Tomato leaf curl Uganda virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002824385.1 |
| Isolate | Uganda: Iganga |
| Release date | 2018/8/25 |
| Submitter | Shih,S.L., Green,S.K., Tsai,W.S., Ssekyewa,C. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
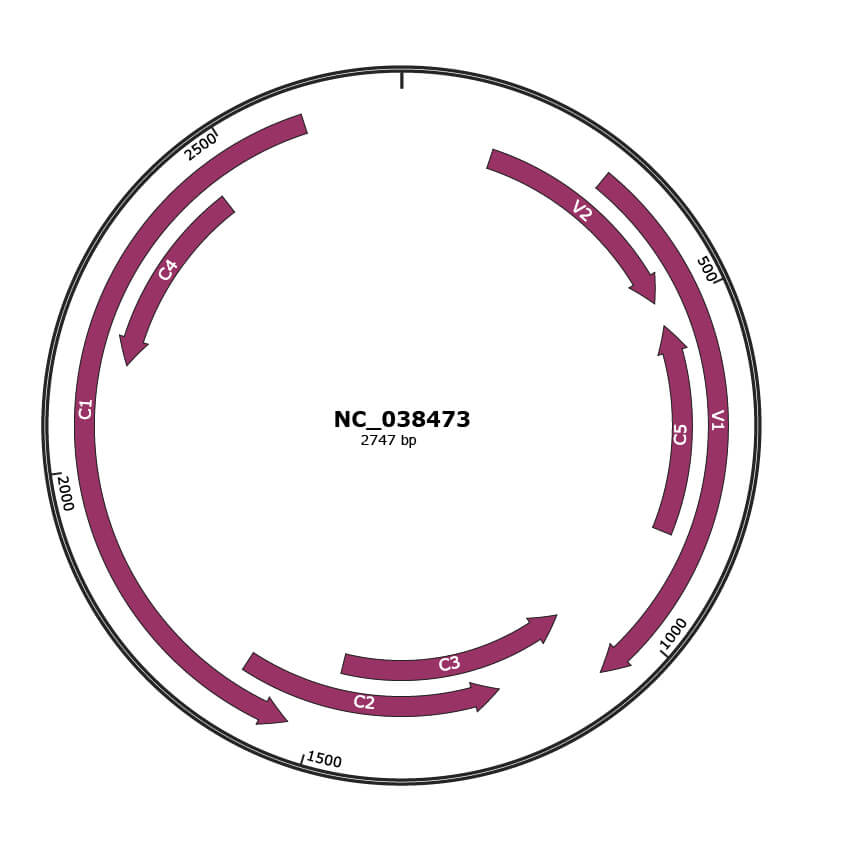
JBrowse
Genome
NC_038473
Gene Information
| NCBI Accession | YP_009506546.1 |
|---|---|
| Location | 141-491 |
| Gene Name | V2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCACTGTTAAATGAGTTTCCAGACTCAGTTCATGGGTTTCGTTGTATGCTTGCAATAAAATATTTGCAGGCTATTGAGTCCACTTACGAGCCCAATACGTTGGGCCACGATTTAATTCGAGATCTCATTTGTGTCGTTAGAGCCCGAGATTATGTCGAAGCGACCCGGAGATATAATAATTTCAACGCCCGCCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCGTACACCAGCCGTGCTGCTGTCCCCACTGCCCCAGGCACAAGCAGACGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPDSVHGFRCMLAIKYLQAIESTYEPNTLGHDLIRDLICVVRARDYVEATRRYNNFNARLEGSSKAELRQPVHQPCCCPHCPRHKQTSIMDLQAHVSKAQDVQNVQKP |
| NCBI Accession | YP_009506547.1 |
|---|---|
| Location | 301-1077 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCCGGAGATATAATAATTTCAACGCCCGCCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCGTACACCAGCCGTGCTGCTGTCCCCACTGCCCCAGGCACAAGCAGACGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCACGGGGTTGTGAAGGCCCATGTAAGGTTCAGTCATACGAGCAGAGAGATGATGTTAAGCATACTGGTGTTGTCCGTTGTGTTAGTGATGTTACTCGTGGATCGGGTATTACACATAGGGTTGGCAAGAGGTTCTGTGTGAAGTCCATTTACATTATAGGGAAGATATGGATGGATGAGAATATCAAGAAGCAGAATCACACTAATCAGGTCATGTTTTTTTTGGTCCGTGATAGAAGGCCCTATGGTACAAGCCCAATGGACTTTGGGCAGGTGTTTAACATGTTTGATAACGAGCCCAGTACAGCTACCGTCAAGAATGATTTGAGAGACAGATACCAAGTTTTGCGGAAATTTCATGCAACTGTTGTAGGTGGACCCTCCGGGATGAAGGAGCACGCGTTAGTTAAGAGATTTTTTAAGGTTAATAATCATGTAGTTTATAATCATCAGGAAGCAGCTAAGTACGAAAACCATACGGAGAATGCGTTGTTGTTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACGTTGAAAATACGTATTTATTTCTATGATTCAGTCGGTAATTAA |
| Protein Sequence | MSKRPGDIIISTPASKVRRRLNFDSPYTSRAAVPTAPGTSRRRSWTYRPMYRKPRMYRMYRSPDVPRGCEGPCKVQSYEQRDDVKHTGVVRCVSDVTRGSGITHRVGKRFCVKSIYIIGKIWMDENIKKQNHTNQVMFFLVRDRRPYGTSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVLRKFHATVVGGPSGMKEHALVKRFFKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVGN |
| NCBI Accession | YP_009506548.1 |
|---|---|
| Location | 529-855 |
| Gene Name | C5 |
| Protein Name | C5 protein |
| Coding Region | ATGAAATTTCCGCAAAACTTGGTATCTGTCTCTCAAATCATTCTTGACGGTAGCTGTACTGGGCTCGTTATCAAACATGTTAAACACCTGCCCAAAGTCCATTGGGCTTGTACCATAGGGCCTTCTATCACGGACCAAAAAAAACATGACCTGATTAGTGTGATTCTGCTTCTTGATATTCTCATCCATCCATATCTTCCCTATAATGTAAATGGACTTCACACAGAACCTCTTGCCAACCCTATGTGTAATACCCGATCCACGAGTAACATCACTAACACAACGGACAACACCAGTATGCTTAACATCATCTCTCTGCTCGTATGA |
| Protein Sequence | MKFPQNLVSVSQIILDGSCTGLVIKHVKHLPKVHWACTIGPSITDQKKHDLISVILLLDILIHPYLPYNVNGLHTEPLANPMCNTRSTSNITNTTDNTSMLNIISLLV |
| NCBI Accession | YP_009506549.1 |
|---|---|
| Location | 1074-1478 |
| Gene Name | C3 |
| Protein Name | replication enhancement protein |
| Coding Region | ATGGATTCACGCACCGGGGAATACATCACTGCTCATCAAGCGATGAGTGGCGTAAATATCTGGGAGATACAAAATCCCCTTTATTTCAAGATCATCGACCACAACATCAGACCATTCAACACCAACCACGACATCATATCGATCCAGATACGGTTCAACCACAACCTGAGGAAGGAATTGGGGATTCACAAGTGTTTTCTCAACTTCAGAGTCTGGACGACATTACGGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAGATATCAAGTTCTTAAATATTTAGATAACCTTGGTGTAATTTCAATTAATACAGTTATTAGAGCAGTTGATCATGTATTGTACGATGTACTTGTAAACACACTCCAAGTTACGGAGGATCATGAAATAAAATTTAATCTTTATTAA |
| Protein Sequence | MDSRTGEYITAHQAMSGVNIWEIQNPLYFKIIDHNIRPFNTNHDIISIQIRFNHNLRKELGIHKCFLNFRVWTTLRPQTGRFLRVFRYQVLKYLDNLGVISINTVIRAVDHVLYDVLVNTLQVTEDHEIKFNLY |
| NCBI Accession | YP_009506550.1 |
|---|---|
| Location | 1219-1626 |
| Gene Name | C2 |
| Protein Name | transcriptional activation protein |
| Coding Region | ATGCGACCTTCGTCACCCTCCACGAGCCATTGTTCACAGGTACCCATCAAGGTCCAACACCGAGTAGCCAAGAAGAAGGTAATCAGACGTAGACGAATAGACCTAAACTGCGGCTGCTCATATTTCCTACACATCGACTGCAACAACCATGGATTCACGCACCGGGGAATACATCACTGCTCATCAAGCGATGAGTGGCGTAAATATCTGGGAGATACAAAATCCCCTTTATTTCAAGATCATCGACCACAACATCAGACCATTCAACACCAACCACGACATCATATCGATCCAGATACGGTTCAACCACAACCTGAGGAAGGAATTGGGGATTCACAAGTGTTTTCTCAACTTCAGAGTCTGGACGACATTACGGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAG |
| Protein Sequence | MRPSSPSTSHCSQVPIKVQHRVAKKKVIRRRRIDLNCGCSYFLHIDCNNHGFTHRGIHHCSSSDEWRKYLGDTKSPLFQDHRPQHQTIQHQPRHHIDPDTVQPQPEEGIGDSQVFSQLQSLDDITASDWSFLKSI |
| NCBI Accession | YP_009506551.1 |
|---|---|
| Location | 1535-2611 |
| Gene Name | C1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGAGAAATCCACGATTTAAAATACAAGCTAAAAACATTTTCCTCACATATCCCAAGTGTTCCTTACCAAAAGAATACCTTCTCTCTTTCATTCAAAACCTTACCCTTGCATCAAATCCTAAATATATCAAAATCTGTAAAGAACTCCATCAGAATGGGGAACCTCATCTGCATGCCCTCATCCAATTCGAGGGTAAAATCACGGTTACGAACAATCGCCTCTTCGATTGTTCACACCCAAGCTGTAGCACCAGTTTCCACCCCAACATACAAGGTGCTAAGTCCAGTTCAGATGTCAATTCCTATCTGGATAAGGACGGAGACACCATCGAATGGGGAGAGTTTCAGATCGATGGACGATCTGCAAGGGGTGGGCAACAGTCAGCCAACGACGCTTACGCAAAGGCACTTAACTCAGGAAGTAAGTCGGAGGCTCTTAGAGTCCTTAGAGAATTAGCCCCAAAAGATTTTGTTTTACAATTTCATAATTTGAATAGCAATTTAGATAGGATTTTTCAGGAGCCTCCAGCTCCTTATGTTTCTCCTTTTCTTTCCTCTTCTTTTAACCAAGTTCCAGAAGAACTTGAATGTTGGGTGTCTGAGAATGTAATGACTTCCGCTGCGCGGCCATGGAGACCGATTAGTATTGTTATCGAGGGTGATAGTCGAACAGGCAAGACAATGTGGGCCAGGTCATTAGGACCACACAATTATTTGTGTGGTCATCTTGATCTAAGCCCAAAGGTGTACAGCAATGATGCGTGGTACAACGTCATTGATGACGTTGATCCGCATTATCTAAAGCACTTTAAAGAATTCATGGGGGCCCAGAGAGACTGGCAAAGCAACACCAAGTACGGGAAGCCCATTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCCTCATATAGAGAATATCTAGACGAGGAAAAAAATGCACCACTGAAAGCCTGGGCAATCAAGAATGCGACCTTCGTCACCCTCCACGAGCCATTGTTCACAGGTACCCATCAAGGTCCAACACCGAGTAGCCAAGAAGAAGGTAATCAGACGTAG |
| Protein Sequence | MRNPRFKIQAKNIFLTYPKCSLPKEYLLSFIQNLTLASNPKYIKICKELHQNGEPHLHALIQFEGKITVTNNRLFDCSHPSCSTSFHPNIQGAKSSSDVNSYLDKDGDTIEWGEFQIDGRSARGGQQSANDAYAKALNSGSKSEALRVLRELAPKDFVLQFHNLNSNLDRIFQEPPAPYVSPFLSSSFNQVPEELECWVSENVMTSAARPWRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYREYLDEEKNAPLKAWAIKNATFVTLHEPLFTGTHQGPTPSSQEEGNQT |
| NCBI Accession | YP_009506552.1 |
|---|---|
| Location | 2155-2457 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCTCATCTGCATGCCCTCATCCAATTCGAGGGTAAAATCACGGTTACGAACAATCGCCTCTTCGATTGTTCACACCCAAGCTGTAGCACCAGTTTCCACCCCAACATACAAGGTGCTAAGTCCAGTTCAGATGTCAATTCCTATCTGGATAAGGACGGAGACACCATCGAATGGGGAGAGTTTCAGATCGATGGACGATCTGCAAGGGGTGGGCAACAGTCAGCCAACGACGCTTACGCAAAGGCACTTAACTCAGGAAGTAAGTCGGAGGCTCTTAGAGTCCTTAGAGAATTAG |
| Protein Sequence | MGNLICMPSSNSRVKSRLRTIASSIVHTQAVAPVSTPTYKVLSPVQMSIPIWIRTETPSNGESFRSMDDLQGVGNSQPTTLTQRHLTQEVSRRLLESLEN |
References More References in PubMed
| 1 |
Molecular Characterization of a Begomovirus Associated with Tomato Leaf Curl Disease in Uganda. Shih SL, et al. Plant Dis. 2006 Feb;90(2):246. doi: 10.1094/PD-90-0246A. PMID: 30786424 |
|---|---|
| 2 |
Relationship between Tomato yellow leaf curl viruses and the whitefly vector. Ssekyewa C, et al. Commun Agric Appl Biol Sci. 2007;72(4):1029-48. PMID: 18396846 |
| 3 |
Ringeera KH, et al. Mol Biol Rep. 2025 Sep 13;52(1):901. doi: 10.1007/s11033-025-11020-1. PMID: 40944776 |
| 4 |
A novel East African monopartite begomovirus-betasatellite complex that infects Vernonia amygdalina. Mollel HG, et al. Arch Virol. 2017 Apr;162(4):1079-1082. doi: 10.1007/s00705-016-3175-2. Epub 2016 Nov 29. PMID: 27900540 |
| 5 |
Commodity risk assessment of Petunia spp. and Calibrachoa spp. unrooted cuttings from Uganda. EFSA Panel on Plant Health (PLH), et al. EFSA J. 2026 Jan 14;24(1):e9849. doi: 10.2903/j.efsa.2026.9849. eCollection 2026 Jan. PMID: 41542351 |
| 6 |
Mwaipopo B, et al. Plant Dis. 2018 Nov;102(11):2361-2370. doi: 10.1094/PDIS-01-18-0198-RE. Epub 2018 Sep 19. PMID: 30252625 |
| 7 |
Kyallo M, et al. Arch Virol. 2017 May;162(5):1393-1396. doi: 10.1007/s00705-016-3217-9. Epub 2017 Jan 9. PMID: 28070648 |