Tomato mosaic severe dwarf virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_018587715.1 |
| Isolate | Brazil |
| Release date | 2021/6/1 |
| Submitter | Alves-Andrade,I., Gilbertson,R.L., Boiteux,L.S., Fonseca,M.E.N., Rojas,M.R., Reis,L.N.A., Pereira-Carvalho,R.C. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
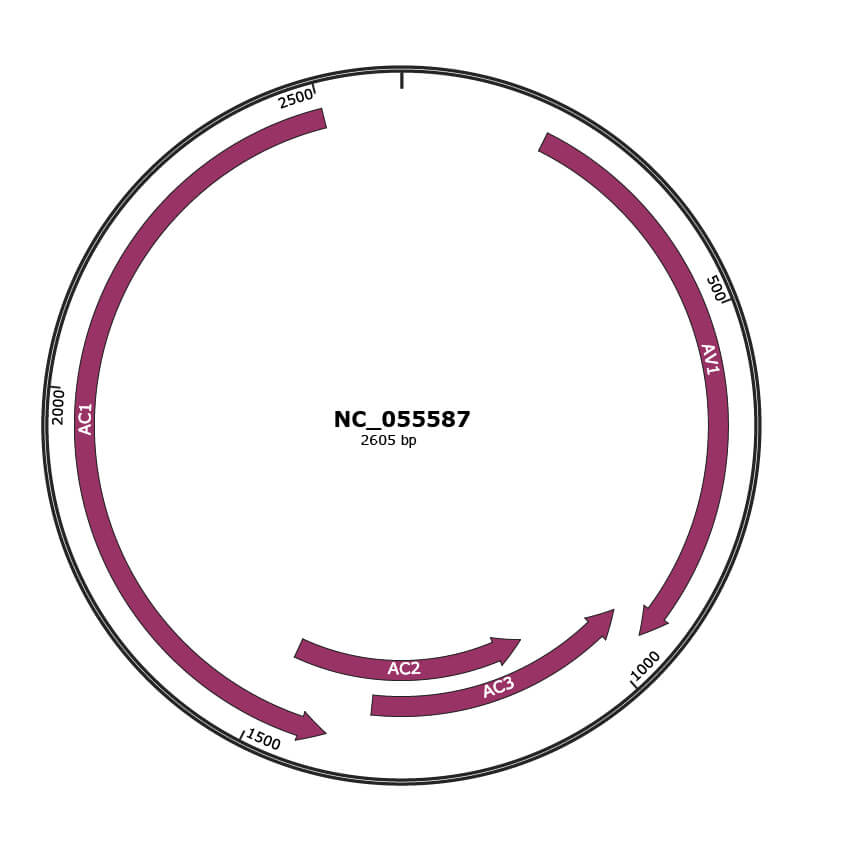
JBrowse
Genome
NC_055587
Gene Information
| NCBI Accession | YP_010087802.1 |
|---|---|
| Location | 193-951 |
| Gene Name | AV1 |
| Protein Name | Cp |
| Coding Region | ATGTCTAAGCGGGCTGCCCCCTCGTGGCGCTCTATGGCGGGTATCTCAAAGGTTAGCCGCTCACTTAATTTCTCGCCTCGTGGAGGTATTAATCCCAAATTTGATAGGGCCTCAGCGTGGGTCAATCGACCCATGTACAGGAAGCCCAGGATATATCGGACTATTCGAAGCCCTGATGTCCCTAAAGGGTGTGAGGGGCCTTGTAAGGTCCAATCATTTGAACAGCGCCACGATATCTCCCATACCGGGAAGGTGCTGTGTATATCTGATGTGACACGGGGCAGTGGTATTACCCACCGTGTCGGTAAGCGTTTTTGCGTGAAGTCCGTTTATATTTTAGGCAAGGTATGGATGGACGAGAACATCAAGTTGAAGAACCATACGAACAGCGTCATGTTCTGGTTGGTTAGAGACAGGAGACCCTATGGCACGCCGATGGATTTTGGACAGGTGTTCAACCTGTTTGATAATGAGCCCAGTACTGCGACTGTGAAGAACGATCTCCGGGATCGTTTCCAAGTGATGCACAGATTCCACACTAAGGTGACGGGTGGACAGTATGCGAGCAACGAGCAGGCTCTTGTCCGGCGATTTTGGAAGGTCAACACCCATGTTGTGTACAACCATCAGGAAGCTGCGAAGTATGAGAACCACACGGAGAACGCCCTCTTATTGTATATGGCATGTACTCATGCATCTAACCCTGTGTATGCAACCCTTAAGATCCGGATCTATTTCTACGATTCGGTATCGAATTAA |
| Protein Sequence | MSKRAAPSWRSMAGISKVSRSLNFSPRGGINPKFDRASAWVNRPMYRKPRIYRTIRSPDVPKGCEGPCKVQSFEQRHDISHTGKVLCISDVTRGSGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNLFDNEPSTATVKNDLRDRFQVMHRFHTKVTGGQYASNEQALVRRFWKVNTHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVSN |
| NCBI Accession | YP_010087803.1 |
|---|---|
| Location | 948-1346 |
| Gene Name | AC3 |
| Protein Name | Ren |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAAGCGGAGAATGGCGTGTATATCTGGGAAGTACCAAATCCCCTATATTTCAAGATATACCGAGTCGAAGACCCACTCTACACCACGACCAGAGTCTACCACATCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAGGCATACCTGAACTTCCAAGTCTGGACGACTTCAGTGACAGCTTCTGGGACGACATATTTAGATAGATTTAGACATTTCATCATGTTTTATTTAGATAGTTTGGGCGTTATATCCATTAATAATGTAATTAGAGCTGTTCGTTTCGCAACACACAGACCATATGTAACATCTGTACTCGAAGATCATTCAATAAAATTCAAACTTTATTAA |
| Protein Sequence | MDSRTGELITAPQAENGVYIWEVPNPLYFKIYRVEDPLYTTTRVYHIQIRFNHNLRRALDLHKAYLNFQVWTTSVTASGTTYLDRFRHFIMFYLDSLGVISINNVIRAVRFATHRPYVTSVLEDHSIKFKLY |
| NCBI Accession | YP_010087804.1 |
|---|---|
| Location | 1093-1482 |
| Gene Name | AC2 |
| Protein Name | TRaP |
| Coding Region | ATGCGAGGTTCGTCTTCCTCGAATCCCCCCTCTATCAAAGCTCAACACAGAGCAGCCAAGCGCAGGGCAATTCGACGTAGACGAATAGACCTCAACTGCGGGTGCTCAGTATACGTCCACATCAACTGCGTCGGTCATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAAGCGGAGAATGGCGTGTATATCTGGGAAGTACCAAATCCCCTATATTTCAAGATATACCGAGTCGAAGACCCACTCTACACCACGACCAGAGTCTACCACATCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAGGCATACCTGAACTTCCAAGTCTGGACGACTTCAGTGACAGCTTCTGGGACGACATATTTAGATAG |
| Protein Sequence | MRGSSSSNPPSIKAQHRAAKRRAIRRRRIDLNCGCSVYVHINCVGHGFTHRGTHHCTSSGEWRVYLGSTKSPIFQDIPSRRPTLHHDQSLPHPDTVQPQPQESVGSPQGIPELPSLDDFSDSFWDDIFR |
| NCBI Accession | YP_010087805.1 |
|---|---|
| Location | 1403-2503 |
| Gene Name | AC1 |
| Protein Name | REp |
| Coding Region | TTGCTGGTGTCCTGCCCTATATTTACCAAAATGCCACGAAACCCTAATCAATTTAGGCTTGCTGCCAAAAATATATTCCTCACATATCCCCAATGCGATATACCAAAAGATGAAGCTCTTCAAATGCTTCAATCCCTTCCATGGTCAATCGTCAAACCCACATATATACGAGTCGCCAGGGAGGAACACTCCGACGGATTCCCCCACCTCCATTGTCTTATACAACTCTCAGGAAAGTCTAACATCAAGGATGTTAGATTTTTCGACCTCACTCACCCCAGAAGGTCTGCCACTTTTCACCCAAATATTCAGGCAGCCAAGGACACCAACGCCGTCAAGAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGACAATACAAGGTGTCTGGGGGTACGAAGGCCAATAAAGACGACGTCTACCACAACGCAGTTAATGCAGCTAGTGCAGGAGAGGCTCTGGAGATTATCAGAGCAGGAGACCCCAAGACGTTCGTTGTAAGTTATCATAACGTAAAGGCTAACATTGAACGTCTCTTCCAAAAAGCTCCTGAACCGAGGGTTCCTCCGTTTCCCCTCTCATCGTTCACTAACGTTCCCGCGGAGATGCAGGAATGGGCAGATGACTATTTTGGAAGGGGTTCCGCTGCGCGGCCGGAGAGACCTATTAGTTTAATTATTGAGGGGGATTCGAGGACGGGGAAGACGATGTGGGCCATAGCATTGGGGGTCCACAATTATATCAGCGGCCACATTGATTTGAATTCTAGGGTTTACAACAATAATGCAGAGTACAACGTCATTGATGACATCCCTCCTCATTATTTAAAGTTAAAGCACTGGAAAGAATTAATTGGGGCCCAAAGCAACTGGCAGACAAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGTATACCATCAATCGTGCTCTGCAATCCTGGCGAAGGAGCCAGCTATAAATATTTCCTCGACAAAGAGGAAAACGCATCCCTAAGAAATTGGACTCTCAAGAATGCGAGGTTCGTCTTCCTCGAATCCCCCCTCTATCAAAGCTCAACACAGAGCAGCCAAGCGCAGGGCAATTCGACGTAG |
| Protein Sequence | MLVSCPIFTKMPRNPNQFRLAAKNIFLTYPQCDIPKDEALQMLQSLPWSIVKPTYIRVAREEHSDGFPHLHCLIQLSGKSNIKDVRFFDLTHPRRSATFHPNIQAAKDTNAVKNYITKEGDYCESGQYKVSGGTKANKDDVYHNAVNAASAGEALEIIRAGDPKTFVVSYHNVKANIERLFQKAPEPRVPPFPLSSFTNVPAEMQEWADDYFGRGSAARPERPISLIIEGDSRTGKTMWAIALGVHNYISGHIDLNSRVYNNNAEYNVIDDIPPHYLKLKHWKELIGAQSNWQTNCKYGKPVQIKGGIPSIVLCNPGEGASYKYFLDKEENASLRNWTLKNARFVFLESPLYQSSTQSSQAQGNST |
References More References in PubMed
| 1 |
Ogawa T, et al. Virus Res. 2008 Nov;137(2):235-44. doi: 10.1016/j.virusres.2008.07.021. Epub 2008 Sep 13. PMID: 18722488 |
|---|---|
| 2 |
Next-Generation Sequencing and Genome Editing in Plant Virology. Hadidi A, et al. Front Microbiol. 2016 Aug 26;7:1325. doi: 10.3389/fmicb.2016.01325. eCollection 2016. PMID: 27617007 |
| 3 |
Jones RAC. Viruses. 2020 Dec 4;12(12):1388. doi: 10.3390/v12121388. PMID: 33291635 |
| 4 |
Genetic diversity of begomoviruses infecting tomato plant in Saudi Arabia. Sohrab SS. Saudi J Biol Sci. 2020 Jan;27(1):222-228. doi: 10.1016/j.sjbs.2019.08.015. Epub 2019 Aug 22. PMID: 31889840 |
| 5 |
Rapid detection of fifteen known soybean viruses by dot-immunobinding assay. Ali A. J Virol Methods. 2017 Nov;249:126-129. doi: 10.1016/j.jviromet.2017.09.003. Epub 2017 Sep 6. PMID: 28887190 |
| 6 |
Li C, et al. Virus Genes. 2020 Feb;56(1):67-77. doi: 10.1007/s11262-019-01708-5. Epub 2019 Oct 23. PMID: 31646461 |
| 7 |
Interaction of tomato yellow leaf curl virus with diverse betasatellites enhances symptom severity. Ito T, et al. Arch Virol. 2009;154(8):1233-9. doi: 10.1007/s00705-009-0431-8. Epub 2009 Jul 3. PMID: 19575277 |
| 8 |
A Bipartite Geminivirus Infecting Tomatoes in Cuba. Martinez Y, et al. Plant Dis. 1997 Oct;81(10):1215. doi: 10.1094/PDIS.1997.81.10.1215C. PMID: 30861720 |
| 9 |
Ling KS, et al. Plant Dis. 2014 May;98(5):701. doi: 10.1094/PDIS-09-13-0992-PDN. PMID: 30708518 |
| 10 |
Iris yellow spot virus: A New Onion Disease in Spain. Córdoba-Sellés C, et al. Plant Dis. 2005 Nov;89(11):1243. doi: 10.1094/PD-89-1243A. PMID: 30786456 |