Cabbage leaf curl Jamaica virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002867425.1 |
| Isolate |
Jamaica |
| Release date |
2018/8/26 |
| Submitter |
Smith,K.N., Roye,M.E., McLaughlin,W.A., Maxwell,D.P. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
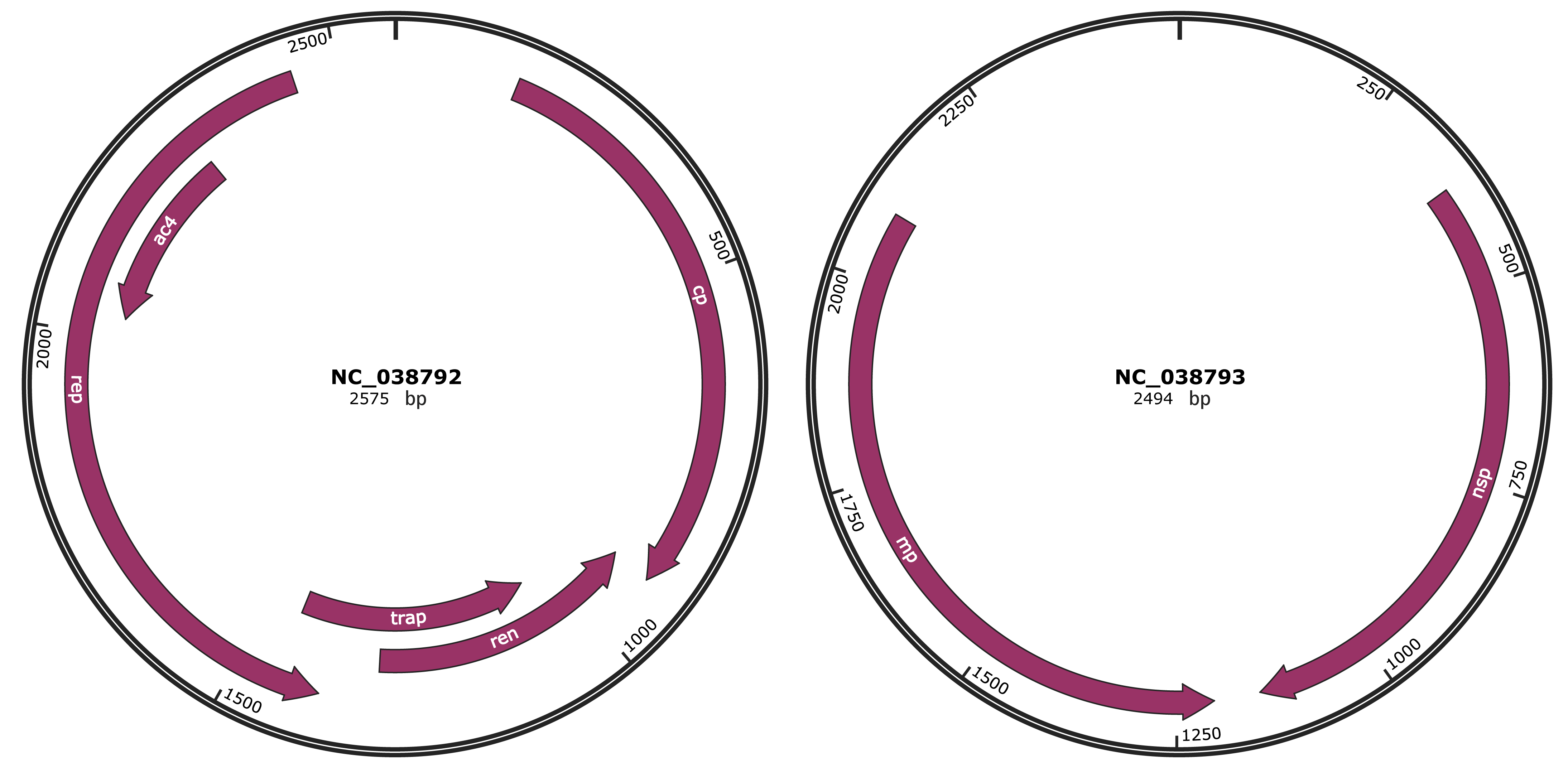
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTGGAGTCATGCGTGGGACCACGCATTAAATGAAATCTAACCAATCACATGCCGCCTGAGAAGGTTAGATATTATGGCGTACTTAGTGCGCTGTGGGCCTATAAAAAGAAATGAAATTTCATTTTATGCTTTACTTCGAAATGCCTAAGCGGGATGCCCCGTGGCGTTCAATGGCGGGGACCTCTAAGGTATCCCGCAATGCTAACTACTCACCTCGTGCAGGTAGAACCCATAAATTTGATAAGGCCGCTGCCTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATAGGATGTTTAGGAGCCCTGATGTTCCCAGAGGCTGTGAAGGCCCATGTAAGGTCCAATCTTATGAGCAGCGTCATGATATCTCACATGTTGGGAAGGTCATCTGCATTTCGGATATAACACGTGGCAATGGTATTACCCATCGTGTTGGGAAGCGTTTCTGCGTCAAGTCCGTCTACATTTTGGGCAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACCAACAGTGTCATGTTTTGGTTGGTTAGGGACAGGAGACCTTATGGCACTCCTATGGAATTTGGGCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACTGTGAAGAACGATCTGCGTGATCGTTTTCAAGTCATGCATAAGTTCTACGCCAAGGTAACCGGTGGGCAGTATGCGAGTAACGAGCAGGCGCTGGTGAAGCGGTTCTGGAAGGTCAATAACTACGTGGTGTATAACCATCAAGAAGCAGGGAAATACGAGAATCATACGGAGAACGCTCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAATTTTGATTTTTATATCATGATTTTCGTGTACATGAGTTACATAGGATCTGTCCGTTGCGAAACGAACAGCTCTAATTACATGATTGATACCAATAACCCCTAGGTTATCTAAATGAGACATTACAAGGCATTTGAATCTACTTAAATATGTCGGCCCAGAAGCTCTCATCGAACTCGTCCAGACCTGGAAATTGAAGTAGGCTTTGTGGAGATCCAATGCTCTCCGTAGGTTGTGGTTGAACCGGACTTGGATGTGGTAGATCCTGGTTCTGGTGTACAACGGGTCCTCTACGCGTTGTATCTTGAAATACAGGGGATTTGGAACCTCCCAGATAAAAACGGAATTCTCTGCCTGAGCTACAGTGATGCTCTCCCCGGTGCGTGAATCCATTATCAGCGCAATTGATATGGAGGAAGATAGAACACCCGCAGTTCAAATCAATGCGTCCTCTGCGTACAGCTCTCCTTTTAGCAGTCTTGTGCTGTGCTTTGATAGAGGGGGGCTTCAAGGGTGATGAATTTCGCATTTTTGATAGTCCACGCTCTGAGTGATGCGTTTTCCTCTTTGTTGAGGAAACTTATATAACCGCTCCCCTCTCCTGGATTGCACAGCACGATTGAGGGTATGCCACCTTTAATTTGAACTGGTTTGCCGTACTTACAGTTTGATTGCCAGTCCCTTTGGGCCCCAATGAGCTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGAGCTATGTCATCAATGACGTTATATTCCACATTATTTGAAAAGACCTTTGAATTAAAGTCGAGGTGCCCACTCAAATAATTATGTGGTCCTAATGCACGCGCCCACATGGTCTTGCCTGTTCGTGAATCACCTTCCACTATGATACTAATAGGTCTTTCCGGCCGCGCAGCGGCACTCCGACCAAAATAGTCATCTGCCCACTCTTGCATTTCGTCCGGGACGTTAGTAAAGGAGGAGAGGGGAAACGGAGGAGACCAAGGATCCGGAGCCTTACTGAAAATCCTATCGAGGTTACTGGATAGGTTGTGATACTGAAAAAGAAACTTCTCCGGGAGCTTTTCTTTAATGATTTTCATGGCCTCCTCCTTTGTTCCAGAGTTTAGTGCCTCGGCGGCTGCGTCGTTAGCTGTTTGCTGACCGCCTCTAGCACTTCTTCCGTCGATCTGGAACACTCCCCATTCAATTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCGGGATGGGGAGACCAAGTCGAAGAATCTGTTATTCGTGCAGTTGTACTTCCCTTCGAACTGTATGAGAACGTGGATATGAGGCTCCCCATTTTCATGAAGCTCTCTGCATATTTTGATGAACTTCTTGTTCACCGGAGTGTTTATTTTTTGTAATTGGGAAAGTGCCTCTTCTTTGCTAAGAGAGCATCGTGGATACGTAAGGAAATAGTTTTTGGCTTTAACTGAGAAAGAGCCCTTTCGTGGCATATTTGTAAATATGGGTGTTCCCCCGATAGCTCTCTCGCTCAAAACTCCTATGAATTGGGGGAACTGGGGGAACTTATATAGTAGAAGTTCCTAAAGGCAAATCAACACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCAAATTTTTTGGCGTCCTGGTGCTGGGGACCATCTCCCGGCCCCCCTTGGCGCACTATCTCTCATCTTTCGACGTGGCGCGTCGATGAGCGTTGGCTAACGCTTATCTCGGTGTTAGACCTTTAATTTGAATTTCGAAATAATTGGTCGTATATATCTATCTTGACCGGTCTTTGTGACGACAAAACTTCTGACACATTGTACGATATATTGAGCGTGGCCCAATTATATTTTCTCTGCGGAGTTAGACTATCGCTTATTGTTATTCATCTTGTCTATATAATGGACGATAGGTTAATAATTTAAATCGTCTTTGACAATAACATTTAAATAACAAATCATTTTGTAGAGGAGCTGAGAATAATGTATCCTACAAAGTTTAGGCGTGGGACTTCTTACTCTCATAGACGATTTGTTTCACGTAATCCTTCTTTTAAGCGTGGAACTTTGGTTAGACGCACTGATGGGAAACATCGTAAAGGCCCATCAAGCAAAGCCCATGATGAGCCTAAAATGAAATTACAACGCATACATGAAAATCAATATGGGCCTGAATTTGTCATGACCCACAACTCAGCTCTTTCAACATTCATTAATTTCCCGGTACTTGGGAAGATCGAACCTAACCGAAGCAGGTCGTATATTAAGTTGAATCGTTTATTATTTAAGGGAACCGTTAAGATTGAGCGTGTGCACGCTGATGTGAACATGGACGGAGTAAGTTCGAAGATAGAAGGTGTGTTCTCTCTTGTTATTGTTATGGATCGCAAGCCACATTTGAGTTCCGCTGGAGGTTTGCATACATTTGATGAAATGTTTGGTGCAAGAATCCACAGCCATGGTAACTTAGCTATTGCACCCGGTTTGAAAGATCGTTATTACGTGCTCCATGTTTTCAAACGCGTATTGTCTGTGGAGAAAGACACTTTGATGGTGGATCTTGAAGGATCGACCATGATATCTAATAGGCGTTATAACTGTTGGGCCTCGTTTAACGATCTTGAACATGACTCATGTAACGGTGTTTATGCGAATATAAGCAAAAATGCCATTTTAGTTTACTATTGTTGGATGTCCGATGCTATGTCTAAGGCATCGACCTTTGTATCTTACGATCTTGATTATTTAGGTTAATCCTGAATAAAATGGCGTTAAGATTGAATATATACATAAAAAATAAAACCAAGCAATTTTATTGCAATGACTTTGGTTGTGTAGGATTACAATTATTGTTAATACATTCCTGGACCGTCGTCCTAACTAGCTCGCTTAATTGGGCCACTGACATCGTTATGGTTGATTGGGCCCTCTGTAATCCAGCTTGTGATGCTGAATCCCCGGGGTCTAATGCGCTAGTTCCTAGCTGGTTGAGTTCTCTATATGGATGTAGCGCATTCTCCACTTCTGATTCAGTTTGTGGGTTTGTAAGCCCAATAGTGCTCCTTGAAGCCCATGAATCACCTGGTTGTAATTCAATTGGGCCTGTTAGTCCAATTCTTGACAATGATCTGGACCTCAACGTTTTCCTCTCCCATTTTCCGTAGTCCACATGGGAGAAATCAACATCTCTATGTGAAAATTGTTTGGAGTGAATTTTCACTGTTGGTGCCCGGAAGGGTATATCCACTGAATGTTTAGCTGTTGACAATTTCAATTTCCCTTTAAACTTGGCAAAATGTGTTCGTTGATGCACATTCGTGTCGCTAACCCTGTAATAGAGTTTCCACGGAATAGGGTCTTTTAGCGAGAAGAATGAAGATGAAAAATAGTGGAGATCTATGTTGCATCTTAAGGGAAATGTCCAAGACGCCTGTAAGGATTCATCGTCAGTCATCCTCTTATCATGGATCTCTACAATCACCGTCCCGGTTGCGTTAATTGGTACTTGCTGTCTATATTCGATGACGCAATGGTCGATTTTCATACAGCTACGATTAAGCCTTGCTGTAAATTGCGCTGCAGTTGAAGGGAATTGCAGTACTATTTCAGTAAGATCATGACATAGCTGATATTCGTCTCTATGAGACTCTATGTAATTAAACGCATTTGGAGCATTTGCTAGCTGAGAATCCATCTATAGAAATCTGCCCGCGCAGCGGCAGAGGCTTCAATAATATCTGGGTTCAAGAATAATTGTGTTGAAGAACACAACAATGAAACGACTTGTTTCACAAGGAGGAAGAGAGAATATCTGGGCTTGTTAACAAGAAGAAAATAATGATATTTTAAAGGAATGATGAATATGTTATGTTATTCCGATAACATGAGTATAATAATCTAAGTCCACCTTGTTTATATAGAGAGTGATTTTCCAGAAGTTGGAAACGCCTTGAATTTCCTTTTAGTGGCATTATTGTAAATATGGGTGTTCCCCCGATAGCGCTCTCGCTCAAAACTCCTATGAATTGGGGGAACTGGGGGAACTTATATAGTAGAAGTTCCTAAAGGCAAATCAACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009507978.1
|
|
Location
|
160-915 |
|
Gene Name
|
cp |
|
Protein Name
|
CP |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCGTGGCGTTCAATGGCGGGGACCTCTAAGGTATCCCGCAATGCTAACTACTCACCTCGTGCAGGTAGAACCCATAAATTTGATAAGGCCGCTGCCTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATAGGATGTTTAGGAGCCCTGATGTTCCCAGAGGCTGTGAAGGCCCATGTAAGGTCCAATCTTATGAGCAGCGTCATGATATCTCACATGTTGGGAAGGTCATCTGCATTTCGGATATAACACGTGGCAATGGTATTACCCATCGTGTTGGGAAGCGTTTCTGCGTCAAGTCCGTCTACATTTTGGGCAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACCAACAGTGTCATGTTTTGGTTGGTTAGGGACAGGAGACCTTATGGCACTCCTATGGAATTTGGGCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACTGTGAAGAACGATCTGCGTGATCGTTTTCAAGTCATGCATAAGTTCTACGCCAAGGTAACCGGTGGGCAGTATGCGAGTAACGAGCAGGCGCTGGTGAAGCGGTTCTGGAAGGTCAATAACTACGTGGTGTATAACCATCAAGAAGCAGGGAAATACGAGAATCATACGGAGAACGCTCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNANYSPRAGRTHKFDKAAAWVNRPMYRKPRIYRMFRSPDVPRGCEGPCKVQSYEQRHDISHVGKVICISDITRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMEFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009507979.1
|
|
Location
|
912-1310 |
|
Gene Name
|
ren |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACCGGGGAGAGCATCACTGTAGCTCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTGTATTTCAAGATACAACGCGTAGAGGACCCGTTGTACACCAGAACCAGGATCTACCACATCCAAGTCCGGTTCAACCACAACCTACGGAGAGCATTGGATCTCCACAAAGCCTACTTCAATTTCCAGGTCTGGACGAGTTCGATGAGAGCTTCTGGGCCGACATATTTAAGTAGATTCAAATGCCTTGTAATGTCTCATTTAGATAACCTAGGGGTTATTGGTATCAATCATGTAATTAGAGCTGTTCGTTTCGCAACGGACAGATCCTATGTAACTCATGTACACGAAAATCATGATATAAAAATCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGESITVAQAENSVFIWEVPNPLYFKIQRVEDPLYTRTRIYHIQVRFNHNLRRALDLHKAYFNFQVWTSSMRASGPTYLSRFKCLVMSHLDNLGVIGINHVIRAVRFATDRSYVTHVHENHDIKIKIY |
|
NCBI Accession
|
YP_009507980.1
|
|
Location
|
1057-1446 |
|
Gene Name
|
trap |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGAAATTCATCACCCTTGAAGCCCCCCTCTATCAAAGCACAGCACAAGACTGCTAAAAGGAGAGCTGTACGCAGAGGACGCATTGATTTGAACTGCGGGTGTTCTATCTTCCTCCATATCAATTGCGCTGATAATGGATTCACGCACCGGGGAGAGCATCACTGTAGCTCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTGTATTTCAAGATACAACGCGTAGAGGACCCGTTGTACACCAGAACCAGGATCTACCACATCCAAGTCCGGTTCAACCACAACCTACGGAGAGCATTGGATCTCCACAAAGCCTACTTCAATTTCCAGGTCTGGACGAGTTCGATGAGAGCTTCTGGGCCGACATATTTAAGTAG |
|
Protein Sequence
|
MRNSSPLKPPSIKAQHKTAKRRAVRRGRIDLNCGCSIFLHINCADNGFTHRGEHHCSSGREFRFYLGGSKSPVFQDTTRRGPVVHQNQDLPHPSPVQPQPTESIGSPQSLLQFPGLDEFDESFWADIFK |
|
NCBI Accession
|
YP_009507981.1
|
|
Location
|
1388-2443 |
|
Gene Name
|
rep |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACGAAAGGGCTCTTTCTCAGTTAAAGCCAAAAACTATTTCCTTACGTATCCACGATGCTCTCTTAGCAAAGAAGAGGCACTTTCCCAATTACAAAAAATAAACACTCCGGTGAACAAGAAGTTCATCAAAATATGCAGAGAGCTTCATGAAAATGGGGAGCCTCATATCCACGTTCTCATACAGTTCGAAGGGAAGTACAACTGCACGAATAACAGATTCTTCGACTTGGTCTCCCCATCCCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACAATTGAATGGGGAGTGTTCCAGATCGACGGAAGAAGTGCTAGAGGCGGTCAGCAAACAGCTAACGACGCAGCCGCCGAGGCACTAAACTCTGGAACAAAGGAGGAGGCCATGAAAATCATTAAAGAAAAGCTCCCGGAGAAGTTTCTTTTTCAGTATCACAACCTATCCAGTAACCTCGATAGGATTTTCAGTAAGGCTCCGGATCCTTGGTCTCCTCCGTTTCCCCTCTCCTCCTTTACTAACGTCCCGGACGAAATGCAAGAGTGGGCAGATGACTATTTTGGTCGGAGTGCCGCTGCGCGGCCGGAAAGACCTATTAGTATCATAGTGGAAGGTGATTCACGAACAGGCAAGACCATGTGGGCGCGTGCATTAGGACCACATAATTATTTGAGTGGGCACCTCGACTTTAATTCAAAGGTCTTTTCAAATAATGTGGAATATAACGTCATTGATGACATAGCTCCGCAATATCTAAAGCTAAAGCACTGGAAAGAGCTCATTGGGGCCCAAAGGGACTGGCAATCAAACTGTAAGTACGGCAAACCAGTTCAAATTAAAGGTGGCATACCCTCAATCGTGCTGTGCAATCCAGGAGAGGGGAGCGGTTATATAAGTTTCCTCAACAAAGAGGAAAACGCATCACTCAGAGCGTGGACTATCAAAAATGCGAAATTCATCACCCTTGAAGCCCCCCTCTATCAAAGCACAGCACAAGACTGCTAA |
|
Protein Sequence
|
MPRKGSFSVKAKNYFLTYPRCSLSKEEALSQLQKINTPVNKKFIKICRELHENGEPHIHVLIQFEGKYNCTNNRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGVFQIDGRSARGGQQTANDAAAEALNSGTKEEAMKIIKEKLPEKFLFQYHNLSSNLDRIFSKAPDPWSPPFPLSSFTNVPDEMQEWADDYFGRSAAARPERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFSNNVEYNVIDDIAPQYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSGYISFLNKEENASLRAWTIKNAKFITLEAPLYQSTAQDC |
|
NCBI Accession
|
YP_009507982.1
|
|
Location
|
2029-2292 |
|
Gene Name
|
ac4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAAAATGGGGAGCCTCATATCCACGTTCTCATACAGTTCGAAGGGAAGTACAACTGCACGAATAACAGATTCTTCGACTTGGTCTCCCCATCCCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACAATTGAATGGGGAGTGTTCCAGATCGACGGAAGAAGTGCTAGAGGCGGTCAGCAAACAGCTAACGACGCAGCCGCCGAGGCACTAA |
|
Protein Sequence
|
MKMGSLISTFSYSSKGSTTARITDSSTWSPHPGQHISIRTYRELNPAPTSSPTSTRTEIQLNGECSRSTEEVLEAVSKQLTTQPPRH |
|
NCBI Accession
|
YP_009507983.1
|
|
Location
|
375-1145 |
|
Gene Name
|
nsp |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATCCTACAAAGTTTAGGCGTGGGACTTCTTACTCTCATAGACGATTTGTTTCACGTAATCCTTCTTTTAAGCGTGGAACTTTGGTTAGACGCACTGATGGGAAACATCGTAAAGGCCCATCAAGCAAAGCCCATGATGAGCCTAAAATGAAATTACAACGCATACATGAAAATCAATATGGGCCTGAATTTGTCATGACCCACAACTCAGCTCTTTCAACATTCATTAATTTCCCGGTACTTGGGAAGATCGAACCTAACCGAAGCAGGTCGTATATTAAGTTGAATCGTTTATTATTTAAGGGAACCGTTAAGATTGAGCGTGTGCACGCTGATGTGAACATGGACGGAGTAAGTTCGAAGATAGAAGGTGTGTTCTCTCTTGTTATTGTTATGGATCGCAAGCCACATTTGAGTTCCGCTGGAGGTTTGCATACATTTGATGAAATGTTTGGTGCAAGAATCCACAGCCATGGTAACTTAGCTATTGCACCCGGTTTGAAAGATCGTTATTACGTGCTCCATGTTTTCAAACGCGTATTGTCTGTGGAGAAAGACACTTTGATGGTGGATCTTGAAGGATCGACCATGATATCTAATAGGCGTTATAACTGTTGGGCCTCGTTTAACGATCTTGAACATGACTCATGTAACGGTGTTTATGCGAATATAAGCAAAAATGCCATTTTAGTTTACTATTGTTGGATGTCCGATGCTATGTCTAAGGCATCGACCTTTGTATCTTACGATCTTGATTATTTAGGTTAA |
|
Protein Sequence
|
MYPTKFRRGTSYSHRRFVSRNPSFKRGTLVRRTDGKHRKGPSSKAHDEPKMKLQRIHENQYGPEFVMTHNSALSTFINFPVLGKIEPNRSRSYIKLNRLLFKGTVKIERVHADVNMDGVSSKIEGVFSLVIVMDRKPHLSSAGGLHTFDEMFGARIHSHGNLAIAPGLKDRYYVLHVFKRVLSVEKDTLMVDLEGSTMISNRRYNCWASFNDLEHDSCNGVYANISKNAILVYYCWMSDAMSKASTFVSYDLDYLG |
|
NCBI Accession
|
YP_009507984.1
|
|
Location
|
1204-2085 |
|
Gene Name
|
mp |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGATTCTCAGCTAGCAAATGCTCCAAATGCGTTTAATTACATAGAGTCTCATAGAGACGAATATCAGCTATGTCATGATCTTACTGAAATAGTACTGCAATTCCCTTCAACTGCAGCGCAATTTACAGCAAGGCTTAATCGTAGCTGTATGAAAATCGACCATTGCGTCATCGAATATAGACAGCAAGTACCAATTAACGCAACCGGGACGGTGATTGTAGAGATCCATGATAAGAGGATGACTGACGATGAATCCTTACAGGCGTCTTGGACATTTCCCTTAAGATGCAACATAGATCTCCACTATTTTTCATCTTCATTCTTCTCGCTAAAAGACCCTATTCCGTGGAAACTCTATTACAGGGTTAGCGACACGAATGTGCATCAACGAACACATTTTGCCAAGTTTAAAGGGAAATTGAAATTGTCAACAGCTAAACATTCAGTGGATATACCCTTCCGGGCACCAACAGTGAAAATTCACTCCAAACAATTTTCACATAGAGATGTTGATTTCTCCCATGTGGACTACGGAAAATGGGAGAGGAAAACGTTGAGGTCCAGATCATTGTCAAGAATTGGACTAACAGGCCCAATTGAATTACAACCAGGTGATTCATGGGCTTCAAGGAGCACTATTGGGCTTACAAACCCACAAACTGAATCAGAAGTGGAGAATGCGCTACATCCATATAGAGAACTCAACCAGCTAGGAACTAGCGCATTAGACCCCGGGGATTCAGCATCACAAGCTGGATTACAGAGGGCCCAATCAACCATAACGATGTCAGTGGCCCAATTAAGCGAGCTAGTTAGGACGACGGTCCAGGAATGTATTAACAATAATTGTAATCCTACACAACCAAAGTCATTGCAATAA |
|
Protein Sequence
|
MDSQLANAPNAFNYIESHRDEYQLCHDLTEIVLQFPSTAAQFTARLNRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDDESLQASWTFPLRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIHSKQFSHRDVDFSHVDYGKWERKTLRSRSLSRIGLTGPIELQPGDSWASRSTIGLTNPQTESEVENALHPYRELNQLGTSALDPGDSASQAGLQRAQSTITMSVAQLSELVRTTVQECINNNCNPTQPKSLQ |