Tomato twisted leaf virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_013088455.1 |
| Isolate | Venezuela |
| Release date | 2021/6/1 |
| Submitter | Romay,G., Geraud-Pouey,F., Chirinos,D.T., Mahillon,M., Gillis,A., Mahillon,J., Bragard,C. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
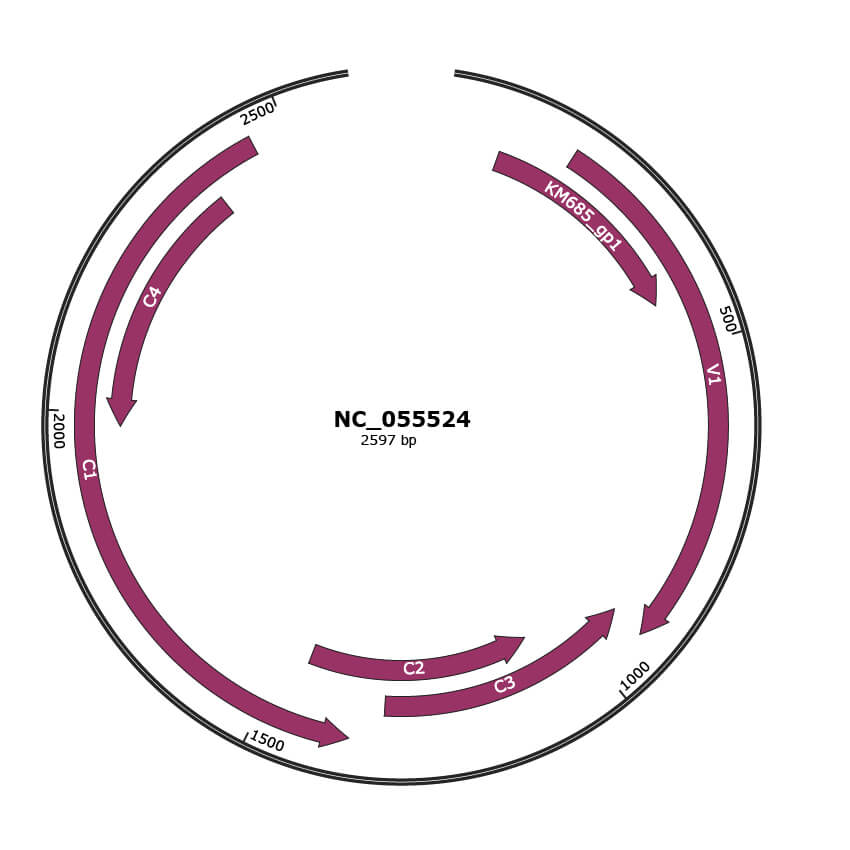
Genomic Organization
JBrowse
Genome
NC_055524
Gene Information
| NCBI Accession | YP_010087241.1 |
|---|---|
| Location | 85-426 |
| Protein Name | hypothetical protein |
| Coding Region | ATGAGAGAGCGTCTGTGGAGCCTAGATATTATGACTTGGTCCCTAAGTTGTGGGCCTATAAAAGAAATGACGCTCTCTCTCTGTCACTTTAATTCGAAATGCCTAAGCGGGATGCCCCATGGCGCACTATTGCGGGGACCTCAAAGGTCTCTCGCTCTTCTACTCAGTCGCCTCGTGGTGGTATGGGCCCTAAGGCAACTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGAACTTGGAGATCACCTGACGTCCCCAAGGGATGTGAAGGCCCATGTAAGGTTCAGTCTTTTGAGCAGCGTCACGATATCTCTCATGTTGGGAAGGTGA |
| Protein Sequence | MRERLWSLDIMTWSLSCGPIKEMTLSLCHFNSKCLSGMPHGALLRGPQRSLALLLSRLVVVWALRQLLGLTGPCTGSPGSTELGDHLTSPRDVKAHVRFSLLSSVTISLMLGR |
| NCBI Accession | YP_010087242.1 |
|---|---|
| Location | 183-929 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCATGGCGCACTATTGCGGGGACCTCAAAGGTCTCTCGCTCTTCTACTCAGTCGCCTCGTGGTGGTATGGGCCCTAAGGCAACTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGAACTTGGAGATCACCTGACGTCCCCAAGGGATGTGAAGGCCCATGTAAGGTTCAGTCTTTTGAGCAGCGTCACGATATCTCTCATGTTGGGAAGGTGATCTGTATATCCGATGTTACTCGTGGTCCTGGTATCACTCACCGTGTTGGGAAACGTTTCTGCGTGAAGTCAGTCTACATTCTAGGCAAGATATGGATGGACGAGAACATCAAACTTAAGAACCACACTAACAGCGTCATGTTCTGGTTAGTTAGGGACAGGAGACCATATGGCACCCCCATGGATTTTGGCCAAGTTTTCAACATGTACGACAACGAGCCCAGTACTGCCACTGTGAAGAACGATCTCCGTGATCGTTTCCAAGTTATGCACAGGTTCTACGCTAAGGTTACCGGTGGTCAGTATGCTAGCAACGAGCAGGCTCTAGTCAGGCGATTTTGGAAGGTCCACAACCATGTGGTCTACAACCATCAGGAAGCTGGGAAGTACGAGAATCACACTGAGAACGCCCTATTATTGTATATGGCATGCACTCATGCCTCTAACCCTGTATATGCTACGTTGAAAATACGTAGCTATTTTTATGACTCGATCAGCAATTAA |
| Protein Sequence | MPKRDAPWRTIAGTSKVSRSSTQSPRGGMGPKATAWVNRPMYRKPRIYRTWRSPDVPKGCEGPCKVQSFEQRHDISHVGKVICISDVTRGPGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQALVRRFWKVHNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRSYFYDSISN |
| NCBI Accession | YP_010087243.1 |
|---|---|
| Location | 926-1324 |
| Gene Name | C3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACCGGGGAGAACATCACTGTGCGTCAGGCAGAGAGTTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTTTATTTCAAGATTCAACAAGTAGAGGATCCAATTCACACGTCGCTCAGGATTTACCACATCCAGATCCGGTTCAACCACAACCTCAGGAGGGCGTTGAATCTTCACAAAGCTTTCCTGAACTTCCAAGTCTGGACGACATCAGTTCGAGCTTCTGGGACGACATATTTAAATAGATTTAGATATTTAGTTTTATTGTATTTAGATAGGATAGGTGTTATCGGAATTAATAATGTAATACGTGCAGTTCGTTTCGCAACGGACAAATCATATGTAAATTATGTACACGAGAATCATGAAATAAAATTCAACTTTTATTAA |
| Protein Sequence | MDSRTGENITVRQAESSVFIWEVPNPLYFKIQQVEDPIHTSLRIYHIQIRFNHNLRRALNLHKAFLNFQVWTTSVRASGTTYLNRFRYLVLLYLDRIGVIGINNVIRAVRFATDKSYVNYVHENHEIKFNFY |
| NCBI Accession | YP_010087244.1 |
|---|---|
| Location | 1071-1460 |
| Gene Name | C2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAGGCACAGCACAGAATCGCCAAGAAGAGGGCACTCAGACGGAGACGCATTGACTTGAACTGCGGCTGTTCAATCTTCATGCACATCAACTGCTCTAATAATGGATTCACGCACCGGGGAGAACATCACTGTGCGTCAGGCAGAGAGTTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTTTATTTCAAGATTCAACAAGTAGAGGATCCAATTCACACGTCGCTCAGGATTTACCACATCCAGATCCGGTTCAACCACAACCTCAGGAGGGCGTTGAATCTTCACAAAGCTTTCCTGAACTTCCAAGTCTGGACGACATCAGTTCGAGCTTCTGGGACGACATATTTAAATAG |
| Protein Sequence | MLNSSSSTPPSIKAQHRIAKKRALRRRRIDLNCGCSIFMHINCSNNGFTHRGEHHCASGREFRFYLGGSKSPLFQDSTSRGSNSHVAQDLPHPDPVQPQPQEGVESSQSFPELPSLDDISSSFWDDIFK |
| NCBI Accession | YP_010087245.1 |
|---|---|
| Location | 1372-2451 |
| Gene Name | C1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACGAAACCCTAATTCATTTCGCTTACAAGCCAGAAATATCTTTTTAACATATCCCCAGTGCGACATATCCAAAGATGAGGCTATTGAGATGCTTCAAGCACTCTCATGGTCAATCGTCAAACCAACCTACATCAGAGTCGCAAGAGAGGAACACTCCGACGGTCTCCCACATCTCCACTGTCTCATCCAGCTCTCCGGCAAGTCAAACATCAAGGATGCTAGGTTTTTCGACCTTACTCACCCCAGAAGGTCTTCCACTTTTCACCCAAATGTCCAGGCAGCCAAAGACGCCAATGCCGTCAAGAACTACATCACCAAGGAGGGTGATTATTGTGAATCCGGACAATACAAAGTGTCTGGCGGAACAAAGTCAAATAAAGACGACGTGTATCACAACGCCGTCCATGCATCTAGTGTGGGAGAAGCTATCGACATTATCCGTGCAGGAGATCCAAAGACGTTCATAGTCAGTTACCATAACATAAAATCGAATTTAGAACGTCTTTTTCAAAAGGCTCCAGAACCATGGGTTCCTCCGTTTCAACTCTCCTCTTTCACTAACGTACCGGAGGAGATGCAAGAGTGGGCTGATGATTACTTTGGGAGGAGTTCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATCGTCGAAGGTGATAGTCGTACAGGGAAGACCATGTGGGCACGTGCATTGGGGTCCCACAATTATTTGAGCGGTCATTTAGATTTCAATGCAAGGGTCTATTCAAATGAAGTGGAGTATAACGTCATTGATGACATAACTCCGCATTATCTAAAGTTAAAGCATTGGAAGGAGTTAATTGGCGCTCAAAAGGACTGGCAGTCAAACTGTAAATACGGAAAGCCAGTTCAAATTAAAGGCGGTATCCCATCAATCGTGCTGTGCAATCCAGGAGAGGGGAGCAGCTATAAAGAATTCCTCGACAAAGAGGAAAATGCAGCTCTGAGGGCGTGGACGCTTAAGAATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAGGCACAGCACAGAATCGCCAAGAAGAGGGCACTCAGACGGAGACGCATTGA |
| Protein Sequence | MPRNPNSFRLQARNIFLTYPQCDISKDEAIEMLQALSWSIVKPTYIRVAREEHSDGLPHLHCLIQLSGKSNIKDARFFDLTHPRRSSTFHPNVQAAKDANAVKNYITKEGDYCESGQYKVSGGTKSNKDDVYHNAVHASSVGEAIDIIRAGDPKTFIVSYHNIKSNLERLFQKAPEPWVPPFQLSSFTNVPEEMQEWADDYFGRSSAARPERPISIIVEGDSRTGKTMWARALGSHNYLSGHLDFNARVYSNEVEYNVIDDITPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKEFLDKEENAALRAWTLKNAKFIFLDAPLYQGTAQNRQEEGTQTETH |
| NCBI Accession | YP_010087246.1 |
|---|---|
| Location | 1980-2372 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGAGGCTATTGAGATGCTTCAAGCACTCTCATGGTCAATCGTCAAACCAACCTACATCAGAGTCGCAAGAGAGGAACACTCCGACGGTCTCCCACATCTCCACTGTCTCATCCAGCTCTCCGGCAAGTCAAACATCAAGGATGCTAGGTTTTTCGACCTTACTCACCCCAGAAGGTCTTCCACTTTTCACCCAAATGTCCAGGCAGCCAAAGACGCCAATGCCGTCAAGAACTACATCACCAAGGAGGGTGATTATTGTGAATCCGGACAATACAAAGTGTCTGGCGGAACAAAGTCAAATAAAGACGACGTGTATCACAACGCCGTCCATGCATCTAGTGTGGGAGAAGCTATCGACATTATCCGTGCAGGAGATCCAAAGACGTTCATAG |
| Protein Sequence | MRLLRCFKHSHGQSSNQPTSESQERNTPTVSHISTVSSSSPASQTSRMLGFSTLLTPEGLPLFTQMSRQPKTPMPSRTTSPRRVIIVNPDNTKCLAEQSQIKTTCITTPSMHLVWEKLSTLSVQEIQRRS |
References More References in PubMed
| 1 |
Romay G, et al. Viruses. 2019 Apr 4;11(4):327. doi: 10.3390/v11040327. PMID: 30987360 |
|---|---|
| 2 |
Venkataravanappa V, et al. Acta Virol. 2015 Jun;59(2):125-39. doi: 10.4149/av_2015_02_125. PMID: 26104329 |
| 3 |
Spinach latent virus Infecting Tomato in Virginia, United States. Vargas-Asencio J, et al. Plant Dis. 2013 Dec;97(12):1663. doi: 10.1094/PDIS-05-13-0529-PDN. PMID: 30716862 |
| 4 |
Pest categorisation of non-EU viruses and viroids of Prunus L. EFSA Panel on Plant Health (PLH), et al. EFSA J. 2019 Sep 30;17(9):e05735. doi: 10.2903/j.efsa.2019.5735. eCollection 2019 Sep. PMID: 32626421 |
| 5 |
Venkataravanappa V, et al. Virusdisease. 2022 Jun;33(2):194-207. doi: 10.1007/s13337-022-00772-0. Epub 2022 Jul 1. PMID: 35991698 |
| 6 |
Leaf Curl Disease of Carica papaya from India May Be Caused by a Bipartite Geminivirus. Saxena S, et al. Plant Dis. 1998 Jan;82(1):126. doi: 10.1094/PDIS.1998.82.1.126A. PMID: 30857046 |
| 7 |
Mackie AE, et al. Plant Dis. 2019 Dec;103(12):3009-3017. doi: 10.1094/PDIS-02-19-0312-RE. Epub 2019 Sep 25. PMID: 31567060 |
| 8 |
First Report of a Phytoplasma Affecting Tomato in Poland. Pospieszny H, et al. Plant Dis. 2007 Aug;91(8):1054. doi: 10.1094/PDIS-91-8-1054B. PMID: 30780451 |