Tomato leaf curl New Delhi virus 2
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002824165.1 |
| Isolate | India |
| Release date | 2018/8/25 |
| Submitter | Chaudhary,A., Kumar,R., Mukherjee,S.K. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
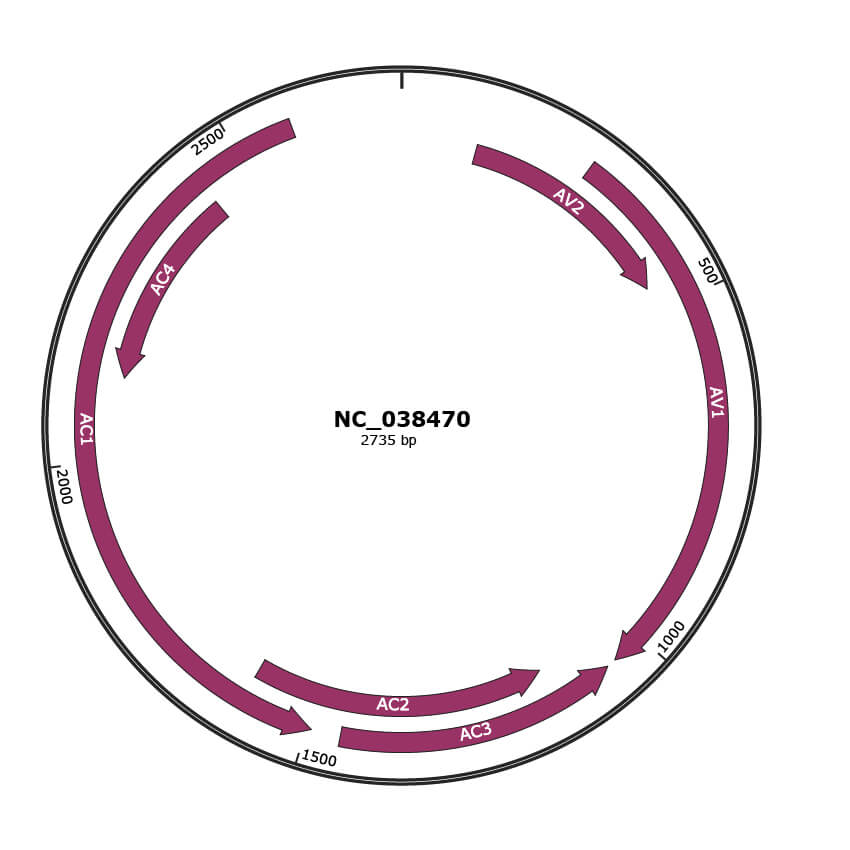
JBrowse
Genome
NC_038470
Gene Information
| NCBI Accession | YP_009506526.1 |
|---|---|
| Location | 116-463 |
| Gene Name | AV2 |
| Protein Name | AV2 |
| Coding Region | ATGTGGGATCCACTGGTTAACGAGTTCCCCGAGACGGTTCACGGGTTTCGGTGCATGCTTGCCATCAAATATCTTCAGCTACTCTCTCAGGAATACTCTCCCGATACGGTAGGTTACGATCTAATACGCGATTTGATCTGTATTTTGCGTTCCAGGAATTATGTCGAAGCGTCCTGCAGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCGTACGCGACCCGTGTGGCTGTCCCCACTGTCCGCGTCACAAAATCGCGAATGTGGGCGAACAGGCCCATGAATCGGAAGCCCAGAATTTACAGGATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLVNEFPETVHGFRCMLAIKYLQLLSQEYSPDTVGYDLIRDLICILRSRNYVEASCRYRHFYPRVEGASASELRQPVRDPCGCPHCPRHKIANVGEQAHESEAQNLQDVQKP |
| NCBI Accession | YP_009506527.1 |
|---|---|
| Location | 276-1046 |
| Gene Name | AV1 |
| Protein Name | AV1 |
| Coding Region | ATGTCGAAGCGTCCTGCAGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCGTACGCGACCCGTGTGGCTGTCCCCACTGTCCGCGTCACAAAATCGCGAATGTGGGCGAACAGGCCCATGAATCGGAAGCCCAGAATTTACAGGATGTACAGAAGCCCTGATGTTCCAAAGGGCTGTGAGGGTCCATGTAAGGTACAGTCTTTCGAGTCCAGACACGATGTAGTGCATATAGGTAAGGTAATGTGCATCAGTGATGTCACCCGCGGTACTGGGCTGACCCATCGAGTAGGGAAGCGTTTCTGCGTGAAATCTGTTTATGTTTTGGGTAAGATATGGATGGATGAAAACATCAAGTCCAAAAATCATACTAACAATGTCATGTTCTTTCTCGCCCGTGATCGACGGCCCACTGACAAGCCTCAGGATTTTGGAGAGGTGTTCAACATGTTTGACAACGAGCCTAGCACTGCCACTGTGAAGAATATGCATCGAGACCGCTACCAGGTATTGCGTAAGTGGTATGCAACCGTCACGGGTGGACAGTATGGTGCAAAGGAACAGGCCCTTGTCAAGAAGTTTGTTAGGGTTAACAATTATGTAGTTTATAACCAGCAGGAGGCTGGTAAATATGAGAATCACACCGAGAATGCTCTGATGTTGTATATGGCATGTACCCATGCCTCTAATCCCGTGTACGCGACTCTTAAGATTAGGATTTACTTCTACGATTCTGTAACGAACTGA |
| Protein Sequence | MSKRPADIVISTPASKVRRRLNFDSPYATRVAVPTVRVTKSRMWANRPMNRKPRIYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKSKNHTNNVMFFLARDRRPTDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWYATVTGGQYGAKEQALVKKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | YP_009506528.1 |
|---|---|
| Location | 1060-1452 |
| Gene Name | AC3 |
| Protein Name | AC3 |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAATGGCGCCTATATCTGGGAGATTCCAAATCCCCTCTATTTCAAGCTCCTCAGCCACGACGTCCGTCCATTCACGACGAACATGGACATACTCACGATCAGGATCCAATTCAACTACAACCTCCGGAGAGCTCTGGGAGTGCACAAATGTTTTCTGACCTACCGAATCTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACCCAAGTCCTCAAGTATCTCAACAATATCGGTGTAATATCAATTAATGCAATTATTAGGGCTGTAAATCATGTATTATGGAATAAATTAGAGCAAACTATGTATGTAGACCTGATCAGAAATAAAAATTAA |
| Protein Sequence | MDSRTGEPITAAQAWNGAYIWEIPNPLYFKLLSHDVRPFTTNMDILTIRIQFNYNLRRALGVHKCFLTYRIWTTLHPPTGLFLRVFKTQVLKYLNNIGVISINAIIRAVNHVLWNKLEQTMYVDLIRNKN |
| NCBI Accession | YP_009506529.1 |
|---|---|
| Location | 1145-1597 |
| Gene Name | AC2 |
| Protein Name | AC2 |
| Coding Region | ATGCGATCTTCGTCACCCTCGAAGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACCGGAGGAGGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATCTGTCCATCAACTGCCACAATCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAATGGCGCCTATATCTGGGAGATTCCAAATCCCCTCTATTTCAAGCTCCTCAGCCACGACGTCCGTCCATTCACGACGAACATGGACATACTCACGATCAGGATCCAATTCAACTACAACCTCCGGAGAGCTCTGGGAGTGCACAAATGTTTTCTGACCTACCGAATCTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACCCAAGTCCTCAAGTATCTCAACAATATCGGTGTAATATCAATTAA |
| Protein Sequence | MRSSSPSKDHCTQVPIKVQHREAKRRNRRRRVDLECGCSYYLSINCHNHGFTHRGTHHCSSSMEWRLYLGDSKSPLFQAPQPRRPSIHDEHGHTHDQDPIQLQPPESSGSAQMFSDLPNLDDLTPSDWSFLKGIQDPSPQVSQQYRCNIN |
| NCBI Accession | YP_009506530.1 |
|---|---|
| Location | 1494-2582 |
| Gene Name | AC1 |
| Protein Name | AC1 |
| Coding Region | ATGCCTCCAAAGCGCTTCGTTATAAACTCCAAAAATTATTTCCTCACTTATCCTAAGTGCTCACTAACCAAAGAGGAAGCACTTTCCCAAATCCAGAATTTCCAAACCCCAACTTCAAAAAAATATATTAAAATCTGCCGAGAATTACATGAGAATGGGGAACCTCATCTGCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGGGACACTCTCGAGTGGGGAGAGTTTCAGATCGATGGAAGATCAGCAAGAGGAGGACAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAGGGAACTAGCTCCTAAAGATTTTGTACTACAATTTCATAATTTAAATGCAAATCTAGACAGAATCTTTCAGGAGCCACCGGCTCCCTATATTTCTCCTTTTTCTTCATCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGATTGGGCGTCCGAGAACGTTGTCGATCCCGCTGCGCGGCCCCTTAGACCTCAGAGTATAGTAATTGAGGGAGACAGTCGAACGGGGAAGACGATGTGGGCTAGGTCACTGGGACCACACAACTATTTGTGTGGACACCTGGACCTAAGTCCCAAAGTATACAGTAACGACGCTTGGTATAACGTCATTGATGACGTTGACCCGCACTTCCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGAGACTGGCAGTCCAACACAAAATACGGGAAGCCAGTTCAAATTAAAGGCGGGATACCGACAATCTTCCTGTGCAATCCTGGTCCCAACAGCAGTTATAAGGAATTCCTCGACGAGGAAAAGAACACCGCATTAAAGAACTGGGCCGTCAAAAATGCGATCTTCGTCACCCTCGAAGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAGGCGCAACCGGAGGAGGAGAGTAGATCTTGA |
| Protein Sequence | MPPKRFVINSKNYFLTYPKCSLTKEEALSQIQNFQTPTSKKYIKICRELHENGEPHLHVLIQFEGKYKCQNQRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIRELAPKDFVLQFHNLNANLDRIFQEPPAPYISPFSSSSFDQVPEELEDWASENVVDPAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNTALKNWAVKNAIFVTLEGPLYSGSNQSTAQGSEEAQPEEESRS |
| NCBI Accession | YP_009506531.1 |
|---|---|
| Location | 2126-2434 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAGAATGGGGAACCTCATCTGCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGGGACACTCTCGAGTGGGGAGAGTTTCAGATCGATGGAAGATCAGCAAGAGGAGGACAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAGGGAACTAG |
| Protein Sequence | MRMGNLICTCSSSSRGNTSARISDSSTWSPQAGQHISIRTFRELNQAPMSSPTSTRTGTLSSGESFRSMEDQQEEDNRQPTTLTPQHLTQAVSQRLLESLGN |
References More References in PubMed
| 1 |
Begomovirus Tomato Leaf Curl New Delhi Virus Is Seedborne but Not Seed Transmitted in Melon. Fortes IM, et al. Plant Dis. 2023 Feb;107(2):473-479. doi: 10.1094/PDIS-09-21-1930-RE. Epub 2023 Feb 15. PMID: 35771117 |
|---|---|
| 2 |
Host Species-Dependent Transmission of Tomato Leaf Curl New Delhi Virus-ES by Bemisia tabaci. Janssen D, et al. Plants (Basel). 2022 Jan 30;11(3):390. doi: 10.3390/plants11030390. PMID: 35161372 |
| 3 |
Taglienti A, et al. Front Microbiol. 2022 Apr 25;13:840893. doi: 10.3389/fmicb.2022.840893. eCollection 2022. PMID: 35547120 |
| 4 |
Resistance Against Melon Chlorotic Mosaic Virus and Tomato Leaf Curl New Delhi Virus in Melon. Romay G, et al. Plant Dis. 2019 Nov;103(11):2913-2919. doi: 10.1094/PDIS-02-19-0298-RE. Epub 2019 Aug 20. PMID: 31436474 |
| 5 |
Koeda S, et al. BMC Plant Biol. 2024 Oct 2;24(1):879. doi: 10.1186/s12870-024-05591-7. PMID: 39358692 |
| 6 |
Venkataravanappa V, et al. 3 Biotech. 2020 Jun;10(6):282. doi: 10.1007/s13205-020-02245-x. Epub 2020 Jun 2. PMID: 32550101 |
| 7 |
Sub-cellular localization of suppressor proteins of tomato leaf curl New Delhi virus. Sarkar M, et al. Virusdisease. 2021 Jun;32(2):298-304. doi: 10.1007/s13337-021-00651-0. Epub 2021 Apr 10. PMID: 34350318 |
| 8 |
Schafleitner R, et al. Sci Rep. 2024 Mar 21;14(1):6793. doi: 10.1038/s41598-024-57348-9. PMID: 38514827 |
| 9 |
Grafting to Manage Infections of the Emerging Tomato Leaf Curl New Delhi Virus in Cucurbits. Mastrochirico M, et al. Plants (Basel). 2022 Dec 21;12(1):37. doi: 10.3390/plants12010037. PMID: 36616164 |
| 10 |
Natural Occurrence of Tomato leaf curl New Delhi virus in Iranian Cucurbit Crops. Yazdani-Khameneh S, et al. Plant Pathol J. 2016 Jun;32(3):201-8. doi: 10.5423/PPJ.OA.10.2015.0210. Epub 2016 Jun 1. PMID: 27298595 |