Tomato leaf curl Moheli virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002987035.1 |
| Isolate | Comoros:Moheli, Fomboni |
| Release date | 2018/8/26 |
| Submitter | Lefeuvre,P., Martin,D.P., Hoareau,M., Naze,F., Becker,N., Delatte,H., Reynaud,B., Lett,J.M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
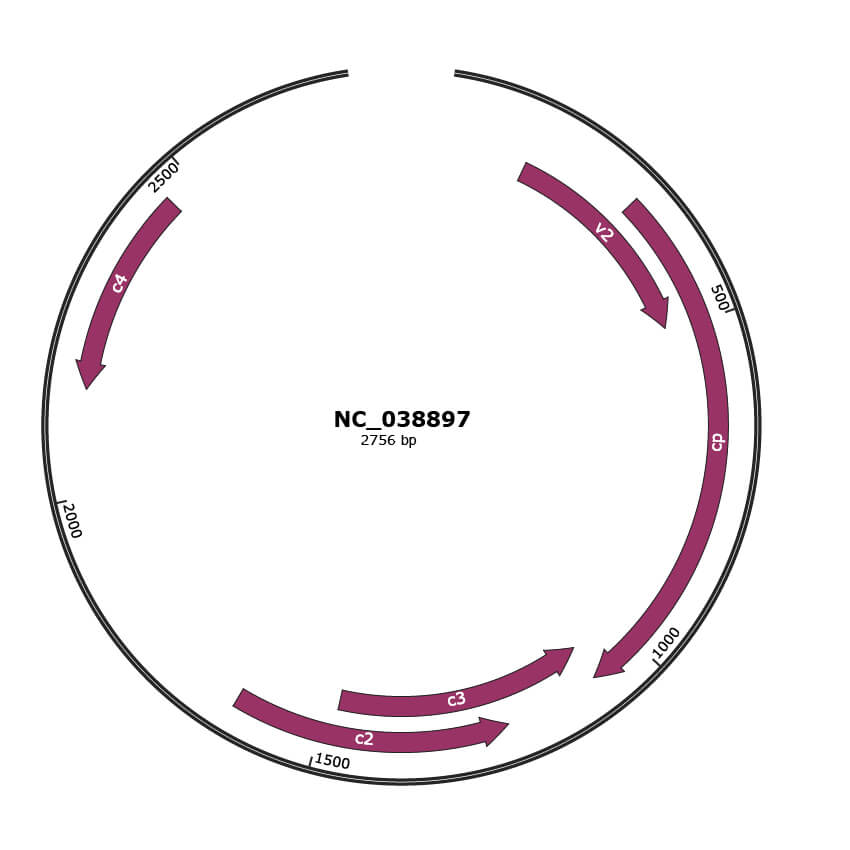
Genomic Organization
JBrowse
Genome
NC_038897
Gene Information
| NCBI Accession | YP_009508191.1 |
|---|---|
| Location | 136-492 |
| Gene Name | v2 |
| Protein Name | V2 protein |
| Coding Region | ATGTGGGATCCGGATCCACTCTTAAATGAGTTCCCAGACTCTGTTCACGGTTTTCGTTGTATGCTAGCTATCAAATATTTGCAGGCCATTGAGCAAACCTACGAGCCCAATACTTTGGGCCACGAATTGATTCGTGATCTCATATCCGTTATCAGAGCTCGTGACTATGTCGAAGCGACCCGCCGATATAATCATTTCCACGCCCGCTTCGAAGGTGCGTCGAAGGTTGAACTTCGACAGCCCGTTTACCAGCCGTGCTGTTGTCCCCATTGTCCCAGGCACAAGCAGACGTCGGTCATGGACGTACAGGCCCATGTATCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPDPLLNEFPDSVHGFRCMLAIKYLQAIEQTYEPNTLGHELIRDLISVIRARDYVEATRRYNHFHARFEGASKVELRQPVYQPCCCPHCPRHKQTSVMDVQAHVSKAQDVQNVQKP |
| NCBI Accession | YP_009508192.1 |
|---|---|
| Location | 302-1078 |
| Gene Name | cp |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCCGCCGATATAATCATTTCCACGCCCGCTTCGAAGGTGCGTCGAAGGTTGAACTTCGACAGCCCGTTTACCAGCCGTGCTGTTGTCCCCATTGTCCCAGGCACAAGCAGACGTCGGTCATGGACGTACAGGCCCATGTATCGAAAGCCCAGGATGTACAGAATGTACAGAAGCCCTGATGTTCCAAAGGGTTGTGAAGGCCCATGTAAGGTCCAGTCTTATGAGCAGAGGGATGATGTTAAACATACTGGTATTGTTCGTTGTGTTAGTGATGTTACGCGTGGTCCGGGAATTACTCATAGAGTTGGCAAGAGGTTCTGTGTTAAGTCCATTTACATTTTAGGTAAGATATGGATGGATGAAAATATCAAGAAGCAGAATCACACTAATCAGGTTATGTTTTTTTTAGTCCGTGATAGAAGGCCCTATGGTGCAGCCCCAATGGATTTTGGGCAGGTGTTTAACATGTTTGATAATGAGCCCAGCACAGCTACGGTGAAGAATGATTTGAGAGACAGGTATCAGGTTTTGCGGAAGTTTCATGCAACTGTTGTAGGTGGGCCCTCTGGGATGAAGGAACAGGCGTTAGTTAAGAGATTTTTTAAGATTAATAGTCATGTAACATATAATCATCAGGAAGCAGCTAAGTATGAGAACCATACGGAGAATGCTTTGTTGTTGTATATGGCGTGTACTCATGCCTCTAATCCAGTGTATGCTACTCTTAAGATACGAATCTACTTCTACGATTCGATCGGTAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFDSPFTSRAVVPIVPGTSRRRSWTYRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSYEQRDDVKHTGIVRCVSDVTRGPGITHRVGKRFCVKSIYILGKIWMDENIKKQNHTNQVMFFLVRDRRPYGAAPMDFGQVFNMFDNEPSTATVKNDLRDRYQVLRKFHATVVGGPSGMKEQALVKRFFKINSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIGN |
| NCBI Accession | YP_009508193.1 |
|---|---|
| Location | 1075-1479 |
| Gene Name | c3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTTTCGCACAGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTGTATTTCAAGATTATCGACCACGAGAACCGACCATTCAACATGCCCCACGACATCATATCAGTCCAGATAAGATTCAACCACAACTTGAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCAGGGTCTGGACGAGCTCACAGCCTCAGACTGGTCTTTTCTTAAGGGTATTTAGGACTCAGGTTCTCAAGTATTTAGATAGATTAGGGGTTATTTCAATTAACGATGTAATTAGAGCAGTTTATCATGTATTGTATAATGTATTGAAAAATACTCTGCAAGTATCAGAAAATCATGAAATAAAATTTAATATTTATTAA |
| Protein Sequence | MDFRTGELITAAQAQSGVFIWEIQNPLYFKIIDHENRPFNMPHDIISVQIRFNHNLRKELGIHKCFLNFRVWTSSQPQTGLFLRVFRTQVLKYLDRLGVISINDVIRAVYHVLYNVLKNTLQVSENHEIKFNIY |
| NCBI Accession | YP_009508194.1 |
|---|---|
| Location | 1220-1627 |
| Gene Name | c2 |
| Protein Name | C2 protein |
| Coding Region | ATGCGACCTTCGTCACCCTCCACGAGCCACTGTTCTCAAATACCAATCAAAGTCCAGCACAGAATAGCCAAGAAGAGGGCAGTGAGGCGTAGAAGGATTGATCTCGACTGCGGCTGCTCATACTATCTCCACATCAACTGCATCGACCATGGATTTTCGCACAGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTGTATTTCAAGATTATCGACCACGAGAACCGACCATTCAACATGCCCCACGACATCATATCAGTCCAGATAAGATTCAACCACAACTTGAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCAGGGTCTGGACGAGCTCACAGCCTCAGACTGGTCTTTTCTTAAGGGTATTTAG |
| Protein Sequence | MRPSSPSTSHCSQIPIKVQHRIAKKRAVRRRRIDLDCGCSYYLHINCIDHGFSHRGTHHCSSSTEWRVYLGDTKSPVFQDYRPREPTIQHAPRHHISPDKIQPQLEEGTGDSQMFSQLQGLDELTASDWSFLKGI |
| NCBI Accession | YP_009508195.1 |
|---|---|
| Location | 2155-2457 |
| Gene Name | c4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCTCATCTGCATGCCCTTATTCAATTCGAGGGAAAACTCACGTGCACCAACAATCGCCTCTTCGATTGCGTACACCCAAGCAGTAGCACCTGTTTCCACCCCAACATACAAGGAGCTAAGTCCAGCTCTGACGTCAAGTCCTATCTGGACAAGGACGGAGACACCCTTGAGTGGGGAGAGTTTCAGATCGATGGACGATCTGCAAGAGGGGGACAACAATCAGCCAATGACGCTTACGCCAAAGCTATTAACTCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAGGGAGTTAG |
| Protein Sequence | MGNLICMPLFNSRENSRAPTIASSIAYTQAVAPVSTPTYKELSPALTSSPIWTRTETPLSGESFRSMDDLQEGDNNQPMTLTPKLLTQAVSQRLLESLGS |
References More References in PubMed
| 1 |
A New Tomato leaf curl virus from Mayotte. Lett JM, et al. Plant Dis. 2004 Jun;88(6):681. doi: 10.1094/PDIS.2004.88.6.681B. PMID: 30812598 |
|---|---|
| 2 |
Molecular Characterization of a Begomovirus Associated with Tomato Leaf Curl Disease in Uganda. Shih SL, et al. Plant Dis. 2006 Feb;90(2):246. doi: 10.1094/PD-90-0246A. PMID: 30786424 |
| 3 |
Within-host dynamics of the emergence of Tomato yellow leaf curl virus recombinants. Urbino C, et al. PLoS One. 2013;8(3):e58375. doi: 10.1371/journal.pone.0058375. Epub 2013 Mar 5. PMID: 23472190 |
| 4 |
Tomato leaf curl Mahe virus: a novel tomato-infecting monopartite begomovirus from the Seychelles. Scussel S, et al. Arch Virol. 2018 Dec;163(12):3451-3453. doi: 10.1007/s00705-018-4007-3. Epub 2018 Sep 3. PMID: 30178119 |
| 5 |
Martin DP, et al. PLoS Pathog. 2011 Sep;7(9):e1002203. doi: 10.1371/journal.ppat.1002203. Epub 2011 Sep 15. PMID: 21949649 |
| 6 |
Thierry M, et al. Arch Virol. 2012 Mar;157(3):545-50. doi: 10.1007/s00705-011-1199-1. Epub 2011 Dec 21. PMID: 22187103 |
| 7 |
Péréfarres F, et al. Virol J. 2011 Aug 5;8:389. doi: 10.1186/1743-422X-8-389. PMID: 21819593 |