Tomato yellow leaf curl Kanchanaburi virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000840985.1 |
| Isolate | Thailand: Kanchanaburi |
| Release date | 2015/2/12 |
| Submitter | Green,S.K., Tsai,W.S., Shih,S.L., Rezaian,M.A., Duangsong,U. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
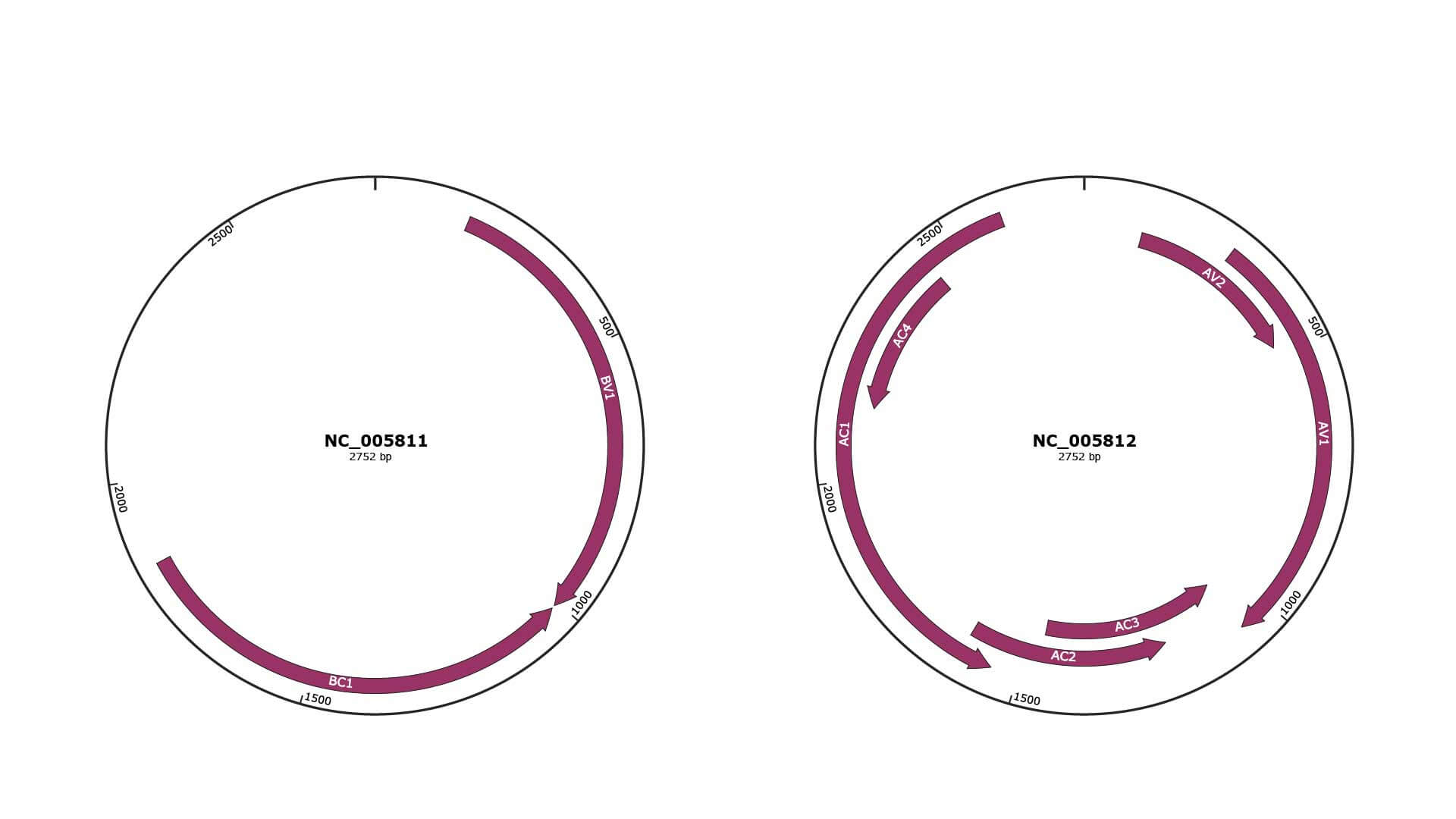
JBrowse
Genome
NC_005811
NC_005812
Gene Information
| NCBI Accession | NP_995300.1 |
|---|---|
| Location | 174-1007 |
| Gene Name | BV1 |
| Protein Name | BV1 protein |
| Coding Region | ATGAGAGTTCCAATCCGGAGGAATTCAGGTTTTAATTCTGACCGTCGTCCTTCAAATGGTTCAATCCACCGGTGGAATTACCCATATTCCGGCTATTTTGGCAGGAGGATTGGCAACCGCGTATATGGCATGCCATTTGGAAGCCGTCAAGTTCAAAGACGTGAATTTCAGCAGACTCATCGTCCTATCAAGTTTTCTGACCATGTTTCTTCTCGGAGGAAGTTTATGAAGACTATAGAGGAAATTCACGATGGCACTGACTACTTGCTTTGCAATAACATGTCCAAGGTGTCATACATTAGTTACCCTCCTCTATCCGGTACTGAACATGGTAGTAGAGCTGAATCCTATCTCAAAGTCCTGGGTTTTAATGTATCTGGGTCTGTTGTGCTGAAGCAGCTGCACATGCGTGAAGCAGATATGTCTCAAGGAATTCATGGTATATTTACCACAGTAATTGTTCGTGATAAGAGACCATGTCAGTTCTCTGCTGTGGATCCTATCATCCCATTTGTTGAGTTATTTGGACCAGAAAAGAGAGCATGCTCCACATTACATGTTAGAGATTCTTATAAGAATCGATTTAGTGTTGTCTATCAAAAGAAACATGTTGTAAATAGTGCTCTGACAACACATGTATTTAGGTATAATTTTAATGTTAAGTTTTCTAGGTTTCCTTTCTGGGTGTCTTTCAAAGACACATCCAATGCAGAGCCTACTGGACTATATTCTAATGTTTCTAAGAACGCATTGGTGGTGTACTACGTGTGGCTGTGTGATTCAAATGTAACAGCCGAAGTGCACGTACAGTATGATTTGAACTATATTGGATAA |
| Protein Sequence | MRVPIRRNSGFNSDRRPSNGSIHRWNYPYSGYFGRRIGNRVYGMPFGSRQVQRREFQQTHRPIKFSDHVSSRRKFMKTIEEIHDGTDYLLCNNMSKVSYISYPPLSGTEHGSRAESYLKVLGFNVSGSVVLKQLHMREADMSQGIHGIFTTVIVRDKRPCQFSAVDPIIPFVELFGPEKRACSTLHVRDSYKNRFSVVYQKKHVVNSALTTHVFRYNFNVKFSRFPFWVSFKDTSNAEPTGLYSNVSKNALVVYYVWLCDSNVTAEVHVQYDLNYIG |
| NCBI Accession | NP_995301.1 |
|---|---|
| Location | 1014-1847 |
| Gene Name | BC1 |
| Protein Name | BC1 protein |
| Coding Region | ATGGAGTCCAACAATAACAGTATTGCCTATACGACGTCGGATAGGACTGAATTTCAGCTGTCCAATGAAAAAACAGAAGTCACTCTGTTGTTTCCCTCAACCGTCGATCAAAAATTATCAATGCTCCTGGGAAAGTGTCTCAGGATTGACCATGTCATCCTCCAATACAGGAACCAAGTACCTGTCAATGCAACTGGGCATGTGGTCATAGAAATGCACGACACAAGGTTACATGAAGGAGACTCAAAGCAGGCTGAGTTCACAATACCCATAGGGTGTAACTGCAATATCCACTACTACTCATCCTCATACTTCTCCCCCAAAGATCCAAATCCATGGAGGGTGCTGTACAGGGTGGACGACACTAACGTGGTCAATGGTGTTCACTTTTGTAGGATGCAAGGGAAGTTAAAAATGTCCTCTGCAAAACAGTCATCTGAAATAACATTTAAGTCCCCAAAAATTGTAATACTGTCAAAGGCATATAACATGAACCACATAGATTTCTGGCATGTGCCTCAGTCCAAGGTATCAAGGAAACCAGTACAAGCCCTATCACAAATGAGGTCACAGTCTTCCAGATACACTACAAATGCCATTCCACAAGGGCATACCTGGGCTTCAGCCAGCGCAGTGGGGAACAACGAGATAGAGGAATACCCATACAGACATTTGCATCAGCTGCAAGATGCAACTCTAGATCCTGGCCCTTCGGCATCGGAAGTTGTTGCATGTAGCAACAAAGTGAATGATGATGTAATTAATATTATTAAAAAAACAGTTGAATTATGTATGGAAGGGAGTAATGTCTCCTCAAATGTAAAAAAAATATGA |
| Protein Sequence | MESNNNSIAYTTSDRTEFQLSNEKTEVTLLFPSTVDQKLSMLLGKCLRIDHVILQYRNQVPVNATGHVVIEMHDTRLHEGDSKQAEFTIPIGCNCNIHYYSSSYFSPKDPNPWRVLYRVDDTNVVNGVHFCRMQGKLKMSSAKQSSEITFKSPKIVILSKAYNMNHIDFWHVPQSKVSRKPVQALSQMRSQSSRYTTNAIPQGHTWASASAVGNNEIEEYPYRHLHQLQDATLDPGPSASEVVACSNKVNDDVINIIKKTVELCMEGSNVSSNVKKI |
| NCBI Accession | NP_995302.1 |
|---|---|
| Location | 118-480 |
| Gene Name | AV2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGGAAAACATGTGGGATCCATTGCTACATCCTTTTCCAGAGAGTTTGCACGGCTTTAGATGTATGCTTGCAATCAAGTATCTTCAAAGCTTACAGAGTAAGTATTCTCCTGATACTCTTGGGAGTGAATTCTTGAAGGATTTCATCTGCATCTTGCGGAGTAGAAATTATGCCGAAGCGTTCAATAGATACAGTGACGTCGTTGCCAATGTCTATAACACGCCGGAGGTTAAACTTCGGGAGTCAGTACAGTCTCCCTGCCTCTGCCCCCACTGCCCCAGGCATGTCGTACAAACGAAGAGCTTGGAAAAACCGTCCTATGTACACGAAGCCACGGTTTTATCGGTGGCGAAGGAGCAGTGA |
| Protein Sequence | MENMWDPLLHPFPESLHGFRCMLAIKYLQSLQSKYSPDTLGSEFLKDFICILRSRNYAEAFNRYSDVVANVYNTPEVKLRESVQSPCLCPHCPRHVVQTKSLEKPSYVHEATVLSVAKEQ |
| NCBI Accession | NP_995303.1 |
|---|---|
| Location | 287-1063 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCGAAGCGTTCAATAGATACAGTGACGTCGTTGCCAATGTCTATAACACGCCGGAGGTTAAACTTCGGGAGTCAGTACAGTCTCCCTGCCTCTGCCCCCACTGCCCCAGGCATGTCGTACAAACGAAGAGCTTGGAAAAACCGTCCTATGTACACGAAGCCACGGTTTTATCGGTGGCGAAGGAGCAGTGATGTTCCACGGGGTTGTGAGGGTCCTTGTAAGGTTCAGTCCTTTGAGCAGAGACATGATATAACACACACCGGCAAGGTGTTGTGTGTGTCTGATGTTACTAGAGGCAATGGTATTACTCATAGAATAGGTAAAAGATTTTGCGTTAAGTCTGTTTATGTTATGGGCAAAATCTGGATGGATGAGAATATTAAATTGAAGAATCACACCAACACTGTTATGTTTTGGCTTGTTCGCGACAGAAGACCTGTTACTACCCCATATGGATTTGGAGAGTTATTCAACATGTATGACAACGAGCCCAGTACTGCAACAATAAAGAACGATCTTAGAGATCGTGTGCAAGTGCTTCATCGTTTCTCAGCATCATTAACTGGTGGTCAATATGCCAGCAAGGAACAAGCAGTTATTAAGAAGTTTTTTAGAGTTAATAATTATGTGGTGTACAATCACCAAGAAGCTGCTAAGTATGAAAATCATACTGAGAATGCTTTGCTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACACTTAAGATTAGAATTTATTTTTATGACAATGTAACTAATTAA |
| Protein Sequence | MPKRSIDTVTSLPMSITRRRLNFGSQYSLPASAPTAPGMSYKRRAWKNRPMYTKPRFYRWRRSSDVPRGCEGPCKVQSFEQRHDITHTGKVLCVSDVTRGNGITHRIGKRFCVKSVYVMGKIWMDENIKLKNHTNTVMFWLVRDRRPVTTPYGFGELFNMYDNEPSTATIKNDLRDRVQVLHRFSASLTGGQYASKEQAVIKKFFRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDNVTN |
| NCBI Accession | NP_995304.1 |
|---|---|
| Location | 1060-1464 |
| Gene Name | AC3 |
| Protein Name | AC3 |
| Coding Region | ATGGATTTACGCACAGGGGAAACCATTACTGCAGCTCAAGCGCAGAATGGCGTGTATATATGGGAAGTTCCAAATCCCCTGTATTTCAAGGTGCTGAAGCACAACAGCAAACCATTCAACGACAACAACGACTATTTGGAGATACAGATCCAATTCAACCACAACCTCAGGAAGGCGTTGGGGATTCACAAGTGTTTCCTGATCTTCAGAATATGGACTCCTTTACAACCTCAGACCTGGCATTTCTTAAGAGTATTTAAAAATCAATGTATGAAATATTTGAATAACTTAGGTATAGTTTCAATTAACAATGTAATACGCGCAGCTGATTATGTATTGTGGGATGTATTGGAAAATACAAGTTATGTAGACCAATGTCATATAATAAAATTCAACATTTATTAA |
| Protein Sequence | MDLRTGETITAAQAQNGVYIWEVPNPLYFKVLKHNSKPFNDNNDYLEIQIQFNHNLRKALGIHKCFLIFRIWTPLQPQTWHFLRVFKNQCMKYLNNLGIVSINNVIRAADYVLWDVLENTSYVDQCHIIKFNIY |
| NCBI Accession | NP_995305.1 |
|---|---|
| Location | 1205-1612 |
| Gene Name | AC2 |
| Protein Name | AC2 |
| Coding Region | ATGCAGAATTCGTCACCCTCCAACAGCCACTCTACAATTGTACCAGTCAAAGTACAACATAAAATTGCAAAGAAAAAAATACCAAGAAGACGCAGAGTAGACTTAGATTGTGGCTGTTCGTATTACGTAAACATTAATTGTCACAAATATGGATTTACGCACAGGGGAAACCATTACTGCAGCTCAAGCGCAGAATGGCGTGTATATATGGGAAGTTCCAAATCCCCTGTATTTCAAGGTGCTGAAGCACAACAGCAAACCATTCAACGACAACAACGACTATTTGGAGATACAGATCCAATTCAACCACAACCTCAGGAAGGCGTTGGGGATTCACAAGTGTTTCCTGATCTTCAGAATATGGACTCCTTTACAACCTCAGACCTGGCATTTCTTAAGAGTATTTAA |
| Protein Sequence | MQNSSPSNSHSTIVPVKVQHKIAKKKIPRRRRVDLDCGCSYYVNINCHKYGFTHRGNHYCSSSAEWRVYMGSSKSPVFQGAEAQQQTIQRQQRLFGDTDPIQPQPQEGVGDSQVFPDLQNMDSFTTSDLAFLKSI |
| NCBI Accession | NP_995306.1 |
|---|---|
| Location | 1551-2600 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCTTCTCTAAATAAATTCAGAATAAATGCCAAAAACTATTTTCTCACATATCCTCAGTGCTCTCTGAGCAAGGAAGAAACCCTCTCTCAATTGAAGGAACTACAAACCCCAACCTCAAAAAAATATATCAAAATCTGCAGGGAGTTACACGAAGATGGGAGCCCTCATCTCCATGTGCTCATTCAATTCGAAGGGAAATTCCAGTGCAAAAATAACAGATTCTTCGACCTGGTTTCCCCAACCAGATCAGCACATTTCCATCCAAATGTTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTATTTGGAGAAGGACGGAGATACAATTGAATGGGGAGAATTCCAGGTTGATGGAAGATCTGCTAGAGGCGGACAACAATCCGCCAATGACGCATACGCAAAGGCAATTAACTGCGGAAGTAAGTCGGAGGCTCTTGCAGTCCTTAAGGAATTAGCTCCAAAGGACTATGTACTGCAGTACCACAACCTAAATGCTAATTTGGACCGGATATTTGCCCCAATCCAAGAATTATTTGTTAATCCTTACGAATTGTCGTCTTTCAATCAAGTTCCAAAAGAACTTGCCTCCTGGGCTGAGAAAAATGTATGTGATGCCGCTGCGCGGCCGTGGAGACCCATAGGAATGGTGATTGAAGGTGAATCTAGAACCGGCAAAACAATGTGGGCCAGATCATTGGGCCCTCATAATTATTTGTGTGGACATCTAGACCTTAGCCCAAAAGTGTACAGCAATGATGCTTGGTATAACGTCATTGATGACGTAGATCCGCATTATCTAAAGCACTTAAAAGAATTCATGGGGGCCCAGAGGGACTGGCAAAGCAATACAAAGTACGGTAAACCAATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCTGGTCCATCTTCCTCTTTTAAGGAGTTTTTGGACGAACCAAAAAATGAGGCATTAAAAAATTGGGCTTTGAAAAATGCAGAATTCGTCACCCTCCAACAGCCACTCTACAATTGTACCAGTCAAAGTACAACATAA |
| Protein Sequence | MPSLNKFRINAKNYFLTYPQCSLSKEETLSQLKELQTPTSKKYIKICRELHEDGSPHLHVLIQFEGKFQCKNNRFFDLVSPTRSAHFHPNVQGAKSSSDVKSYLEKDGDTIEWGEFQVDGRSARGGQQSANDAYAKAINCGSKSEALAVLKELAPKDYVLQYHNLNANLDRIFAPIQELFVNPYELSSFNQVPKELASWAEKNVCDAAARPWRPIGMVIEGESRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHLKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPSSSFKEFLDEPKNEALKNWALKNAEFVTLQQPLYNCTSQSTT |
| NCBI Accession | NP_995307.1 |
|---|---|
| Location | 2141-2443 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGAGCCCTCATCTCCATGTGCTCATTCAATTCGAAGGGAAATTCCAGTGCAAAAATAACAGATTCTTCGACCTGGTTTCCCCAACCAGATCAGCACATTTCCATCCAAATGTTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTATTTGGAGAAGGACGGAGATACAATTGAATGGGGAGAATTCCAGGTTGATGGAAGATCTGCTAGAGGCGGACAACAATCCGCCAATGACGCATACGCAAAGGCAATTAACTGCGGAAGTAAGTCGGAGGCTCTTGCAGTCCTTAAGGAATTAG |
| Protein Sequence | MGALISMCSFNSKGNSSAKITDSSTWFPQPDQHISIQMFRELNQAPTSSPIWRRTEIQLNGENSRLMEDLLEADNNPPMTHTQRQLTAEVSRRLLQSLRN |
References More References in PubMed
| 1 |
An JW, et al. Virus Res. 2021 Jan 2;291:198192. doi: 10.1016/j.virusres.2020.198192. Epub 2020 Oct 13. PMID: 33058965 |
|---|---|
| 2 |
First Report of Tomato yellow leaf curl Kanchanaburi virus Infecting Eggplant in Laos. Tang YF, et al. Plant Dis. 2014 Mar;98(3):428. doi: 10.1094/PDIS-07-13-0696-PDN. PMID: 30708424 |
| 3 |
Panerio EG, et al. Microbiol Resour Announc. 2025 Sep 11;14(9):e0025725. doi: 10.1128/mra.00257-25. Epub 2025 Aug 6. PMID: 40767482 |
| 4 |
Koeda S, et al. Plant Dis. 2020 Dec;104(12):3221-3229. doi: 10.1094/PDIS-03-20-0613-RE. Epub 2020 Oct 12. PMID: 33044916 |
| 5 |
Díaz-Pendón JA, et al. Mol Plant Pathol. 2010 Jul;11(4):441-50. doi: 10.1111/j.1364-3703.2010.00618.x. PMID: 20618703 |
| 6 |
Tsai WS, et al. Plant Dis. 2006 Feb;90(2):247. doi: 10.1094/PD-90-0247B. PMID: 30786428 |
| 7 |
Green SK, et al. Plant Dis. 2003 Apr;87(4):446. doi: 10.1094/PDIS.2003.87.4.446A. PMID: 30831844 |
| 8 |
A New Geminivirus Associated with a Yellow Leaf Curl Disease of Pepper in Thailand. Samretwanich K, et al. Plant Dis. 2000 Sep;84(9):1047. doi: 10.1094/PDIS.2000.84.9.1047D. PMID: 30832019 |
| 9 |
Lestari SM, et al. Arch Insect Biochem Physiol. 2023 Feb;112(2):e21984. doi: 10.1002/arch.21984. Epub 2022 Nov 17. PMID: 36397643 |
| 10 |
Incidence and Molecular Identification of Begomoviruses Infecting Tomato and Pepper in Myanmar. Kwak HR, et al. Plants (Basel). 2022 Apr 10;11(8):1031. doi: 10.3390/plants11081031. PMID: 35448759 |