Tomato leaf curl Namakely virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002987045.1 |
| Isolate | Madagascar:Antsiranana, Namakely |
| Release date | 2018/8/26 |
| Submitter | Lefeuvre,P., Martin,D.P., Hoareau,M., Naze,F., Becker,N., Delatte,H., Reynaud,B., Lett,J.M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
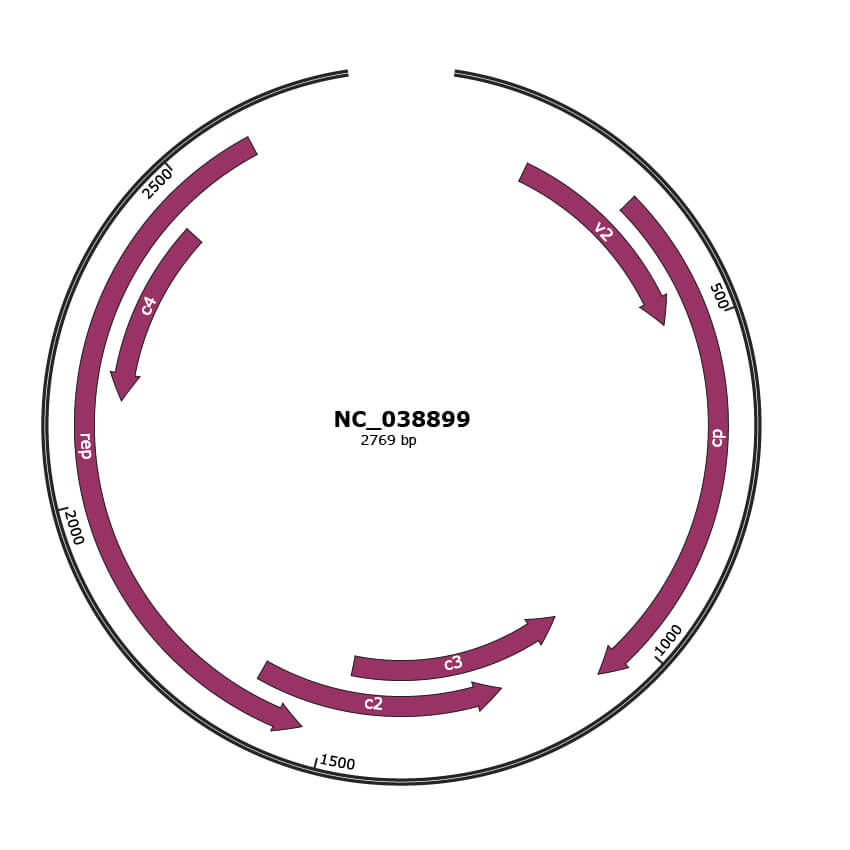
Genomic Organization
JBrowse
Genome
NC_038899
Gene Information
| NCBI Accession | YP_009508199.1 |
|---|---|
| Location | 139-489 |
| Gene Name | v2 |
| Protein Name | V2 protein |
| Coding Region | ATGTGGGATCCATTGTTAAATGAATTTCCGGACTCTGTGCATGGGTTTCGTTGTATGCTTGCCATAAAATATCTGCAGGCCGTTGAGCAAACTTATGAGCCCAATACATTGGGCCACGATTTAATTCGAGATTTAATTTCTGTGATTAGAGCCCGTGACTATGTCGAAGCGACCCGGAGATATAATCATTTCCACGCCCGTCTCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCATATACCAGCCGTGCTGCTGCCCCCATTGTCCCAGGCACAAACAGACGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPDSVHGFRCMLAIKYLQAVEQTYEPNTLGHDLIRDLISVIRARDYVEATRRYNHFHARLEGASKAELRQPIYQPCCCPHCPRHKQTSIMDLQAHVSKAQDVQNVQKP |
| NCBI Accession | YP_009508200.1 |
|---|---|
| Location | 299-1075 |
| Gene Name | cp |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCCGGAGATATAATCATTTCCACGCCCGTCTCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCATATACCAGCCGTGCTGCTGCCCCCATTGTCCCAGGCACAAACAGACGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCTCGTGGTTGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAGCAGAGGGATGATGTTAAGCATACCGGTATTGTTCGTTGTGTTAGTGATGTTACGCGTGGTTCGGGTATTACCCATAGAGTTGGCAAGAGGTTTTGTGTTAAGTCCATTTACATTTTAGGGAAGATCTGGATGGATGAAAATATCAAGAAGCAGAATCATACTAATCAGGTTATGTTTTTCCTTGTTCGTGATAGAAGGCCCTATGGGCCTTCTCCAATGGATTTTGGACAGGTGTTCAACATGTTTGATAATGAGCCCAGTACAGCTACAGTGAAGAATGATTTGAGAGACAGATATCAAGTTATGCGGAAATTTCATGCAACTGTTGTTGGTGGACCCTCAGGGATGAGAGAGCAGACTTTAGTTAAGAGATTTTTTAGGATTAATAGTCATGTAACGTATAATCATCAGGAGCAGGCTAAGTATGAGAACCATACTGAGAACGCTTTGTTGTTGTATATGGCATGTACTCATGCTTCTAACCCAGTGTATGCTACTCTTAAGATACGGATCTATTTTTATGATTCGGTCAGCAATTAA |
| Protein Sequence | MSKRPGDIIISTPVSKVRRRLNFDSPYTSRAAAPIVPGTNRRRSWTYRPMYRKPRMYRMYRSPDVPRGCEGPCKVQSFEQRDDVKHTGIVRCVSDVTRGSGITHRVGKRFCVKSIYILGKIWMDENIKKQNHTNQVMFFLVRDRRPYGPSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMRKFHATVVGGPSGMREQTLVKRFFRINSHVTYNHQEQAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVSN |
| NCBI Accession | YP_009508201.1 |
|---|---|
| Location | 1072-1476 |
| Gene Name | c3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTTACGCACAGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTATATTTCAAGATAATCGACCACAGCATCAGACCATTCAACATGAACCACGACATCATATCAATCCAGATACGGTTCAACCACAACATCAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCAAGATCTGGACGAGCTTACGCCCTCAGACTGGTCGTTTCTTAAGAGTATTTAGGACTCAAGTTCTCATGTATTTAGATAGATTAGGAATTATTTCAATTAACAATGTAATAAGAGCAGTTGATTATGTATTGTACGATGTACTTGTAAATACACTCCAAGTTGAGGAGAATTATGAAATAAAATTCAATATTTATTAA |
| Protein Sequence | MDLRTGELITAAQAQSGVFIWEIQNPLYFKIIDHSIRPFNMNHDIISIQIRFNHNIRKELGIHKCFLNFKIWTSLRPQTGRFLRVFRTQVLMYLDRLGIISINNVIRAVDYVLYDVLVNTLQVEENYEIKFNIY |
| NCBI Accession | YP_009508202.1 |
|---|---|
| Location | 1217-1624 |
| Gene Name | c2 |
| Protein Name | C2 protein |
| Coding Region | ATGCGACCTTCGTCACCCTCCACGAGCCATTGTTCTCAAGTACCAATCAAGGTCCACCACCGCATAGCCAAGAGGAAAGCAGTGAGGCGTAGAAGAATTGACCTAGACTGCGGTTGCTCCTATTATCTACACATCAACTGCACAAACCATGGATTTACGCACAGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTATATTTCAAGATAATCGACCACAGCATCAGACCATTCAACATGAACCACGACATCATATCAATCCAGATACGGTTCAACCACAACATCAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCAAGATCTGGACGAGCTTACGCCCTCAGACTGGTCGTTTCTTAAGAGTATTTAG |
| Protein Sequence | MRPSSPSTSHCSQVPIKVHHRIAKRKAVRRRRIDLDCGCSYYLHINCTNHGFTHRGTHHCSSSTEWRVYLGDTKSPIFQDNRPQHQTIQHEPRHHINPDTVQPQHQEGTGDSQMFSQLQDLDELTPSDWSFLKSI |
| NCBI Accession | YP_009508203.1 |
|---|---|
| Location | 1533-2612 |
| Gene Name | rep |
| Protein Name | replication associated protein |
| Coding Region | ATGGCTCCCCCACGTCGCTTTAAAATTTTTGCTAAAAATTTTTTCCTCACTTATCCAAAGTGCTCTCTCACAAAAGAGGAAGCACTATCCCAAATACAAGCCTTACAAACCCCAGTAAACAAATTATTCATCAAAATTTGCAGAGAATTACACGAAAATGGGGAACCTCATCTGCACATGCTTATCCAGTTCGAAGGAAAGTACCAGTGCACGAATCAGAGATTCTTCGACCTTGTATCCCCAACAAGGCCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGACACCCTCGAATGGGGCGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAACAATCCGCCAATGACGCTTACGCCACAGCTCTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAATTAGTCCCAAAAGATTATGTTTTACAATTTCATAATTTAAATAGTAATTTAGATAGGATTTTTAAGGAGCCTCCGGCTCCTTATGTTTCTCCATTTCTTTCTTCTTCTTTTAATCAAGTTCCCGAAGAACTTGAAGTTTGGGTGTCGGAGAACATCAGGGATGCCGCTGCGCGGCCGTGGAGACCGATTAGTATTGTAATTGAGGGTGATAGTAGGACGGGGAAGACGATGTGGGCCAGATCATTAGGACCCCACAACTATTTATGTGGTCATCTTGACCTGAGTCCTAAAGTCTACAGCAATGATGCATGGTTCAACATCATTGATGACGTGGACCCGCATTATTTAAAACATTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAGAGCAACACAAAGTACGGGAAGCCAATTCAAATAAAAGGCGGAATTCCCACTATATTCCTCTGCAATCCAGGACCAACATCCTCTTATAAAGAATATCTAGACGAGGAGAAAAATGCACCACTAAAAGCCTGGGCACTGAAGAATGCGACCTTCGTCACCCTCCACGAGCCATTGTTCTCAAGTACCAATCAAGGTCCACCACCGCATAGCCAAGAGGAAAGCAGTGAGGCGTAG |
| Protein Sequence | MAPPRRFKIFAKNFFLTYPKCSLTKEEALSQIQALQTPVNKLFIKICRELHENGEPHLHMLIQFEGKYQCTNQRFFDLVSPTRPAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQSANDAYATALNAGSKSEALRVIKELVPKDYVLQFHNLNSNLDRIFKEPPAPYVSPFLSSSFNQVPEELEVWVSENIRDAAARPWRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWFNIIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKNAPLKAWALKNATFVTLHEPLFSSTNQGPPPHSQEESSEA |
| NCBI Accession | YP_009508204.1 |
|---|---|
| Location | 2153-2455 |
| Gene Name | c4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCTCATCTGCACATGCTTATCCAGTTCGAAGGAAAGTACCAGTGCACGAATCAGAGATTCTTCGACCTTGTATCCCCAACAAGGCCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGACACCCTCGAATGGGGCGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAACAATCCGCCAATGACGCTTACGCCACAGCTCTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAATTAG |
| Protein Sequence | MGNLICTCLSSSKESTSARIRDSSTLYPQQGQHISIRTFRELNPAPTSSPTSTRTETPSNGASFRSMEDLQEGDNNPPMTLTPQLLTQAVSQRLLESLRN |
References More References in PubMed
| 1 |
Al-Matroushi AR, et al. Cell Mol Biol (Noisy-le-grand). 2024 Nov 27;70(11):101-108. doi: 10.14715/cmb/2024.70.11.15. PMID: 39707774 |
|---|---|
| 2 |
Zhao J, et al. Virology. 2019 Sep;535:210-217. doi: 10.1016/j.virol.2019.07.007. Epub 2019 Jul 11. PMID: 31319278 |
| 3 |
Introduction of the Exotic Tomato yellow leaf curl virus-Israel in Tomato to Puerto Rico. Bird J, et al. Plant Dis. 2001 Sep;85(9):1028. doi: 10.1094/PDIS.2001.85.9.1028B. PMID: 30823090 |
| 4 |
Sharma N, et al. Genomics. 2021 May;113(3):889-899. doi: 10.1016/j.ygeno.2021.01.022. Epub 2021 Jan 30. PMID: 33524498 |
| 5 |
R K MP, et al. BMC Plant Biol. 2026 Jul 9. doi: 10.1186/s12870-026-09443-4. Online ahead of print. PMID: 42420848 |
| 6 |
Rosas-Díaz T, et al. Plants (Basel). 2016 Jan 15;5(1):8. doi: 10.3390/plants5010008. PMID: 27135228 |
| 7 |
Ghosh S, et al. Viruses. 2021 Sep 11;13(9):1808. doi: 10.3390/v13091808. PMID: 34578388 |
| 8 |
Hussain K, et al. Cell Mol Biol (Noisy-le-grand). 2022 Sep 30;68(9):129-134. doi: 10.14715/cmb/2022.68.9.20. PMID: 36905263 |
| 9 |
Enhanced association of whitefly-begomovirus competence with plant-mediated mutualism. He WZ, et al. Pest Manag Sci. 2025 Apr;81(4):2126-2132. doi: 10.1002/ps.8613. Epub 2024 Dec 18. PMID: 39691989 |
| 10 |
Nayaka SN, et al. Virusdisease. 2023 Sep;34(3):421-430. doi: 10.1007/s13337-023-00837-8. Epub 2023 Sep 8. PMID: 37780909 |