Tomato mottle wrinkle virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000926355.1 |
| Isolate |
Argentina |
| Release date |
2015/2/22 |
| Submitter |
Vaghi Medina,C.G., Martin,D.P., Lopez Lambertini,P.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
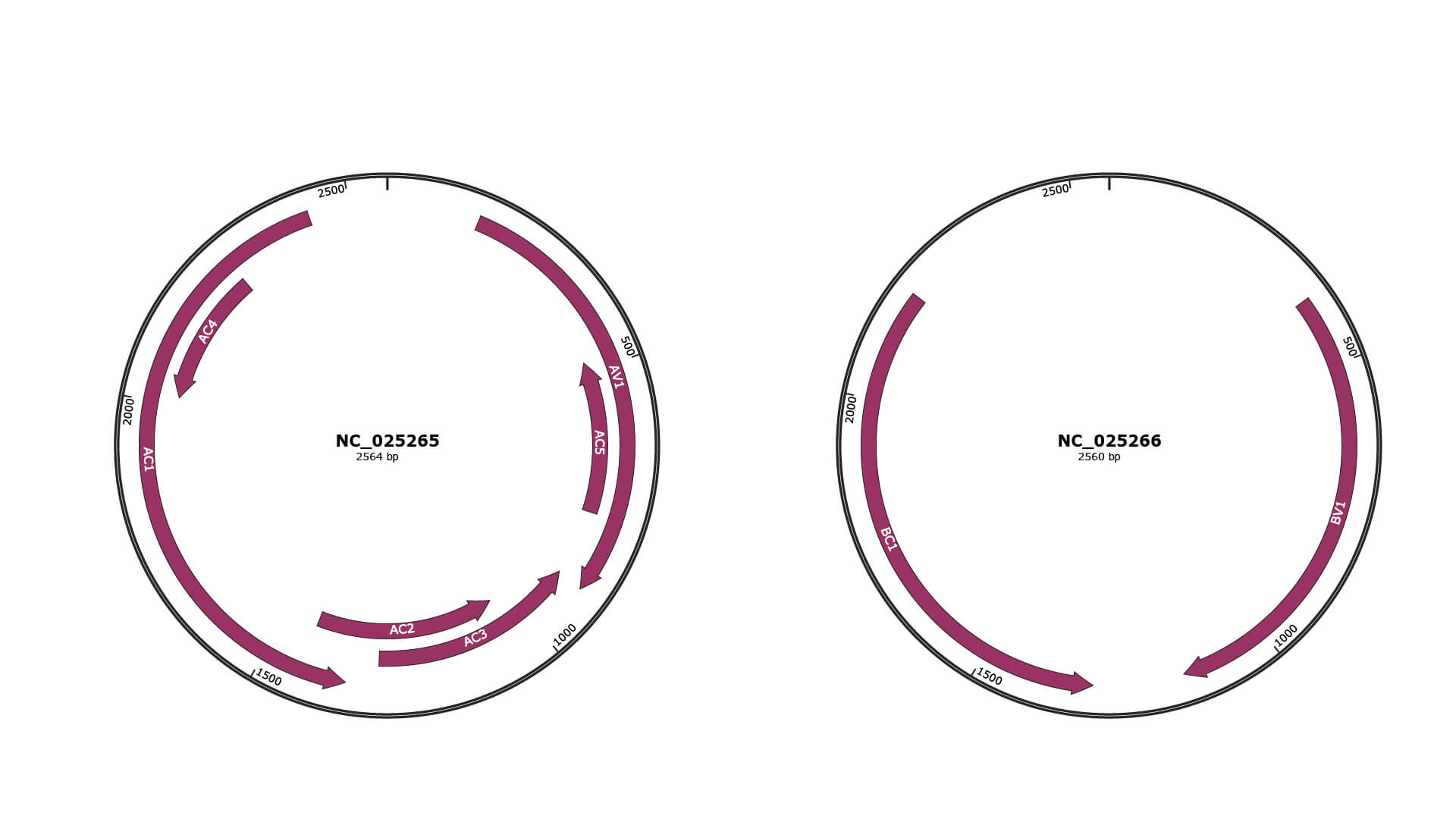
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTAAGTGGTCCCACAACGCCTGACCAATCAGAATTCGTCTTGAAAGTCTATTTATTTTGAAATACTTGGGCGCTAAGGTTATTAAAGTAATATAAATAGGACCCTACTTATCATCTCTCAATACGCTTTAATTCAAAATGCCTAAGCGGGATGCCCCATGGCGTATAATGGCGGGGACCACCAAAGTTAGTCGCTCTTCTAATTATTCACCTCGTGGCGGTAATTCCAAGCGAGATGCTTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATATATCGTACGCTGAGAGGGCCGGATGTTCCTAAAGGATGTGAAGGCCCATGTAAAGTCCAATCTTATGAGCAGCGTCATGATATTTCTCATCTTGGCAAGGTGATGTGTATTTCTGATATCACACGTGGTAATGGTATTACACACCGTGTCGGTAAGCGTTTTTGTGTCAAGTCCGTGTACATTTTAGGGAAGATATGGATGGACGAAAATATTAAACTGAAGAACCACACGAACAGCGTCATTTTCTGGTTGGTTAGGGATCGGAGACCGTATGGGACACCTATGGATTTTGGCCAAGTGTTTAATATGTTTGATAATGAGCCTAGTACTGCCACTGTGAAGAACGATCTTCGTGATCGGTATCAAGTCATGCATAGGTTCAATGCTAAGGTTACGGGAGGACAGTATGCAAGCAACGAGCAAGCTCTTGTTCGTCGTTTCTGGAAGGTCAATAATCATGTGGTCTACAACCATCAGGAAGCAGGGAAATATGAGAATCACACAGAGAACGCTCTATTATTGTATATGGCATGTACTCATGCTTCTAATCCCGTGTATGCTACTTTGAAAATTCGGATCTATTTTTATGATTCGATTACAAATTAATAAAGTTTAAATTTTATTGAATGATTTTCGAGTACATAATTTACATATGATTTGTCTGTTGCGAAACGAACAGCTCTGATTACATTATTAATTGAAATAACACCTAAACGGTCTAGATACAATAAGACTAAATACTTAAATCTATTTAAATATGTCATCCCAGAAGCTCTCAGGGATGTCGTCCAGACTTGGAAATTTAGAAATGCCTTGTGGAGATCCAACGCTTTCCGCAGTTTGTGGTTGAAACGTATCTGCAGATGATAAATCCTTGTCGTTGTGTATAGGTGGTCCTCTACGTTGGTTATCTTGAAATAGAGGGGATTTGCAATCTCCCAAATAAAGGCGCCATTCTCTGCTTGATGCACAGTGATGTGTTCCCCGGTGCGTGAATCCATTGTTTCTACAGTTGAGGTGGATGTAGATGGAGCAGCCACAGTCTAGGTCTATGCGTTTACGCCGAATTGCCCTCTGTTTGGCAGCTCTGTGTCGTGGTTTGATAGAGGGGGGAGTTGAGGAAGATGAATTTAGCATTATGAAGTGTCCACGCTTTTAGAGATGAATTTTCATGCTTGTCAAGGAACTCTTTATAACTAGCCCCCTCTCSTGGATTGCAAAGCACGATTGATGGGATTCCTCCTTTAATTTGAACTGGCTTTCCGTATTTACAGTTGCTTTGCCAGTCACGTTGGGACCCAATTAGCTCTTTCCAGTGTTTCATTTTTAGGTATTGCGGAGTGACATCATCAATGACGTTATATTCCACTTCATTTGAATAAACTTTAGAATTAAAGTGTAGATGTCCACTCAAGTAATTATGTGAACCTAATGCACGGGCCCACCTCGTCTTCCCCGTCCTTGAATCACCCTCAATGATTATACTAATAGGTCTCTCTGGCCGCGCAGCGGCACCCCTTCCGAAATATTCATCAGCCCACTCTTGCATCTCGTCAGGCACGTTAGTGAAAGATGAGAGTGGAAACGGAGGAACCCATTGTTCAGGAGGCTTATTAAAAATCCTATCTAAATTGGAATTTAAATTATGATATTGAAATAAATATTTCTCGGGAAGTTTTTCCCTTATTATTTGCATAGCGGATTCTTTAGAAGGGGCGTTTAATGCCTCTGCTGCGGCGTCGTTAGCCGTTTGCTGACCTCCTCTAGCACTTCTACCGTCGATTTGGAATTCTCCCCATTCAAGAGTATCTCCGTCTTTATCGATATAGGACTTGACGTCGGACGATGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGATCTTGTTGGGGATACCAGGTCGAAGAATCTATTATTCGTGCATTGGTATTTACCTTCGAATTGGATAAGCACGTGGAGATGAGGCTCCCCATTCTCGTGAAGTTCTCTACAGATCTTGATGAATTTCTTGTTGGTTGGTGTCTGTAAGGCTTGTAATTGGGAAAGTGCGTCTTCTTTAGTGAGAGAACATTTAGGATATGTGATGAAATAGTTTTTGGAAGATATCTTAAAACGCTTGGGGAGTGGCATATTTGTAAATATAGGCTTGTACCCCGATTGCTCTCGCTTCAAAACTCTATATGAATTGGGGTAATGGGGTACAATATATAGTATAAGTTCTTTAGGGTTTAAATAGACACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGCGATTTTTTTTGGTGGGTCCCTCTCTATTTTAATTGAGCGCATTTTTGACGTCCGCGAATTTAGTTGAGCGCAAATTTTGAGATCCGCCAATAGCGTTAGTGGTATAACTTTAATTTGAAATAAAGAGCAACTTTGTGTTTAGCCAATCATATTGCGTCTAAGAAGACTAGTTGTGTATTACTTTGATATCATTTCAAACTTGAATATTATTGGTCAGTCTTACCACTATGGGGTACATTTATAACATTTATGTCATTGTCAATATATTATATGTGCATGACGTGTACCAATTAAATATTTGCTATGCAGTTAAGAAATGTTATAAATGAATCTGCAATACATTGTTATGGATATAATATCTGATCATGTATCCTACTAAGTATAAACGTAATTGGTCATCTAATCAACGAAGAGGTTATTCACGTCAATCATTCTTCAAACGTTCTTATTATTTTAAGCGTACAGATGGGAAACGTCGATCAAATAGTTCAGTCCAGGTGAATGAGGATGATAAATTATCACAACAGCGGATACATGAGAACCAGTTTGGCCCAGATTTTGTTATGGGTCATAATAGTGCCGTGTCTACTTTCATCACTTTCCCTACTCTCAGTAAAATTGAGCCTAACCGGTCAAGGTCATATATTAAGTTGAAACGCTTACGTTTCAAAGGTACTGTTAAAATTGAACGGTTGCAAACTGATATGAAAATGGACTGTGTAATTCCAAGTATTGAAGGGGTCTTTTCGCTGGTTATCGTCGTTGATCGTAAACCCCATTTGAGCCCAACAGGATGTCTGCATACATTTGATGAGCTCTTTGGTGCACGGATCCACAGTCATGGCAATTTGGCTATAAGTTCATCGTTGAAGGACCGCTTTTACATACGTCATGTTTGGAAGAAAGTAATATCTGTCGAGAAGGATAGCACGATGGTTGATCTTGAAGGAACGACATCACTATCTAACAAGCGTTATAATTGTTGGTCTGGTTTTAAGGATCTTGATCGTGATTCCTGTAATGGGGTTTATGCGAATATAAGCAAGAACGCCCTTTTAGTTTATTATTGTTGGATGTCTGACATCATGTCTACAGCATCCTCATTTGTATCGTTTGATCTTGATTATGTTGGTTAATTAATAATATTATGAGTTATAATAAAGTCAGACTTACATAAGAGATTCAATCACTCAAGAAAACATGTACAGGAAATTATTAGGAATAACACAATTACATTTAATATATATTAGGCTGCGCAGCTGCACCAAAAAAATGTTCTAGAAAGTCAGCATCTATTTCAAAGATTTGGGCTGTGCAGGAATACAATTAGTTTTAATACACTCTTGGACCGTCGATCTAACAATTTCGTTTAATTGGGCCATTGACATAGTAATGTTTGATTGTGTTCTTTGGGCCCCAATTATAGAAGCTGACTCTCCTGGGTCTAAGATGGCAGTGCCAAGTCTGTTAAGATCCTTATATGGATGTAATGAGTCACCTACTTCTGATTCCGTATCTAATTGGGCCGGACCTATAGTACTCCTTGTGGCCCAAGACTCTCCTGGATTTAGTTCTATTGGGCCTGGTAGCCCAAACCTAGAAGTCGATGCAGATCGTATTAATTTTCTCTCCCATTTCCCATAGCCCACATGAGAGAAGTCTATATCATTGACTGTAAATTGCTTGGACATGATCTTTACTGTGGGTGCTCTGAAAGGTATATCAACCGAATGTTTTGCCGTCGATAGCTTCAATTTCCCTTTAAATTTTGCAAAGTGGGTCATTTGATGAACATTCGAGTCACAAACCTTATAATATAGTTTCCATGGAATAGGGTCTTTGAGCGAAAAGAATGATGATGAGAAATAGTGGAGATCTATGTTGCACCTTATCGGAAAAGTCCATGACGCCTGTAATGATTCATTTTCGGTCATTCTCTTGTCATGGATCTCCACAATAACTGACCCTGTTGCGTTTATTGGTACTTGTTGCCTATATTCTATGACGCAATGGTCTATTTTCATACAGCTTCGATTCAGTCTTGCACTTAATTGAGTTGCTTTGGAAGGAAATTGCAATATGATTTCCGTTAGGTCATGAGATAACTGATATTCATCACGACGAGATTCTATGTAATTAAAGGCGTTTGGTGGGCAAACTACTTGTGAATCCATATATTTGAGTAAAGTAAATAGGTAAAGATATTAAGCAAGAAAGATTTAAGAAAATTGTAGTAGTGGGAGAAAATTGAAGTAGTGAGAGAAAAATTGATTTTGAAGATATGACAATATGAAGAAGATTGCGTTTCTTATATAGACTCACAATTGGATATGGATAATTATGTTAGTGAATAATGATATAATTTAATAGGTAATTTAAGATATGTGATAAATTAAGTTTGATAATGGCATATGTGTAAATATAGGCTTGTACCCCGATTGCTCTGGCTTCAAAACTCTATATGAATTGGGGTAATGGGGTACAATATATAGTATAAGTTCTTTAGGGTTTAAATAGACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009091989.1
|
|
Location
|
159-902 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCATGGCGTATAATGGCGGGGACCACCAAAGTTAGTCGCTCTTCTAATTATTCACCTCGTGGCGGTAATTCCAAGCGAGATGCTTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATATATCGTACGCTGAGAGGGCCGGATGTTCCTAAAGGATGTGAAGGCCCATGTAAAGTCCAATCTTATGAGCAGCGTCATGATATTTCTCATCTTGGCAAGGTGATGTGTATTTCTGATATCACACGTGGTAATGGTATTACACACCGTGTCGGTAAGCGTTTTTGTGTCAAGTCCGTGTACATTTTAGGGAAGATATGGATGGACGAAAATATTAAACTGAAGAACCACACGAACAGCGTCATTTTCTGGTTGGTTAGGGATCGGAGACCGTATGGGACACCTATGGATTTTGGCCAAGTGTTTAATATGTTTGATAATGAGCCTAGTACTGCCACTGTGAAGAACGATCTTCGTGATCGGTATCAAGTCATGCATAGGTTCAATGCTAAGGTTACGGGAGGACAGTATGCAAGCAACGAGCAAGCTCTTGTTCGTCGTTTCTGGAAGGTCAATAATCATGTGGTCTACAACCATCAGGAAGCAGGGAAATATGAGAATCACACAGAGAACGCTCTATTATTGTATATGGCATGTACTCATGCTTCTAATCCCGTGTATGCTACTTTGAAAATTCGGATCTATTTTTATGATTCGATTACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRIMAGTTKVSRSSNYSPRGGNSKRDAWVNRPMYRKPRIYRTLRGPDVPKGCEGPCKVQSYEQRHDISHLGKVMCISDITRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVIFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFNAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009091990.1
|
|
Location
|
480-770 |
|
Gene Name
|
AC5 |
|
Protein Name
|
AC5 protein |
|
Coding Region
|
ATGGTTGTAGACCACATGATTATTGACCTTCCAGAAACGACGAACAAGAGCTTGCTCGTTGCTTGCATACTGTCCTCCCGTAACCTTAGCATTGAACCTATGCATGACTTGATACCGATCACGAAGATCGTTCTTCACAGTGGCAGTACTAGGCTCATTATCAAACATATTAAACACTTGGCCAAAATCCATAGGTGTCCCATACGGTCTCCGATCCCTAACCAACCAGAAAATGACGCTGTTCGTGTGGTTCTTCAGTTTAATATTTTCGTCCATCCATATCTTCCCTAA |
|
Protein Sequence
|
MVVDHMIIDLPETTNKSLLVACILSSRNLSIEPMHDLIPITKIVLHSGSTRLIIKHIKHLAKIHRCPIRSPIPNQPENDAVRVVLQFNIFVHPYLP |
|
NCBI Accession
|
YP_009091991.1
|
|
Location
|
899-1297 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACACATCACTGTGCATCAAGCAGAGAATGGCGCCTTTATTTGGGAGATTGCAAATCCCCTCTATTTCAAGATAACCAACGTAGAGGACCACCTATACACAACGACAAGGATTTATCATCTGCAGATACGTTTCAACCACAAACTGCGGAAAGCGTTGGATCTCCACAAGGCATTTCTAAATTTCCAAGTCTGGACGACATCCCTGAGAGCTTCTGGGATGACATATTTAAATAGATTTAAGTATTTAGTCTTATTGTATCTAGACCGTTTAGGTGTTATTTCAATTAATAATGTAATCAGAGCTGTTCGTTTCGCAACAGACAAATCATATGTAAATTATGTACTCGAAAATCATTCAATAAAATTTAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGEHITVHQAENGAFIWEIANPLYFKITNVEDHLYTTTRIYHLQIRFNHKLRKALDLHKAFLNFQVWTTSLRASGMTYLNRFKYLVLLYLDRLGVISINNVIRAVRFATDKSYVNYVLENHSIKFKLY |
|
NCBI Accession
|
YP_009091992.1
|
|
Location
|
1044-1433 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGAGCTGCCAAACAGAGGGCAATTCGGCGTAAACGCATAGACCTAGACTGTGGCTGCTCCATCTACATCCACCTCAACTGTAGAAACAATGGATTCACGCACCGGGGAACACATCACTGTGCATCAAGCAGAGAATGGCGCCTTTATTTGGGAGATTGCAAATCCCCTCTATTTCAAGATAACCAACGTAGAGGACCACCTATACACAACGACAAGGATTTATCATCTGCAGATACGTTTCAACCACAAACTGCGGAAAGCGTTGGATCTCCACAAGGCATTTCTAAATTTCCAAGTCTGGACGACATCCCTGAGAGCTTCTGGGATGACATATTTAAATAG |
|
Protein Sequence
|
MLNSSSSTPPSIKPRHRAAKQRAIRRKRIDLDCGCSIYIHLNCRNNGFTHRGTHHCASSREWRLYLGDCKSPLFQDNQRRGPPIHNDKDLSSADTFQPQTAESVGSPQGISKFPSLDDIPESFWDDIFK |
|
NCBI Accession
|
YP_009091993.1
|
|
Location
|
1354-2430 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACTCCCCAAGCGTTTTAAGATATCTTCCAAAAACTATTTCATCACATATCCTAAATGTTCTCTCACTAAAGAAGACGCACTTTCCCAATTACAAGCCTTACAGACACCAACCAACAAGAAATTCATCAAGATCTGTAGAGAACTTCACGAGAATGGGGAGCCTCATCTCCACGTGCTTATCCAATTCGAAGGTAAATACCAATGCACGAATAATAGATTCTTCGACCTGGTATCCCCAACAAGATCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTATATCGATAAAGACGGAGATACTCTTGAATGGGGAGAATTCCAAATCGACGGTAGAAGTGCTAGAGGAGGTCAGCAAACGGCTAACGACGCCGCAGCAGAGGCATTAAACGCCCCTTCTAAAGAATCCGCTATGCAAATAATAAGGGAAAAACTTCCCGAGAAATATTTATTTCAATATCATAATTTAAATTCCAATTTAGATAGGATTTTTAATAAGCCTCCTGAACAATGGGTTCCTCCGTTTCCACTCTCATCTTTCACTAACGTGCCTGACGAGATGCAAGAGTGGGCTGATGAATATTTCGGAAGGGGTGCCGCTGCGCGGCCAGAGAGACCTATTAGTATAATCATTGAGGGTGATTCAAGGACGGGGAAGACGAGGTGGGCCCGTGCATTAGGTTCACATAATTACTTGAGTGGACATCTACACTTTAATTCTAAAGTTTATTCAAATGAAGTGGAATATAACGTCATTGATGATGTCACTCCGCAATACCTAAAAATGAAACACTGGAAAGAGCTAATTGGGTCCCAACGTGACTGGCAAAGCAACTGTAAATACGGAAAGCCAGTTCAAATTAAAGGAGGAATCCCATCAATCGTGCTTTGCAATCCASGAGAGGGGGCTAGTTATAAAGAGTTCCTTGACAAGCATGAAAATTCATCTCTAAAAGCGTGGACACTTCATAATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGAGCTGCCAAACAGAGGGCAATTCGGCGTAA |
|
Protein Sequence
|
MPLPKRFKISSKNYFITYPKCSLTKEDALSQLQALQTPTNKKFIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAAAEALNAPSKESAMQIIREKLPEKYLFQYHNLNSNLDRIFNKPPEQWVPPFPLSSFTNVPDEMQEWADEYFGRGAAARPERPISIIIEGDSRTGKTRWARALGSHNYLSGHLHFNSKVYSNEVEYNVIDDVTPQYLKMKHWKELIGSQRDWQSNCKYGKPVQIKGGIPSIVLCNPXEGASYKEFLDKHENSSLKAWTLHNAKFIFLNSPLYQTTTQSCQTEGNSA |
|
NCBI Accession
|
YP_009091994.1
|
|
Location
|
2016-2273 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTGCTTATCCAATTCGAAGGTAAATACCAATGCACGAATAATAGATTCTTCGACCTGGTATCCCCAACAAGATCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTATATCGATAAAGACGGAGATACTCTTGAATGGGGAGAATTCCAAATCGACGGTAGAAGTGCTAGAGGAGGTCAGCAAACGGCTAACGACGCCGCAGCAGAGGCATTAA |
|
Protein Sequence
|
MGSLISTCLSNSKVNTNARIIDSSTWYPQQDQHISIRTFRELNHRPTSSPISIKTEILLNGENSKSTVEVLEEVSKRLTTPQQRH |
|
NCBI Accession
|
YP_009091995.1
|
|
Location
|
381-1151 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATCCTACTAAGTATAAACGTAATTGGTCATCTAATCAACGAAGAGGTTATTCACGTCAATCATTCTTCAAACGTTCTTATTATTTTAAGCGTACAGATGGGAAACGTCGATCAAATAGTTCAGTCCAGGTGAATGAGGATGATAAATTATCACAACAGCGGATACATGAGAACCAGTTTGGCCCAGATTTTGTTATGGGTCATAATAGTGCCGTGTCTACTTTCATCACTTTCCCTACTCTCAGTAAAATTGAGCCTAACCGGTCAAGGTCATATATTAAGTTGAAACGCTTACGTTTCAAAGGTACTGTTAAAATTGAACGGTTGCAAACTGATATGAAAATGGACTGTGTAATTCCAAGTATTGAAGGGGTCTTTTCGCTGGTTATCGTCGTTGATCGTAAACCCCATTTGAGCCCAACAGGATGTCTGCATACATTTGATGAGCTCTTTGGTGCACGGATCCACAGTCATGGCAATTTGGCTATAAGTTCATCGTTGAAGGACCGCTTTTACATACGTCATGTTTGGAAGAAAGTAATATCTGTCGAGAAGGATAGCACGATGGTTGATCTTGAAGGAACGACATCACTATCTAACAAGCGTTATAATTGTTGGTCTGGTTTTAAGGATCTTGATCGTGATTCCTGTAATGGGGTTTATGCGAATATAAGCAAGAACGCCCTTTTAGTTTATTATTGTTGGATGTCTGACATCATGTCTACAGCATCCTCATTTGTATCGTTTGATCTTGATTATGTTGGTTAA |
|
Protein Sequence
|
MYPTKYKRNWSSNQRRGYSRQSFFKRSYYFKRTDGKRRSNSSVQVNEDDKLSQQRIHENQFGPDFVMGHNSAVSTFITFPTLSKIEPNRSRSYIKLKRLRFKGTVKIERLQTDMKMDCVIPSIEGVFSLVIVVDRKPHLSPTGCLHTFDELFGARIHSHGNLAISSSLKDRFYIRHVWKKVISVEKDSTMVDLEGTTSLSNKRYNCWSGFKDLDRDSCNGVYANISKNALLVYYCWMSDIMSTASSFVSFDLDYVG |
|
NCBI Accession
|
YP_009091996.1
|
|
Location
|
1308-2189 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGATTCACAAGTAGTTTGCCCACCAAACGCCTTTAATTACATAGAATCTCGTCGTGATGAATATCAGTTATCTCATGACCTAACGGAAATCATATTGCAATTTCCTTCCAAAGCAACTCAATTAAGTGCAAGACTGAATCGAAGCTGTATGAAAATAGACCATTGCGTCATAGAATATAGGCAACAAGTACCAATAAACGCAACAGGGTCAGTTATTGTGGAGATCCATGACAAGAGAATGACCGAAAATGAATCATTACAGGCGTCATGGACTTTTCCGATAAGGTGCAACATAGATCTCCACTATTTCTCATCATCATTCTTTTCGCTCAAAGACCCTATTCCATGGAAACTATATTATAAGGTTTGTGACTCGAATGTTCATCAAATGACCCACTTTGCAAAATTTAAAGGGAAATTGAAGCTATCGACGGCAAAACATTCGGTTGATATACCTTTCAGAGCACCCACAGTAAAGATCATGTCCAAGCAATTTACAGTCAATGATATAGACTTCTCTCATGTGGGCTATGGGAAATGGGAGAGAAAATTAATACGATCTGCATCGACTTCTAGGTTTGGGCTACCAGGCCCAATAGAACTAAATCCAGGAGAGTCTTGGGCCACAAGGAGTACTATAGGTCCGGCCCAATTAGATACGGAATCAGAAGTAGGTGACTCATTACATCCATATAAGGATCTTAACAGACTTGGCACTGCCATCTTAGACCCAGGAGAGTCAGCTTCTATAATTGGGGCCCAAAGAACACAATCAAACATTACTATGTCAATGGCCCAATTAAACGAAATTGTTAGATCGACGGTCCAAGAGTGTATTAAAACTAATTGTATTCCTGCACAGCCCAAATCTTTGAAATAG |
|
Protein Sequence
|
MDSQVVCPPNAFNYIESRRDEYQLSHDLTEIILQFPSKATQLSARLNRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTENESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDSNVHQMTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIMSKQFTVNDIDFSHVGYGKWERKLIRSASTSRFGLPGPIELNPGESWATRSTIGPAQLDTESEVGDSLHPYKDLNRLGTAILDPGESASIIGAQRTQSNITMSMAQLNEIVRSTVQECIKTNCIPAQPKSLK |