Tomato mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000837105.1 |
| Release date | 2015/2/12 |
| Submitter | Abouzid,A.M., Polston,J.E., Hiebert,E. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
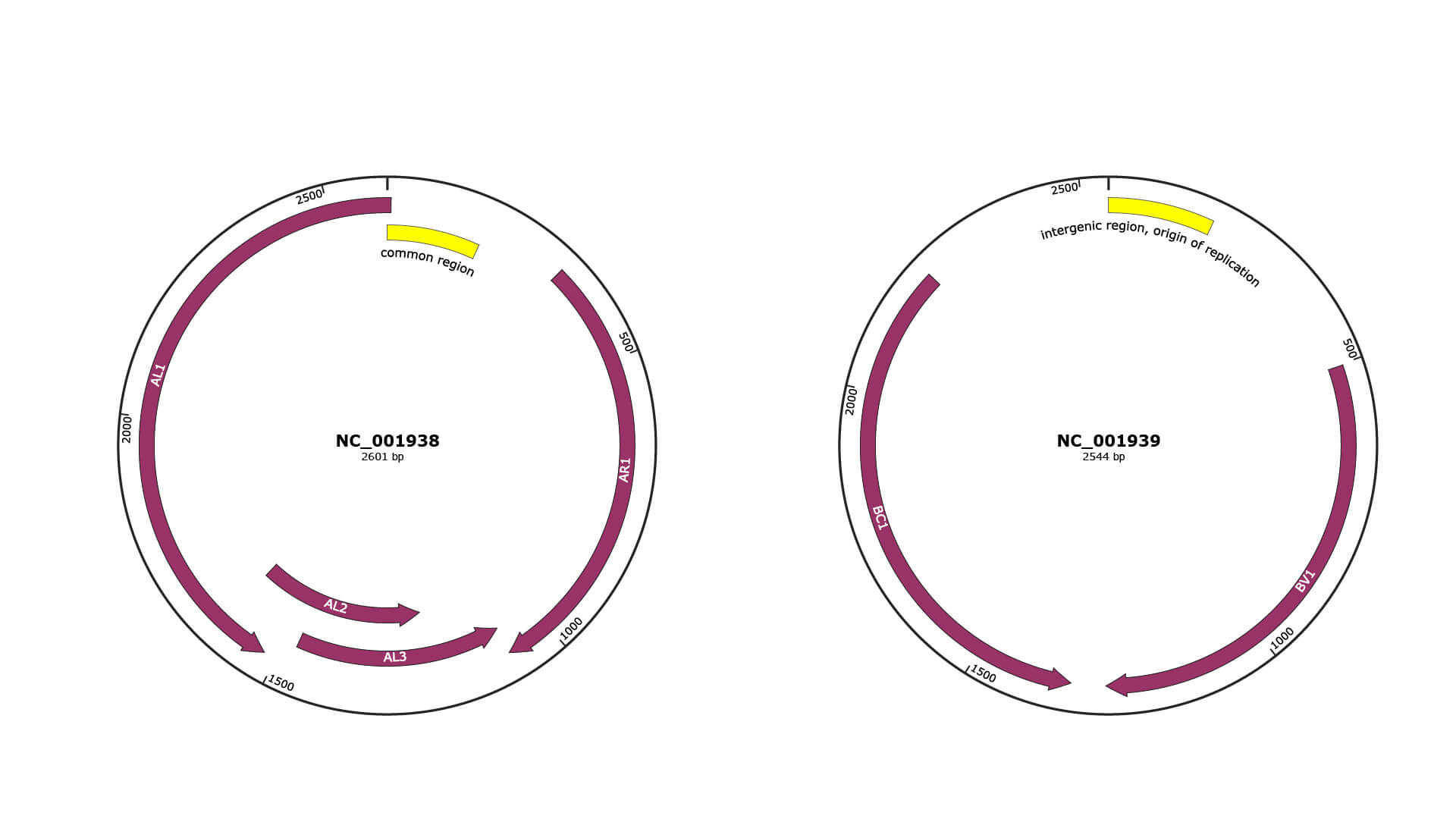
JBrowse
Genome
NC_001938
NC_001939
Gene Information
| NCBI Accession | NP_047249.1 |
|---|---|
| Location | 1523-2601,1-7 |
| Gene Name | AL1 |
| Protein Name | replicative protein |
| Coding Region | ATGCCCCCACCAAAGAAATTTAGAGTTCAGTCAAAGAACTATTTCCTAACTTATCCCCAGTGCTCTCTATCTAAAGAAGAAGCACTTTCCCAATTACAAAACCTAAATACCCCAGTCAACAAGAAATTCATCAAAATTTGCAGAGAGCTTCATGAAAATGGGGAACCTCATCTCCATGTGCTTGTTCAGTTCGAAGGTAAGTACCAATGCACGAATAACAGATTCTTCGACCTGGTCTCCCCAACCCGGTCAGCACATTTCCATCCGAATATTCAGGGAGCTAAATCGAGCTCCGACGTCAAATCATACATCGACAAGGACGGAGATACAATCGAATGGGGAGATTTCCAAATCGACGGCAGATCTGCCAGAGGAGGCCAGCAGTCTGCTAATGATTCATATGCGAAAGCATTAAATGCAGGTTCGGTTCAATCTGCCTTAGCGGTTCTAAGGGAAGAACAACCAAAAGATTTTGTATTACAAAATCATAACATCCGCTCTAACCTAGAACGAATATTCGCAAAGGCTCCGGAACCGTGGGTTCCTCCATTTCAAGTCTCTTCTTTCACTAACGTTCCTGACGAGATGCAGGAATGGGCGGATAATTATTTCGGGACGGGTGACGCTGCGCCGCCGGATAGACCTGTAAGTATCATCGTCGAGGGTGATTCAAGAACAGGGAAGACGATGTGGGCGCGTGCGTTAGGCCCACATAACTATCTCAGTGGACACCTAGACTTCAATGGTCGAGTCTTCTCGAATGATGTGCAGTATAACGTCATTGATGACATCGCACCGCATTATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAGAAAGATTGGCAATCAAATTGCAAGTACGGTAAGCCAGTTCAAATTAAAGGCGGAATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGAGTTCTTAGACAAAGCAGAAAATACAGGTCTCAAGAACTGGACTATCAAGAATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAGAGCACACAGGCAAGCCAAGAAACGGGCAATCAGAAGGCGCAGGGTTGA |
| Protein Sequence | MPPPKKFRVQSKNYFLTYPQCSLSKEEALSQLQNLNTPVNKKFIKICRELHENGEPHLHVLVQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGDFQIDGRSARGGQQSANDSYAKALNAGSVQSALAVLREEQPKDFVLQNHNIRSNLERIFAKAPEPWVPPFQVSSFTNVPDEMQEWADNYFGTGDAAPPDRPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVFSNDVQYNVIDDIAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKEFLDKAENTGLKNWTIKNAIFITLTAPLYQESTQASQETGNQKAQG |
| NCBI Accession | NP_047250.1 |
|---|---|
| Location | 325-1080 |
| Gene Name | AR1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGTGATTTGCCATGGCGATCGATGGCGGGAACCTCAAAGGTTAGCCGCAATGCTAATTATTCTCCCCGTGCAGGTATTGGGCCAAGAATTAACAAGGCCGCTGAATGGGTGAACCGGCCCATGTACAGGAAGCCCAGGATGTATCGGACTCTTAGGACAACTGACGTCGCCAGGGGCTGTGAAGGCCCATGTAAGGTCCAGTCTTTCGAACAGCGCCATGACATCTCACATATCGGTAAGGTCATGTGCATATCCGATGTGACTCGTGGTAATGGCATAACCCACCGTGTTGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTTGGTAAGATTTGGATGGATGAGAACATCAAGCTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTAAGAGATCGTAGACCCTATGGTACTCCAATGGACATTTGGACAGTGTTCAACATGTTCGACAACGAGCCTAGCACTGCTACTGTCAAAAACGATCTACGCGATCGTTACCAGGTCATGCATAAGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTTAAGAGGTTCTGGAAGGTCAACAATCATGTAGTCTATAATCATCAAGAGGCTGGCAAGTACGAGAATCACACAGAGAACGCCTTGTTATTGTATATGGCATGCACTCATGCGTCTAACCCTGTATATGCAACTTTGAAAATTCGAATCTATTTTTATGATTCGATCACGAATTAA |
| Protein Sequence | MPKRDLPWRSMAGTSKVSRNANYSPRAGIGPRINKAAEWVNRPMYRKPRMYRTLRTTDVARGCEGPCKVQSFEQRHDISHIGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDIWTVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_047251.1 |
|---|---|
| Location | 1077-1475 |
| Gene Name | AL3 |
| Protein Name | AL3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGCTAGAAAATCCCCTTTATTTCAAGATACACAGAGTAGAGGACCCACTGTATACCAGAACGAGGGTATACCACGTACAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTTTGGACGACGTCGATGACAGCTTCTGGATCAATTTATTTAGCTAGATTTAGATATTTAGTCAACATGTATCTAGATCAATTAGGTGTTATTTCAATAAACAATGTAGTTAGAGCTGTACGTTTCGCAACAAACAGAGTGTATGTAAATCATGTATTGGAGAATCATTCAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGELITAHQAENGVYIWELENPLYFKIHRVEDPLYTRTRVYHVQIRFNHNLRKALHLHKAYLNFQVWTTSMTASGSIYLARFRYLVNMYLDQLGVISINNVVRAVRFATNRVYVNHVLENHSIKFKFY |
| NCBI Accession | NP_047252.1 |
|---|---|
| Location | 1222-1611 |
| Gene Name | AL2 |
| Protein Name | AL2 protein |
| Coding Region | ATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAGAGCACACAGGCAAGCCAAGAAACGGGCAATCAGAAGGCGCAGGGTTGATCTACAGTGCGGGTGCTCCATCTACTTCCACTTAGGCTGTGCGGGACATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGCTAGAAAATCCCCTTTATTTCAAGATACACAGAGTAGAGGACCCACTGTATACCAGAACGAGGGTATACCACGTACAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTTTGGACGACGTCGATGACAGCTTCTGGATCAATTTATTTAGCTAG |
| Protein Sequence | MRSSSPSQPPSIKRAHRQAKKRAIRRRRVDLQCGCSIYFHLGCAGHGFTHRGTHHCTSGGEWRVYLGARKSPLFQDTQSRGPTVYQNEGIPRTDTVQPQPEESVASPQSLPELPSLDDVDDSFWINLFS |
| NCBI Accession | NP_047253.1 |
|---|---|
| Location | 503-1276 |
| Gene Name | BV1 |
| Protein Name | nuclear membrane movement protein |
| Coding Region | ATGTATCCTTTAAAGAGTAAACGTGGTTTCTCATATTCAAATCGAAGATTTAACTCACGTAATATTGTGTTTAACCGTCCAGTTTCTGGTAAGAGACATGATGGAAAGCGTCGGGGAGGTAATTTCGTGAAGCCCAATGATGAGCCCAAGATGTTAGCCCAACGCATACATGAGAATCAGTATGGGCCTGAATTTGTATTGGCCCATAACTCAGCTATCTCCACATTTATTCCAGTTATCCATCTTGGGCAAGTCCCGAAGCCCAGTCGAAGTAGGTCCTATATCAAGTTGAAACGTCTCCGTTTCAAAGGGACTGTGAAGATTGAGCGTGTTCAATCTGATTTGAACATGGATGGTTTTATGCCTAAAGTCGAAGGAGTATTCTCTATGGTTGTTGTTGTGGATCGTAAACCACACCTTGGGCCTTCCGGGTGTTTGCATACATTCGACGAGCTATTTGGTGCAAGGATCAATAGTCATGGCAACCTCACTATTGTACCTTCTCTGAAAGATCGCTTCTACATTAGACATGTGTTCAAGCGAGTGCTCTCAGTTGAGAAGGATACGTTGATGGTGGACGTTGAAGGATCCACAACACTCTCTAACAGGCGTTACAACTGCTGGTCTACGTTTAAAGACCTTGATCGTGAATCATGCAAGGGTGTTTATGATAACATTAGCAAGAACGCCTTGTTAGTTTATTATTGCTGGATGTCTGACACGCCTGCGAATGCATCATCTTTTGTATCTTTTGATCTTGATTATATTGGTTAA |
| Protein Sequence | MYPLKSKRGFSYSNRRFNSRNIVFNRPVSGKRHDGKRRGGNFVKPNDEPKMLAQRIHENQYGPEFVLAHNSAISTFIPVIHLGQVPKPSRSRSYIKLKRLRFKGTVKIERVQSDLNMDGFMPKVEGVFSMVVVVDRKPHLGPSGCLHTFDELFGARINSHGNLTIVPSLKDRFYIRHVFKRVLSVEKDTLMVDVEGSTTLSNRRYNCWSTFKDLDRESCKGVYDNISKNALLVYYCWMSDTPANASSFVSFDLDYIG |
| NCBI Accession | NP_047254.1 |
|---|---|
| Location | 1336-2217 |
| Gene Name | BC1 |
| Protein Name | cell-to-cell movement protein |
| Coding Region | ATGGATTCTCAGTTAGTTAATCCTCCTAGTGCATTCAACTACATAGAGTCACACCGTGACGAATATCAGCTTTCTCATGACCTAACTGAGATAATACTGCAGTTTCCGTCCACGGCGTCGCAGTTAACCGCTAGGCTCAGCCGTAGCTGCATGAAAATCGACCACTGCGTCATAGAGTACAGACAACAAGTACCAATAAACGCCACTGGGTCGGTAATAGTGGAGATTCACGACAAAAGGATGACGGAGAATGAGTCTTTACAGGCATCATGGACATTTCCGATCAGGTGCAACATAGATCTCCACTATTTCTCAGCTTCCTTCTTCTCCTTGAAAGACCCAATTCCATGGAAATTGTATTACAGGGTTTGCGATACGAATGTTCATCAACGGACCCACTTCGCCAAGTTTAAGGGGAAGCTGAAATTGTCCACAGCAAAACACTCAGTAGACATTCCCTTCCGGGCACCAACAGTAAAAATCCTGTCCAAACAGTTCACAGATAAAGATGTGGACTTTTCCCATGTGGATTACGGTAAATGGGAGAGGAAGCCCATTAGATGCGCGTCTATGTCCAGACTTGGGCTTAGAGGCCCAATTGAGATCAGGCCTGGTGAGTCATGGGCTTCAAGGAGTACAATAGGCATAGGGCATTCAGATGCAGACTCAGAAGTGGAGAACGAACTCCACCCGTACAGACATCTAAACAGGCTAGGAACAGGCATACTGGACCCGGGAGAGTCTGCTTCTATTGTGGGGGCCCAGAAAGCAGAGTCCAACATTACAATGTCTATGGGTCAGTTGAACGAATTAATACGGACTACGGTCCATGAATGTATTAATAGTAATTGTAAGGCGTCTCAGACGAAATCATTAAAATAA |
| Protein Sequence | MDSQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTENESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRLGLRGPIEIRPGESWASRSTIGIGHSDADSEVENELHPYRHLNRLGTGILDPGESASIVGAQKAESNITMSMGQLNELIRTTVHECINSNCKASQTKSLK |
References More References in PubMed
| 1 |
Occurrence of pepper mottle virus on tomato in India. Sharma S, et al. Virusdisease. 2019 Sep;30(3):474-475. doi: 10.1007/s13337-019-00543-4. Epub 2019 Jul 22. PMID: 31803817 |
|---|---|
| 2 |
A tomato mottle mosaic virus-based vector system for gene function studies in tomato. Yan ZY, et al. Virology. 2025 Jul;608:110549. doi: 10.1016/j.virol.2025.110549. Epub 2025 Apr 16. PMID: 40252327 |
| 3 |
Kimura K, et al. Viruses. 2023 Aug 3;15(8):1688. doi: 10.3390/v15081688. PMID: 37632030 |
| 4 |
Wang GD, et al. Viruses. 2024 Apr 26;16(5):687. doi: 10.3390/v16050687. PMID: 38793569 |
| 5 |
Tiberini A, et al. Plants (Basel). 2022 Feb 11;11(4):489. doi: 10.3390/plants11040489. PMID: 35214821 |
| 6 |
Tomato mottle wrinkle virus, a recombinant begomovirus infecting tomato in Argentina. Vaghi Medina CG, et al. Arch Virol. 2015 Feb;160(2):581-5. doi: 10.1007/s00705-014-2216-y. Epub 2014 Sep 25. PMID: 25252814 |
| 7 |
Engineered Resistance to Tobamoviruses. Carr JP. Viruses. 2024 Jun 22;16(7):1007. doi: 10.3390/v16071007. PMID: 39066170 |
| 8 |
Souza JO, et al. J Virol. 2022 Sep 28;96(18):e0072522. doi: 10.1128/jvi.00725-22. Epub 2022 Aug 31. PMID: 36043875 |
| 9 |
Taino Tomato Mottle Virus, a New Bipartite Geminivirus from Cuba. Ramos PL, et al. Plant Dis. 1997 Sep;81(9):1095. doi: 10.1094/PDIS.1997.81.9.1095C. PMID: 30861977 |
| 10 |
Sui X, et al. Plant Dis. 2017 May;101(5):704-711. doi: 10.1094/PDIS-10-16-1504-RE. Epub 2017 Mar 7. PMID: 30678578 |