Tomato rugose yellow leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000904155.4 |
| Isolate | Uruguay: Salto Grande |
| Release date | 2018/8/7 |
| Submitter | Marquez-Martin,B., Maeso,D., Martinez-Ayala,A., Bernal,R., Teresa Federici,M., Vincelli,P., Navas-Castillo,J., Moriones,E., Federici,M.T. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
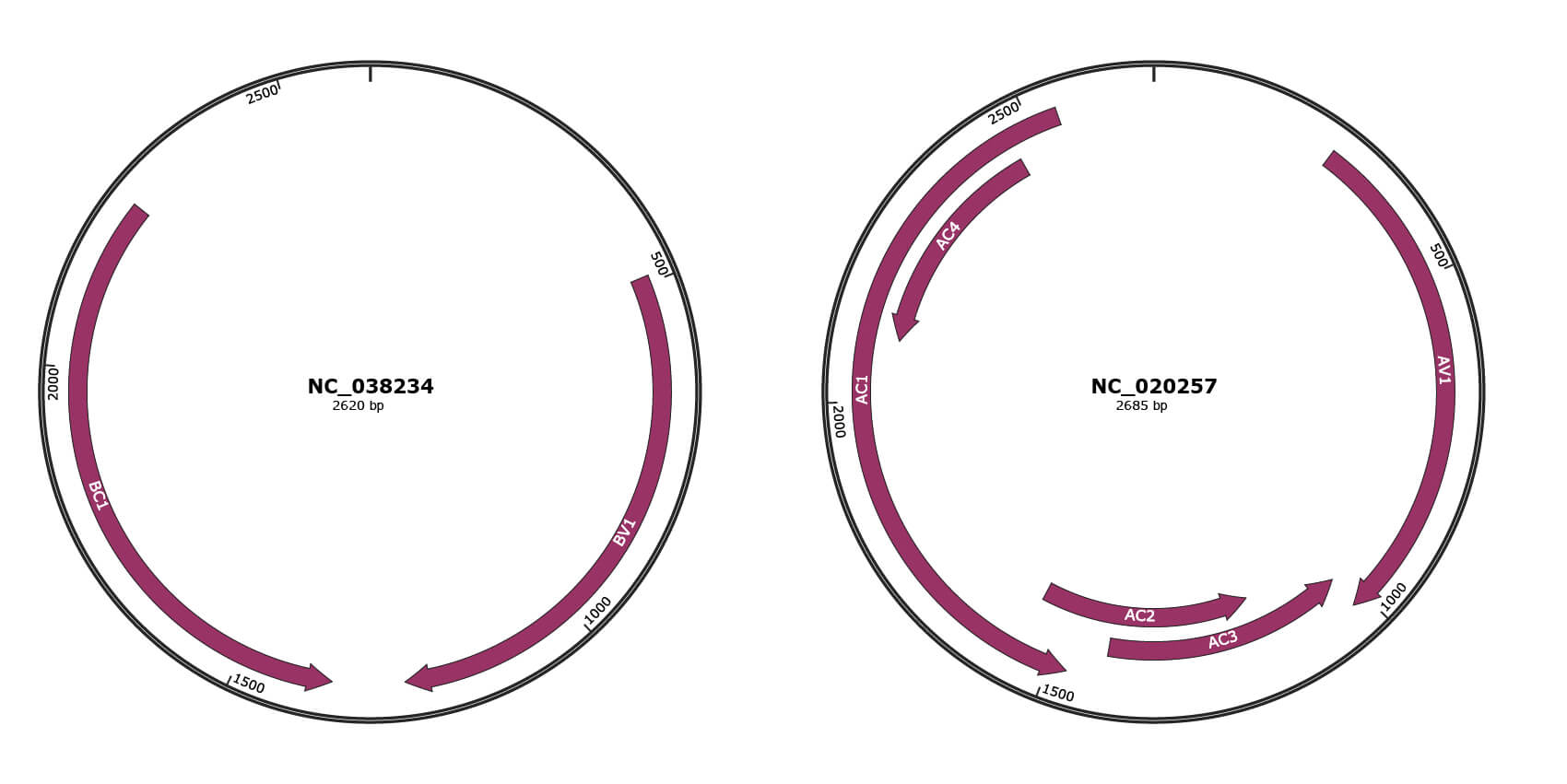
JBrowse
Genome
NC_038234
NC_020257
Gene Information
| NCBI Accession | YP_009505297.1 |
|---|---|
| Location | 490-1260 |
| Gene Name | BV1 |
| Protein Name | NSP |
| Coding Region | ATGTATACTACGAGATATAGACGTGGCAGGTTCTCTACACAAGGACGAGTTTACTCGCGCTATCCCTTATCCAAGCGTTCTTACTATGTGAAACGGACGGAGTGTAAGCGTCGCTCGAGTAAGGTGACTCATGCTGATGAAGACAAGAAGATGTCAGTCCAGCGGCTACATGAGAATCAGTTCGGTGCTGGTTTTGCTATGGCTCATAATACAGCGATGTCCACGTACATCACCTTCCCAACTCTTGGTATAACCGAACCTAACCGTTCAAGGTCATACATCAAGTTGAAACGCTTACGTTACAAGGGTACTGTAAAGATTGAGCGTGTTCATGTTGATGTGAATATGGACGTTGCAGCTCCAAAAATTGAAGGAGTCTTTTCTTTGGTTGTGGTGGTTGATCGAAAGCCGCATTTGAACGAAACTGGGAGTTTGCATTCATTCGACGAAATATTCGGTGCGAGGATTAATAGTCATGGTAATTTAGCCATAGCTCCTGTGTTTAAAGATCGTTATTACATACGTCATGTGCTAAAACGAGTGCTATCAGTGGAGAAGGATAGCATGATGGTCGATCTGGAGGGAAGCATGTCCTTATCCAACCGGCGTTTCAACTGTTGGTCTACGTTTAAGGATTTGGATAGGGATTCATGTAATGGGGTTTATGCCAATATAAGCAAAAACGCCCTATTAGTTTATTATTATTGGATGTCGGATAACGCGTCGAATGCGTCGACGTTTGTATCATATGATCTTGATTATGTGGGTTGA |
| Protein Sequence | MYTTRYRRGRFSTQGRVYSRYPLSKRSYYVKRTECKRRSSKVTHADEDKKMSVQRLHENQFGAGFAMAHNTAMSTYITFPTLGITEPNRSRSYIKLKRLRYKGTVKIERVHVDVNMDVAAPKIEGVFSLVVVVDRKPHLNETGSLHSFDEIFGARINSHGNLAIAPVFKDRYYIRHVLKRVLSVEKDSMMVDLEGSMSLSNRRFNCWSTFKDLDRDSCNGVYANISKNALLVYYYWMSDNASNASTFVSYDLDYVG |
| NCBI Accession | YP_009505298.1 |
|---|---|
| Location | 1365-2246 |
| Gene Name | BC1 |
| Protein Name | MP |
| Coding Region | ATGGAATCTCAGTTAGTGCATCCACCAAACGCCTTTAATTATATAGAATCTCAGCGTGATGAATATCAATTATCACATGACCAAACTGAGATTAAGTTGCAGTTTCCGTCCACGACGTCTCAACTCAGTGCCAGACTCAGTCGCAGCTGTATGAAGATCGACCATAGCGTCATAGAATACAGGCAGCAAGTACCAATAAACGCCACAGGGACAGTGGTAGTCGAGCTCCATGACACGAGGATCACACACAACGAATCCTTACAAGCGTCTTGGACATTTCCTATCCGGTGCAGCATAGATCTCCATTATTTCTCATCCTCATTCTTCTCGCTCAAAGACCCAATTCCATGGAAACTATATTACAGGGTTTGTGACACCAACGTTCATCAGGGGACTCACTTTGCGAAGATCAAGGGGAAACTCAGACTATCGACGGCTAAACACTCCGTTGATATCCCTTTCCGGGCACCGACGGTTAAGATATTGTCCAAACAGTTCACAGAGAAAGACATTGATTTCTCACACGTCGGTTATGGTCGATGGGAGAGGAAATTGATCCGATCCGCATCCACAACAAGATATGGGCTTCCAGGCCCAATAGAAATAAGGCCCGGGGAGTCTTGGGCTACCAGGAGCAGCATCGGCCATACCCAATCTGATGCGGAATCGGACGCAGGGGACGCGATACACCCATATAGACATCTCAATAGGTTAGGAACCACCATCTTAGACCCAGGCGAGTCTGCGTCAATAGTGGGTGCTCATAAGACACAGTCCAACATCACCATGTCAATAACCCAGTTAAACGACCTTGTCCGGTCCACAGTCCAAGAATGTATCAACTCAAACTGTACTCCCTCACAACCCAAATCGTTGAAATAA |
| Protein Sequence | MESQLVHPPNAFNYIESQRDEYQLSHDQTEIKLQFPSTTSQLSARLSRSCMKIDHSVIEYRQQVPINATGTVVVELHDTRITHNESLQASWTFPIRCSIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVHQGTHFAKIKGKLRLSTAKHSVDIPFRAPTVKILSKQFTEKDIDFSHVGYGRWERKLIRSASTTRYGLPGPIEIRPGESWATRSSIGHTQSDAESDAGDAIHPYRHLNRLGTTILDPGESASIVGAHKTQSNITMSITQLNDLVRSTVQECINSNCTPSQPKSLK |
| NCBI Accession | YP_007438885.1 |
|---|---|
| Location | 275-1021 |
| Gene Name | AV1 |
| Protein Name | CP |
| Coding Region | ATGCCGAAGCGGGATGGCTCATGGCGTTCGATTGCGGGTACGTCTAAGGTTAGGCGCTCTCTCAATTTCTCGCCTCGTGGAGGTATTGGGCCTAAGGCCTCTGCTTGGGTTAATAGGCCCATGTACAGGAAGCCCAGTATTTATCGGGCCTATAGGTCACCTGACGTTCCTAAAGGTTGTGAGGGGCCTTGTAAGGTGCAGTCTTATGAGCAGCGCCATGACATCGCCCATACCGGGAAGGTTCTGTGTATCTCCGACGTGACGCGCGGTAGCGGCATCACTCACCGTGTCGGTAAGCGTTTTTGTGTGAAGTCTGTCTATATATTAGGTAAGGTCTGGATGGACGATAACATAAAGCTGAGGAACCACACGAACAACGTCATGTTCTGGTTGGTTAGAGACCGTAGACCCTATGGCACGCCTATGGATTTCGGACAGGTGTTTAATCTGTTCGATAATGAGCCTAGTACCGCCACCGTGAAGAACGATCTCCGCGATCGTTTCCAAGTGATGCACAAGTTCCACACCACGGTCACCGGTGGGCAATATGCTGCCAAGGAGCAGGCGATGGTTAAGCGTTTCTGGAGGGTCAACAACCATGTGACCTATAACCACCAGGAAGCCGCGAAGTACGAGAACCACACGGAGAATGCCTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTATATGCAACCCTTAAGATTCGGATCTATTTTTACGATTCGATATCAAATTAA |
| Protein Sequence | MPKRDGSWRSIAGTSKVRRSLNFSPRGGIGPKASAWVNRPMYRKPSIYRAYRSPDVPKGCEGPCKVQSYEQRHDIAHTGKVLCISDVTRGSGITHRVGKRFCVKSVYILGKVWMDDNIKLRNHTNNVMFWLVRDRRPYGTPMDFGQVFNLFDNEPSTATVKNDLRDRFQVMHKFHTTVTGGQYAAKEQAMVKRFWRVNNHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | YP_007438886.1 |
|---|---|
| Location | 1018-1416 |
| Gene Name | AC3 |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAAGCAGAGAGTGGCGTGTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAACCAGAGTGGAGGATCCACTCTACACCAACAACAGGATCTACCACGTCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCATTTCTCAACTTCCAAGTCTGGACGACTTCAGTGACAGCTTCTGGGCCGATATATTTAAATAGGTTTACACATTTTGTTTTGTTGTATCTAGATCAGTTAGGCGTTATTTCAATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAGATCATATGTAAATGCTGTACTCGAACGTCATTCAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGELITAPQAESGVYIWEITNPLYFKITRVEDPLYTNNRIYHVQIRFNHNLRRALDLHKAFLNFQVWTTSVTASGPIYLNRFTHFVLLYLDQLGVISINNVIRAVRFATDRSYVNAVLERHSIKFKIY |
| NCBI Accession | YP_007438887.1 |
|---|---|
| Location | 1163-1552 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGCGAGATTCATCTTCCTCACATCTCCCCTCTATCAAGGTAGCACACAGGGCAGCCAAGCGCAGGGCTATTCGACGTAGGCGCATTGACCTACACTGTGGGTGCTCAGTATATGTCCACATAAACTGCCGCAACAATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAAGCAGAGAGTGGCGTGTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAACCAGAGTGGAGGATCCACTCTACACCAACAACAGGATCTACCACGTCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCATTTCTCAACTTCCAAGTCTGGACGACTTCAGTGACAGCTTCTGGGCCGATATATTTAAATAG |
| Protein Sequence | MRDSSSSHLPSIKVAHRAAKRRAIRRRRIDLHCGCSVYVHINCRNNGFTHRGTHHCASSREWRVYLGDNKSPVFQDNQSGGSTLHQQQDLPRPDTVQPQPEESVGSPQGISQLPSLDDFSDSFWADIFK |
| NCBI Accession | YP_007438888.1 |
|---|---|
| Location | 1473-2543 |
| Gene Name | AC1 |
| Protein Name | Rep |
| Coding Region | ATGCCACGAAATCCTAACCAATTTAGACTTGCTGCCAAAAACATCTTCCTCACATATCCCCAGTGCGATATACCAAAGGATGAAGCTCTTCAAATGCTTCAAGCCCTTCCATGGTCAGTCGTCAAACCCACATATGTCCGAGTCGCAAGAGAGGAACACTCAGACGGACATCCCCACCTTCATTGTCTCATCCAGTTATCCGGAAAGTCTAACATCAAGGATGCTAGATTTTTCGACCTTACTCACCCCAGAAGGTCTGCCAATTTTCACCCAAATGTCCAGGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGCCAATATCAAGTGTCTGGGGGTACAAAGTCAAATAAAGATGACGTCTATCACAACGCCGTCAATGCAAGAGGAGCTTCAGAAGCTCTTGCTATTATAAAAGCCGGAGACCCTAAGACATTCATTGTTAGCTATCATAATGTCAAGGCTAATATCGAACGTTTGTTTCAGAAGGCTCCAGAACCATGGTCTCCTCCGTTTCCCCTCTCCTCGTTCAATAACGTTCCTGACGATATGCAAGAATGGGCGGACGAATATTTCGGGAGAGGTTCCGCTGCGCGGCCTGAGCGACCTATTAGTATCATCGTCGAGGGCGATAGTCGTACAGGGAAGACGATGTGGGCCCGTGCTTTAGGTTCACACAATTACTTGAGCGGACACCTAGATTTCAATTCTAGGGTTTACTCGAACGAGGCGGAGTATAACGTCATTGATGACGTCGCCCCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTAATTGGGGCCCAGAGGGACTGGCAAAGCAATTGCAAGTACGGTAAGCCAGTTCAAATTAAAGGAGGTATACCAGCAATCGTGCTTTGCAATTCTGGAGAGGGGGCCAGTTATAAAGATTTCCTCGACAAAGAGGAAAACTCATCATTAAGAACCTGGACACTCCGCAATGCGAGATTCATCTTCCTCACATCTCCCCTCTATCAAGGTAGCACACAGGGCAGCCAAGCGCAGGGCTATTCGACGTAG |
| Protein Sequence | MPRNPNQFRLAAKNIFLTYPQCDIPKDEALQMLQALPWSVVKPTYVRVAREEHSDGHPHLHCLIQLSGKSNIKDARFFDLTHPRRSANFHPNVQAAKDTNAVKNYITKEGDYCESGQYQVSGGTKSNKDDVYHNAVNARGASEALAIIKAGDPKTFIVSYHNVKANIERLFQKAPEPWSPPFPLSSFNNVPDDMQEWADEYFGRGSAARPERPISIIVEGDSRTGKTMWARALGSHNYLSGHLDFNSRVYSNEAEYNVIDDVAPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPAIVLCNSGEGASYKDFLDKEENSSLRTWTLRNARFIFLTSPLYQGSTQGSQAQGYST |
| NCBI Accession | YP_007438889.1 |
|---|---|
| Location | 2099-2464 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAAGCTCTTCAAATGCTTCAAGCCCTTCCATGGTCAGTCGTCAAACCCACATATGTCCGAGTCGCAAGAGAGGAACACTCAGACGGACATCCCCACCTTCATTGTCTCATCCAGTTATCCGGAAAGTCTAACATCAAGGATGCTAGATTTTTCGACCTTACTCACCCCAGAAGGTCTGCCAATTTTCACCCAAATGTCCAGGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGCCAATATCAAGTGTCTGGGGGTACAAAGTCAAATAAAGATGACGTCTATCACAACGCCGTCAATGCAAGAGGAGCTTCAGAAGCTCTTGCTATTATAA |
| Protein Sequence | MKLFKCFKPFHGQSSNPHMSESQERNTQTDIPTFIVSSSYPESLTSRMLDFSTLLTPEGLPIFTQMSRQPKTPTPSRITSPKRVIIVNPANIKCLGVQSQIKMTSITTPSMQEELQKLLLL |
References More References in PubMed
| 1 |
Butterbach P, et al. Proc Natl Acad Sci U S A. 2014 Sep 2;111(35):12942-7. doi: 10.1073/pnas.1400894111. Epub 2014 Aug 18. PMID: 25136118 |
|---|---|
| 2 |
First Report of Tomato rugose yellow leaf curl virus Infecting Tomato in Argentina. Guerrero EB, et al. Plant Dis. 2013 Dec;97(12):1662. doi: 10.1094/PDIS-01-13-0003-PDN. PMID: 30716848 |
| 3 |
Macedo MA, et al. Arch Virol. 2018 Mar;163(3):737-743. doi: 10.1007/s00705-017-3662-0. Epub 2017 Dec 9. PMID: 29224131 |
| 4 |
Viruses of Economic Impact on Tomato Crops in Mexico: From Diagnosis to Management-A Review. García-Estrada RS, et al. Viruses. 2022 Jun 9;14(6):1251. doi: 10.3390/v14061251. PMID: 35746722 |
| 5 |
Leaf Plasmodesmata Respond Differently to TMV, ToBRFV and TYLCV Infection. Kutsher Y, et al. Plants (Basel). 2021 Jul 14;10(7):1442. doi: 10.3390/plants10071442. PMID: 34371642 |
| 6 |
Davino S, et al. Virus Res. 2009 Jul;143(1):15-23. doi: 10.1016/j.virusres.2009.03.001. Epub 2009 Mar 14. PMID: 19463717 |
| 7 |
Hussain MD, et al. Plant Dis. 2026 Mar;110(3):592-598. doi: 10.1094/PDIS-04-25-0930-SC. Epub 2026 Mar 6. PMID: 40587188 |
| 8 |
Diverse population of a new bipartite begomovirus infecting tomato crops in Uruguay. Márquez-Martín B, et al. Arch Virol. 2012 Jun;157(6):1137-42. doi: 10.1007/s00705-012-1262-6. Epub 2012 Mar 1. PMID: 22383056 |
| 9 |
Simmonds-Gordon RN, et al. Arch Virol. 2014 Oct;159(10):2815-8. doi: 10.1007/s00705-014-2112-5. Epub 2014 May 29. PMID: 24872185 |
| 10 |
Diversity and prevalence of Brazilian bipartite begomovirus species associated to tomatoes. Fernandes FR, et al. Virus Genes. 2008 Feb;36(1):251-8. doi: 10.1007/s11262-007-0184-y. Epub 2008 Jan 4. PMID: 18175211 |