Tomato leaf curl Sudan virus
Basic Information
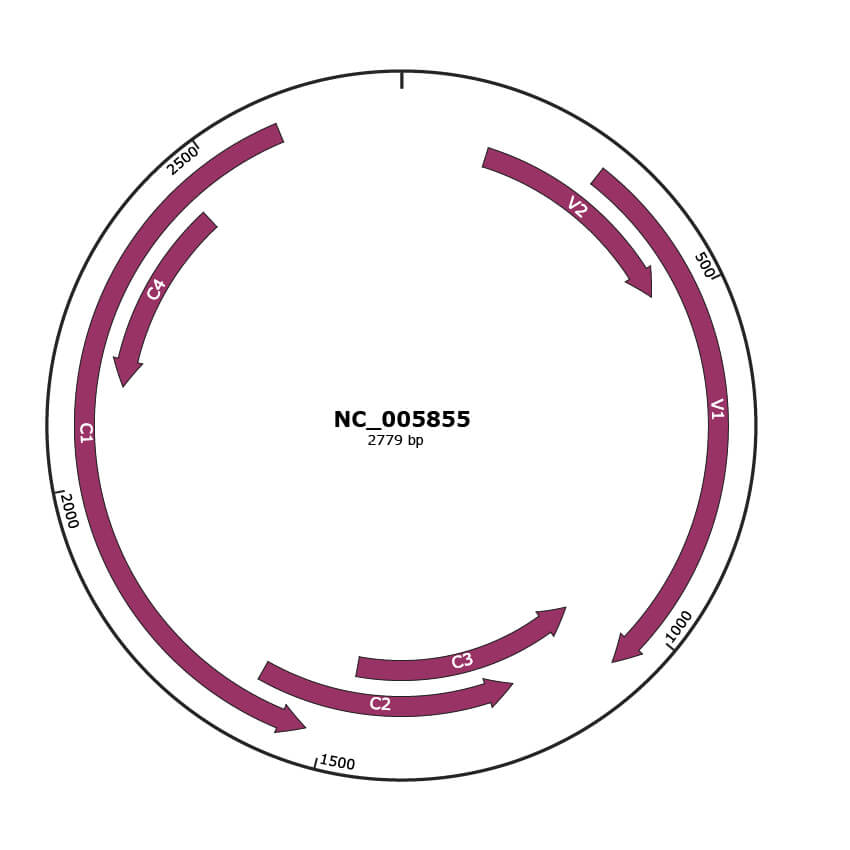
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGCCCCTCTTTTTAGTGGGTCCCACTCACGTCGCTATCAACCAATCAAAATGCATCCTCAAACGTTAGATAAGTGTTCATTTGTCCTTATATACTTGGTCCCCAAGTTGTTTGTCAAGCAATATGTGGGATCCACTTCTAAATGAATTTCCTGAATCTGTTCATGGATTTCGTTGTATGTTAGCTATTAAATATTTGCAGGCCGTTGAGGAAACTTACGAGCCCAATACATTGGGCCACGATTTAATTAGGGATCTTATATCTGTTGTAAGGGCCCGTGATTATGTCGAAGCGACCCGGCGATATAGTCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGACGATCATGGACGTACAGGCCCATGTATCGAAAGCCCAGAATATACAGAATGTATCGAAGTCCTGATGTTCCCCGTGGATGTGAAGGCCCATGTAAGGTCCAATCGTTTGACAAGCGCCATGATTTGAAGCATACGGGTGAGGTATTGTGTGTTTCAGATGTAACACGTGGTAATGGCCTTACTCATCGTGTTGGGAAACGTTTTTGTATCAAGTCTATTTACATTGTTGGCAAAGTGTGGATGGATGAGAACATTAAGGTGAAGAATCATACTAACACTTGTATGTTCTGGCTTGTTCGGGATCGTCGTCCAGTTACTACTCCCTATGGATTTGGAGAATTGTTTAACATGTATGATAATGAGCCATCTACTGCCACTATTAAGAATGATCTGCGGGATCGTTGTCAGGTTCTTAAGAGGTTCACTGCTAGTTTGAGTGGTGGTCAATATGCGTCCAAAGAGCAATGTGTCATTAGGCGATTTTATAAGATTTATAACCATATTGTTTATAATCATCAAGAGCAGGGGAAATATGAGAATCATACTGAGAACGCTCTTTTACTGTATATGGCATGTACTCATGCTTCTAATCCAGTGTACGCTACTCTTAAAATAAGGGTGTACTTCTACGATTCAATATCGAATTAATAAAATTTATATTTTATATCGTGAATCTCGGTTACATTTATTGTGTTTTCAAGTACATTATACAATACATGATCAACTGCTCTAATTACATTGTTAATGGAAATTACACCAATATTATTTAAATATCTAAGAACTTGATATCTAAATACTCTTAAGAAACGACCAGTCTGAGGCCGTAAGGTCGTCCAGATTCGGAAGTTGAGAAAACATTTGTGAATCCCCAGTACCTTCCTGATATTGTGGCTGAATCTTATCTGCATGGAAATGATGTCGTGGTTCATTAGAAATGGCCTCTCGTTGTGTTCTGTTATCTTGAAATATAGGGGATTGTTTATCTCCCAGATAAAAACGCCATTCTCTGCTTGATGAGCAGTGATGAGTTCCCCTGTGCGTGAATCCATAGTTGATGCAGTTGATGTGGAGGTAGTATGAGCAGCCACAATCTAGGTCTACACGCTTACGCCTGATTGGTTGTTTCTTGGCTATTTTGTGTTGGTCCTTGATTGGTACTGGAGAACAGTGGCTCGTAGAGGGTGACGAAGGTTGCATTCTTGAGAGCCCAATTTTTCAAGGAAATATTTTTTTCTTCGTCTAGATATTCCTTATATGAGGAGGTAGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCCCCTTTAATTTGAATGGGCTTCCCATACTTTGTGTTGCTTTGCCAGTCCCTCTGGGCCCCCATGAATTCCTTGAAGTGCTTTAAATAATGCGGGTCTACGTCATCAATGACGTTGTACCACGCATCATTACTGTACACCTTTGGACTTAGGTCTAGATGTCCACATAAATAGTTATGTGGGCCTAGAGACCTAGCCCACATTGTTTTGCCTGTTCTGCTATCACCCTCGATGATAATACTGTTAGGTCTCCATGGCCGCGCAGCGGAAGACATGACGTTCTCGGACACCCATACTTCAAGTTCCTCTGGAACTTGATTAAAAGAAGAAGATAAAAAAGGAGAGATATAAGGAGCCGGAGGCTCCTGAAAAATTCTATCTAAATTAGAATTTAAATTATGAAACTGTAAAATATAATCTTTCGGTGCTAATTCTTTAATGATTCTAAGAGCCTCTGACTTACTGCCTGCGTTAAGTGCTGCTGCGTAAGCGTCATTGGCTGATTGTTGTCCTCCTCTTGCAGATCTTCCATCGATCTGAAACTCACCCCAATCGATGGTGTCTCCGTCTTTATCGATGTAGGACTTGACATCAGATGAGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGTTGATCTACTTGGGGATGCCAGGTCGAAGAATCTGTTATTCGTGCACTGGTACTTGCCTTCGAACTGAACAAGGGCATGCAGATGAGGTTCCCCATTCTCGTGGAGCTCTCTGCAAATTTTAATGTATAATTTATTTACAGGAGTTTCGAGGGTTTGTAGTTGGGAAAGTGCTTCGGATAAAGAAAGAGAACACTGGGGATAAGTAAGGAAATAATTTTTGGCATTTATTTTAAAACGCTTTGGGGGAGCCATTTGGTCAATGTACCCCGATTGACTTGGATTTCATTTATCCCTGCAATCGGTGTAGTGGGGTACAATATATACTTGTACCCCAAATGGCAAATTGGTAATTTAGTAAAAGTATATTGCAATTCAAATTTCAAAATTCAAAAATCAAATCACTAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_006465.1
|
|
Location
|
135-485 |
|
Gene Name
|
V2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTGGGATCCACTTCTAAATGAATTTCCTGAATCTGTTCATGGATTTCGTTGTATGTTAGCTATTAAATATTTGCAGGCCGTTGAGGAAACTTACGAGCCCAATACATTGGGCCACGATTTAATTAGGGATCTTATATCTGTTGTAAGGGCCCGTGATTATGTCGAAGCGACCCGGCGATATAGTCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGACGATCATGGACGTACAGGCCCATGTATCGAAAGCCCAGAATATACAGAATGTATCGAAGTCCTGA |
|
Protein Sequence
|
MWDPLLNEFPESVHGFRCMLAIKYLQAVEETYEPNTLGHDLIRDLISVVRARDYVEATRRYSHFHARLEGSPKAELRQPIQQPCCCPHCPRHKQATIMDVQAHVSKAQNIQNVSKS |
|
NCBI Accession
|
YP_006466.1
|
|
Location
|
295-1068 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCCGGCGATATAGTCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGACGATCATGGACGTACAGGCCCATGTATCGAAAGCCCAGAATATACAGAATGTATCGAAGTCCTGATGTTCCCCGTGGATGTGAAGGCCCATGTAAGGTCCAATCGTTTGACAAGCGCCATGATTTGAAGCATACGGGTGAGGTATTGTGTGTTTCAGATGTAACACGTGGTAATGGCCTTACTCATCGTGTTGGGAAACGTTTTTGTATCAAGTCTATTTACATTGTTGGCAAAGTGTGGATGGATGAGAACATTAAGGTGAAGAATCATACTAACACTTGTATGTTCTGGCTTGTTCGGGATCGTCGTCCAGTTACTACTCCCTATGGATTTGGAGAATTGTTTAACATGTATGATAATGAGCCATCTACTGCCACTATTAAGAATGATCTGCGGGATCGTTGTCAGGTTCTTAAGAGGTTCACTGCTAGTTTGAGTGGTGGTCAATATGCGTCCAAAGAGCAATGTGTCATTAGGCGATTTTATAAGATTTATAACCATATTGTTTATAATCATCAAGAGCAGGGGAAATATGAGAATCATACTGAGAACGCTCTTTTACTGTATATGGCATGTACTCATGCTTCTAATCCAGTGTACGCTACTCTTAAAATAAGGGTGTACTTCTACGATTCAATATCGAATTAA |
|
Protein Sequence
|
MSKRPGDIVISTPVSKVRRRLNFDSPYSSRAAVPIVQGTNKRRSWTYRPMYRKPRIYRMYRSPDVPRGCEGPCKVQSFDKRHDLKHTGEVLCVSDVTRGNGLTHRVGKRFCIKSIYIVGKVWMDENIKVKNHTNTCMFWLVRDRRPVTTPYGFGELFNMYDNEPSTATIKNDLRDRCQVLKRFTASLSGGQYASKEQCVIRRFYKIYNHIVYNHQEQGKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSISN |
|
NCBI Accession
|
YP_006467.1
|
|
Location
|
1065-1469 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCTCATCAAGCAGAGAATGGCGTTTTTATCTGGGAGATAAACAATCCCCTATATTTCAAGATAACAGAACACAACGAGAGGCCATTTCTAATGAACCACGACATCATTTCCATGCAGATAAGATTCAGCCACAATATCAGGAAGGTACTGGGGATTCACAAATGTTTTCTCAACTTCCGAATCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAGATATCAAGTTCTTAGATATTTAAATAATATTGGTGTAATTTCCATTAACAATGTAATTAGAGCAGTTGATCATGTATTGTATAATGTACTTGAAAACACAATAAATGTAACCGAGATTCACGATATAAAATATAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQAENGVFIWEINNPLYFKITEHNERPFLMNHDIISMQIRFSHNIRKVLGIHKCFLNFRIWTTLRPQTGRFLRVFRYQVLRYLNNIGVISINNVIRAVDHVLYNVLENTINVTEIHDIKYKFY |
|
NCBI Accession
|
YP_006468.1
|
|
Location
|
1210-1617 |
|
Gene Name
|
C2 |
|
Protein Name
|
transactivation protein |
|
Coding Region
|
ATGCAACCTTCGTCACCCTCTACGAGCCACTGTTCTCCAGTACCAATCAAGGACCAACACAAAATAGCCAAGAAACAACCAATCAGGCGTAAGCGTGTAGACCTAGATTGTGGCTGCTCATACTACCTCCACATCAACTGCATCAACTATGGATTCACGCACAGGGGAACTCATCACTGCTCATCAAGCAGAGAATGGCGTTTTTATCTGGGAGATAAACAATCCCCTATATTTCAAGATAACAGAACACAACGAGAGGCCATTTCTAATGAACCACGACATCATTTCCATGCAGATAAGATTCAGCCACAATATCAGGAAGGTACTGGGGATTCACAAATGTTTTCTCAACTTCCGAATCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MQPSSPSTSHCSPVPIKDQHKIAKKQPIRRKRVDLDCGCSYYLHINCINYGFTHRGTHHCSSSREWRFYLGDKQSPIFQDNRTQREAISNEPRHHFHADKIQPQYQEGTGDSQMFSQLPNLDDLTASDWSFLKSI |
|
NCBI Accession
|
YP_006469.1
|
|
Location
|
1526-2605 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGCTCCCCCAAAGCGTTTTAAAATAAATGCCAAAAATTATTTCCTTACTTATCCCCAGTGTTCTCTTTCTTTATCCGAAGCACTTTCCCAACTACAAACCCTCGAAACTCCTGTAAATAAATTATACATTAAAATTTGCAGAGAGCTCCACGAGAATGGGGAACCTCATCTGCATGCCCTTGTTCAGTTCGAAGGCAAGTACCAGTGCACGAATAACAGATTCTTCGACCTGGCATCCCCAAGTAGATCAACACATTTCCATCCAAACATTCAGGGAGCTAAATCCTCATCTGATGTCAAGTCCTACATCGATAAAGACGGAGACACCATCGATTGGGGTGAGTTTCAGATCGATGGAAGATCTGCAAGAGGAGGACAACAATCAGCCAATGACGCTTACGCAGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAATCATTAAAGAATTAGCACCGAAAGATTATATTTTACAGTTTCATAATTTAAATTCTAATTTAGATAGAATTTTTCAGGAGCCTCCGGCTCCTTATATCTCTCCTTTTTTATCTTCTTCTTTTAATCAAGTTCCAGAGGAACTTGAAGTATGGGTGTCCGAGAACGTCATGTCTTCCGCTGCGCGGCCATGGAGACCTAACAGTATTATCATCGAGGGTGATAGCAGAACAGGCAAAACAATGTGGGCTAGGTCTCTAGGCCCACATAACTATTTATGTGGACATCTAGACCTAAGTCCAAAGGTGTACAGTAATGATGCGTGGTACAACGTCATTGATGACGTAGACCCGCATTATTTAAAGCACTTCAAGGAATTCATGGGGGCCCAGAGGGACTGGCAAAGCAACACAAAGTATGGGAAGCCCATTCAAATTAAAGGGGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCTACCTCCTCATATAAGGAATATCTAGACGAAGAAAAAAATATTTCCTTGAAAAATTGGGCTCTCAAGAATGCAACCTTCGTCACCCTCTACGAGCCACTGTTCTCCAGTACCAATCAAGGACCAACACAAAATAGCCAAGAAACAACCAATCAGGCGTAA |
|
Protein Sequence
|
MAPPKRFKINAKNYFLTYPQCSLSLSEALSQLQTLETPVNKLYIKICRELHENGEPHLHALVQFEGKYQCTNNRFFDLASPSRSTHFHPNIQGAKSSSDVKSYIDKDGDTIDWGEFQIDGRSARGGQQSANDAYAAALNAGSKSEALRIIKELAPKDYILQFHNLNSNLDRIFQEPPAPYISPFLSSSFNQVPEELEVWVSENVMSSAARPWRPNSIIIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKNISLKNWALKNATFVTLYEPLFSSTNQGPTQNSQETTNQA |
|
NCBI Accession
|
YP_006470.1
|
|
Location
|
2146-2448 |
|
Gene Name
|
C4 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGGGAACCTCATCTGCATGCCCTTGTTCAGTTCGAAGGCAAGTACCAGTGCACGAATAACAGATTCTTCGACCTGGCATCCCCAAGTAGATCAACACATTTCCATCCAAACATTCAGGGAGCTAAATCCTCATCTGATGTCAAGTCCTACATCGATAAAGACGGAGACACCATCGATTGGGGTGAGTTTCAGATCGATGGAAGATCTGCAAGAGGAGGACAACAATCAGCCAATGACGCTTACGCAGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAATCATTAAAGAATTAG |
|
Protein Sequence
|
MGNLICMPLFSSKASTSARITDSSTWHPQVDQHISIQTFRELNPHLMSSPTSIKTETPSIGVSFRSMEDLQEEDNNQPMTLTQQHLTQAVSQRLLESLKN |