Tomato yellow leaf curl Indonesia virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000869285.1 |
| Isolate | Indonesia:Lembang |
| Release date | 2015/2/13 |
| Submitter | Tsai,W.S., Shih,S.L., Green,S.K., Akkermans,D., Jan,F.-J. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
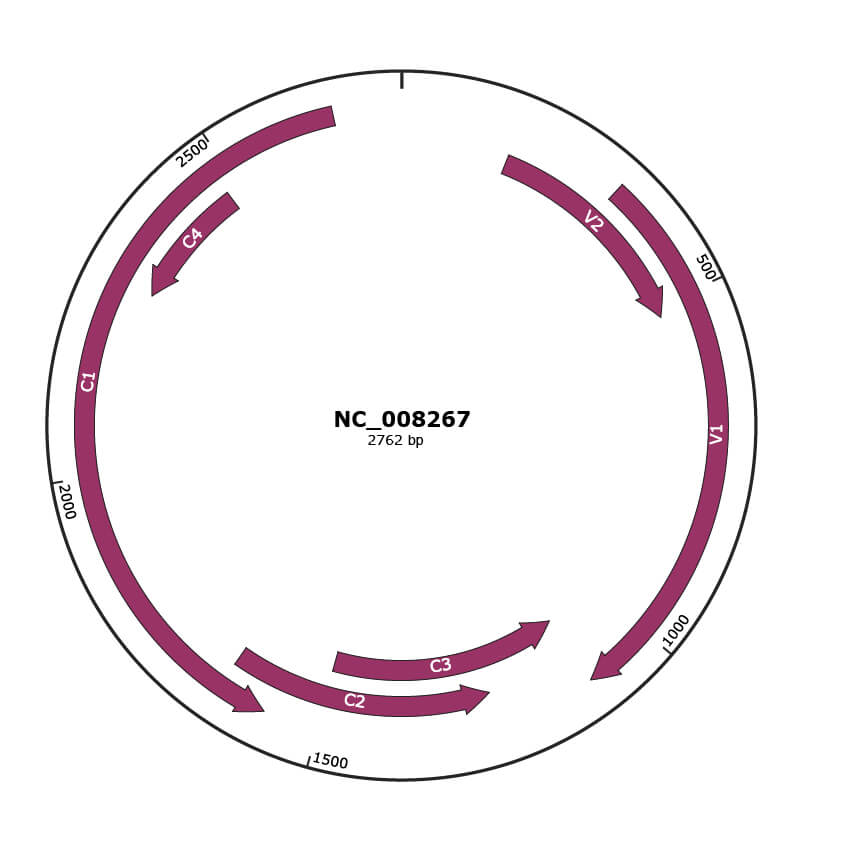
JBrowse
Genome
NC_008267
Gene Information
| NCBI Accession | YP_699989.1 |
|---|---|
| Location | 167-517 |
| Gene Name | V2 |
| Protein Name | precoat protein |
| Coding Region | ATGTGGGATCCTCTTTTAAACGAATTTCCGGATTCTGTTCACGGTTTTCGGTGTATGCTCGCAATAAAGTATTTGCAAGGCGTTGAAGCAACCTACGCCCCTGATACTGTCGGTTACGACCTAGTTCGAGATCTGATCTCAGTTGTTCGTGCGAGCAATTATGCTGAAGCGTGCCGGAGATATAGCCTTTTCCGGTCCCGTATCGAAAGTACGCCGTCGTCTCAATTACGACAGCCCAGGTACCAGCCGTGCTGCTGTACTCACTGCCCTCGGCATAAATCGAAAGAAGTCTTGGACTTCTCGGCCTATGTACCGGAAGCCCAGGATTTACCGGATGTACCGAACAGCTGA |
| Protein Sequence | MWDPLLNEFPDSVHGFRCMLAIKYLQGVEATYAPDTVGYDLVRDLISVVRASNYAEACRRYSLFRSRIESTPSSQLRQPRYQPCCCTHCPRHKSKEVLDFSAYVPEAQDLPDVPNS |
| NCBI Accession | YP_699990.1 |
|---|---|
| Location | 327-1100 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGCTGAAGCGTGCCGGAGATATAGCCTTTTCCGGTCCCGTATCGAAAGTACGCCGTCGTCTCAATTACGACAGCCCAGGTACCAGCCGTGCTGCTGTACTCACTGCCCTCGGCATAAATCGAAAGAAGTCTTGGACTTCTCGGCCTATGTACCGGAAGCCCAGGATTTACCGGATGTACCGAACAGCTGATGTCCCTAGGGGATGTGAAGGTCCTTGCAAGATTCAATCCTTTGAATCTCGACATGATATTGCTCACACCGGTAAGGTTATGTGTGTGACGGATGTTACTCGTGGCGGTGGTTTAACCCACCGTACTGGGAAGAGATTTTGCGTTAAGTCCCTCTATATCCTTGGCAAAATCTGGATGGATGAAAATATCAAGACTAAGAATCACACTAACACGGTCATGTTCTATGTTGTTCGGGATCGTAGACCCTATGGTACTCCTCAAGATTTTGGACAAGTGTTTAACATGTTCGATAACGAACCTAGCACTGCAACTGTCAAGAATGATCTTCGAGATCGGTTTCAAGTTTTGCGGAAGTTCACGGCAACTGTTGTTGGTGGTCAGTATGCTTGTAAGGAACAAACGTTAGTTAGGAAGTTCATGAGATTGAACAATTATGTTGTTTACAACCATCAGGAAACCGCAAAATATGAGAATCATACAGAGAATGCTCTGTTATTGTACATGGCATCTACGCATGCCTCTAACCCTGTGTATGCAACTTTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MLKRAGDIAFSGPVSKVRRRLNYDSPGTSRAAVLTALGINRKKSWTSRPMYRKPRIYRMYRTADVPRGCEGPCKIQSFESRHDIAHTGKVMCVTDVTRGGGLTHRTGKRFCVKSLYILGKIWMDENIKTKNHTNTVMFYVVRDRRPYGTPQDFGQVFNMFDNEPSTATVKNDLRDRFQVLRKFTATVVGGQYACKEQTLVRKFMRLNNYVVYNHQETAKYENHTENALLLYMASTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_699991.1 |
|---|---|
| Location | 1097-1501 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTTACGCACAGGGGAGTACATCACTGCAGCTCAAGCCAGGAATGGCGTCTATATTTGGGAGATTCAAAATCCCCTCTATTTCAAGATACTCAGCCATCACAGCCGGCCGTTCAACACGAACCACGACGTGATAACAATACGGCTGCAGTTCAACCACAACCTGAGGAAAGCGTTGGGAATACACCGGTGTTTTCTGACGTTCCAAGTTTGGACTTACTTACACCCTCCGACTGGGCTTTTCTTAAAAGTCTTTAAGACTCAATGTATTAAATACTTGAATAATTTAGGTGTAATTTCAATTAATAATGTAATTAGAGCTGTAGACCATGTCTTGTTTAAAGTGCTAGAACGCACTATTGATGTACAACCAGATTATGAAATAAAATTCAACATTTATTAA |
| Protein Sequence | MDLRTGEYITAAQARNGVYIWEIQNPLYFKILSHHSRPFNTNHDVITIRLQFNHNLRKALGIHRCFLTFQVWTYLHPPTGLFLKVFKTQCIKYLNNLGVISINNVIRAVDHVLFKVLERTIDVQPDYEIKFNIY |
| NCBI Accession | YP_699992.1 |
|---|---|
| Location | 1242-1649 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCAGAATTCATCACCCTCGAGAGACCACTGTACTCAGGTTCCCATCAAAGTCCAGCACCGGATTGCTAAAAAGAAGATAATAAGACGACGGCGGGTAGACCTTAATTGCGGTTGCTCATACTACGTGTCAATAAACTGTGCTAATCATGGATTTACGCACAGGGGAGTACATCACTGCAGCTCAAGCCAGGAATGGCGTCTATATTTGGGAGATTCAAAATCCCCTCTATTTCAAGATACTCAGCCATCACAGCCGGCCGTTCAACACGAACCACGACGTGATAACAATACGGCTGCAGTTCAACCACAACCTGAGGAAAGCGTTGGGAATACACCGGTGTTTTCTGACGTTCCAAGTTTGGACTTACTTACACCCTCCGACTGGGCTTTTCTTAAAAGTCTTTAA |
| Protein Sequence | MQNSSPSRDHCTQVPIKVQHRIAKKKIIRRRRVDLNCGCSYYVSINCANHGFTHRGVHHCSSSQEWRLYLGDSKSPLFQDTQPSQPAVQHEPRRDNNTAAVQPQPEESVGNTPVFSDVPSLDLLTPSDWAFLKSL |
| NCBI Accession | YP_699993.1 |
|---|---|
| Location | 1579-2667 |
| Gene Name | C1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGGAGAGCAATCGGGGAACCCCCTCTAATAACTCTCTCACAAAGCGTTTTCAAATAAACGCTAAAAACTATTTCCTCACCTATCCTCACTGCTCTCTCTCTAAAAGCGAAGCTCTCTCTCAAATTAGAAATTTGAATACCCCAACAAATAAAAAATATATCAAAATCTGCTCAGAGCTTCACGAGGATGGGGAACCACATCTCCATGTGCTTATCCAATTTGAGGGTAAGTTCAAGACAAAGAACAAGAGGTTCTTCGATCTGGTATCCCCAACCAGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAAGCATATATCGAAAAGGATGGTGATACCCTTGAATGGGGTACCTTCCAAATAGATGGAAGATCTTCAAGAGGCGGAAAGCAATCCGCTAACGACGCTTATGCAAAAGCTATGAATGCAGGAAACAAAGCGGAGGCTCTGAATATTCTTAAAGAACTTGCGCCTAAAGATTACATCTTGCAGTTTCATAACTTGAACACAAATCTTGACAAGATCTTCATGACTCCGCAACCAGTCTTTACCTCTCCATTCTTATCTTCATCCTTTGACCAGGTTCCTGAAGAACTTGAAGAATGGGTCGCCGAGAACATAGTCGACCCCGCTGCGCGGCCATTAAGACCAAAGAGTCTGGTGTTACAAGGTGATAGTCGTACAGGTAAAACCATGTGGGCTAGATCGCTTGGTAGGCACAATTACTTGTGCGGCCATCTAGATCTCAATCCTAGGGTTTACTCAAATGACGCATGGTATAACGTCATTGATGACGTCGATCCGCATTACCTAAAGCACTTTAAAGAGTTTATGGGGGCCCAGATGGACTGGCAAAGCAATACAAAGTATGGTAGACCCATTCAAATTAAAGGCGGGATACCGACCATCTTTTTATGTAATGCTGGACCCACATCTTCATATAAAGAGTTTTTAGACGAACCTAAAAACATCGCACTTAAAAATTGGTCTCTTCATAATGCAGAATTCATCACCCTCGAGAGACCACTGTACTCAGGTTCCCATCAAAGTCCAGCACCGGATTGCTAA |
| Protein Sequence | MESNRGTPSNNSLTKRFQINAKNYFLTYPHCSLSKSEALSQIRNLNTPTNKKYIKICSELHEDGEPHLHVLIQFEGKFKTKNKRFFDLVSPTRSTHFHPNIQGAKSSSDVKAYIEKDGDTLEWGTFQIDGRSSRGGKQSANDAYAKAMNAGNKAEALNILKELAPKDYILQFHNLNTNLDKIFMTPQPVFTSPFLSSSFDQVPEELEEWVAENIVDPAARPLRPKSLVLQGDSRTGKTMWARSLGRHNYLCGHLDLNPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQMDWQSNTKYGRPIQIKGGIPTIFLCNAGPTSSYKEFLDEPKNIALKNWSLHNAEFITLERPLYSGSHQSPAPDC |
| NCBI Accession | YP_699994.1 |
|---|---|
| Location | 2283-2480 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCACATCTCCATGTGCTTATCCAATTTGAGGGTAAGTTCAAGACAAAGAACAAGAGGTTCTTCGATCTGGTATCCCCAACCAGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAAGCATATATCGAAAAGGATGGTGATACCCTTGAATGGGGTACCTTCCAAATAG |
| Protein Sequence | MGNHISMCLSNLRVSSRQRTRGSSIWYPQPDQHISIRTFRELNQAPMSKHISKRMVIPLNGVPSK |
References More References in PubMed
| 1 |
Díaz-Pendón JA, et al. Mol Plant Pathol. 2010 Jul;11(4):441-50. doi: 10.1111/j.1364-3703.2010.00618.x. PMID: 20618703 |
|---|---|
| 2 |
Kesumawati E, et al. Arch Virol. 2019 Sep;164(9):2379-2383. doi: 10.1007/s00705-019-04316-8. Epub 2019 Jun 15. PMID: 31203434 |
| 3 |
Koeda S, et al. Plant Dis. 2020 Dec;104(12):3221-3229. doi: 10.1094/PDIS-03-20-0613-RE. Epub 2020 Oct 12. PMID: 33044916 |
| 4 |
Tsai WS, et al. Plant Dis. 2009 Mar;93(3):321. doi: 10.1094/PDIS-93-3-0321C. PMID: 30764201 |
| 5 |
Sakata JJ, et al. Arch Virol. 2008;153(12):2307-13. doi: 10.1007/s00705-008-0254-z. Epub 2008 Nov 18. PMID: 19015934 |
| 6 |
Neriya Y, et al. Microbiol Resour Announc. 2020 Jun 18;9(25):e00486-20. doi: 10.1128/MRA.00486-20. PMID: 32554790 |
| 7 |
Tsai WS, et al. Plant Dis. 2006 Feb;90(2):247. doi: 10.1094/PD-90-0247B. PMID: 30786428 |
| 8 |
Tsai WS, et al. Plant Dis. 2006 Jun;90(6):831. doi: 10.1094/PD-90-0831B. PMID: 30781263 |
| 9 |
First Report of Pepper yellow leaf curl Indonesia virus in Ageratum conyzoides in Indonesia. Shibuya Y, et al. Plant Dis. 2007 Sep;91(9):1198. doi: 10.1094/PDIS-91-9-1198B. PMID: 30780641 |
| 10 |
Kon T, et al. Arch Virol. 2007;152(6):1147-57. doi: 10.1007/s00705-006-0928-3. Epub 2007 Feb 12. PMID: 17294343 |