Tomato wrinkled mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_004788055.1 |
| Isolate | Venezuela |
| Release date | 2021/6/1 |
| Submitter | Romay,G., Chirinos,D.T., Geraud-Pouey,F., Gillis,A., Mahillon,J., Desbiez,C., Bragard,C. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
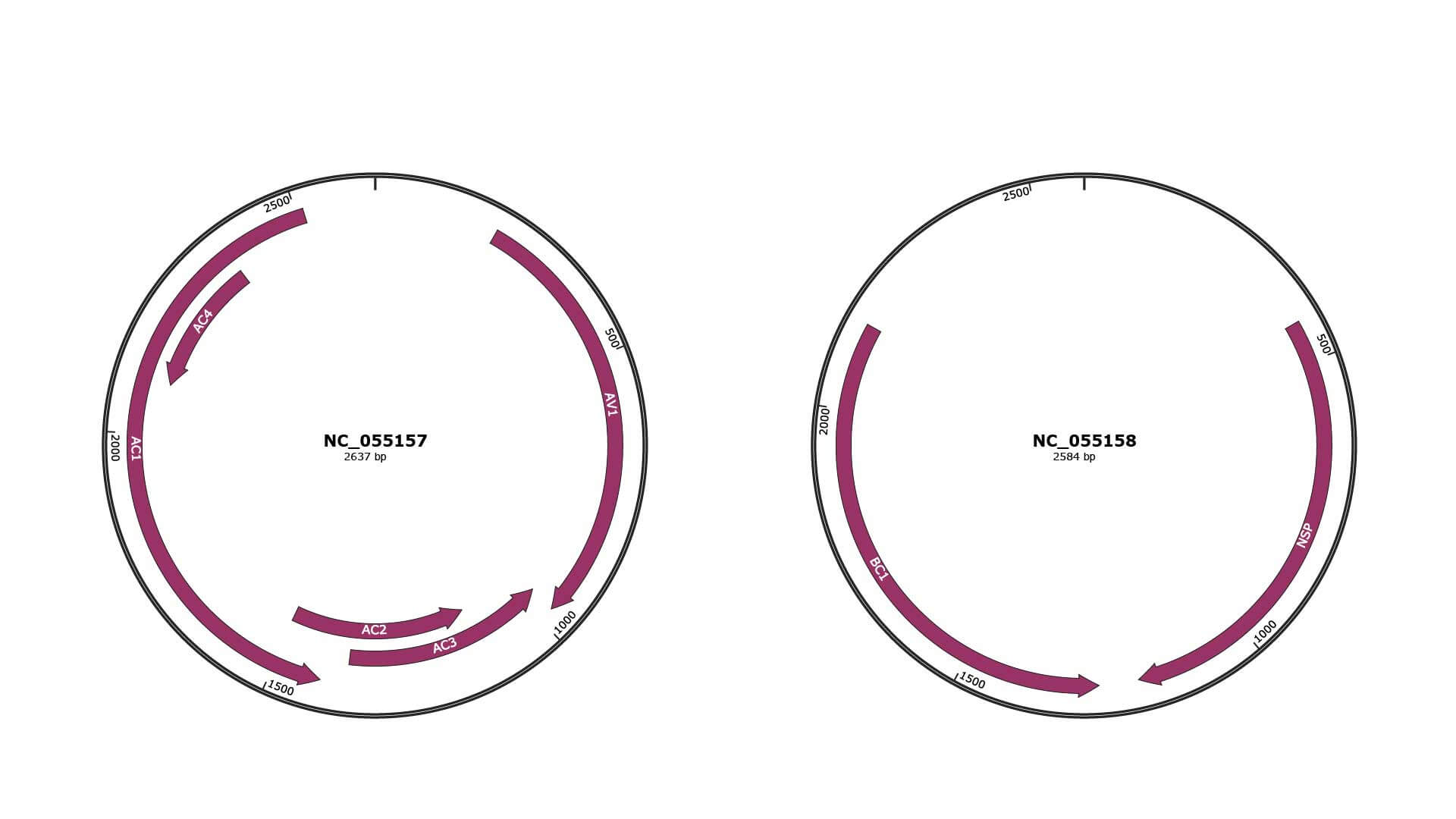
JBrowse
Genome
NC_055157
ACCGGATGGCCGCGCGATTTTTCCCCCCCCTTACGTGGCGCTATGGTGGCCGCCCGATCTCGTCGCGCTTTTCCTTTAACTCGAATTAAAGGAAATCTCTTTCGTCTCGTCCAATGATAATGCGCCTGTCGCGCCTAGATATCCGGAACAACTTGGGCCCTAAGTTGTTCGTGGCCTATAAATGAAAAGCTAATTGGGCCACATTCTTTAATTCAAAATGCCTAAGCGCGATCTCCCATGGCGCGCGATGCCGGGAACATCAAAGGTTAGTCGCAATGCTAACTATTCTCCTCGTGCAGGTGGTGGCCCAAAAGTGAATAGGGCCTCCGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATATACCGGACGCTAAGGACGCCTGATGTGCCCAGAGGATGTGAAGGCCCTTGCAAGGTCCAGTCCTATGAACAGCGTCACGATATCTCACATGTCGGGAAGGTCATGTGCATTTCTGACGTGACACGTGGTAATGGGATCACCCACCGTGTTGGTAAGCGTTTCTGTGTCAAGTCCGTGTACATCCTTGGTAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTGATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACTCCCATGGATTTTGGCCAAGGGTTCAACATGTTCGACAACGAGCCTAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAGGTTATGCACAAGTTTTATGGCAAGGTGACAGGAGGACAGTATGCCAGCAATGAACAGGCAATTGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTCTACTACTATATATGGCATGTACTCATGCGTCTAACCCCGTGGATGCTACCCTTAAGAATCGAATCTATTTTTATGATTCGATTATGAATTAATAAATTTTGAATTTTATTGAATGATCCTCTATTACATGATTAACGTACGATCTGGCTGTTGCGAAACGAACAGCTCTGATTACATTGTTAAGTGAGATCACTCCTAACTGATCTAAATACATATTGACTAAGTGCCTAAACCTAGCTAAATAAGTCGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGAAGGCTTTGTGGAGATGCAACGCTCTCCTGAGGTTGTGGTTGAACCGTATCTGTACGCTGTACACCCTGCTCCTGGTGTATAATGGGTCTTCTACCTTGTACATCCTGAAATAAAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCCGCCTGAGGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGCCCGGTGCAGTCTATGTGGAAGTAGATGGAGCAACCGCAATCTAAATCAATCCTGCGTCTCCTGATAGCCCTCCTCTTGGCTTGCCTGTGTGCCTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGACCGCATTCTTTATTGTCCAGTTCCTGAGGGATGCGTTTTCCTCTTTGCTCAGGAAGTCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATACCCCCTTTAATTTGAACTGGCTTGCCGTACTTGCAATTTGATTGCCAGTCCTTCTGGGCCCCAAGAAGTTCCTTCCAGTGCTTTATCTTTAGATATTGCGGTGCGACGTCATCAATGACGTATACTCCACTTCGTTCGAGTAGACCCGGTGATTGAAGTCCAGATGTCCACGAAGATAGGTATGTGGGCCTAGCGCACGAGCCCACGTTGTCTTCCCTGTCCTTGAATGACCCTCTACTATGAGACTTACTGAGACTTACTGGTCTCTCTGGCCGCGCAGCGGCACCTCTCCCAAAATAATCGTCCGCCCACTCTTGCATCTCGTCGGGCACGTTAGTGAAAGAGGAGAGGTGAAACGGAGGAGACCCACGGGCCTCTGGAGCCTTCATGAAAATCCTATCTAGGTTACTGGATAGGTTGTGATACTGGAAGAGAAACTTTTCCGGCAACTTCTCTTTGATGATTTTCATTGCCTCCTCCTTTGTTCCAGCATTCAACGCCTCGGCGGCTGCGTCGTTAGATGTCTGTTGACCGCCTCTAGCACTTCTGCCGTCGATCTGGAACACCCCCCATTCGGCGGTGTCCCCGTCTTTCTCGACGTAGGACTTGACGTCGGAGCAGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTACTGACCTGGTTGGGGACACCAGATCGAACAATCTCTTATTCGTGCAGTTGAATTTCCCTTCGAATTGGATGAGCACATGGAGATGAGGCTCCCCATTTGCATGCAGTTCTCTGCAGATCTTGATGAACTTCTTGTTGACTGGAGTGTTTAGGTTTTGTAATTGGGAAAGTGCCTCTTCTTTGTTAAGAGAGCACTGGGGATATGTAAGGAAATAGTTTTTGGCTTTTATAGAGAACACTCCCTTCCGTGGCATATTTGTAAATAAGGGTGTTCCCCCAATAGCTCTCTCGCTCAAAACTCGTATGAATTGGGGGAAATGGGGGAAAATATATAGTAGAAGTTCCTAAGGGGCACGTGGCGGCCATCCGTATAATATT
NC_055158
ACCGGATGGCCGCGCGATTTTTTTCCCCCCTTGACGTGGCGCTCTGGTGGCCGTGCGATCCCCTCGCGCTCCCTGGTGCTCTTCTGGTGCCCCCTCCCGCTCACGCTCGCTCCAACATTGGTGCTGGAGACGCGCTCCCTCATTGGTGCTGGTACCTGACGCGCGTCTTTTTGACTGCCCTTTAATTCGAGTTAAAGGATTAATCTTTTGTCGCGCGATTTGAATTATTGTCCCGCGACGACTGTGTGTACCCCATGGTGGACGTGGCCAATTTCTGACCACGCTGCTGAGTTTACTTGCGATTAATGTTGTACCCGTTCAGTTATATATGTAGTGGAATGGTATATCATGTCATATCCTACTCAGCAGCCGAACACGTCTATAGAGTAATTAACTAATTACTGTGTTGATCTCGTATTATTTTTAGATAATGTATTATTTTAGGAATAGACGTGGTTCGAATTCACACGGACGACGACATTATTCTCGTAATAATGTGTTCAAGCGTCCAATTTCATCAAAGAGGCATGATTGGAAACGTGGAGGAGTCAATTCCAGCAAGCCCAGTGATGAGCCCAAGATGAAGGTCCAACGCATTCATGAGAATCAGTATGGGTCCAACTTTGTAATGGCCCATAATTCAGCCATTTCTACGTACATCACTTATCCCAGCTTGGGGAAGATCGAACCCAGCAGGAGCAGGTCCTATATTAAGTTGAACCGCTTGCGTTTCAAAGGGACCGTTAAGATTGAACGTGTTCAACCGGACATGAATCTGGACGTTGCTATCCCCAAGGTGGAAGGAGTCTTCACCCTCGTTGTGGTTGTGGATCGGAAACCGCATCTTGATCCATCTGGTGGTCTGCAAACGTTTGACGATCTTTTCGGTGCTAGGATACACAGTCACGGTAACCTCAGCATAATTCCTACGTTGAAAGACCGCTATTATATCCGACACGGTTCAAACGTTGTTGTCGTTGAGAAAGACACGCTGATGGTAGACGTGGAAGGATCCATTCCCCTCTCTAACAGGCGTTATAATTGTTGGTCCACGTTTAAGGATCTGGATCGAGAATCATGCAATGGCGTTTACGGCAACATTAACAAGAACGCCCTGTTAGTCTATTACTGTTGGATGTCGGATACGATGTCTAATGCATCGACATTTGTAACTTATGATCTGGATTATATTGGATGATTAATGAAATAAACATTGTATTTAGCCAATTTTGAACACTTTAATATTATGAAGATCATTATTACAATCTACTGCAATGATTTGGGCTGTGAAGGTCTACAATTACTATTGATACACTCCTGGACAGTAGTCCTAACGAGCTCGTTCAACTGGCCCATTGACATCGTGATGTTGGACTCCGCTCTCTGGGCTCCTATAACTGACGCAGACTCTCCTGGGTCTAGAACGGTGGTCCCGAGCCTGCTCAGGTGTCTGTAAGGGTGGAGTTCGTTCTCCACCTCCGAGTCCGCCTCTGAATGGCCCGTTCCTATGGTGCTCCTGGAAGCCCACGATTCACCAGGCCTTATCTCTATTGGGCCTCGAAGCCCAACCCTTGACATGGACGCGCATCTGATGGGCTTCCTTTCCCATCTTCCGTAGTCGACATGGGAAAAGTCCACATCTTTGTCCGTGAACTGTTTGGACAAGATCTTTACTGTTGGTGCCCGGAAAGGGATGTCGACGGAGTGTTTCGCCGTCGATAATTTCAGCTTCCCTTTGAACTTCGCGAAGTGGGTCCTCTGATGAACATTCGTGTCGCAAACTCTGTAATAGAGTTTCCATGGAATTGGGTCCTTGAGCGAGAAGAATGAAGCTGAAAAGTAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCACGACGCCTGCAGTGACTCGTTGTCCGTCATCCTCTTGTCGTGGATCTCCACAATTACCGACCCCGTCGCGTTGATCGGAACTTGCTGCCTGTATTCTATGACGCAGTGGTCGATCTTCATGCAGCTACGACTGAGTCTAGCCGTCAACTGAGACGCCGTCGACGGAAATTGCAGAACGATCTCAGTTAGGTCATGCGAAAGCTGATATTCGTCCCTATGGGACTCTATGTAATTGAAGGCATGCGGAGGATTAACCAACTGAGAATCCATCTGAATAAGAAAGGCCGCGCAGCGGAACCGATTGCTGAAGTTGATGTGCTGAGAAAAATGTTAGGGTTCCTCTTGAAGAAATGTGAAGGATATGACTGAGGAAGAAGATGATCAACTGCTCTGGGTGGTTATGAACACTATTTATAAGATGGAAATTCTGTTTAAGCCTTCTCTTTTTGAGAAAGAGAAGAGAGTTTATGAAGAAGTTGAGGATGAGGATAATCTACTTCTAAGGGTGTTTATATAGAAACCCAGGTGTTATGTTCTTTCTTTAGAGCGTTCTGTAGAAGTTTTAATCCCTGGGAATGGCATTTCTGTAAATAAGGGTGTTCCCCCAATAGCTCTCTCGCTCAAAACTCCTATGAATTGGGGGAAATGGGGGAAAATATATACTAGAAGCTCCTAAGGGGCACGTGGCGGCCATCCGTATAATATT
Gene Information
| NCBI Accession | YP_010084728.1 |
|---|---|
| Location | 218-973 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATCTCCCATGGCGCGCGATGCCGGGAACATCAAAGGTTAGTCGCAATGCTAACTATTCTCCTCGTGCAGGTGGTGGCCCAAAAGTGAATAGGGCCTCCGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATATACCGGACGCTAAGGACGCCTGATGTGCCCAGAGGATGTGAAGGCCCTTGCAAGGTCCAGTCCTATGAACAGCGTCACGATATCTCACATGTCGGGAAGGTCATGTGCATTTCTGACGTGACACGTGGTAATGGGATCACCCACCGTGTTGGTAAGCGTTTCTGTGTCAAGTCCGTGTACATCCTTGGTAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTGATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACTCCCATGGATTTTGGCCAAGGGTTCAACATGTTCGACAACGAGCCTAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAGGTTATGCACAAGTTTTATGGCAAGGTGACAGGAGGACAGTATGCCAGCAATGAACAGGCAATTGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTCTACTACTATATATGGCATGTACTCATGCGTCTAACCCCGTGGATGCTACCCTTAAGAATCGAATCTATTTTTATGATTCGATTATGAATTAA |
| Protein Sequence | MPKRDLPWRAMPGTSKVSRNANYSPRAGGGPKVNRASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQGFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVDATLKNRIYFYDSIMN |
| NCBI Accession | YP_010084729.1 |
|---|---|
| Location | 970-1368 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTTTATTTCAGGATGTACAAGGTAGAAGACCCATTATACACCAGGAGCAGGGTGTACAGCGTACAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAGGTTTAGGCACTTAGTCAATATGTATTTAGATCAGTTAGGAGTGATCTCACTTAACAATGTAATCAGAGCTGTTCGTTTCGCAACAGCCAGATCGTACGTTAATCATGTAATAGAGGATCATTCAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGELITAPQAENGVYIWEIENPLYFRMYKVEDPLYTRSRVYSVQIRFNHNLRRALHLHKAFLNFQVWTTSMTASGSTYLARFRHLVNMYLDQLGVISLNNVIRAVRFATARSYVNHVIEDHSIKFKIY |
| NCBI Accession | YP_010084730.1 |
|---|---|
| Location | 1115-1504 |
| Gene Name | AC2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCGGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCTATCAGGAGACGCAGGATTGATTTAGATTGCGGTTGCTCCATCTACTTCCACATAGACTGCACCGGGCATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTTTATTTCAGGATGTACAAGGTAGAAGACCCATTATACACCAGGAGCAGGGTGTACAGCGTACAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAG |
| Protein Sequence | MRSSSPSQPPSIKKAHRQAKRRAIRRRRIDLDCGCSIYFHIDCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPLFQDVQGRRPIIHQEQGVQRTDTVQPQPQESVASPQSLPELPSLDDIDDSFWVDLFS |
| NCBI Accession | YP_010084731.1 |
|---|---|
| Location | 1416-2513 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACGGAAGGGAGTGTTCTCTATAAAAGCCAAAAACTATTTCCTTACATATCCCCAGTGCTCTCTTAACAAAGAAGAGGCACTTTCCCAATTACAAAACCTAAACACTCCAGTCAACAAGAAGTTCATCAAGATCTGCAGAGAACTGCATGCAAATGGGGAGCCTCATCTCCATGTGCTCATCCAATTCGAAGGGAAATTCAACTGCACGAATAAGAGATTGTTCGATCTGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCCTGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGGGACACCGCCGAATGGGGGGTGTTCCAGATCGACGGCAGAAGTGCTAGAGGCGGTCAACAGACATCTAACGACGCAGCCGCCGAGGCGTTGAATGCTGGAACAAAGGAGGAGGCAATGAAAATCATCAAAGAGAAGTTGCCGGAAAAGTTTCTCTTCCAGTATCACAACCTATCCAGTAACCTAGATAGGATTTTCATGAAGGCTCCAGAGGCCCGTGGGTCTCCTCCGTTTCACCTCTCCTCTTTCACTAACGTGCCCGACGAGATGCAAGAGTGGGCGGACGATTATTTTGGGAGAGGTGCCGCTGCGCGGCCAGAGAGACCAGTAAGTCTCAGTAAGTCTCATAGTAGAGGGTCATTCAAGGACAGGGAAGACAACGTGGGCTCGTGCGCTAGGCCCACATACCTATCTTCGTGGACATCTGGACTTCAATCACCGGGTCTACTCGAACGAAGTGGAGTATACGTCATTGATGACGTCGCACCGCAATATCTAAAGATAAAGCACTGGAAGGAACTTCTTGGGGCCCAGAAGGACTGGCAATCAAATTGCAAGTACGGCAAGCCAGTTCAAATTAAAGGGGGTATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGACTTCCTGAGCAAAGAGGAAAACGCATCCCTCAGGAACTGGACAATAAAGAATGCGGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCTATCAGGAGACGCAGGATTGA |
| Protein Sequence | MPRKGVFSIKAKNYFLTYPQCSLNKEEALSQLQNLNTPVNKKFIKICRELHANGEPHLHVLIQFEGKFNCTNKRLFDLVSPTRSVHFHPNIQGAKSCSDVKSYVEKDGDTAEWGVFQIDGRSARGGQQTSNDAAAEALNAGTKEEAMKIIKEKLPEKFLFQYHNLSSNLDRIFMKAPEARGSPPFHLSSFTNVPDEMQEWADDYFGRGAAARPERPVSLSKSHSRGSFKDREDNVGSCARPTYLSSWTSGLQSPGLLERSGVYVIDDVAPQYLKIKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLSKEENASLRNWTIKNAVFITLTAPLYQEGTQASQEEGYQETQD |
| NCBI Accession | YP_010084732.1 |
|---|---|
| Location | 2099-2362 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGCAAATGGGGAGCCTCATCTCCATGTGCTCATCCAATTCGAAGGGAAATTCAACTGCACGAATAAGAGATTGTTCGATCTGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCCTGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGGGACACCGCCGAATGGGGGGTGTTCCAGATCGACGGCAGAAGTGCTAGAGGCGGTCAACAGACATCTAACGACGCAGCCGCCGAGGCGTTGA |
| Protein Sequence | MQMGSLISMCSSNSKGNSTARIRDCSIWCPQPGQYISIRTYRELNPAPTSSPTSRKTGTPPNGGCSRSTAEVLEAVNRHLTTQPPRR |
| NCBI Accession | YP_010084733.1 |
|---|---|
| Location | 431-1198 |
| Gene Name | NSP |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATTATTTTAGGAATAGACGTGGTTCGAATTCACACGGACGACGACATTATTCTCGTAATAATGTGTTCAAGCGTCCAATTTCATCAAAGAGGCATGATTGGAAACGTGGAGGAGTCAATTCCAGCAAGCCCAGTGATGAGCCCAAGATGAAGGTCCAACGCATTCATGAGAATCAGTATGGGTCCAACTTTGTAATGGCCCATAATTCAGCCATTTCTACGTACATCACTTATCCCAGCTTGGGGAAGATCGAACCCAGCAGGAGCAGGTCCTATATTAAGTTGAACCGCTTGCGTTTCAAAGGGACCGTTAAGATTGAACGTGTTCAACCGGACATGAATCTGGACGTTGCTATCCCCAAGGTGGAAGGAGTCTTCACCCTCGTTGTGGTTGTGGATCGGAAACCGCATCTTGATCCATCTGGTGGTCTGCAAACGTTTGACGATCTTTTCGGTGCTAGGATACACAGTCACGGTAACCTCAGCATAATTCCTACGTTGAAAGACCGCTATTATATCCGACACGGTTCAAACGTTGTTGTCGTTGAGAAAGACACGCTGATGGTAGACGTGGAAGGATCCATTCCCCTCTCTAACAGGCGTTATAATTGTTGGTCCACGTTTAAGGATCTGGATCGAGAATCATGCAATGGCGTTTACGGCAACATTAACAAGAACGCCCTGTTAGTCTATTACTGTTGGATGTCGGATACGATGTCTAATGCATCGACATTTGTAACTTATGATCTGGATTATATTGGATGA |
| Protein Sequence | MYYFRNRRGSNSHGRRHYSRNNVFKRPISSKRHDWKRGGVNSSKPSDEPKMKVQRIHENQYGSNFVMAHNSAISTYITYPSLGKIEPSRSRSYIKLNRLRFKGTVKIERVQPDMNLDVAIPKVEGVFTLVVVVDRKPHLDPSGGLQTFDDLFGARIHSHGNLSIIPTLKDRYYIRHGSNVVVVEKDTLMVDVEGSIPLSNRRYNCWSTFKDLDRESCNGVYGNINKNALLVYYCWMSDTMSNASTFVTYDLDYIG |
| NCBI Accession | YP_010084734.1 |
|---|---|
| Location | 1267-2148 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGATTCTCAGTTGGTTAATCCTCCGCATGCCTTCAATTACATAGAGTCCCATAGGGACGAATATCAGCTTTCGCATGACCTAACTGAGATCGTTCTGCAATTTCCGTCGACGGCGTCTCAGTTGACGGCTAGACTCAGTCGTAGCTGCATGAAGATCGACCACTGCGTCATAGAATACAGGCAGCAAGTTCCGATCAACGCGACGGGGTCGGTAATTGTGGAGATCCACGACAAGAGGATGACGGACAACGAGTCACTGCAGGCGTCGTGGACTTTTCCGATCAGATGCAACATAGATCTCCACTACTTTTCAGCTTCATTCTTCTCGCTCAAGGACCCAATTCCATGGAAACTCTATTACAGAGTTTGCGACACGAATGTTCATCAGAGGACCCACTTCGCGAAGTTCAAAGGGAAGCTGAAATTATCGACGGCGAAACACTCCGTCGACATCCCTTTCCGGGCACCAACAGTAAAGATCTTGTCCAAACAGTTCACGGACAAAGATGTGGACTTTTCCCATGTCGACTACGGAAGATGGGAAAGGAAGCCCATCAGATGCGCGTCCATGTCAAGGGTTGGGCTTCGAGGCCCAATAGAGATAAGGCCTGGTGAATCGTGGGCTTCCAGGAGCACCATAGGAACGGGCCATTCAGAGGCGGACTCGGAGGTGGAGAACGAACTCCACCCTTACAGACACCTGAGCAGGCTCGGGACCACCGTTCTAGACCCAGGAGAGTCTGCGTCAGTTATAGGAGCCCAGAGAGCGGAGTCCAACATCACGATGTCAATGGGCCAGTTGAACGAGCTCGTTAGGACTACTGTCCAGGAGTGTATCAATAGTAATTGTAGACCTTCACAGCCCAAATCATTGCAGTAG |
| Protein Sequence | MDSQLVNPPHAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGTGHSEADSEVENELHPYRHLSRLGTTVLDPGESASVIGAQRAESNITMSMGQLNELVRTTVQECINSNCRPSQPKSLQ |
References More References in PubMed
| 1 |
Tomato mottle wrinkle virus, a recombinant begomovirus infecting tomato in Argentina. Vaghi Medina CG, et al. Arch Virol. 2015 Feb;160(2):581-5. doi: 10.1007/s00705-014-2216-y. Epub 2014 Sep 25. PMID: 25252814 |
|---|---|
| 2 |
Zhang S, et al. Mol Plant Pathol. 2022 Sep;23(9):1262-1277. doi: 10.1111/mpp.13229. Epub 2022 May 22. PMID: 35598295 |
| 3 |
Sabra A, et al. Plants (Basel). 2022 Nov 18;11(22):3157. doi: 10.3390/plants11223157. PMID: 36432886 |
| 4 |
Romay G, et al. Arch Virol. 2018 Feb;163(2):555-558. doi: 10.1007/s00705-017-3611-y. Epub 2017 Oct 20. PMID: 29058148 |