Tomato leaf curl Toliara virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002987065.1 |
| Isolate | Madagascar:Menabe, Miandrivazo |
| Release date | 2018/8/26 |
| Submitter | Lefeuvre,P., Martin,D.P., Hoareau,M., Naze,F., Becker,N., Delatte,H., Reynaud,B., Lett,J.M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
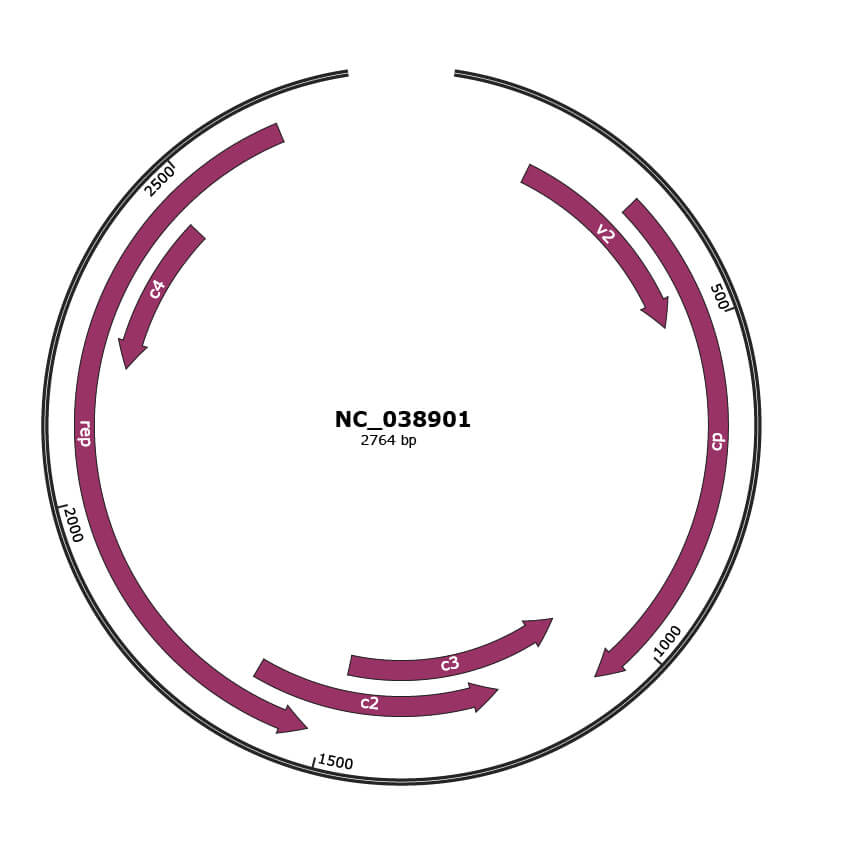
Genomic Organization
JBrowse
Genome
NC_038901
Gene Information
| NCBI Accession | YP_009508206.1 |
|---|---|
| Location | 143-493 |
| Gene Name | v2 |
| Protein Name | V2 protein |
| Coding Region | ATGTGGGATCCACTTCTTAACGATTTTCCAGAAACTGTTCACGGTTTCCGTTGTATGTTAGCTATTAAATATTTGCAGGCTGTAGAGAAACAGTACGAGCCAGGTACGTTAGGGTTCGAGTTAATTCGTGATTTAATTGTCGTTCTCAGGACGAAGAATTATGTCGAAGCGACCTGCCGATATAGTAATTTCCACTCCCGCGTCCAAGGTGCGTCGCCGGTTGAACTTCGACAGCCCATACTTGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAACGGCGAGCATGGGTCAACAGGCCCATGTACCGAAAGCCCAGGATGTACCGGATGTACAAAAATCCTGA |
| Protein Sequence | MWDPLLNDFPETVHGFRCMLAIKYLQAVEKQYEPGTLGFELIRDLIVVLRTKNYVEATCRYSNFHSRVQGASPVELRQPILEPCCCPHCPRHKQTASMGQQAHVPKAQDVPDVQKS |
| NCBI Accession | YP_009508207.1 |
|---|---|
| Location | 303-1079 |
| Gene Name | cp |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCTGCCGATATAGTAATTTCCACTCCCGCGTCCAAGGTGCGTCGCCGGTTGAACTTCGACAGCCCATACTTGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAACGGCGAGCATGGGTCAACAGGCCCATGTACCGAAAGCCCAGGATGTACCGGATGTACAAAAATCCTGATGTCCCTAGGGGCTGTGAAGGCCCGTGTAAGATCCAGTCTTACGAACAACGTGATGACGTGAAGCATGTTGGTGTGGTTAGGTGTATTAGTGATATTACTAAGGGTCCTGGTTTGACCCATAGGACCGGTAAACGTTTTGTTGTTAAGTCTGTTTATATATTAGGTAAAGTTTGGATGGATGAAAACATTAAGAAGCAGAATCACACGAACAATGTGATGTTTTTCCTGGTTAGAGATAGGAGGCCTTATGGCCCGAGTCCAATGGACTTTGGGCAGGTGTTTAATATGTTTGACAATGAGCCCAGCACAGCAACGGTGAAGAACGATTTTAGGGATCGTTTCCAAGTTTTAAGGAAATTCACTGCTACTGTTGTTGGTGGACCTTCTGGTTTGAAGGAACAGGCCTTGGTAAAGCGATTCTTCAGGCTCAACAGCCATGTGACGTATAATCATCAAGAAGCTGCTAAGTATGAGAACCATACGGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCTTCTAATCCAGTGTATGCTACTCTTAAAATACGTGTGTATTTCTACGATTCTGTAACAAATTAA |
| Protein Sequence | MSKRPADIVISTPASKVRRRLNFDSPYLSRAAAPTVLVTNKRRAWVNRPMYRKPRMYRMYKNPDVPRGCEGPCKIQSYEQRDDVKHVGVVRCISDITKGPGLTHRTGKRFVVKSVYILGKVWMDENIKKQNHTNNVMFFLVRDRRPYGPSPMDFGQVFNMFDNEPSTATVKNDFRDRFQVLRKFTATVVGGPSGLKEQALVKRFFRLNSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSVTN |
| NCBI Accession | YP_009508208.1 |
|---|---|
| Location | 1076-1480 |
| Gene Name | c3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCACGCACCGGGGAACTCATCACTGCGCATCAGGCACAGAGTGGCGTCTATACCTGGGAAATCGCCAATCCCCTATATTTCAGCATCACGGAACACTCGAAGAGACCATTCAACTACAACCACGACATAATCACAGTACAACTCCGATTCAACCACAACCTAAGGAAGGAACTGGGGATTCACAAATGTTTCATGACCTTCAAGATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGAGTCTTTAAGACTCAAGTTAGTAAATATTTAAACAATCTTGGTGTAATTTCAATTAATAATGTAATTAGAGCAATAGATTATGTATTGTTTGATGTAATCAACGAAACCTTATGGGTGGAACAAAATTATGATATAAAATATAAACTTTATTAA |
| Protein Sequence | MDSRTGELITAHQAQSGVYTWEIANPLYFSITEHSKRPFNYNHDIITVQLRFNHNLRKELGIHKCFMTFKIWTTLQPQTGHFLRVFKTQVSKYLNNLGVISINNVIRAIDYVLFDVINETLWVEQNYDIKYKLY |
| NCBI Accession | YP_009508209.1 |
|---|---|
| Location | 1221-1628 |
| Gene Name | c2 |
| Protein Name | C2 protein |
| Coding Region | ATGCGATCTTCGTCACCATCCAACAGCCATTGTACTCAAGTTCCTATCAAGGTCCAACACAGAGCAGCCAAGCAGAGGCTTCAGAGGAGGAAGAGGATAGACCTTAATTGCGGGTGCTCGTACTACTTGTCACTCAACTGTCGCAACAATGGATTCACGCACCGGGGAACTCATCACTGCGCATCAGGCACAGAGTGGCGTCTATACCTGGGAAATCGCCAATCCCCTATATTTCAGCATCACGGAACACTCGAAGAGACCATTCAACTACAACCACGACATAATCACAGTACAACTCCGATTCAACCACAACCTAAGGAAGGAACTGGGGATTCACAAATGTTTCATGACCTTCAAGATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGAGTCTTTAA |
| Protein Sequence | MRSSSPSNSHCTQVPIKVQHRAAKQRLQRRKRIDLNCGCSYYLSLNCRNNGFTHRGTHHCASGTEWRLYLGNRQSPIFQHHGTLEETIQLQPRHNHSTTPIQPQPKEGTGDSQMFHDLQDLDDLTASDWSFLKSL |
| NCBI Accession | YP_009508210.1 |
|---|---|
| Location | 1522-2652 |
| Gene Name | rep |
| Protein Name | replication associated protein |
| Coding Region | ATGCAAATGAGAAGTCAATTGGAGACACTTGACCAAATGGCTCGGCCACGTCGTTTTAAAATACAAGCCAAAAATTATTTCCTTACTTATCCCAAATGCAATTTAACTAAAGAAGAAGCACTTTCCCAATTATTAAATATAGATACTCCAACAAATAAAAGATTCATCAAAATCTGCAGAGAGTTGCACGAAGATGGGGAGCCTCATCTCCACATGCTCATCCAGTTCGAGGGCAAATTCCACTGCACGAATAACCGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGACACACTTGAATGGGGTGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGAATGCTAACGACGCATGCGCCGAGGCATTAAACGCAGGTTCCGCTGAAGCCGCTATGGCTATTATTAAAGAGAAACTCCCTAAAGATTTTATTTTTCAGTATCATAATTTAAAATGTAATTTAGATAGGATTTTTACACCTCCGTTGGAGGATTATGTTTCTCCTTTTTTATGTTCTTCTTTCGATCAAGTTCCGGAAGAACTTGAAGAGTGGGCGGCGGAGAATGTTGTCAGTGCCGCTGCGCGGCCATTGAGACCCATAAGTATTGTGATTGAAGGGGATAGTCGTACCGGGAAGACAATGTGGGCTAGGTCATTGGGTCCACACAATTATTTGTGTGGTCATCTTGATCTTAGTCCAAAGGTGTATTCAAATGAAGCATGGTACAACGTAATAGATGACGTCGATCCTCATTATCTAAAGCACTTTAAGGAATTCATGGGCGCACAACGGGACTGGCAAAGCAACACAAAGTACGGGAAACCAATTCAAATTAAAGGAGGTATCCCGACAATCTTCCTCTGCAATCCAGGACCCACTTCATCATATAAAGAGTACTTGGACGAGCAAAAGAACGCACCACTAAAGGCCTGGGCAATTAAGAATGCGATCTTCGTCACCATCCAACAGCCATTGTACTCAAGTTCCTATCAAGGTCCAACACAGAGCAGCCAAGCAGAGGCTTCAGAGGAGGAAGAGGATAGACCTTAA |
| Protein Sequence | MQMRSQLETLDQMARPRRFKIQAKNYFLTYPKCNLTKEEALSQLLNIDTPTNKRFIKICRELHEDGEPHLHMLIQFEGKFHCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQNANDACAEALNAGSAEAAMAIIKEKLPKDFIFQYHNLKCNLDRIFTPPLEDYVSPFLCSSFDQVPEELEEWAAENVVSAAARPLRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEQKNAPLKAWAIKNAIFVTIQQPLYSSSYQGPTQSSQAEASEEEEDRP |
| NCBI Accession | YP_009508211.1 |
|---|---|
| Location | 2202-2459 |
| Gene Name | c4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAGCCTCATCTCCACATGCTCATCCAGTTCGAGGGCAAATTCCACTGCACGAATAACCGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGACACACTTGAATGGGGTGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGAATGCTAACGACGCATGCGCCGAGGCATTAA |
| Protein Sequence | MGSLISTCSSSSRANSTARITDSSTWYPQPGQHISIQTFRELNQAPTSSPTSTRMETHLNGVNSRSTAEVLEEAARMLTTHAPRH |
References More References in PubMed
| 1 |
Tomato Yellow Leaf Curl Virus: Impact, Challenges, and Management. Prasad A, et al. Trends Plant Sci. 2020 Sep;25(9):897-911. doi: 10.1016/j.tplants.2020.03.015. Epub 2020 May 1. PMID: 32371058 |
|---|---|
| 2 |
Tomato yellow leaf curl virus: Characteristics, influence, and regulation mechanism. Cao X, et al. Plant Physiol Biochem. 2024 Aug;213:108812. doi: 10.1016/j.plaphy.2024.108812. Epub 2024 Jun 8. PMID: 38875781 |
| 3 |
Tomato Yellow Leaf Curl Virus (TYLCV) Promotes Plant Tolerance to Drought. Shteinberg M, et al. Cells. 2021 Oct 25;10(11):2875. doi: 10.3390/cells10112875. PMID: 34831098 |
| 4 |
Tomato Yellow Leaf Curl Sardinia Virus Increases Drought Tolerance of Tomato. Sacco Botto C, et al. Int J Mol Sci. 2023 Feb 2;24(3):2893. doi: 10.3390/ijms24032893. PMID: 36769211 |
| 5 |
Tomato leaf curl Kunene virus: a novel tomato-infecting monopartite begomovirus from Namibia. Lett JM, et al. Arch Virol. 2020 Aug;165(8):1887-1889. doi: 10.1007/s00705-020-04666-8. Epub 2020 May 23. PMID: 32447622 |
| 6 |
Xie Y, et al. Virology. 2024 Jun;594:110040. doi: 10.1016/j.virol.2024.110040. Epub 2024 Mar 5. PMID: 38471198 |
| 7 |
Detection of Tomato Leaf Curl New Delhi Virus-ES by Real-Time Quantitative PCR. Janssen D, et al. Methods Mol Biol. 2025;2912:145-156. doi: 10.1007/978-1-0716-4454-6_12. PMID: 40064778 |
| 8 |
Tomato Leaf Curl New Delhi Virus: An Emerging Virus Complex Threatening Vegetable and Fiber Crops. Moriones E, et al. Viruses. 2017 Sep 21;9(10):264. doi: 10.3390/v9100264. PMID: 28934148 |
| 9 |
Leclair P, et al. Arch Virol. 2025 Jul 5;170(8):173. doi: 10.1007/s00705-025-06345-y. PMID: 40616602 |
| 10 |
Akbar A, et al. Virol J. 2024 Nov 27;21(1):308. doi: 10.1186/s12985-024-02540-6. PMID: 39605076 |