Cabbage leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000838405.1 |
| Release date | 2015/2/12 |
| Submitter | Abouzid,A.M., Hiebert,E., Strandberg,J.O. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
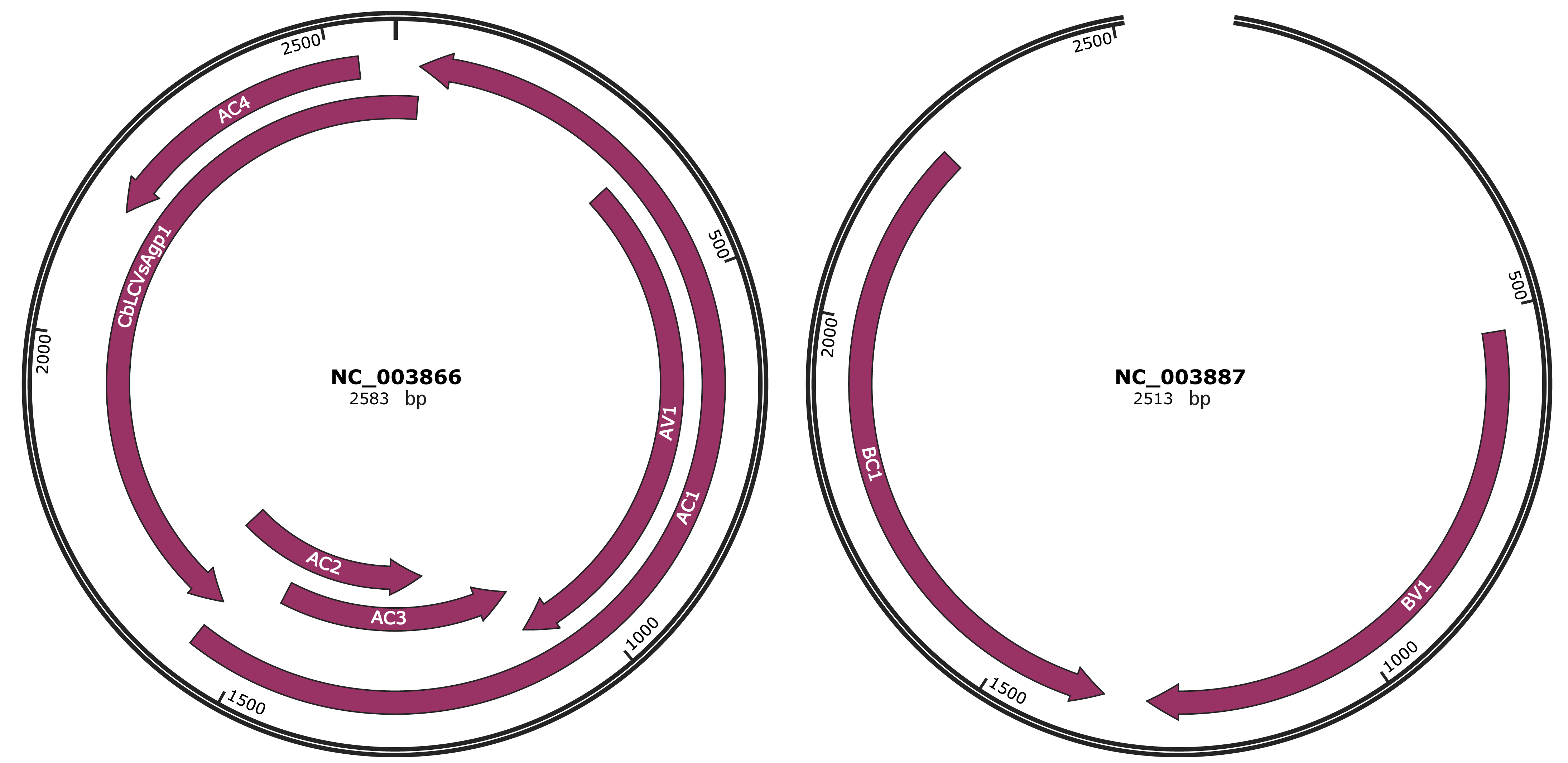
JBrowse
Genome
NC_003866
NC_003887
Gene Information
| NCBI Accession | NP_620884.1 |
|---|---|
| Location | 1567-2583,1-33 |
| Protein Name | replicase associated protein |
| Coding Region | ATGCCACGAAACCCTAAATCGTTTCGTTTAGCAGCCCGAAATATATTCTTAACATATCCCCAGTGCGACATACCCAAAGATGAAGCTCTTCAGATGCTTCAAACCCTGTCGTGGTCAGTCGTCAAACCCACATACATCAGAGTCGCAAGAGAGGAACATTCAGACGGGTTCCCCCATTTACACTGTCTCATCCAACTATCAGGAAAGTCGAACATCAAGGATGCTAGATTTTTCGACATCACTCACCCCAGAAGGTCTGCCAATTTTCACCCAAACATTCAGGCAGCCAAAGACACCAATGCCGTCAAGAATTACATCACCAAAGATGGTGATTATTGTGAATCCGGGCAGTACAAGGTGTCTGGGGGTACAAAGGCAAATAAAGACGACGTCTACCACAACGCCGTCAATGCGGGATGTGTGGAAGAGGCTCTCGCAATTATAAGGGCTGGAGATCCAAAGACGTTCATTGTTAGTTATCATAATGTTAGAGCTAACATAGAGCGACTCTTTACTAAGGCTCCGGAACCATGGGCTCCTCCGTTTCAACTCTCCTCCTTTACTAACGTCCCGGACGAGATGAGTTCATGGGCAGATGACTATTTTGGTCGGAGTGCCGCTGCGCGGGCGGAAAGACCTATTAGTATCATAGTTGAAGGTGATTCACGAACCGGCAAGACCATGTGGGCGCGTGCTTTAGGACCACATAATTATTTGAGTGGGCACCTCGACTTTAATTCAAAGGTCTTTTCAAATAATGCGGAGTATAACGTCATTGATGACATAGCTCCGCATTATCTAAAGCTAAAGCACTGGAAAGAGCTTATTGGGGCCCAAAGGGACTGGCAATCAAACTGTAAGTACGGCAAGCCAGTTCAAATTAAAGGTGGCATACCCTCAATCGTGCTGTGCAATCCAGGAGAGGGGAGCAGTTATATAAGTTTCCTCAACAAAGAGGAAAATGCATCACTAAGAGCGTGGACTACCAAAAATGCAAAATTCATCACTCTTGAAGCCCCCCTCTATCAAAGCACAGCACAAGATTGCTAA |
| Protein Sequence | MPRNPKSFRLAARNIFLTYPQCDIPKDEALQMLQTLSWSVVKPTYIRVAREEHSDGFPHLHCLIQLSGKSNIKDARFFDITHPRRSANFHPNIQAAKDTNAVKNYITKDGDYCESGQYKVSGGTKANKDDVYHNAVNAGCVEEALAIIRAGDPKTFIVSYHNVRANIERLFTKAPEPWAPPFQLSSFTNVPDEMSSWADDYFGRSAAARAERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFSNNAEYNVIDDIAPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYISFLNKEENASLRAWTTKNAKFITLEAPLYQSTAQDC |
| NCBI Accession | NP_620885.1 |
|---|---|
| Location | 339-1094 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGTTCTATGGCGGGGACCTCTAAAGTGTCCCGCAATGCTAACTATTCACCTCGTGCAGGTATGATCCATAAATTTGATAAGGCCGCTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATAGGACGTTTAGAAGCCCAGATGTTCCTAGAGGCTGTGAAGGGCCTTGCAAAGTCCAGTCTTATGAGCAGCGGCATGACATTTCCCATGTTGGTAAGGTCATGTGTATTTCAGACATAACACGTGGTAATGGTATTACCCATCGTGTTGGGAAGCGTTTTTGCGTCAAGTCCGTGTACATTTTGGGCAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACCAACAGTGTCATGTTTTGGTTGGTTAGGGACAGAAGACCATATGGCACCCCTATGGAGTTTGGCCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGTTATCAAGTCATGCACAAGTTTTACGCAAAGGTAACCGGTGGGCAGTATGCGAGTAACGAGCAGGCGTTGGTGAAGCGTTTTTGGAAGGTCAATAACTACGTTGTGTACAACCATCAAGAAGCAGGGAAATACGAGAATCATACGGAGAACGCTCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCGACATTAAAAATTCGGATCTATTTTTACGATTCGATAACAAATTAA |
| Protein Sequence | MPKRDAPWRSMAGTSKVSRNANYSPRAGMIHKFDKAAAWVNRPMYRKPRIYRTFRSPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDITRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMEFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_620886.1 |
|---|---|
| Location | 1091-1489 |
| Gene Name | AC3 |
| Protein Name | replicase associated protein |
| Coding Region | ATGGATTCACGCACCGGGGAGAGCATCACTGTAGCTCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTATATTTCAGGATACAACGCGTAGAGGACCCGTTGTACACCAGAACCAGGATCTACCACATCCAAGTCCGGTTCAACCACAACCTACGGAAAGCATTGGATCTCCGCAAAGCCTACTTCAACTTCCAAGTCTGGACGACTTCGATGAGAGCTTCTGGGCCGACATATTTAAGTAGATTCAAATGCCTTGTAATGTCTCATTTAGATAACCTAGGTGTTATTGGTATTAATCATGTAATTAGAGCTGTTCGTTTCGCAACGGACAGATCTTATGTAACTCATGTTCACGAGAATCATGTAATAAATTTCAAAATTTATTAA |
| Protein Sequence | MDSRTGESITVAQAENSVFIWEVPNPLYFRIQRVEDPLYTRTRIYHIQVRFNHNLRKALDLRKAYFNFQVWTTSMRASGPTYLSRFKCLVMSHLDNLGVIGINHVIRAVRFATDRSYVTHVHENHVINFKIY |
| NCBI Accession | NP_620887.1 |
|---|---|
| Location | 1236-1625 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCAAAATTCATCACTCTTGAAGCCCCCCTCTATCAAAGCACAGCACAAGATTGCTAAAAGGAGAGCTGTACGCCGAAGACGCATTGATTTGAACTGCGGGTGTTCTATCTTCCTCCACATCAATTGCGCAGATAATGGATTCACGCACCGGGGAGAGCATCACTGTAGCTCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTATATTTCAGGATACAACGCGTAGAGGACCCGTTGTACACCAGAACCAGGATCTACCACATCCAAGTCCGGTTCAACCACAACCTACGGAAAGCATTGGATCTCCGCAAAGCCTACTTCAACTTCCAAGTCTGGACGACTTCGATGAGAGCTTCTGGGCCGACATATTTAAGTAG |
| Protein Sequence | MQNSSLLKPPSIKAQHKIAKRRAVRRRRIDLNCGCSIFLHINCADNGFTHRGEHHCSSGREFRFYLGGSKSPIFQDTTRRGPVVHQNQDLPHPSPVQPQPTESIGSPQSLLQLPSLDDFDESFWADIFK |
| NCBI Accession | NP_620888.1 |
|---|---|
| Location | 2172-2537 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAAGCTCTTCAGATGCTTCAAACCCTGTCGTGGTCAGTCGTCAAACCCACATACATCAGAGTCGCAAGAGAGGAACATTCAGACGGGTTCCCCCATTTACACTGTCTCATCCAACTATCAGGAAAGTCGAACATCAAGGATGCTAGATTTTTCGACATCACTCACCCCAGAAGGTCTGCCAATTTTCACCCAAACATTCAGGCAGCCAAAGACACCAATGCCGTCAAGAATTACATCACCAAAGATGGTGATTATTGTGAATCCGGGCAGTACAAGGTGTCTGGGGGTACAAAGGCAAATAAAGACGACGTCTACCACAACGCCGTCAATGCGGGATGTGTGGAAGAGGCTCTCGCAATTATAA |
| Protein Sequence | MKLFRCFKPCRGQSSNPHTSESQERNIQTGSPIYTVSSNYQESRTSRMLDFSTSLTPEGLPIFTQTFRQPKTPMPSRITSPKMVIIVNPGSTRCLGVQRQIKTTSTTTPSMRDVWKRLSQL |
| NCBI Accession | NP_624352.1 |
|---|---|
| Location | 529-1299 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle movement protein |
| Coding Region | ATGTATCCTACAAAGTTTAGGCGTGGGGTATCTTACTCTCAAAGACGATTTGTTTCACGTAATCAATCGTCTAAGCGTGGAACTTTTGTTAGACGCACTGATGGGAAACGTCGTAAAGGCCCATCAAGTAAAGCCCATGATGAGCCTAAAATGAAGTTGCAACGCATACATGAAAATCAATATGGGCCTGAATTTGTCATGACCCATAACTCAGCCCTTTCAACGTTTATTAATTTCCCTGTACTTGGTAAGATTGAACCTAACCGAAGCAGGTCGTATATTAAGTTGAACCGGTTATCATTTAAGGGAACCGTTAAGATTGAGCGTGTACATGCTGATGTGAACATGGACGGAGTAATTTCGAAGATAGAGGGTGTGTTCTCTCTTGTTATTGTTGTTGATCGCAAACCACATTTAAGCTCCACTGGAGGTTTGCATACATTTGATGAAATATTTGGTGCAAGAATCCATAGCCATGGGAACTTAGCTATTACACCCGGTTTGAAAGATCGTTATTACGTCCTCCATGTTTTGAAACGCGTATTGTCTGTGGAGAAAGACACTTTGATGGTGGATCTTGAAGGATCTACCACGATATCTAATAGGCGTTATAACTGTTGGGCCTCATTTAACGATCTTGAACATGACTTATGTAACGGTGTTTATGCGAATATAAGCAAAAACGCCATTTTGGTATATTATTGTTGGATGTCCGATGCTATGTCTAAGGCATCGACCTTTGTATCTTACGATCTTGATTATTTAGGTTAA |
| Protein Sequence | MYPTKFRRGVSYSQRRFVSRNQSSKRGTFVRRTDGKRRKGPSSKAHDEPKMKLQRIHENQYGPEFVMTHNSALSTFINFPVLGKIEPNRSRSYIKLNRLSFKGTVKIERVHADVNMDGVISKIEGVFSLVIVVDRKPHLSSTGGLHTFDEIFGARIHSHGNLAITPGLKDRYYVLHVLKRVLSVEKDTLMVDLEGSTTISNRRYNCWASFNDLEHDLCNGVYANISKNAILVYYCWMSDAMSKASTFVSYDLDYLG |
| NCBI Accession | NP_624353.1 |
|---|---|
| Location | 1357-2244 |
| Gene Name | BC1 |
| Protein Name | movement/pathogenicity protein |
| Coding Region | ATGAATTCTCAGTTAGCGAATGCTCCAAATGCGTTTAATTACATAGAGTCTCATAGAGACGAATATCAGCTGTCGCATGATCTTACTGAGATACTACTTCAATTCCCTTCAACTGCAGCGCAATTTACAGCAAGGCTTAATCGTAGCTGTATGAAAATCGACCATTGCGTCATCGAATATAGACAGCAAGTACCAATTAACGCAACTGGATCTGTGATAGTGGAGATCCATGACAAGAGGATGACTGACGACGAATCCTTACAAGCGTCTTGGACATTTCCCTTAAGATGCAACATAGATCTCCACTATTTTTCATCTTCATTCTTCTCTCTAAAAGACCCCATTCCGTGGAAACTCTATTACAGAGTTAGCGACACAAATGTGCATCAACGAACACATTTTGCCAAGTTTAAGGGGAAATTGAAATTGTCCACAGCTAAACATTCAGTGGATATCCCCTTCCGGGCACCAACAGTGAAAATTCATTCAAAACAATTTTCACATAGAGATGTTGATTTCTCACATGTGGACTACGGAAGATGGGAGAGGAAGACCTTGAGGTCCAAATCATTGTCAAGAATTGGACTAACAGGCCCAGGCCCAATTGAATTACAACCAGGTGATTCATGGGCTTCAAGGAGCACAATTGGGTTTCCCAACCCACACACAGAATCAGAAGTGGAAAACGCGCTACATCCATATAGAGAACTCAACCTGCTAGGAACTAGCGCATTAGACCCCGGGGATTCAGCATCACAAGCTGGGTTACAAAGGGCCCAATCAACCATAACGATGTCAGTGGCCCAATTAAGCGAGCTAGTTAGGACGACGGTTCAGGAATGTATTAACAATAATTGTAATCCTCCACAACCAAAGTCATTGCAATAA |
| Protein Sequence | MNSQLANAPNAFNYIESHRDEYQLSHDLTEILLQFPSTAAQFTARLNRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDDESLQASWTFPLRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIHSKQFSHRDVDFSHVDYGRWERKTLRSKSLSRIGLTGPGPIELQPGDSWASRSTIGFPNPHTESEVENALHPYRELNLLGTSALDPGDSASQAGLQRAQSTITMSVAQLSELVRTTVQECINNNCNPPQPKSLQ |
References More References in PubMed
| 1 |
First Report of Cabbage leaf curl virus (Family Geminiviridae) in Georgia. Mandal B, et al. Plant Dis. 2001 May;85(5):561. doi: 10.1094/PDIS.2001.85.5.561A. PMID: 30823146 |
|---|---|
| 2 |
Xiao Z, et al. Planta. 2020 Sep 1;252(3):42. doi: 10.1007/s00425-020-03454-7. PMID: 32870402 |
| 3 |
Brown JK, et al. Plant Dis. 2001 Sep;85(9):1027. doi: 10.1094/PDIS.2001.85.9.1027C. PMID: 30823088 |
| 4 |
SnRK1 phosphorylation of AL2 delays Cabbage leaf curl virus infection in Arabidopsis. Shen W, et al. J Virol. 2014 Sep;88(18):10598-612. doi: 10.1128/JVI.00761-14. Epub 2014 Jul 2. PMID: 24990996 |
| 5 |
Viral Vectors for Plant Genome Engineering. Zaidi SS, et al. Front Plant Sci. 2017 Apr 11;8:539. doi: 10.3389/fpls.2017.00539. eCollection 2017. PMID: 28443125 |
| 6 |
Trejo-Saavedra DL, et al. Virol J. 2009 Oct 20;6:169. doi: 10.1186/1743-422X-6-169. PMID: 19840398 |
| 7 |
Cucurbit leaf curl virus, a New Whitefly Transmitted Geminivirus in Arizona, Texas, and Mexico. Brown JK, et al. Plant Dis. 2000 Jul;84(7):809. doi: 10.1094/PDIS.2000.84.7.809A. PMID: 30832123 |
| 8 |
Hill JE, et al. Virology. 1998 Oct 25;250(2):283-92. doi: 10.1006/viro.1998.9366. PMID: 9792839 |
| 9 |
A TIR-NLR gene from Arabidopsis Pla-1 confers resistance to geminivirus infection. Shen W, et al. Plant J. 2025 Dec;124(5):e70628. doi: 10.1111/tpj.70628. PMID: 41351323 |
| 10 |
Carvalho MF, et al. J Virol. 2004 Oct;78(20):11161-71. doi: 10.1128/JVI.78.20.11161-11171.2004. PMID: 15452236 |