellow Leaf Curl Sardinia Virus in Tomato. Tabein S, et al. Cells. 2021 Jul 2;10(7):1673. doi: 10.3390/cells10071673. PMID: 34359841 |
| 9 |
Shen X, et al. Front Plant Sci. 2020 Sep 10;11:545306. doi: 10.3389/fpls.2020.545306. eCollection 2020. PMID: 33013967 |
| 10 |
Leibman D, et al. Arch Virol. 2015 Nov;160(11):2727-39. doi: 10.1007/s00705-015-2551-7. Epub 2015 Aug 9. PMID: 26255053 |