Tomato yellow leaf curl Malaga virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000842905.1 |
| Isolate | Spain |
| Release date | 2015/2/12 |
| Submitter | Monci,F., Sanchez-Campos,S., Navas-Castillo,J., Moriones,E. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
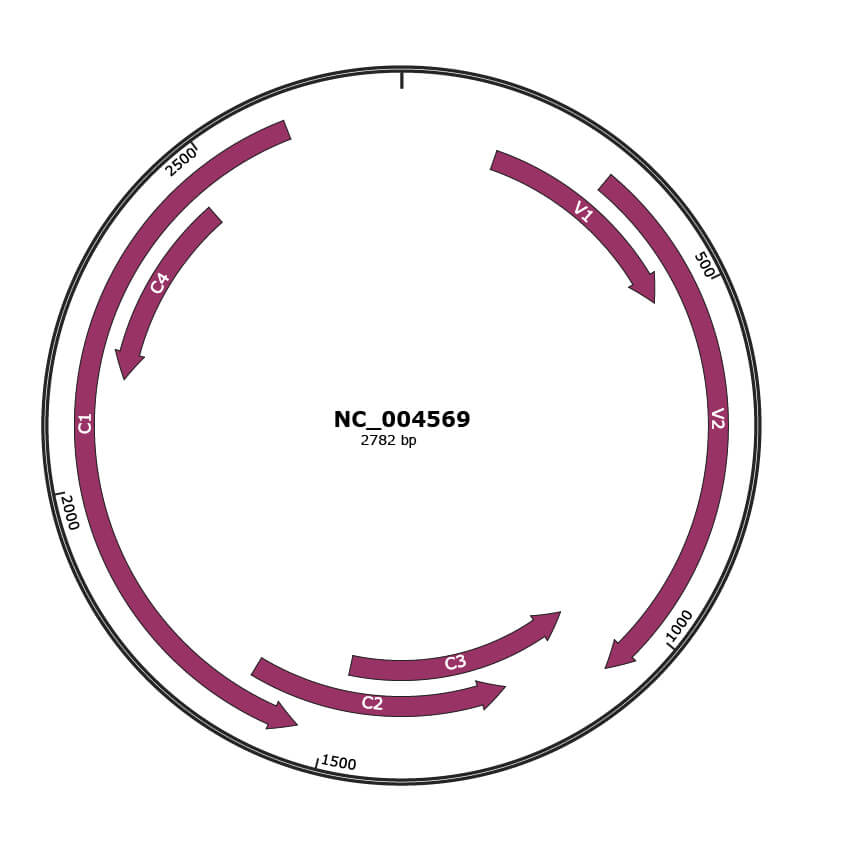
JBrowse
Genome
NC_004569
Gene Information
| NCBI Accession | NP_786876.1 |
|---|---|
| Location | 149-496 |
| Gene Name | V1 |
| Protein Name | precoat protein V1 |
| Coding Region | ATGTGGGATCCTTTATTAAATGAATTTCCAGATTCAGTTCATGGTCTCCGTTGTATGCTTGCAATAAAATATTTGCAGCTAGTTGAAGAAACCTATGAACCCAATACTCTGGGTCATGATCTAATTAGGGATCTCATTTCCGTCATTCGTGCTCGTGACTATGCCGAAGCGAACAGGCGATATACTAATTTCAACGCCCGTTTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCGTATACCAGCCGTGCTGCTGCCCCCACTGTCCAAGGCATCAAGCGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCGCGGATGTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPDSVHGLRCMLAIKYLQLVEETYEPNTLGHDLIRDLISVIRARDYAEANRRYTNFNARFEGSSKTELRQPVYQPCCCPHCPRHQASIMDLQAHVSKAADVQNVQKP |
| NCBI Accession | NP_786877.1 |
|---|---|
| Location | 309-1082 |
| Gene Name | V2 |
| Protein Name | coat protein V2 |
| Coding Region | ATGCCGAAGCGAACAGGCGATATACTAATTTCAACGCCCGTTTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCGTATACCAGCCGTGCTGCTGCCCCCACTGTCCAAGGCATCAAGCGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCGCGGATGTACAGAATGTACAGAAGCCCTGATGTCCCCTTTGGTTGTGAAGGTCCTTGTAAAGTCCAGTCGTATGAGCAGCGTGACGACGTCAAGCATACCGGTGTTGTTCGTTGTGTTAGTGATGTAACTAGGGGTTCTGGTATTACACATAGAGTAGGTAAACGGTTTTGTATTAAGTCAATCTATATTTTAGGGAAGATTTGGATGGATGAAAATATAAAAAAACAAAATCATACTAACCAGGTCATATTCTTTTTAGTACGAGACCGAAGGCCGTATGGAACTAGTCCTATGGATTTTGGTCAAGTTTTTAACATGTTTGATAATGAACCTAGTACGGCTACTGTGAAGAACGATTTAAGGGATAGGTACCAAGTAATGAGGAAGTTCCATGCCACGGTGGTAGGTGGTCCGTCAGGGATGAAGGAGCAGTGTCTGTTGAAGAGGTTTTTTAAAGTTAATACCCATGTAGTTTATAATCATCAAGAGCAGGCGAAGTATGAAAACCATACTGAGAATGCGTTGTTGTTGTATATGGCATGTACTCATGCTTCTAACCCAGTGTATGCTACGTTGAAAATACGTATCTATTTTTATGATGCTGTAACAAATTAA |
| Protein Sequence | MPKRTGDILISTPVSKVRRKLNFDSPYTSRAAAPTVQGIKRRSWTYRPMYRKPRMYRMYRSPDVPFGCEGPCKVQSYEQRDDVKHTGVVRCVSDVTRGSGITHRVGKRFCIKSIYILGKIWMDENIKKQNHTNQVIFFLVRDRRPYGTSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMRKFHATVVGGPSGMKEQCLLKRFFKVNTHVVYNHQEQAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
| NCBI Accession | NP_786878.1 |
|---|---|
| Location | 1079-1483 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCTCCTCAGGCAGAGAATGGCGTTTTTATCTGGGAGATAAACAATCCCCTCTATTTCAAGATAACAGAACACAGCCAGAGGCCATTTCTAATGAACCACGACATCATTTCCATTCAGATAAGATTCAACCACAACATCAGGAAGGTATTGGGGATTCACAAATGTTTTCTCAACTTCCGCATCTGGACGACATTACAGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAGACATCAAGTTCTTAAGTATTTAGATAGTATTGGTGTAATTTCAATTAACAATGTAATCAGAGCAGTTGATCATGTATTGTATGATGTACTTGAAAACACAATAAATGTAATTGAACAACATGAAATAAAATACAATCTTTATTAA |
| Protein Sequence | MDSRTGELITAPQAENGVFIWEINNPLYFKITEHSQRPFLMNHDIISIQIRFNHNIRKVLGIHKCFLNFRIWTTLQPQTGRFLRVFRHQVLKYLDSIGVISINNVIRAVDHVLYDVLENTINVIEQHEIKYNLY |
| NCBI Accession | NP_786879.1 |
|---|---|
| Location | 1224-1631 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCAACCTTCGTCACCCTCTACGAGCCACTGTTCGCAAGTATCAATCAAGGTCCAACACAAGATAGCCAAGAAGAAACCAATAAGGCGTAAGCGTATAGACCTAGACTGTGGCTGCTCATACTACCTCCACCTCAACTGCAACAATCATGGATTCACGCACAGGGGAACTCATCACTGCTCCTCAGGCAGAGAATGGCGTTTTTATCTGGGAGATAAACAATCCCCTCTATTTCAAGATAACAGAACACAGCCAGAGGCCATTTCTAATGAACCACGACATCATTTCCATTCAGATAAGATTCAACCACAACATCAGGAAGGTATTGGGGATTCACAAATGTTTTCTCAACTTCCGCATCTGGACGACATTACAGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAG |
| Protein Sequence | MQPSSPSTSHCSQVSIKVQHKIAKKKPIRRKRIDLDCGCSYYLHLNCNNHGFTHRGTHHCSSGREWRFYLGDKQSPLFQDNRTQPEAISNEPRHHFHSDKIQPQHQEGIGDSQMFSQLPHLDDITASDWSFLKSI |
| NCBI Accession | NP_786880.1 |
|---|---|
| Location | 1540-2619 |
| Gene Name | C1 |
| Protein Name | replication associated protein C1 |
| Coding Region | ATGGCTCCCCCTAAGCGCTTCCAAATAAATTGCAAAAATTATTTCCTCACATATCCTAAGTGCTCCTTAACGAAAGAAGAAGCACTTTCCCAGTTAAAAAACCTAGAAACCCCAACAAATAAAAAATACATCAAAGTTTGCAGAGAACTCCACGAGAATGGGGAACCACATCTCCATGTGCTTATCCAATTTGAAGGGAAATTCAAGTGCCAAAATCAGCGATTCTTCGACCTGGTATCCCCAAGCAGGGCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGTTCAGATGTCAAGTCTTATGTCGATAAGGACGGAGACACCGTCGACTGGGGTGAGTTTCAGATCGACGGACGATCTGCACGTGGGGGTCAGCAGTCAGCCAATGACGCTTACGCCGCAGCTCTTAACTCAGGCAGTAAGTCAGAGGCTCTTAGAATCATTAAAGAATTAATACCGAAAGATTATATTTTACAATTTCATAATTTAAATAGTAATTTAGATAGAATTTTTCAGGAGCCTCCGGCTCCTTATATTTCTCCCTTTTTATCTTCATCTTTTAATCAAGTTCCAGATGAACTTGAAGTATGGGTGTCCGAGAACGTCGTGTCTTCCGCTGCGCGGCCATGGAGACCTAATAGTATTGTCATTGAGGGTGATAGCAGAACAGGCAAAACAATGTGGGCCAGGTCTCTAGGCCCACATAATTATTTATGTGGACATCTAGACCTAAGCCCAAAGGTATACAGTAATGATGCATGGTACAACGTCATTGATGACGTAGACCCGCATTATTTAAAGCACTTCAAGGAATTCATGGGGGCCCAGAGGGACTGGCAAAGCAACACAAAGTACGGGAAGCCCATTCAAATTAAAGGGGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCTACCTCCTCATATAGGGAATATCTAGACGAAGAAAAAAACATATCCTTGAAAAATTGGGCTCTCAAGAATGCAACCTTCGTCACCCTCTACGAGCCACTGTTCGCAAGTATCAATCAAGGTCCAACACAAGATAGCCAAGAAGAAACCAATAAGGCGTAA |
| Protein Sequence | MAPPKRFQINCKNYFLTYPKCSLTKEEALSQLKNLETPTNKKYIKVCRELHENGEPHLHVLIQFEGKFKCQNQRFFDLVSPSRAAHFHPNIQGAKSSSDVKSYVDKDGDTVDWGEFQIDGRSARGGQQSANDAYAAALNSGSKSEALRIIKELIPKDYILQFHNLNSNLDRIFQEPPAPYISPFLSSSFNQVPDELEVWVSENVVSSAARPWRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYREYLDEEKNISLKNWALKNATFVTLYEPLFASINQGPTQDSQEETNKA |
| NCBI Accession | NP_786881.1 |
|---|---|
| Location | 2160-2462 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCACATCTCCATGTGCTTATCCAATTTGAAGGGAAATTCAAGTGCCAAAATCAGCGATTCTTCGACCTGGTATCCCCAAGCAGGGCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGTTCAGATGTCAAGTCTTATGTCGATAAGGACGGAGACACCGTCGACTGGGGTGAGTTTCAGATCGACGGACGATCTGCACGTGGGGGTCAGCAGTCAGCCAATGACGCTTACGCCGCAGCTCTTAACTCAGGCAGTAAGTCAGAGGCTCTTAGAATCATTAAAGAATTAA |
| Protein Sequence | MGNHISMCLSNLKGNSSAKISDSSTWYPQAGQHISIQTFRELNPVQMSSLMSIRTETPSTGVSFRSTDDLHVGVSSQPMTLTPQLLTQAVSQRLLESLKN |
References More References in PubMed
| 1 |
Tomato yellow leaf curl virus, an emerging virus complex causing epidemics worldwide. Moriones E, et al. Virus Res. 2000 Nov;71(1-2):123-34. doi: 10.1016/s0168-1702(00)00193-3. PMID: 11137167 |
|---|---|
| 2 |
Transcriptional and epigenetic changes during tomato yellow leaf curl virus infection in tomato. Romero-Rodríguez B, et al. BMC Plant Biol. 2023 Dec 18;23(1):651. doi: 10.1186/s12870-023-04534-y. PMID: 38110861 |
| 3 |
Fortes IM, et al. Phytopathology. 2023 Jul;113(7):1347-1359. doi: 10.1094/PHYTO-09-22-0334-R. Epub 2023 Aug 29. PMID: 36690608 |
| 4 |
Díaz-Pendón JA, et al. Mol Plant Pathol. 2010 Jul;11(4):441-50. doi: 10.1111/j.1364-3703.2010.00618.x. PMID: 20618703 |
| 5 |
The Global Dimension of Tomato Yellow Leaf Curl Disease: Current Status and Breeding Perspectives. Yan Z, et al. Microorganisms. 2021 Apr 1;9(4):740. doi: 10.3390/microorganisms9040740. PMID: 33916319 |
| 6 |
Gaertner NF, et al. J Virol. 2025 Dec 23;99(12):e0128625. doi: 10.1128/jvi.01286-25. Epub 2025 Nov 10. PMID: 41211974 |
| 7 |
Díaz-Pendón JA, et al. Viruses. 2019 Jan 9;11(1):45. doi: 10.3390/v11010045. PMID: 30634476 |
| 8 |
Revisiting Seed Transmission of the Type Strain of Tomato yellow leaf curl virus in Tomato Plants. Pérez-Padilla V, et al. Phytopathology. 2020 Jan;110(1):121-129. doi: 10.1094/PHYTO-07-19-0232-FI. Epub 2019 Nov 20. PMID: 31584339 |
| 9 |
A New Tomato yellow leaf curl virus Strain in Southern Spain. Morilla G, et al. Plant Dis. 2003 Aug;87(8):1004. doi: 10.1094/PDIS.2003.87.8.1004B. PMID: 30812778 |
| 10 |
Wang L, et al. PLoS Pathog. 2022 Oct 18;18(10):e1010909. doi: 10.1371/journal.ppat.1010909. eCollection 2022 Oct. PMID: 36256684 |