Tomato leaf curl Palampur virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000875365.1 |
| Isolate | India:Himachal Pradesh |
| Release date | 2015/2/13 |
| Submitter | Kumar,Y., Hallan,V., Zaidi,A.A. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
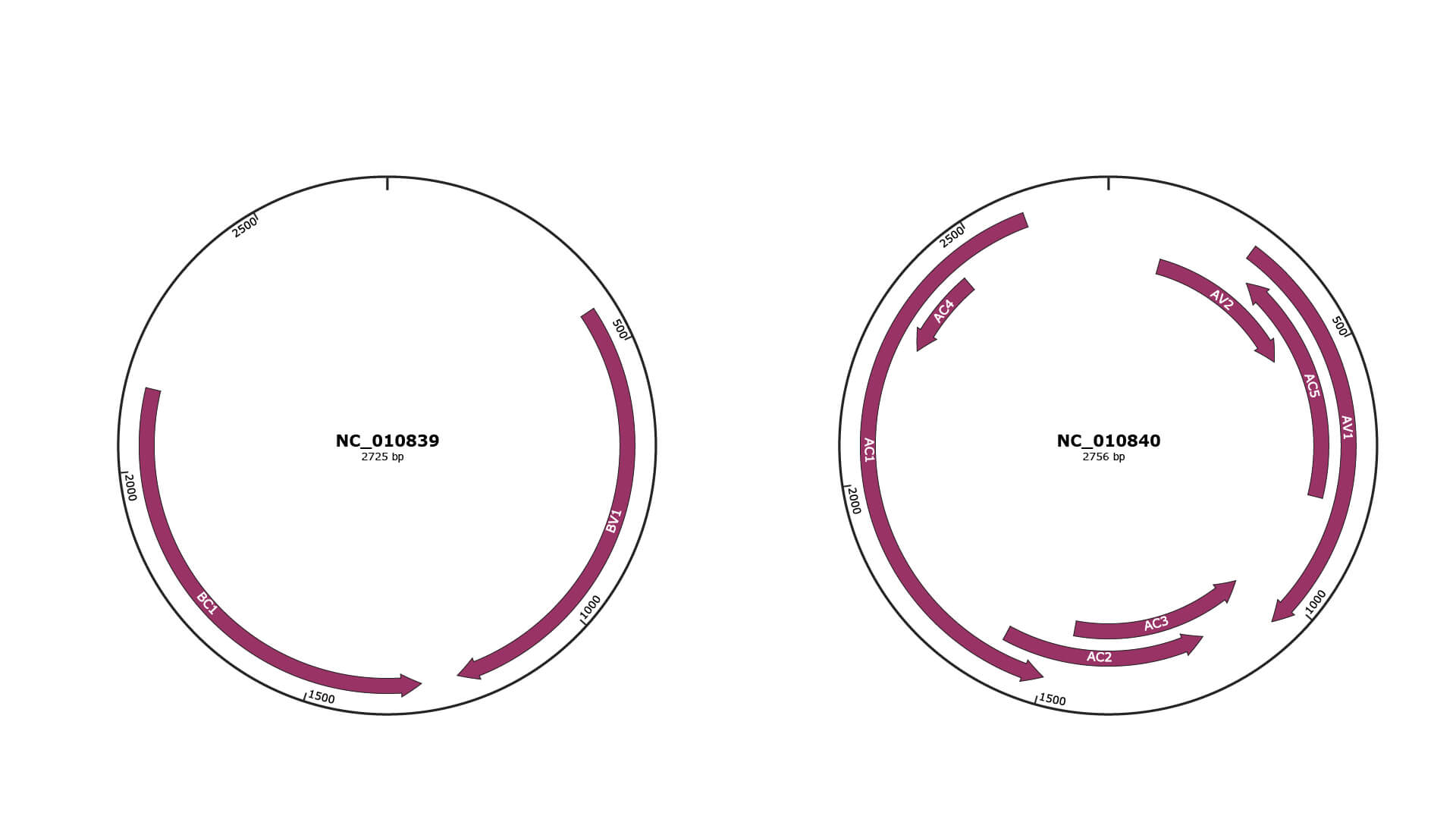
Genomic Organization
JBrowse
Genome
NC_010839
NC_010840
Gene Information
| NCBI Accession | YP_001960966.1 |
|---|---|
| Location | 428-1234 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGGCTTTTCCTTCTCCTTATACCACCCCTCGTCGGTTAGGTTCATCCTATCCGAGACGGTACAACGGAACCAGAAGCGTGAGATTCTGGAAATTCCGTAAATCTCAGCCATGGTTACGTCATCGTCCAAGTGCATCGTCTTCCAGATCTGCTACTGAACTGTTTGGAGAGCCCATCTCCAAACAATATACGCGTAAGGAAATATGTGAAACTCAACAGGGGTCGGAATATGTTTTGCAGAACAATCGATATATGACCTCTTACGTTACATATCCATCTAAAACTAGAACGGGAACGAACAACCGAGTTCGTTCGTACATCAAGTTAAAAAGTCTGAACTTATCTGGAACTTTTGCCATTCGCAGTACTGAAATGATGCAGGACGTCGACCAGAGTGGTGGTTTATATGGTGTGATGTCAGTAGTTGTCGTCAGGGATAAATCGCCTAAGATTTATTCTACTGCCCAACCATTAATCCCGTTTCTAGATATATTCGGATCGGTAAACGCTTGCAGGGGAACATTGAAGGTGGCGGAACGCCACCGCGATAGATTTGTAGTTTTGAATCAGTCTTCAATAATTGTTAATACTCCACATACTAACACTATGAAAAAATTCTGCATTCGCAATTGCATCCCAAAAACCTATACTACTTGGGTCACGTTCCGCGACGAAGAAGAGGACAATTGCACTGGACTGTACTCTAACACACTGCGAAATGCTATACTTATTTATTATGTATGGTTAAGCGATGTACCCTCTCAAGTCGATTTGTATAGTAATGTAATTCTTAATTATATTGGCTGA |
| Protein Sequence | MAFPSPYTTPRRLGSSYPRRYNGTRSVRFWKFRKSQPWLRHRPSASSSRSATELFGEPISKQYTRKEICETQQGSEYVLQNNRYMTSYVTYPSKTRTGTNNRVRSYIKLKSLNLSGTFAIRSTEMMQDVDQSGGLYGVMSVVVVRDKSPKIYSTAQPLIPFLDIFGSVNACRGTLKVAERHRDRFVVLNQSSIIVNTPHTNTMKKFCIRNCIPKTYTTWVTFRDEEEDNCTGLYSNTLRNAILIYYVWLSDVPSQVDLYSNVILNYIG |
| NCBI Accession | YP_001960967.1 |
|---|---|
| Location | 1301-2146 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGTCAATAAGAAATGATAGGGAGGGTTTGTCCGTGGGAGGATACGTTCAGTCTGAACGCGTTGAGTACGCGCTCACAAACGATGCTGCAGAGGTTAAATTAACGTTTCCGTCGATGTTCGAGCAGAAAATAAGCCAATTACGAAACAGATGCATGAAAATTGATCACATCGTACTAGAATACCGCAGTCAGGTACCCATTAATGCAGTTGGACATGTCGTGATTGAAATACACGACATGAGGTTAACGGAAGGGGACACGAAACAGGCTGAGTTTAATATTCCCATCAAATGCAATTGTAACCTGCACTACTACTCTTCTTCGTTCTTCTCTCTCAAGGATTTAAATCCTTGGCGAGTTGAATATAGGGTGGAGAACACAAACGTCGTAGATGGAGTTCACTTCTGCAGGATTTTGGGTAAATTGAAGCTATCGTCGGCAAAACATTCGACTGACGTCGAATTCCGACCACCGAAAATTGAAATACATAGCAAGGAATTCACATTAAACGACATTGATTTCTGGTCTGTGGGTTCGAAACCACAGACAAGACGTTTGGTGGATGGTTCACGATTAATCGGACACAGTTCTAGATCGTTAAGGGTACCATATCTGACGATAGGTCCGAACGAGTCATGGGCTAGCAGATCAGAGATCGGACATTCGTCCGTCACCAGCAGACCTTACAAGAACTTAAGCGGACTGGACGATTCCGCAATCGATCCTGGTCCTTCGGCGTCACAAGCAGGAAGTATTACGAGAGAAGAAATTGCAGATATAATTTCAAAAACAGTAGAACAATGTATAAAATCCAATGTAAATGCTCCACTTTCAAAGGGCGTCTAA |
| Protein Sequence | MSIRNDREGLSVGGYVQSERVEYALTNDAAEVKLTFPSMFEQKISQLRNRCMKIDHIVLEYRSQVPINAVGHVVIEIHDMRLTEGDTKQAEFNIPIKCNCNLHYYSSSFFSLKDLNPWRVEYRVENTNVVDGVHFCRILGKLKLSSAKHSTDVEFRPPKIEIHSKEFTLNDIDFWSVGSKPQTRRLVDGSRLIGHSSRSLRVPYLTIGPNESWASRSEIGHSSVTSRPYKNLSGLDDSAIDPGPSASQAGSITREEIADIISKTVEQCIKSNVNAPLSKGV |
| NCBI Accession | YP_001960968.1 |
|---|---|
| Location | 120-485 |
| Gene Name | AV2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCATTATTGCACGAATTTCCTGAAAGCGTTCATGGTCTTAGGTGCATGCTAGCTGTAAAATATCTCAAAGAGATAGAAAAGACCTACTCTCCGGACACAATCGGATACGATCTTGTTCGTGACCTAATCTCTGTCGTCCGTGCCAGAAACTATGGTGAAGCGTCCAGCAGATATCTACATTTCAACGCCCGCATCGAAAGCACGCCGTCGTCTGAACTTCGACAGCCCGTATGCTGTCCGTGCAGCTGTCCCTATTGTCCGCGCCACAAAGGCAAGGGAATGGGTGAACAGACCCATGAACCGGAAACCAAGATTTTACCGGATGTATCGAAGCTCGGACGTGCCCAGGGGCTGTGA |
| Protein Sequence | MWDPLLHEFPESVHGLRCMLAVKYLKEIEKTYSPDTIGYDLVRDLISVVRARNYGEASSRYLHFNARIESTPSSELRQPVCCPCSCPYCPRHKGKGMGEQTHEPETKILPDVSKLGRAQGL |
| NCBI Accession | YP_001960969.1 |
|---|---|
| Location | 280-1050 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGGTGAAGCGTCCAGCAGATATCTACATTTCAACGCCCGCATCGAAAGCACGCCGTCGTCTGAACTTCGACAGCCCGTATGCTGTCCGTGCAGCTGTCCCTATTGTCCGCGCCACAAAGGCAAGGGAATGGGTGAACAGACCCATGAACCGGAAACCAAGATTTTACCGGATGTATCGAAGCTCGGACGTGCCCAGGGGCTGTGAAGGCCCATGTAAGGTGCAATCTTTTGAATCCAGGCACGATGTCTCCCATATTGGTAAGGTGATGTGTATTAGCGACGTTACCCGTGGAACCGGTCTCACACATCGCGTCGGAAAGCGATTCTGTGTGAAGTCCGTCTACGTGCTTGGCAAGATCTGGATGGACGAGAATATCAAGACCAAGAACCACACGAATAGTGTGATGTTTTTCTTGGTGCGTGATCGTCGACCTACGGGTGCGCCACAAGATTTCGGCGAAGTTTTTAATATGTTCGACAACGAACCTAGCACTGCCACTGTTAAGAATATGCATCGTGATCGATATCAAGTGCTCAAAAAATGGCATTCGACTGTGACGGGAGGAACATACGCGTCGAAGGAACAAGCATTAGTTAAACGTTTTATTAGAGTTAATAATTACGTTGTATATAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAATGCATTAATGTTGTATATGGCCTGTACTCATCCATCAAATCCTGTATATGCGACTTTAAAAATCCGGATCTATTTTTATGATTCGGTAACAAATTAA |
| Protein Sequence | MVKRPADIYISTPASKARRRLNFDSPYAVRAAVPIVRATKAREWVNRPMNRKPRFYRMYRSSDVPRGCEGPCKVQSFESRHDVSHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPTGAPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLKKWHSTVTGGTYASKEQALVKRFIRVNNYVVYNQQEAGKYENHTENALMLYMACTHPSNPVYATLKIRIYFYDSVTN |
| NCBI Accession | YP_001960970.1 |
|---|---|
| Location | 310-795 |
| Gene Name | AC5 |
| Protein Name | AC5 protein |
| Coding Region | ATGCATATTCTTAACAGTGGCAGTGCTAGGTTCGTTGTCGAACATATTAAAAACTTCGCCGAAATCTTGTGGCGCACCCGTAGGTCGACGATCACGCACCAAGAAAAACATCACACTATTCGTGTGGTTCTTGGTCTTGATATTCTCGTCCATCCAGATCTTGCCAAGCACGTAGACGGACTTCACACAGAATCGCTTTCCGACGCGATGTGTGAGACCGGTTCCACGGGTAACGTCGCTAATACACATCACCTTACCAATATGGGAGACATCGTGCCTGGATTCAAAAGATTGCACCTTACATGGGCCTTCACAGCCCCTGGGCACGTCCGAGCTTCGATACATCCGGTAAAATCTTGGTTTCCGGTTCATGGGTCTGTTCACCCATTCCCTTGCCTTTGTGGCGCGGACAATAGGGACAGCTGCACGGACAGCATACGGGCTGTCGAAGTTCAGACGACGGCGTGCTTTCGATGCGGGCGTTGA |
| Protein Sequence | MHILNSGSARFVVEHIKNFAEILWRTRRSTITHQEKHHTIRVVLGLDILVHPDLAKHVDGLHTESLSDAMCETGSTGNVANTHHLTNMGDIVPGFKRLHLTWAFTAPGHVRASIHPVKSWFPVHGSVHPFPCLCGADNRDSCTDSIRAVEVQTTACFRCGR |
| NCBI Accession | YP_001960971.1 |
|---|---|
| Location | 1047-1457 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGATCACGGATTCACGCACAGGGGAATACATCACTGCGGATCGAGCAGAGAGTGGCGTGTATATCTGGGACGTTCCAAATCCCCTGTATTTCAAAATTTTGAAACACGACGAGAGACCTTGCCTCACGAACCACGACATTATAACAGTCCAAATACAGTTCAACCACAACCTGAGGAAAGCACTGGGGCTTCACAAGTGTTTTCTAACATTCCAGATCTGGACGGGCTTACGCCCTCAGACTGGGCGTTTCTTGAGAGTTTTCAAAACCCAGGTCCTTAAGTACCTCGATATGTTAGGTGTTGTTGGAATTAATAATGTAATAAGAGCAGCTTATCATGTATTAGACAATGTATTGCAAAGAACAGTTGATGTATGGGCAACATATGATGTAAAACTTAATACATATTAA |
| Protein Sequence | MITDSRTGEYITADRAESGVYIWDVPNPLYFKILKHDERPCLTNHDIITVQIQFNHNLRKALGLHKCFLTFQIWTGLRPQTGRFLRVFKTQVLKYLDMLGVVGINNVIRAAYHVLDNVLQRTVDVWATYDVKLNTY |
| NCBI Accession | YP_001960972.1 |
|---|---|
| Location | 1177-1596 |
| Gene Name | AC2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCAGTCTTCATTACACTCGAGGGACCACTCTATTCCGGTCGCGAAAACGTCGCTCCCCAAGAAGAAGAAGAAGAACATCCGCAGGAGACGAGTTGATTTGCAGTGTGGTTGTTCGTATTACATATCGATCAACTGCCATGATCACGGATTCACGCACAGGGGAATACATCACTGCGGATCGAGCAGAGAGTGGCGTGTATATCTGGGACGTTCCAAATCCCCTGTATTTCAAAATTTTGAAACACGACGAGAGACCTTGCCTCACGAACCACGACATTATAACAGTCCAAATACAGTTCAACCACAACCTGAGGAAAGCACTGGGGCTTCACAAGTGTTTTCTAACATTCCAGATCTGGACGGGCTTACGCCCTCAGACTGGGCGTTTCTTGAGAGTTTTCAAAACCCAGGTCCTTAA |
| Protein Sequence | MQSSLHSRDHSIPVAKTSLPKKKKKNIRRRRVDLQCGCSYYISINCHDHGFTHRGIHHCGSSREWRVYLGRSKSPVFQNFETRRETLPHEPRHYNSPNTVQPQPEESTGASQVFSNIPDLDGLTPSDWAFLESFQNPGP |
| NCBI Accession | YP_001960973.1 |
|---|---|
| Location | 1499-2602 |
| Gene Name | AC1 |
| Protein Name | replication initiator protein |
| Coding Region | ATGGCTCCGCCAACTCGTTTCAGAATAAATGCAAAAAACTATTTCCTTACATATCCAAAGTGCTCTCTAACTAAAGAAGAGGCACTTTCCCAATTACAAAACCTAGAAACCCCTACATCAAAGAAATTCATAAAAATCTGCAGAGAGCTTCACGAAGATGGGTCTCCGCATATCCATGTTCTCATCCAATTTGAAGGAAAATTCCAGTGCAAAAATAACAGATTCTTCGACTTGGTTGCCCCAAGTCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAGCGTCAGATGTCAAGACATACATCGACAAAGACGGAGACGTTTTAGAGTGGGGTGTTTTCCAGATCGATGGACGATCTGCTCGTGGTGGTCAACAAACAGCTAACGATGCATACGCACAAGCAATTAATACTGGAAATAAAGAAGACGCATTGAAGGTGCTAAAAGAATTAGCACCAAAAGATTATGTGTTGCAGTTTCACAATTTAATGACAAATTTAGATCGGATTTTTCCTTCTCGAATCGAAGTTTATCGTTCGCCATTTACTGTTTCGTCCTTCGACAGAGTTCCGCCAGAACTCGTCGATTGGGTGTCGTCAAATTTGAGGTGTTCCGCTGCGCGGCCTTTTTCCGCTGCGCTCCCGATTAGACCCATAGGGTTAGTATTGGAGGGCGATAGTCGTACGGGCAAAACAATGTGGGCGCGTAGTTTGGGACCCCACAATTACTTGTGCGGTCACTTGGATCTAAACCCTAGGGTTTACAGTAACGATGCTTGGTACAACGTCATTGATGACGTTGATCCCCACTATCTAAAGCACTTTAAAGAATTCATGGGGGCCCAGCGTGACTGGCAAAGCAACACAAAATACGGAAAGCCGATGATGATTAAAGGCGGCATTCCCACTATCTTCTTGTGCAATAAAGGACCACAAAGCAGCTATAAAGAATTCTTGGACGAAGAAAAGAATGCAGCACTGAAACAGTGGGCATTGAAGAATGCAGTCTTCATTACACTCGAGGGACCACTCTATTCCGGTCGCGAAAACGTCGCTCCCCAAGAAGAAGAAGAAGAACATCCGCAGGAGACGAGTTGA |
| Protein Sequence | MAPPTRFRINAKNYFLTYPKCSLTKEEALSQLQNLETPTSKKFIKICRELHEDGSPHIHVLIQFEGKFQCKNNRFFDLVAPSRSAHFHPNIQGAKSASDVKTYIDKDGDVLEWGVFQIDGRSARGGQQTANDAYAQAINTGNKEDALKVLKELAPKDYVLQFHNLMTNLDRIFPSRIEVYRSPFTVSSFDRVPPELVDWVSSNLRCSAARPFSAALPIRPIGLVLEGDSRTGKTMWARSLGPHNYLCGHLDLNPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPMMIKGGIPTIFLCNKGPQSSYKEFLDEEKNAALKQWALKNAVFITLEGPLYSGRENVAPQEEEEEHPQETS |
| NCBI Accession | YP_001960974.1 |
|---|---|
| Location | 2269-2445 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGTCTCCGCATATCCATGTTCTCATCCAATTTGAAGGAAAATTCCAGTGCAAAAATAACAGATTCTTCGACTTGGTTGCCCCAAGTCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAGCGTCAGATGTCAAGACATACATCGACAAAGACGGAGACGTTTTAG |
| Protein Sequence | MGLRISMFSSNLKENSSAKITDSSTWLPQVGQHISIRTFRELNQRQMSRHTSTKTETF |
References More References in PubMed
| 1 |
Tomato leaf curl Palampur virus: an emerging begomovirus threatening tomato and cucurbit production. Roy A, et al. Mol Biol Rep. 2026 Apr 24;53(1):658. doi: 10.1007/s11033-026-11845-4. PMID: 42029785 |
|---|---|
| 2 |
Bottle gourd IC-0262269, a super-susceptible genotype to tomato leaf curl Palampur virus. Nayaka SN, et al. 3 Biotech. 2024 Jan;14(1):8. doi: 10.1007/s13205-023-03838-y. Epub 2023 Dec 8. PMID: 38074288 |
| 3 |
Naganur P, et al. Plants (Basel). 2023 Jan 20;12(3):490. doi: 10.3390/plants12030490. PMID: 36771575 |
| 4 |
Saeed A, et al. Microb Pathog. 2024 Nov;196:106953. doi: 10.1016/j.micpath.2024.106953. Epub 2024 Sep 20. PMID: 39299556 |
| 5 |
Kulshreshtha A, et al. Microb Pathog. 2019 Oct;135:103636. doi: 10.1016/j.micpath.2019.103636. Epub 2019 Aug 2. PMID: 31377236 |
| 6 |
First Report of Tomato leaf curl Palampur virus on Bitter Gourd in Pakistan. Ali I, et al. Plant Dis. 2010 Feb;94(2):276. doi: 10.1094/PDIS-94-2-0276A. PMID: 30754274 |
| 7 |
Esmaeili M, et al. Virus Genes. 2015 Dec;51(3):408-16. doi: 10.1007/s11262-015-1250-5. Epub 2015 Oct 3. PMID: 26433951 |
| 8 |
Shafiq M, et al. 3 Biotech. 2019 Jun;9(6):204. doi: 10.1007/s13205-019-1727-3. Epub 2019 May 7. PMID: 31139535 |
| 9 |
Malik AH, et al. Virol J. 2011 Apr 15;8:173. doi: 10.1186/1743-422X-8-173. PMID: 21496256 |
| 10 |
Complete sequences of tomato leaf curl Palampur virus isolates infecting cucurbits in Iran. Heydarnejad J, et al. Arch Virol. 2009;154(6):1015-8. doi: 10.1007/s00705-009-0389-6. Epub 2009 May 8. PMID: 19424773 |