Tomato leaf curl Mindanao virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000872745.1 |
| Isolate |
Philippines: Mindanao |
| Release date |
2015/2/13 |
| Submitter |
Tsai,W.S., Shih,S.L., Venkatesan,S.G., Aquino,M.U., Green,S.K., Kenyon,L., Jan,F.J., Aquino,M., Huang,Y.C., Jan,F.-J. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
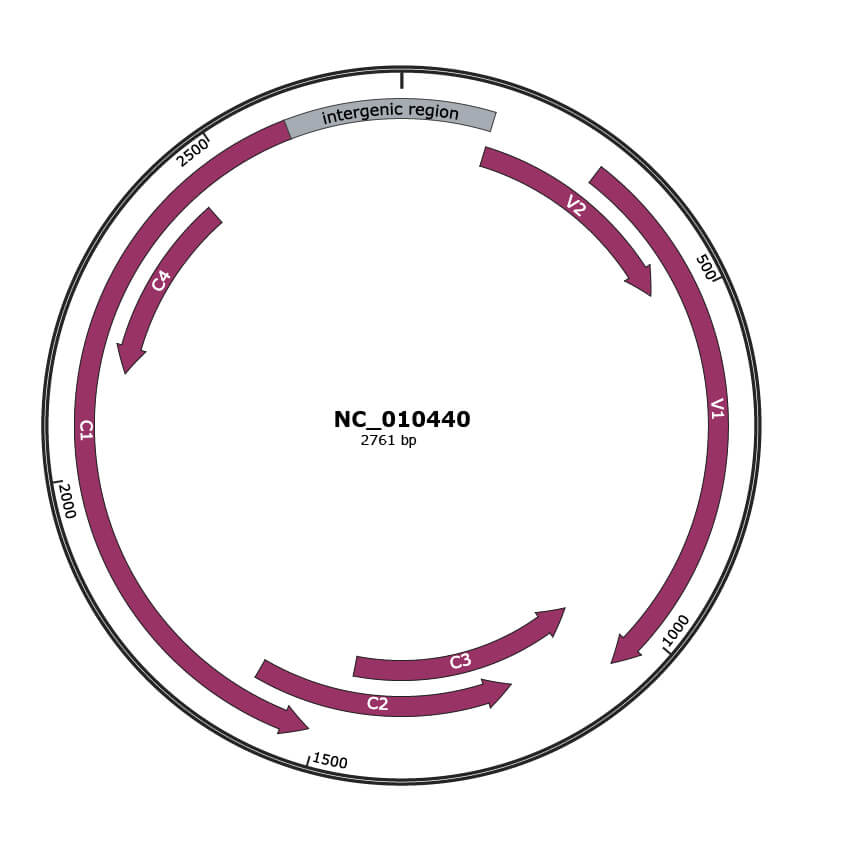
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTGGTGGTCACTATCACTAACTTTTGTCTGCCAATAGAAACGCTCCCTCAAAGCTTATTTAATATGTGGTCCCCTATTTAAAGATTGCTCACTAAGTTGTTTCCCAAACATGTGGGATCCGTTAGTTAATGAGTTTCCCGATACCGTTCATGGTTTCAGGTGTATGTTAGCCGTAAAATACTTGCAGTTAGTAGAATCTACGTATTCACCAGATACGCTTGGGTACGATCTTATCCGAGATTTAATTTCCGTCGTCCGTGCAAAAAACTATGTCGAAGCGTCCCGCCGATATAGTCATTTCCACTCCCGCATCGAAGGTACGTCGCCGTCTCAATTTCGACAGCCCTTACACGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAGGAGAACATGGTCCAACAGGCCCATGTACAGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGATGTGCCCAAAGGTTGTGAAGGCCCATGTAAGGTCCAATCGTATGAACAGAGGCACGACATATCCCATGTTGGTAAAGTATTATGTGTTAGTGATGTCACTCGTGGCAGTGGGCTTACCCATCGAGTTGGTAAGAGATTCTGTGTGAAGTCCGTCTATGTATTGGGTAAAATATGGATGGATGAAAATATCAAAACCAAGAACCATACGAACACTGTGATGTTTTATCTTGTTCGTGATAGAAGGCCCTATGGTACTGCTATGGAATTTGGTCAGGTGTTTAACATGTATGATAATGAGCCCAGTACTGCTACTATCAAGAATGATCTTCGAGATCGTTATCAGGTTTTAAGAAAATTCACCTCAACGGTCACAGGCGGTCAATATGCTTCTAAGGAACAGGCGTTGGTTAGGAAATTTATGAAGGTTAATAATTATGTAGTTTATAATCATCAAGAGGCTGCTAAGTATGACAATCATACTGAGAATGCCTTGTTATTGTATATGGCTTGTACTCATGCCAGTAATCCAGTGTATGCTACTTTGAAGATCAGAATCTATTTCTATGATTCTCTTCAGAATTAATAAAGATTGAATTTTATTATACTTGAAAGTTGTACATCGATTGTTCTTTCCAATACATTCCATAATACATGAGAAACTGCCCTAATTACATTGTTAATGCTGATTACACCCAAATTATCTAAATACTTCATACATTGATATTTAAAGACTCTTAAGAAACGCCAAGTCTGAGGTTGTAAGCGAGTCCAAATCTGGAAAATCAGAAAACACTGGTGTATTCCCAACGCTTTCCTCAGGTTGTGGTTGAACTGTATCTGGATCGTTATGATGTCGTGGTTGTTGTTGAATGATCTCTCGTGGTGTTTGGTGATCTTGAAATATAGGGGATTTTTGATTGTCCAGGTATACACGCCACTCTCGCATTGAGTTGCAGTGAGTAATTCCCCTGTGCGAAAATCCATGATTTGCACAATCTATGCCGAAGTAGTATGAGCAACCGCAAGGAAGATCAACTCTCCGTCTGCGAACAGGCCTCTTCTTGGCTATTCTGTGTTGGACTTTGATGGGTACCTGAGTACAATGGGCTTGTGAGGGTGATGAATTCTGCATTCTTTAGTGCCCAATCTTTTAATGCTGAATTTTTATTTTCGTCCAAGTACTCTTTATATGATGATGTTGGTCCCGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATGGGCTTCCCGTACTTGGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAATGCTTTAGATAGTGGGGGTSGACGTCATCAATGACGTTGTACCAAGCATCATTACTGTAGACCTTTGGACTTAAGTCCAGATGTCCACATAAGTAATTGTGTGGACCCAGTGACCTAGCCCACATCGTCTTCCCTGTCCTACTATCGCCCTCTATTACAATACTTTTAGGTCTCCAAGGCCGCGCAGCGGCATCCCTTACATTCTCAGAGACCCAATCTTCAAGTTCTTCTGGAACTTGATTAAAAGAAGAAGAAAGAAAAGGACAAACAAAAACCTCTAAAGGAGGTGCGAAAATCCTATCTAAATTATTATTTAAATTATGAAATTGTAAAACAAAATCTTTAGGAGCTAATTCCTTAATTACATTAAGAGCCTCCGACTTACTTCCTGCGTTAAGCGCCTTGGCGTAAGCATCATTGGCTGATTGTTGTCCCCCTCGTGCAGATCGTGCGTCGATCTGGAATTCACCCCATTCGAGAGTGTCTCCGTCCTTGTCGATATAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGAAGGGGATACAAGGTCGAAGAATCGTGAATTTGTGCATCTGTATTTCCCTTCGAACTGTACGAGCACGTGGAGATGAGGGCTCCCATCTTCGTGAAGTTCTCTGCAGATTCTGATATATTTTTTATTTGTTGGGGTTTGTATATTTTGTATTTGGGAAAGTGCTTCCTCTTTGGTTAGAGAGCACTGTGGATATGTGAGGAAATAATTTTTGGCATTTATTTGGAATTTTCTCGGTGGTGCCATTTGACTTAGTCAATGGGTACCCAATGAGAGGATTTCCTAATGCTCTGGGTATCGGTACATTGGTACCCATCTATACTCGGTTACCTAATGGCATTAATGTAATTTCTAGAGAAATTCAAAATTTTAATTTTAAATCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001718624.1
|
|
Location
|
130-480 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCGTTAGTTAATGAGTTTCCCGATACCGTTCATGGTTTCAGGTGTATGTTAGCCGTAAAATACTTGCAGTTAGTAGAATCTACGTATTCACCAGATACGCTTGGGTACGATCTTATCCGAGATTTAATTTCCGTCGTCCGTGCAAAAAACTATGTCGAAGCGTCCCGCCGATATAGTCATTTCCACTCCCGCATCGAAGGTACGTCGCCGTCTCAATTTCGACAGCCCTTACACGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAGGAGAACATGGTCCAACAGGCCCATGTACAGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLVNEFPDTVHGFRCMLAVKYLQLVESTYSPDTLGYDLIRDLISVVRAKNYVEASRRYSHFHSRIEGTSPSQFRQPLHEPCCCPHCPRHQQKENMVQQAHVQEAQNVQNVQKP |
|
NCBI Accession
|
YP_001718625.1
|
|
Location
|
290-1063 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCCGCCGATATAGTCATTTCCACTCCCGCATCGAAGGTACGTCGCCGTCTCAATTTCGACAGCCCTTACACGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAGGAGAACATGGTCCAACAGGCCCATGTACAGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGATGTGCCCAAAGGTTGTGAAGGCCCATGTAAGGTCCAATCGTATGAACAGAGGCACGACATATCCCATGTTGGTAAAGTATTATGTGTTAGTGATGTCACTCGTGGCAGTGGGCTTACCCATCGAGTTGGTAAGAGATTCTGTGTGAAGTCCGTCTATGTATTGGGTAAAATATGGATGGATGAAAATATCAAAACCAAGAACCATACGAACACTGTGATGTTTTATCTTGTTCGTGATAGAAGGCCCTATGGTACTGCTATGGAATTTGGTCAGGTGTTTAACATGTATGATAATGAGCCCAGTACTGCTACTATCAAGAATGATCTTCGAGATCGTTATCAGGTTTTAAGAAAATTCACCTCAACGGTCACAGGCGGTCAATATGCTTCTAAGGAACAGGCGTTGGTTAGGAAATTTATGAAGGTTAATAATTATGTAGTTTATAATCATCAAGAGGCTGCTAAGTATGACAATCATACTGAGAATGCCTTGTTATTGTATATGGCTTGTACTCATGCCAGTAATCCAGTGTATGCTACTTTGAAGATCAGAATCTATTTCTATGATTCTCTTCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYTSRAAAPTVLVTNKRRTWSNRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSYEQRHDISHVGKVLCVSDVTRGSGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNTVMFYLVRDRRPYGTAMEFGQVFNMYDNEPSTATIKNDLRDRYQVLRKFTSTVTGGQYASKEQALVRKFMKVNNYVVYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSLQN |
|
NCBI Accession
|
YP_001718626.1
|
|
Location
|
1060-1464 |
|
Gene Name
|
C3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTTTCGCACAGGGGAATTACTCACTGCAACTCAATGCGAGAGTGGCGTGTATACCTGGACAATCAAAAATCCCCTATATTTCAAGATCACCAAACACCACGAGAGATCATTCAACAACAACCACGACATCATAACGATCCAGATACAGTTCAACCACAACCTGAGGAAAGCGTTGGGAATACACCAGTGTTTTCTGATTTTCCAGATTTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTCTTTAAATATCAATGTATGAAGTATTTAGATAATTTGGGTGTAATCAGCATTAACAATGTAATTAGGGCAGTTTCTCATGTATTATGGAATGTATTGGAAAGAACAATCGATGTACAACTTTCAAGTATAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDFRTGELLTATQCESGVYTWTIKNPLYFKITKHHERSFNNNHDIITIQIQFNHNLRKALGIHQCFLIFQIWTRLQPQTWRFLRVFKYQCMKYLDNLGVISINNVIRAVSHVLWNVLERTIDVQLSSIIKFNLY |
|
NCBI Accession
|
YP_001718627.1
|
|
Location
|
1205-1612 |
|
Gene Name
|
C2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCAGAATTCATCACCCTCACAAGCCCATTGTACTCAGGTACCCATCAAAGTCCAACACAGAATAGCCAAGAAGAGGCCTGTTCGCAGACGGAGAGTTGATCTTCCTTGCGGTTGCTCATACTACTTCGGCATAGATTGTGCAAATCATGGATTTTCGCACAGGGGAATTACTCACTGCAACTCAATGCGAGAGTGGCGTGTATACCTGGACAATCAAAAATCCCCTATATTTCAAGATCACCAAACACCACGAGAGATCATTCAACAACAACCACGACATCATAACGATCCAGATACAGTTCAACCACAACCTGAGGAAAGCGTTGGGAATACACCAGTGTTTTCTGATTTTCCAGATTTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTCTTTAA |
|
Protein Sequence
|
MQNSSPSQAHCTQVPIKVQHRIAKKRPVRRRRVDLPCGCSYYFGIDCANHGFSHRGITHCNSMREWRVYLDNQKSPIFQDHQTPREIIQQQPRHHNDPDTVQPQPEESVGNTPVFSDFPDLDSLTTSDLAFLKSL |
|
NCBI Accession
|
YP_001718628.1
|
|
Location
|
1512-2600 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGCACCACCGAGAAAATTCCAAATAAATGCCAAAAATTATTTCCTCACATATCCACAGTGCTCTCTAACCAAAGAGGAAGCACTTTCCCAAATACAAAATATACAAACCCCAACAAATAAAAAATATATCAGAATCTGCAGAGAACTTCACGAAGATGGGAGCCCTCATCTCCACGTGCTCGTACAGTTCGAAGGGAAATACAGATGCACAAATTCACGATTCTTCGACCTTGTATCCCCTTCCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGACACTCTCGAATGGGGTGAATTCCAGATCGACGCACGATCTGCACGAGGGGGACAACAATCAGCCAATGATGCTTACGCCAAGGCGCTTAACGCAGGAAGTAAGTCGGAGGCTCTTAATGTAATTAAGGAATTAGCTCCTAAAGATTTTGTTTTACAATTTCATAATTTAAATAATAATTTAGATAGGATTTTCGCACCTCCTTTAGAGGTTTTTGTTTGTCCTTTTCTTTCTTCTTCTTTTAATCAAGTTCCAGAAGAACTTGAAGATTGGGTCTCTGAGAATGTAAGGGATGCCGCTGCGCGGCCTTGGAGACCTAAAAGTATTGTAATAGAGGGCGATAGTAGGACAGGGAAGACGATGTGGGCTAGGTCACTGGGTCCACACAATTACTTATGTGGACATCTGGACTTAAGTCCAAAGGTCTACAGTAATGATGCTTGGTACAACGTCATTGATGACGTCSACCCCCACTATCTAAAGCATTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAGTACGGGAAGCCCATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCGGGACCAACATCATCATATAAAGAGTACTTGGACGAAAATAAAAATTCAGCATTAAAAGATTGGGCACTAAAGAATGCAGAATTCATCACCCTCACAAGCCCATTGTACTCAGGTACCCATCAAAGTCCAACACAGAATAGCCAAGAAGAGGCCTGTTCGCAGACGGAGAGTTGA |
|
Protein Sequence
|
MAPPRKFQINAKNYFLTYPQCSLTKEEALSQIQNIQTPTNKKYIRICRELHEDGSPHLHVLVQFEGKYRCTNSRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDARSARGGQQSANDAYAKALNAGSKSEALNVIKELAPKDFVLQFHNLNNNLDRIFAPPLEVFVCPFLSSSFNQVPEELEDWVSENVRDAAARPWRPKSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVXPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDENKNSALKDWALKNAEFITLTSPLYSGTHQSPTQNSQEEACSQTES |
|
NCBI Accession
|
YP_001718629.1
|
|
Location
|
2153-2443 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCACGTGCTCGTACAGTTCGAAGGGAAATACAGATGCACAAATTCACGATTCTTCGACCTTGTATCCCCTTCCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGACACTCTCGAATGGGGTGAATTCCAGATCGACGCACGATCTGCACGAGGGGGACAACAATCAGCCAATGATGCTTACGCCAAGGCGCTTAACGCAGGAAGTAAGTCGGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MGALISTCSYSSKGNTDAQIHDSSTLYPLPGQHISIRTFRELNQAPTSSPISTRTETLSNGVNSRSTHDLHEGDNNQPMMLTPRRLTQEVSRRLLM |