Tomato severe rugose virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000874065.1 |
| Isolate | Brazil |
| Release date | 2015/2/13 |
| Submitter | Bezerra-Agasie,I.C., Ferreira,G.B., Avila,A.C., Inoue-Nagata,A.K., Hallwass,M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
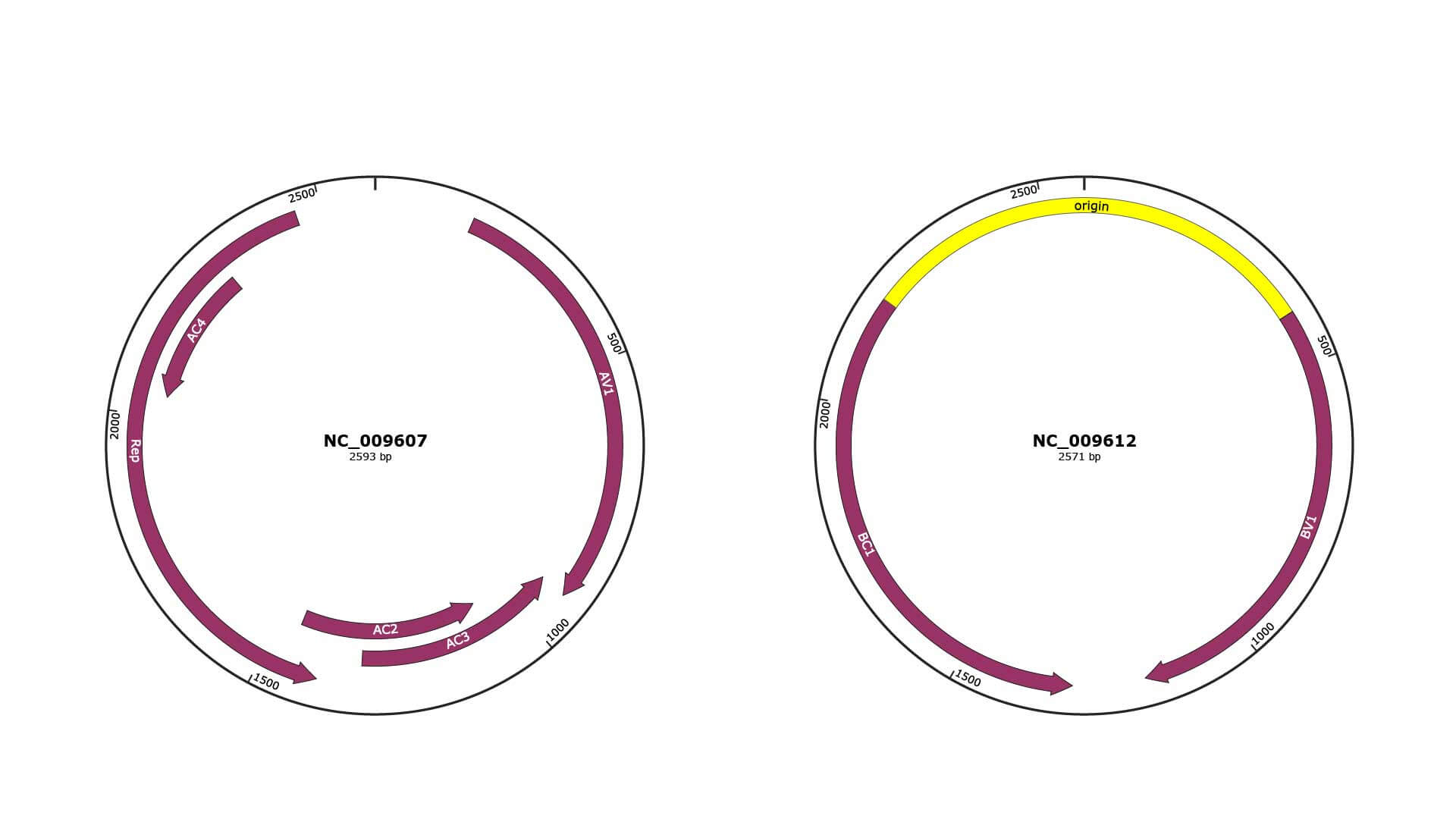
JBrowse
Genome
NC_009607
NC_009612
Gene Information
| NCBI Accession | YP_001294919.1 |
|---|---|
| Location | 171-926 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGTGATGCCCCATGGCGTTTAACGGCGGGAACTTCAAAGGTTTCCCGCTCTGTCAATTATTCTCCCCGTGCAGGATATGGACCCAAATATAATAAGGCCGCTGAGTGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGTACTTTGAGAGGCCCAGATGTTCCTAGAGGCTGTGAAGGGCCTTGTAAGGTTCAGTCTTACGAGTCTCGTCATGATGTTTCCCATGTCGGGAAGGTGATTTGTGTGTCTGACGTTACACGTGGTAACGGTATTACTCACCGTGTTGGTAAGCGTTTCTGCGTGAAGTCTGTATATATTTTAGGGAAGGTATGGATGGACGAGAGCATCAAGTTGAAGAATCACACAAATAGTGTGATGTTCTGGTTGGTTAGAGATCGGAGACCTTATTCGACACCTATGGATTTTGGCCAGGTGTTCAACATGTTTGACAACGAGCCTAGCACTGCAACTGTTAAGAACGATCTTCGGGATCGTTTTCAGGTCATGCACAAGTTTTATGCCAAGGTTACTGGTGGACAGTATGCCAGTAATGAGCAGGCATTAGTGAAGCGCTTTTGGAAGGTCAACAACAACGTAGTCTACAACCATCAGGAGGCAGGGAAATACGAGAATCATACTGAGAACGCCTTGCTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATTACTAATTAA |
| Protein Sequence | MPKRDAPWRLTAGTSKVSRSVNYSPRAGYGPKYNKAAEWVNRPMYRKPRIYRTLRGPDVPRGCEGPCKVQSYESRHDVSHVGKVICVSDVTRGNGITHRVGKRFCVKSVYILGKVWMDESIKLKNHTNSVMFWLVRDRRPYSTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNNVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_001294920.1 |
|---|---|
| Location | 923-1321 |
| Gene Name | AC3 |
| Protein Name | AC3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTTTATATTTGGGAGATATCAAATCCCCTCTATTTCAAGATAAACAGAGTGGAGGATCCAATGTACACCGCGAGCAGAGTCTACCACGTCCAAATACGGTTCAACCACAACCTGAGGAGAGCATTGCATCTCCACAAGAGCTTCCTCAACTTCCAGATATGGACGACTTCACTGACAGCTTCTGGGACGACATATTTAACTAGATTTAAATATTTAGTCTTATTGTATCTAGATCGATTAGGCGTTATTTCCATTAATAATGTAATCAGAGCTGTTCGTTTTGCAACAGACAAATCATATGTAAATGCTGTACTCGAAAATCATTCAATAAAATTTAAATTTTATTAA |
| Protein Sequence | MDSRTGELITARQAENGVYIWEISNPLYFKINRVEDPMYTASRVYHVQIRFNHNLRRALHLHKSFLNFQIWTTSLTASGTTYLTRFKYLVLLYLDRLGVISINNVIRAVRFATDKSYVNAVLENHSIKFKFY |
| NCBI Accession | YP_001294921.1 |
|---|---|
| Location | 1068-1457 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGCGAAATTCGTCTTCCTTAACACCCCCCTCTATCAAGGTACAACACAGAGTTGCTAAAAAACGAGGAATCAGGAGACGACGAATTGATATAGAGTGCGGGTGCTCTATTTACGTACACATCGACTGCAGAGGACATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTTTATATTTGGGAGATATCAAATCCCCTCTATTTCAAGATAAACAGAGTGGAGGATCCAATGTACACCGCGAGCAGAGTCTACCACGTCCAAATACGGTTCAACCACAACCTGAGGAGAGCATTGCATCTCCACAAGAGCTTCCTCAACTTCCAGATATGGACGACTTCACTGACAGCTTCTGGGACGACATATTTAACTAG |
| Protein Sequence | MRNSSSLTPPSIKVQHRVAKKRGIRRRRIDIECGCSIYVHIDCRGHGFTHRGTHHCTSGREWRLYLGDIKSPLFQDKQSGGSNVHREQSLPRPNTVQPQPEESIASPQELPQLPDMDDFTDSFWDDIFN |
| NCBI Accession | YP_001294922.1 |
|---|---|
| Location | 1399-2457 |
| Gene Name | Rep |
| Protein Name | Rep |
| Coding Region | ATGCCATCAGCTCCAAAGCGCTTTCAAATAAAAGCGAAGAATTATTTCCTCACATATCCCAAATGCTCATTATCGAAAGAAGAAGCACTTTCCCAATTAAAAACCCTAAACACTCCTACAAATAAGAAGTTCATCAAGGTTTGCAGAGAGCTCCATGAAAATGGGGAGCCTCATCTCCACGTGCTTCTTCAATTTGAGGGCAACTACTGCTGCCAAAATCAACGATTCTTCGACCTGGTCTCCCCAACAAGGTCAACACATTTCCATCCGAACATTCAGAGAGCTAAGTCATCGTCCGACGTCAAATCCTATGTCGATAAGGACGGAGATACTATCGAGTGGGGGGAATTCCAAATCGACGGAAGAAGTGCTAGAGGCGGTTGCCAGACAGCTAACGACGCTGCCGCAGAAGCCTTGAACGCACCTTCCAAAGACGTCGCCTTGCAGATAATCCGTGAGAAGCTGCCTGAAAAGTTCTTATTTCAGTTTCACAATCTAAATAGTAATTTAGATAGGATATTTACAAGGGCTCCGGAGCCATGGGCCCCTACGTTTCCCCTCTCCTCTTTCACTAGCGTACCGAGAGAGATGCAAGCTTGGGCAGATGACTCTTTTGGGAGAGGTGCCGCTGCGCGGCCGGAACGACCTATTAGTATCATCATTGAAGGTGATTCTCGAACGGGAAAGACGATGTGGGCACGTGCATTAGGGGCCCATAATTATTTGAGTGGACACCTAGATTTCAATCCTAGGGTTTATTCAAATCATGTTGAATATAACGTCATTGATGACATCGCACCGCACTATCTAAAGTTAAAGCACTGGAAAGAATTGCTTGGGGCCCAAAAGGATTGGCAATCAAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGTATCCCATGCATCGTGCTTTGCAATCCTGGCGAGGGGGCCAGCTATAAATGTTTCCTCGACAAAGAAGAAAATGCAAGTCTAAATAATTGGACAAAGCACAATGCGAAATTCGTCTTCCTTAACACCCCCCTCTATCAAGGTACAACACAGAGTTGCTAA |
| Protein Sequence | MPSAPKRFQIKAKNYFLTYPKCSLSKEEALSQLKTLNTPTNKKFIKVCRELHENGEPHLHVLLQFEGNYCCQNQRFFDLVSPTRSTHFHPNIQRAKSSSDVKSYVDKDGDTIEWGEFQIDGRSARGGCQTANDAAAEALNAPSKDVALQIIREKLPEKFLFQFHNLNSNLDRIFTRAPEPWAPTFPLSSFTSVPREMQAWADDSFGRGAAARPERPISIIIEGDSRTGKTMWARALGAHNYLSGHLDFNPRVYSNHVEYNVIDDIAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPCIVLCNPGEGASYKCFLDKEENASLNNWTKHNAKFVFLNTPLYQGTTQSC |
| NCBI Accession | YP_001294923.1 |
|---|---|
| Location | 2040-2303 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAAATGGGGAGCCTCATCTCCACGTGCTTCTTCAATTTGAGGGCAACTACTGCTGCCAAAATCAACGATTCTTCGACCTGGTCTCCCCAACAAGGTCAACACATTTCCATCCGAACATTCAGAGAGCTAAGTCATCGTCCGACGTCAAATCCTATGTCGATAAGGACGGAGATACTATCGAGTGGGGGGAATTCCAAATCGACGGAAGAAGTGCTAGAGGCGGTTGCCAGACAGCTAACGACGCTGCCGCAGAAGCCTTGA |
| Protein Sequence | MKMGSLISTCFFNLRATTAAKINDSSTWSPQQGQHISIRTFRELSHRPTSNPMSIRTEILSSGGNSKSTEEVLEAVARQLTTLPQKP |
| NCBI Accession | YP_001294933.1 |
|---|---|
| Location | 410-1180 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATCCCATTAAGTATAGACGTGGAATGTTGTTTAATCATCGACGAGGTTACTCATCTAATCCCGTATTTAAGCGTTTACACGGAACGAAACGAAGTGATATCAAGCGTCGTTCGAGTAATCAGATTAAGAGTATGGATGAGACTAAAATGTCTGTTCAGCGGATTCATGAGAACCAGTTTGGCCCTGAATTTGTAATTGGCCACAATTCTGCCATATCCACATTCATTACATTCCCTACTCTTTGTAAGACTGTCCCGAACCGTTGTAGGTCATACATAAAGTTAAGACGACTACGTTTTAAAGGAACAATCAAGATTGACCGTGTTCATGCTGAGGTGAATATGGACGGTACAAGTCCAATGATTGAAGGAGTCTTCTCTCTGGTTGTAGTCGTTGATCGCAAACCTCATTTGGGCTCATCTGGAACTCTGCATTCTTTTGATGAGATATTTGGTGCAAGGATTCATAGCCATGGTAACCTGGCAATAGTATCCTCTCTGAAAGAGCGTTTTTACATACGTCACGTTTGGAAGAAAGTAATATCTGTTGAGAAGGATACAACCATGGTTGATGTTGAAGGAAGTACTGTTTTATCTAACAGGCGTTTTAATTGTTGGTCATCCTTTAAGGATATTGACCGTGAATCATGTAATGGTGTTTATGCAAACATAAGCAAGAACGCCCTGTTAGTTTATTACTGTTGGATGTCTGATAATGTGTCTAAGGCATCGACATTTGTATCATTTGACCTTGATTATGTTGGCTAA |
| Protein Sequence | MYPIKYRRGMLFNHRRGYSSNPVFKRLHGTKRSDIKRRSSNQIKSMDETKMSVQRIHENQFGPEFVIGHNSAISTFITFPTLCKTVPNRCRSYIKLRRLRFKGTIKIDRVHAEVNMDGTSPMIEGVFSLVVVVDRKPHLGSSGTLHSFDEIFGARIHSHGNLAIVSSLKERFYIRHVWKKVISVEKDTTMVDVEGSTVLSNRRFNCWSSFKDIDRESCNGVYANISKNALLVYYCWMSDNVSKASTFVSFDLDYVG |
| NCBI Accession | YP_001294934.1 |
|---|---|
| Location | 1306-2187 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGAATCTCAGCTTGTAAATCCTCCCAACGCATTTAATTATATAGAATCTAAGCGTGATGAATATCAGCTTTCCCATGATCTAACCGAGATTATGCTTCAATTCCCTTCAACGGCGTCTCAATTAAGCGCAAGGCTTAGTCGTAGCTGTATGAAAATCGACCATTGCGTAATAGAATACAGACAACAGGTACCAATTAACGCCGTAGGTTCAGTTATAGTCGAAATTCATGACAGAAGAATGACGGACAATGAATCACTACAGGCGTCTTGGACCTTTCCTATCAGATGTAACATAGATCTTCACTACTTTTCGTCGTCGTTCTTCTCCCTTAAGGACCCAATTCCATGGAAATTGTACTACAGAGTATGTGACACGAACGTTCACCAGAGTACCCACTTCGCTAAATTCAAAGGGAGACTGAAACTCTCGACGGCTAAACATTCGGTTGATATACCTTTCCGTGCCCCAACGGTGAAGATTCTTTCAAAACAATTTACAGATAAGGACATTGATTTCAGTCACGTAGGCTATGGCAAATGGGAAAGGAAGATGATCAGATCCGCCTCAATATCAAGATTGGGCCTTCACAACCCACTTGAAATAATGCCCGGAGAGTCATGGGCTGTTAGAAGTACTGTAGGCATAAGCCCATCAGAGGCGGGCTCAGATATAGAGAACGCGATGCATCCATACAGACAATTACATAGATTGGGTACAGGCACATTAGACCCAGGTGATTCTGCGTCCATAATTGGTGCTCAAAGGGCCCAATCGAACATAACACTGTCAATGGCCCAATTAAACGAACTTGTTAAAGCAGCGGCCCATGAATGTATAAACAGCAACTGTACTCCTTCACAGCCAAAATCTTTAAAATAA |
| Protein Sequence | MESQLVNPPNAFNYIESKRDEYQLSHDLTEIMLQFPSTASQLSARLSRSCMKIDHCVIEYRQQVPINAVGSVIVEIHDRRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVHQSTHFAKFKGRLKLSTAKHSVDIPFRAPTVKILSKQFTDKDIDFSHVGYGKWERKMIRSASISRLGLHNPLEIMPGESWAVRSTVGISPSEAGSDIENAMHPYRQLHRLGTGTLDPGDSASIIGAQRAQSNITLSMAQLNELVKAAAHECINSNCTPSQPKSLK |
References More References in PubMed
| 1 |
Zhang S, et al. Mol Plant Pathol. 2022 Sep;23(9):1262-1277. doi: 10.1111/mpp.13229. Epub 2022 May 22. PMID: 35598295 |
|---|---|
| 2 |
Comparative Analysis of Tomato Brown Rugose Fruit Virus Isolates Shows Limited Genetic Diversity. Abrahamian P, et al. Viruses. 2022 Dec 17;14(12):2816. doi: 10.3390/v14122816. PMID: 36560820 |
| 3 |
Intra-host evolution of the ssDNA virus tomato severe rugose virus (ToSRV). Pinto VB, et al. Virus Res. 2021 Jan 15;292:198234. doi: 10.1016/j.virusres.2020.198234. Epub 2020 Nov 21. PMID: 33232784 |
| 4 |
Engineered Resistance to Tobamoviruses. Carr JP. Viruses. 2024 Jun 22;16(7):1007. doi: 10.3390/v16071007. PMID: 39066170 |
| 5 |
Tomato Brown Rugose Fruit Virus Contributes to Enhanced Pepino Mosaic Virus Titers in Tomato Plants. Klap C, et al. Viruses. 2020 Aug 11;12(8):879. doi: 10.3390/v12080879. PMID: 32796777 |
| 6 |
Favara GM, et al. Plant Dis. 2023 Apr;107(4):1087-1095. doi: 10.1094/PDIS-10-21-2160-RE. Epub 2023 Apr 19. PMID: 36096104 |
| 7 |
Nogueira AM, et al. Viruses. 2023 Oct 11;15(10):2074. doi: 10.3390/v15102074. PMID: 37896851 |
| 8 |
Solanum elaeagnifolium and S. rostratum as potential hosts of the tomato brown rugose fruit virus. Matzrafi M, et al. PLoS One. 2023 Mar 1;18(3):e0282441. doi: 10.1371/journal.pone.0282441. eCollection 2023. PMID: 36857395 |
| 9 |
Zisi Z, et al. Front Plant Sci. 2024 May 7;15:1382862. doi: 10.3389/fpls.2024.1382862. eCollection 2024. PMID: 38774217 |
| 10 |
Sabra A, et al. Plants (Basel). 2022 Nov 18;11(22):3157. doi: 10.3390/plants11223157. PMID: 36432886 |