Tomato severe leaf curl Kalakada virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004787335.1 |
| Isolate |
India: Kalakada, Andhra Pradesh |
| Release date |
2021/6/1 |
| Submitter |
Swarnalatha,P., Venkatravanappa,V., Jalali,S., Krishna Reddy,M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
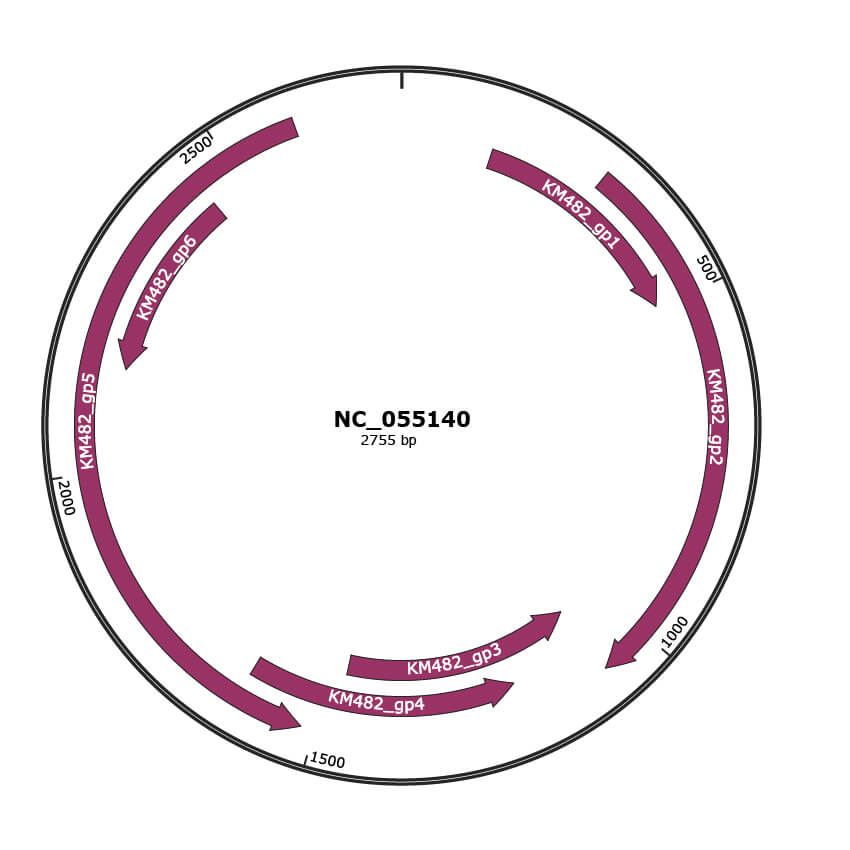
JBrowse
Genome
ACCGAATGGCCGCGCTTTTCTGTCACGGTCATGGTCCCCTCCACTAATTCATGTCCGCCAATCATATGTCATCCTGAAAGCTTAATTATTTATTTTTGTCCTTATATAAATTTAGTCACCAAGTTTTACCATTATTTAAAATGTGGGATCCACTTTTAAATGAATTTCCTGAAACTGTTCACGGATTCAGGTGTATGCTTGCTATAAAATACCTGCAGTTGGTAGAAAATACGTATTCCCCTGATTCGTTGGGATACGACCTAATACGTGATTTAATTTCCGTCGTCAGGGCCAAAAGCTATGTCCAAGCGTCCGGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGCCGACTTCTGAGCTCAATCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGGATGTACAGAGGTCCAGATGTTCCTAGAGGCTGTGAGGGTCCATGTAAGGTCCAGTCTTTTGAGTCAAGACACGATGTAGTTCATATAGGGAAGGTCATGTGTATTAGTGATGTGACTCGTGGTATGGGGCTGACCCATCGAGTGGGTAAGCGATTTTGCGTTAAGTCTGTATACGTTGTGGGTAAGATATGGATGGATGAGAATATCAAGACTAAGAATCACACGAATAGTGTGATGTTCTTCCTTGTACGTGATCGTCGTCCAAATGATAAACCACAAGATTTTGGAGAGGTGTTCAACATGTTTGACAATGAGCCTAGCACTGCAACTGTAAAGAATATGCATAGGGATCGTTATCAGGTTTTGAGGAAATGGCACGCAACTGTTACCGGTGGACAGTATGCTTCGAAGGAACAGGCATTAGTTAAGAAGTTCGTTAGGGTTAACAATTATGTTGTGTATAACCAGCAGGAAGCTGGGAAATATGAAAATCATTCTGAGAATGCTCTGATGTTGTACATGGCATGTACCCATGCCTCTAATCCTGTGTATGCTACTTTGAAGATACGGATCTACTTCTATGATTCAGTATCGAATTAATAAAGATTGAATTTTATTGAATACGACTGTTGTACATGTACAGTGTGTTGTAATACGTTCCATAATACATGTTCAACTGCTCTGATTACATTATTAATTCTAATTACAGCAAAATTATTTAATAACTTAAGCACCTGGGTTTTGAAGACCCTTAAGAAATGACCAGTCAGAGGCTGTGAAGTCGTCCAGATTCGGAAGGTTAGGGAACATTTGTGTATCTCCAAAGTTTTCCGCAGGTGGTGATTGAACTGTATCTGGACGGTGAGGATGTCGTGGTTTCTCAGAAAGGCCTGGTTGTGGTGCTCTGTTATCTTGAAAAACAGGGGATTTTGAATTTCCCAGATAAACACGCCATTCTCTGCTTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATAGCCGTGGCAGCGTAATGCGATGAAATATGAGCAGCCGCAGTCGAGGTCAACGCGACGACGCCTGGTCCCCTTCTTGGCCAGCCTGTGCTGCACTTTGATTGGAACCTGAGTAGAGTGGGCCTTGGAGGGTGATGAAGGTCGCATTCTTTAAAGCCCAATTCTTTAGTGCGGAATGTTTCTCTTCATCCAAGAACTCTTTATAGCTTGAATTGGGTCCTGGATTGCAGAGGAAGATAGCGGGAATTCCACCTTTAATTTGAACTGGCTTTCCGTATTTTGTATTTGATTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGATAATGCGGATCAACGTCATCAATGACGTTATACCATGCATCATTGCTGTACACCTTAGGGCTAAGGTCTAGGTGACCACATAGGTAGTTATGTGGACCCAATGACCTAGCCCACATTGTTTTCCCCGTTCTACTGTCACCCTCAATCACTATACTTATGGGCCTTATAGGCCGCGCAGCGGCACTAACGACGTTGTCGGCAGCCCACTCCTCAAGTTCTTCTGGAACTTGATCAAATGAAGAAGAAGAAAAAGGAGAAACATAAACCTCCATTGGAGGTGTAAAAATCCTATCTAAATTACATTTTAAATTATGGTATTGAAAAATAAAATCTTTGGGGAGTTTTTCCCTTAATACTTTGAGAGCTGCTTCCGCTGAACCTGCATTGAGCGCCTCTGCTGCAGCATCATTAGTTGTCTGTTGACCTCCTCGAGCAGATCGTCCATCGATCTGAAACTGACCCCAGTCGATGTAATCACCGTCCTTCTCGACGTAGACCTTGACATCTGAGCTGGACTTAGCTCCCTGAATGTTTGGGTGGAAATGTGCTGATGTAGTTGGGGAAACCACATCGAAATGTCTGTTGTTTCTGCACTGGGATTTTCCTTTGAATTGGATGAGGGCATGGATATGCAGAGACCCATCTTGGTGAAGCTCTCTGCACACTCTGATAAATAATTTATCAGACGGGCAAGAAATATTTTTAAGGAGTTCGAGCATTTGCTCTTTGGGTATTGGGCATTTTGGATAAGTAAGGAAGATGTTTTTTGCTTTAACTTGGAACTGATGTGTCCGAGGCATATTGACTTGGTCAATCGGTGTCTCTCAACTTAATCTATGAATCGGTGTGATTGGTGTCCTATATATATGGAGCTCCCAAATGGCATTATTGTAATTTGGGGAAATAATCAAAATCCTCACGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010084535.1
|
|
Location
|
141-497 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCACTTTTAAATGAATTTCCTGAAACTGTTCACGGATTCAGGTGTATGCTTGCTATAAAATACCTGCAGTTGGTAGAAAATACGTATTCCCCTGATTCGTTGGGATACGACCTAATACGTGATTTAATTTCCGTCGTCAGGGCCAAAAGCTATGTCCAAGCGTCCGGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGCCGACTTCTGAGCTCAATCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGGATGTACAGAGGTCCAGATGTTCCTAG |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQLVENTYSPDSLGYDLIRDLISVVRAKSYVQASGRYDHFRARLEVSPTSELNQPIQQACCCPHCPRHKGKGMGQQAHESEAHVLQDVQRSRCS |
|
NCBI Accession
|
YP_010084536.1
|
|
Location
|
301-1071 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGTCCAAGCGTCCGGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGCCGACTTCTGAGCTCAATCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGGATGTACAGAGGTCCAGATGTTCCTAGAGGCTGTGAGGGTCCATGTAAGGTCCAGTCTTTTGAGTCAAGACACGATGTAGTTCATATAGGGAAGGTCATGTGTATTAGTGATGTGACTCGTGGTATGGGGCTGACCCATCGAGTGGGTAAGCGATTTTGCGTTAAGTCTGTATACGTTGTGGGTAAGATATGGATGGATGAGAATATCAAGACTAAGAATCACACGAATAGTGTGATGTTCTTCCTTGTACGTGATCGTCGTCCAAATGATAAACCACAAGATTTTGGAGAGGTGTTCAACATGTTTGACAATGAGCCTAGCACTGCAACTGTAAAGAATATGCATAGGGATCGTTATCAGGTTTTGAGGAAATGGCACGCAACTGTTACCGGTGGACAGTATGCTTCGAAGGAACAGGCATTAGTTAAGAAGTTCGTTAGGGTTAACAATTATGTTGTGTATAACCAGCAGGAAGCTGGGAAATATGAAAATCATTCTGAGAATGCTCTGATGTTGTACATGGCATGTACCCATGCCTCTAATCCTGTGTATGCTACTTTGAAGATACGGATCTACTTCTATGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRPADMIISGPVSKYRRLLSSISPYSKRAAVRIVRATKGKEWANRPMNRKPMFYRMYRGPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGMGLTHRVGKRFCVKSVYVVGKIWMDENIKTKNHTNSVMFFLVRDRRPNDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_010084537.1
|
|
Location
|
1068-1472 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTTTATCTGGGAAATTCAAAATCCCCTGTTTTTCAAGATAACAGAGCACCACAACCAGGCCTTTCTGAGAAACCACGACATCCTCACCGTCCAGATACAGTTCAATCACCACCTGCGGAAAACTTTGGAGATACACAAATGTTCCCTAACCTTCCGAATCTGGACGACTTCACAGCCTCTGACTGGTCATTTCTTAAGGGTCTTCAAAACCCAGGTGCTTAAGTTATTAAATAATTTTGCTGTAATTAGAATTAATAATGTAATCAGAGCAGTTGAACATGTATTATGGAACGTATTACAACACACTGTACATGTACAACAGTCGTATTCAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQAENGVFIWEIQNPLFFKITEHHNQAFLRNHDILTVQIQFNHHLRKTLEIHKCSLTFRIWTTSQPLTGHFLRVFKTQVLKLLNNFAVIRINNVIRAVEHVLWNVLQHTVHVQQSYSIKFNLY |
|
NCBI Accession
|
YP_010084538.1
|
|
Location
|
1198-1617 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCGACCTTCATCACCCTCCAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTGGCCAAGAAGGGGACCAGGCGTCGTCGCGTTGACCTCGACTGCGGCTGCTCATATTTCATCGCATTACGCTGCCACGGCTATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTTTATCTGGGAAATTCAAAATCCCCTGTTTTTCAAGATAACAGAGCACCACAACCAGGCCTTTCTGAGAAACCACGACATCCTCACCGTCCAGATACAGTTCAATCACCACCTGCGGAAAACTTTGGAGATACACAAATGTTCCCTAACCTTCCGAATCTGGACGACTTCACAGCCTCTGACTGGTCATTTCTTAAGGGTCTTCAAAACCCAGGTGCTTAA |
|
Protein Sequence
|
MRPSSPSKAHSTQVPIKVQHRLAKKGTRRRRVDLDCGCSYFIALRCHGYGFTHRGTHHCSSSREWRVYLGNSKSPVFQDNRAPQPGLSEKPRHPHRPDTVQSPPAENFGDTQMFPNLPNLDDFTASDWSFLKGLQNPGA |
|
NCBI Accession
|
YP_010084539.1
|
|
Location
|
1520-2605 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGCCTCGGACACATCAGTTCCAAGTTAAAGCAAAAAACATCTTCCTTACTTATCCAAAATGCCCAATACCCAAAGAGCAAATGCTCGAACTCCTTAAAAATATTTCTTGCCCGTCTGATAAATTATTTATCAGAGTGTGCAGAGAGCTTCACCAAGATGGGTCTCTGCATATCCATGCCCTCATCCAATTCAAAGGAAAATCCCAGTGCAGAAACAACAGACATTTCGATGTGGTTTCCCCAACTACATCAGCACATTTCCACCCAAACATTCAGGGAGCTAAGTCCAGCTCAGATGTCAAGGTCTACGTCGAGAAGGACGGTGATTACATCGACTGGGGTCAGTTTCAGATCGATGGACGATCTGCTCGAGGAGGTCAACAGACAACTAATGATGCTGCAGCAGAGGCGCTCAATGCAGGTTCAGCGGAAGCAGCTCTCAAAGTATTAAGGGAAAAACTCCCCAAAGATTTTATTTTTCAATACCATAATTTAAAATGTAATTTAGATAGGATTTTTACACCTCCAATGGAGGTTTATGTTTCTCCTTTTTCTTCTTCTTCATTTGATCAAGTTCCAGAAGAACTTGAGGAGTGGGCTGCCGACAACGTCGTTAGTGCCGCTGCGCGGCCTATAAGGCCCATAAGTATAGTGATTGAGGGTGACAGTAGAACGGGGAAAACAATGTGGGCTAGGTCATTGGGTCCACATAACTACCTATGTGGTCACCTAGACCTTAGCCCTAAGGTGTACAGCAATGATGCATGGTATAACGTCATTGATGACGTTGATCCGCATTATCTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAATCAAATACAAAATACGGAAAGCCAGTTCAAATTAAAGGTGGAATTCCCGCTATCTTCCTCTGCAATCCAGGACCCAATTCAAGCTATAAAGAGTTCTTGGATGAAGAGAAACATTCCGCACTAAAGAATTGGGCTTTAAAGAATGCGACCTTCATCACCCTCCAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTGGCCAAGAAGGGGACCAGGCGTCGTCGCGTTGA |
|
Protein Sequence
|
MPRTHQFQVKAKNIFLTYPKCPIPKEQMLELLKNISCPSDKLFIRVCRELHQDGSLHIHALIQFKGKSQCRNNRHFDVVSPTTSAHFHPNIQGAKSSSDVKVYVEKDGDYIDWGQFQIDGRSARGGQQTTNDAAAEALNAGSAEAALKVLREKLPKDFIFQYHNLKCNLDRIFTPPMEVYVSPFSSSSFDQVPEELEEWAADNVVSAAARPIRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPAIFLCNPGPNSSYKEFLDEEKHSALKNWALKNATFITLQGPLYSGSNQSAAQAGQEGDQASSR |
|
NCBI Accession
|
YP_010084540.1
|
|
Location
|
2155-2448 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGTCTCTGCATATCCATGCCCTCATCCAATTCAAAGGAAAATCCCAGTGCAGAAACAACAGACATTTCGATGTGGTTTCCCCAACTACATCAGCACATTTCCACCCAAACATTCAGGGAGCTAAGTCCAGCTCAGATGTCAAGGTCTACGTCGAGAAGGACGGTGATTACATCGACTGGGGTCAGTTTCAGATCGATGGACGATCTGCTCGAGGAGGTCAACAGACAACTAATGATGCTGCAGCAGAGGCGCTCAATGCAGGTTCAGCGGAAGCAGCTCTCAAAGTATTAA |
|
Protein Sequence
|
MGLCISMPSSNSKENPSAETTDISMWFPQLHQHISTQTFRELSPAQMSRSTSRRTVITSTGVSFRSMDDLLEEVNRQLMMLQQRRSMQVQRKQLSKY |