Tomato mosaic Havana virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000837605.1 |
| Release date | 2015/2/12 |
| Submitter | Martinez-Zubiaur,Y., de Blas,C., Quinones,M., Castellanos,C., Peralta,E.L., Romero,J., Romero,L.C., Martinez Zubiaur,Y. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
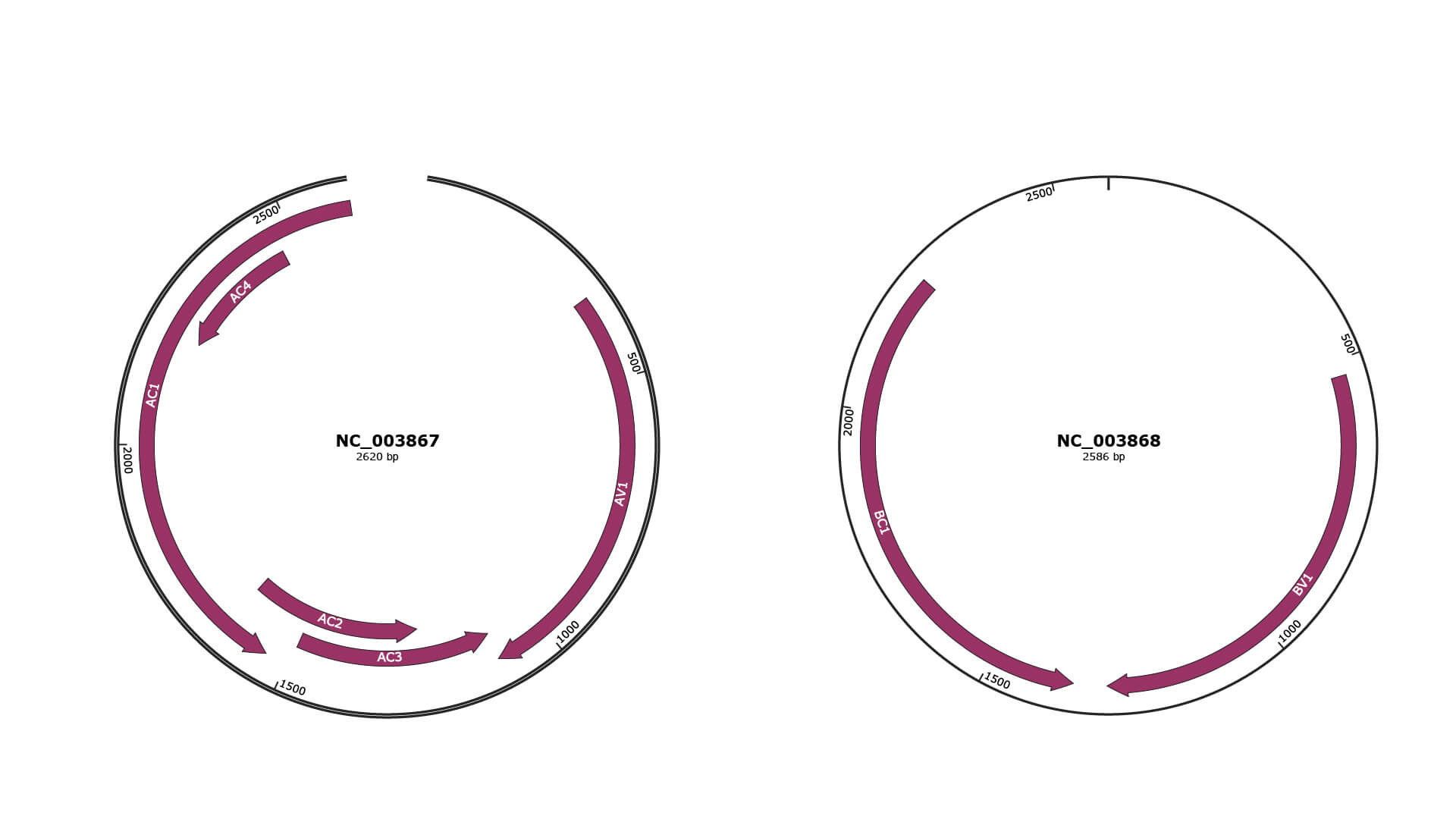
JBrowse
Genome
NC_003867
NC_003868
Gene Information
| NCBI Accession | NP_620889.1 |
|---|---|
| Location | 344-1099 |
| Gene Name | AV1 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCCTAAGCGTGATTTGCCATGGCGTTCTATGGCGGTAACCTCAAAGGTTAGCCGCAACGCTAATTGTTCTCCTCGGTCAGGTATTGGGCCAAAATACAACAAGGCCGCTGAATGGGTTAACAGGCCCATGTACCGGAAGCCCAGGATCTATCGGACTCTGAAGAGTCCTGATGTTGCCAGAGGTTGTGAAAGCCCTTGTAAAGTCCAGTCTTACGAACAGCGCCATGACATCTCACATGTGGGCAAGGTCATGTGCATATCTGACGGGACACGTGGTAATGGTATTACTCATCGTGTGGGAAAGCGTTTCTGTGTGAAGTCTGTGTACATACTAGGGAAGATCTGGATGGACGAGAATATCAAGCTGAAAAACCACACGAACAGCGTCATGTTCTGGTTGGTTAGAGATAGGAGACCCTATGGGACGCCCATGGATTTTGGTCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACAGCCACTGTGAAGAACGATCTTCGTGATCGTTACCAGGTCATGCACAAGTTCTATGGCAAGGTGACCGGTGGTCAGTATGCCAGCAACGAACAGGCTATCGTGAAGCGGTTCTGGAAGGTGAACAACCACGTGGTCTACAATCACCAAGAGGCTGGCAAATACGAGAATCATACTGAGAACGCCCTACTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACTCTGAAGATCCGGATCTATTTTTATGATTCGATCATGAATTAA |
| Protein Sequence | MPKRDLPWRSMAVTSKVSRNANCSPRSGIGPKYNKAAEWVNRPMYRKPRIYRTLKSPDVARGCESPCKVQSYEQRHDISHVGKVMCISDGTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | NP_620890.1 |
|---|---|
| Location | 1096-1494 |
| Gene Name | AC3 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGATTCCCCCACAGGGGATATCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACAGAGTAGAGGAACCACTGTACAGCAGGAGCAGAGTGTACCACATACAAATCAGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTGTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAGGTTTAGACATTTAGTTATCGTGTATTTAGATCAATTAGGTGTAATTTCATTGAACAATGTAATTAGAGCTGTACGTTTTGCAACAGATAGACATTATGTACACGATGTATTAGAGAATCATTCAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSPTGDIITARQAENGVYIWEIENPLYFKIYRVEEPLYSRSRVYHIQIRFNHNLRRALHLHKAFLNFQVWTTSMTASGSTYLARFRHLVIVYLDQLGVISLNNVIRAVRFATDRHYVHDVLENHSIKFKFY |
| NCBI Accession | NP_620891.1 |
|---|---|
| Location | 1241-1630 |
| Gene Name | AC2 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCGCTCTTCATCACCCTCACATCCGCCCTCTATCAAGATAGCTCACAGGCAAGCAAAGAAGAAGACAATCAGGAGAAGGCGGATTGATCTGGAGTGCGGTTGCTCCATTTACTTCCACATAGACTGCGCTGGACATGGATTCCCCCACAGGGGATATCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACAGAGTAGAGGAACCACTGTACAGCAGGAGCAGAGTGTACCACATACAAATCAGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTGTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAG |
| Protein Sequence | MRSSSPSHPPSIKIAHRQAKKKTIRRRRIDLECGCSIYFHIDCAGHGFPHRGYHHCTSGREWRVYLGDRKSPLFQDIQSRGTTVQQEQSVPHTNQVQPQPEESVASPQSLPELPSVDDIDDSFWVNLFS |
| NCBI Accession | NP_620892.1 |
|---|---|
| Location | 1542->2620 |
| Gene Name | AC1 |
| Protein Name | hypothetical protein |
| Coding Region | CCAAAGAAATTTAGAGTTAACTCTAAAAACTATTTCCTCACTTATCCACAGTGCTCCATTACCAAAGAAGAGGCACTTTCCCAAATAAAAAACCTAAACACTCCAGTTAACAAGAAGTTCATCAAGATCTGCAGAGAGCTTCATGAAAATGGGGAGCCTCATCTCCATGTGCTTTTGCAGTTCGAAGCCAAATACCAGTGCACGAATAGCAGATTCTTCGACCTGGTCTCCCCATCCCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAGTCGAGCTCCGACGTCAAGGCATACATCGACAAGGACGGAGATGCGACAGAATGGGGGGAATTCCAGATCGACGGTCGATCTGCTAGAGGAGGCTGCCAGTCGGCCAACGATACATATGCAAAGGCATTGAATGCCTCATGTGCAGAAGAGGCTCTACAAATAATAAAAGAACAGCAGCCTCAACATTTCTTCCTCCATCACCATAACCTGGTCGCAAATGCACAAAGGATCTTCCACAAACCACCGGAACCATGGGTCCCTCCATTTCATCTGTCTTCTTTCACAGACGTCCCGGAAGAAATGCAAAAATGGGCAGACGATTATTTTGGAAGGGGTTCCGCTGCGCGGCCAGATAGACCTATTAGTATCATAGTTGAAGGAGACTCGAGAACAGGGAAGACAATGTGGGCACGTGCACTGGGTCCACATAATTATCTCATGGGCCATTTGGATTTCAATTCTCGAGTCTATTCAAATGCAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAGAGAGACTGGCAGTCAAATTGCAAGTACGGCAAGCCAGTTCAAATTAAAGGTGGGATCCCAGCAATCGTGCTTTGCAATCCAGGTGAGGGCTCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACACAGCACTCAGGAACTGGACTATCAAGAATGCGCTCTTCATCACCCTCACATCCGCCCTCTATCAAGATAGCTCACAGGCAAGCAAAGAAGAAGACAATCAGGAGAAGGCGGATTGA |
| Protein Sequence | PKKFRVNSKNYFLTYPQCSITKEEALSQIKNLNTPVNKKFIKICRELHENGEPHLHVLLQFEAKYQCTNSRFFDLVSPSRSAHFHPNIQGAKSSSDVKAYIDKDGDATEWGEFQIDGRSARGGCQSANDTYAKALNASCAEEALQIIKEQQPQHFFLHHHNLVANAQRIFHKPPEPWVPPFHLSSFTDVPEEMQKWADDYFGRGSAARPDRPISIIVEGDSRTGKTMWARALGPHNYLMGHLDFNSRVYSNAVEYNVIDDVAPHYLKLKHWKELLGAQRDWQSNCKYGKPVQIKGGIPAIVLCNPGEGSSYKDFLNKEENTALRNWTIKNALFITLTSALYQDSSQASKEEDNQEKAD |
| NCBI Accession | NP_620893.1 |
|---|---|
| Location | 2213-2470 |
| Gene Name | AC4 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGGGAGCCTCATCTCCATGTGCTTTTGCAGTTCGAAGCCAAATACCAGTGCACGAATAGCAGATTCTTCGACCTGGTCTCCCCATCCCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAGTCGAGCTCCGACGTCAAGGCATACATCGACAAGGACGGAGATGCGACAGAATGGGGGGAATTCCAGATCGACGGTCGATCTGCTAGAGGAGGCTGCCAGTCGGCCAACGATACATATGCAAAGGCATTGA |
| Protein Sequence | MGSLISMCFCSSKPNTSARIADSSTWSPHPGQHISIRTYRELSRAPTSRHTSTRTEMRQNGGNSRSTVDLLEEAASRPTIHMQRH |
| NCBI Accession | NP_620894.1 |
|---|---|
| Location | 528-1295 |
| Gene Name | BV1 |
| Protein Name | putative movement protein |
| Coding Region | ATGTATCCTGTTAGGAATAAACGTGTTTCTTACTTTGCTCCACGTCGTTATTATCCTCGTAACTACGTACAGACCCGTCCAGTTCATGTTAAAAGACATGTTGGGAGACGTGGAGCTCTATTAACTAGGCCCAGTGATGAGCCCAAGATGGTAGCCCAACGCATACATGAAAACCAGTATGGGCCGGAATTTGTGATGGCCCATAATACATCCGTGTCGACGTTCATCACTTACCCTAGTTTGGGGAAGACTGAGCCCAATCGCAGCAGATCATATATTAAGTTGAAACGACTGCGTTTCAAAGGGACTGTGAAGATTGAACGTGTTCAATCGGATATGAACATGGACGGGTCTGCCCGTCAAGTTGAAGGAGTTTTCTCCCTTGTTATTGTTGTGGATCGTAAACCCCACTTAGGTCCATTTGGATGTTTGCATACGTTTGACGAAATTTTCGGTGCAAGGATCCACAGTCATGGTAATCTCAGTGTAATCCCTGATTTGAAAGAACGTTATTACATCCGACATGTGTTCAAGCGTGTGTTGTCTGTGGAAAAAGACACTCTGATGGCCGATGTTGAGGGATCCATCTCACTATCTAACAGGCGTATGAACTGCTGGTCCACGTTCAAGGATGTCGACCGGGATTCATGCAACGGTGTTTATGATAACATGAGCAAGAACGCCCTGTTAGTGTATTATTGTTGGATGTCTGATACTCATTCAAAGGCATCTACTTTTGTATCGTTTGATCTTGACTATGTTGGTTAA |
| Protein Sequence | MYPVRNKRVSYFAPRRYYPRNYVQTRPVHVKRHVGRRGALLTRPSDEPKMVAQRIHENQYGPEFVMAHNTSVSTFITYPSLGKTEPNRSRSYIKLKRLRFKGTVKIERVQSDMNMDGSARQVEGVFSLVIVVDRKPHLGPFGCLHTFDEIFGARIHSHGNLSVIPDLKERYYIRHVFKRVLSVEKDTLMADVEGSISLSNRRMNCWSTFKDVDRDSCNGVYDNMSKNALLVYYCWMSDTHSKASTFVSFDLDYVG |
| NCBI Accession | NP_620895.1 |
|---|---|
| Location | 1354-2241 |
| Gene Name | BC1 |
| Protein Name | putative cell-to-cell movement protein |
| Coding Region | ATGAATTCTCAGTTAGCAAATCCTCCAAGTGCCTTCAATTACATAGAGTCGCACCGGGACGAATATCAGCTTTCTCATGACCCAACTGAGATAGTACTGCAGTTTCCGTCCACGGAGTCACAAATATCAGCTAGATTCAGTCGTAGCTGCATGAAAATAGACCATTGCGTCATAGAGTACAGGCAACAGGTACTTATCACCACCGGTGGGACGGTAATCGTGGAGATTCATGATAAAAGGATGACGGACAATGAGTCATTACAGGCGTCATGGACTTTCCCGATCAGATGCAACATAGATCTCCACTATTTTTCAGCTTCCTTTTTCTCCCTAAAAGACCCCATACCATGGAAACTCTACTATAGAGTTTCCGATTCGAATGTTCATCAGAGAACGCACTTCGCCAAGTTCAAAGGGAAGCTGAAATTGTCCACAGCAAAACACTCAGTGGATATCCTTCCGGGCACCAACAGTGAAGATCCTATCCAAACAGTTCACGGACAAAGATGTGGGACTTTTCAACATGTGGACTATGGAAAATGGGAAAGGAAGCCCATAAGATGCCAGTCCATGTCCAGAGTTGGGTACAGGAGGCCCAATAGAAATCAAAACCCGGGGGAGTCATGGGCTTTCCCAGGAGTAACTATAGGAATAGCCCAGTCGGAGGCGGACTCAGAGGTGGAAAACGAAATCCACCCATACAGACAGCTTAACAGACTGGGCACCAATTTCCTAGACCCAGGAGATTCTGCTTCCATGGTGGGAGCACGGAGAACAGAGTCCAATATCACTATGTCAATGGGCCAATTGAACGAGTTAGTTAGGACAACGGTCCAAGAATGTATTAACAGTAGTTGTCAGCCTTGTCAGGCTAAATCTTTGAAATAA |
| Protein Sequence | MNSQLANPPSAFNYIESHRDEYQLSHDPTEIVLQFPSTESQISARFSRSCMKIDHCVIEYRQQVLITTGGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDSNVHQRTHFAKFKGKLKLSTAKHSVDILPGTNSEDPIQTVHGQRCGTFQHVDYGKWERKPIRCQSMSRVGYRRPNRNQNPGESWAFPGVTIGIAQSEADSEVENEIHPYRQLNRLGTNFLDPGDSASMVGARRTESNITMSMGQLNELVRTTVQECINSSCQPCQAKSLK |
References More References in PubMed
| 1 |
Havana tomato virus, a new bipartite geminivirus infecting tomatoes in Cuba. Martinez Zubiaur Y, et al. Arch Virol. 1998;143(9):1757-72. doi: 10.1007/s007050050414. PMID: 9787659 |
|---|---|
| 2 |
Taino Tomato Mottle Virus, a New Bipartite Geminivirus from Cuba. Ramos PL, et al. Plant Dis. 1997 Sep;81(9):1095. doi: 10.1094/PDIS.1997.81.9.1095C. PMID: 30861977 |
| 3 |
Macroptilium yellow mosaic virus, a New Begomovirus Infecting Macroptilium lathyroides in Cuba. Ramos PL, et al. Plant Dis. 2002 Sep;86(9):1049. doi: 10.1094/PDIS.2002.86.9.1049B. PMID: 30818538 |
| 4 |
A Bipartite Geminivirus Infecting Tomatoes in Cuba. Martinez Y, et al. Plant Dis. 1997 Oct;81(10):1215. doi: 10.1094/PDIS.1997.81.10.1215C. PMID: 30861720 |
| 5 |
First Report of Tomato yellow leaf curl virus Associated with Beans, Phaseolus vulgaris, in Cuba. Martínez Zubiaur Y, et al. Plant Dis. 2002 Jul;86(7):814. doi: 10.1094/PDIS.2002.86.7.814D. PMID: 30818589 |
| 6 |
First Report of Columnea latent viroid (CLVd) in Tomato in Mali. Batuman O, et al. Plant Dis. 2013 May;97(5):692. doi: 10.1094/PDIS-10-12-0920-PDN. PMID: 30722209 |
| 7 |
Domínguez M, et al. Plant Dis. 2002 Sep;86(9):1050. doi: 10.1094/PDIS.2002.86.9.1050A. PMID: 30818540 |
| 8 |
Fuentes A, et al. Biotechnol Appl Biochem. 2004 Jun;39(Pt 3):355-61. doi: 10.1042/BA20030192. PMID: 15154849 |