Tomato leaf curl Mali virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000841705.1 |
| Isolate | Mali |
| Release date | 2015/2/12 |
| Submitter | Zhou,Y.C., Noussourou,M., Kon,T., Rojas,M.R., Jiang,H., Chen,L.F., Gamby,K., Foster,R., Gilbertson,R.L., Zhou,Y., Chen,L. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
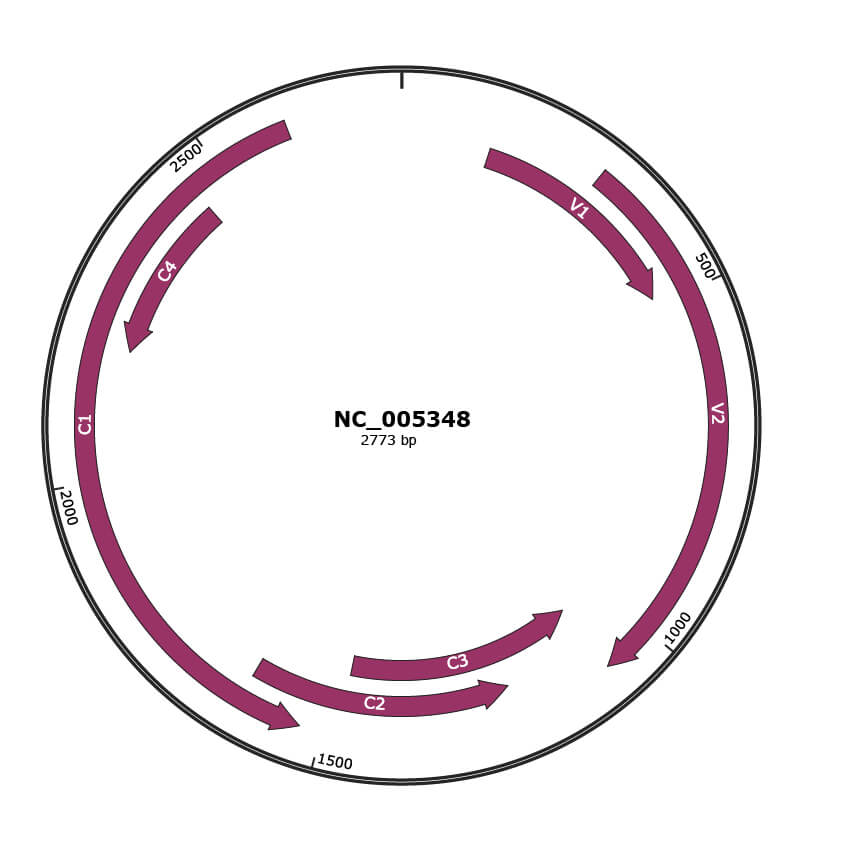
JBrowse
Genome
NC_005348
Gene Information
| NCBI Accession | NP_958316.1 |
|---|---|
| Location | 138-488 |
| Gene Name | V1 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCATTATTGAATGAATTCCCTGAATCAGTACATGGGTTTCGATGTATGCTGGCCATAAAATATTTGCAGGCCATAGAGGAAACATACGAGCCCAATACATTGGGTTACGATTTAATTCGTGATCTCATATCAGTAGTTAGGGCCTCCAACTATGTTGAAGCGACCCGCCGATATATTCATTTCCACTCCCGCCTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCATACTCCAGCCGTGCTGTTGTCCCCACTGTCCGAGGCACAAGCAAGCGTCAACTATGGACGTACCGGCCCATGTACCGAAAGCCCAAGTTTTACAAAATGTACAGAAGTCCTGA |
| Protein Sequence | MWDPLLNEFPESVHGFRCMLAIKYLQAIEETYEPNTLGYDLIRDLISVVRASNYVEATRRYIHFHSRLEGSSKTELRQPILQPCCCPHCPRHKQASTMDVPAHVPKAQVLQNVQKS |
| NCBI Accession | NP_958317.1 |
|---|---|
| Location | 298-1074 |
| Gene Name | V2 |
| Protein Name | coat protein |
| Coding Region | ATGTTGAAGCGACCCGCCGATATATTCATTTCCACTCCCGCCTCGAAGGTTCGTCGAAAACTGAACTTCGACAGCCCATACTCCAGCCGTGCTGTTGTCCCCACTGTCCGAGGCACAAGCAAGCGTCAACTATGGACGTACCGGCCCATGTACCGAAAGCCCAAGTTTTACAAAATGTACAGAAGTCCTGATGTACCACGGGGATGTGAAGGTCCATGTAAGATCCAGTCGTATGAGCAAAGGGATGACGTGAAGCATACCGGTATTGTACGTTGTGTTAGTGATATAACTCGTGGTCCTGGTTTGACTCATAGAACAGGGAAGAGATTCTGTATCAAGTCCATGTATATATTGGGTAAGATTTGGATGGATGAGAACATTAAGAAGACGAATCACACTAACAATGTCATGTTCTACTTGGTCCGTGATAGAAGGCCCTATGGAAAAAGCCCAATGGATTTTGGACAGGTTTTCAATATGTTTGACAATGAGCCCAGTACTGCCACTGTGAAGAATGATCTCCGTGATAGATATCAAGTACTTAGGAAGTTTCATGCTACCGTTACGGGTGGACCCTCTGGAGTGAAGGAACAGGCATTAGTGAAAAGATTTTATAGGCTTAATAGTCATGTAGTGTATAACCATCAGGAAGAGGCTAAATATGAGAATCATACAGAGAATGCGTTGTTATTGTATATGGCATGTACTCATGCTTCTAACCCAGTGTATGCTACCCTTAAAATACGCATCTATTTCTATGATGCAGTTACGAATTAA |
| Protein Sequence | MLKRPADIFISTPASKVRRKLNFDSPYSSRAVVPTVRGTSKRQLWTYRPMYRKPKFYKMYRSPDVPRGCEGPCKIQSYEQRDDVKHTGIVRCVSDITRGPGLTHRTGKRFCIKSMYILGKIWMDENIKKTNHTNNVMFYLVRDRRPYGKSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVLRKFHATVTGGPSGVKEQALVKRFYRLNSHVVYNHQEEAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
| NCBI Accession | NP_958318.1 |
|---|---|
| Location | 1071-1475 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTTACGCACAGGGGAACACATCACTGCTCTTCAAGCTCAGAGTGGCGTGTTTATCTGGGAGCTCAACAATCCCCTATATTTCAAGATAATAAAACACATCAGCCGACCATTCAACAGGAACCACGACATGATATCAGACCAAATCAGGTTCAACCACAACCTCAGGAAAGAGTTGGGGATTCACAAGTGTTATCTGAACTTCCAGATCTGGACGACCTTACGGCCTCAGACTGGTCATTTCTTAAGGGTCTTTAAGACCCAAATAATTAAATATTTAGATAATTTGAATGTAATTTCTATTAATAATATCATTAGGGCAGTCAACCATGTATTGTACAATATTCTTGAAAACATTATTGATGTATCAGAAAATCATGAAATAAAATTTAATATTTATTAA |
| Protein Sequence | MDLRTGEHITALQAQSGVFIWELNNPLYFKIIKHISRPFNRNHDMISDQIRFNHNLRKELGIHKCYLNFQIWTTLRPQTGHFLRVFKTQIIKYLDNLNVISINNIIRAVNHVLYNILENIIDVSENHEIKFNIY |
| NCBI Accession | NP_958319.1 |
|---|---|
| Location | 1216-1623 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCGACCTTCGTCACCCTCACAGAGCCATTGTTCTCCAACGCCAATCAAGGTTCTCCACAAACAAGCCAAGAAGAAACCGATCAGGCGTAGACGAGTAGACCTCAACTGCGGGTGCTCATACTATCTACACATTAACTGCACCAACCATGGATTTACGCACAGGGGAACACATCACTGCTCTTCAAGCTCAGAGTGGCGTGTTTATCTGGGAGCTCAACAATCCCCTATATTTCAAGATAATAAAACACATCAGCCGACCATTCAACAGGAACCACGACATGATATCAGACCAAATCAGGTTCAACCACAACCTCAGGAAAGAGTTGGGGATTCACAAGTGTTATCTGAACTTCCAGATCTGGACGACCTTACGGCCTCAGACTGGTCATTTCTTAAGGGTCTTTAA |
| Protein Sequence | MRPSSPSQSHCSPTPIKVLHKQAKKKPIRRRRVDLNCGCSYYLHINCTNHGFTHRGTHHCSSSSEWRVYLGAQQSPIFQDNKTHQPTIQQEPRHDIRPNQVQPQPQERVGDSQVLSELPDLDDLTASDWSFLKGL |
| NCBI Accession | NP_958320.1 |
|---|---|
| Location | 1532-2611 |
| Gene Name | C1 |
| Protein Name | replication associated protein C1 |
| Coding Region | ATGCCTAGAGCCGGTCGTTTTAGTATTAAAGCCAAGAATTACTTCCTCACTTATCCCCAATGCTCTCTTACTAAAAAAGAGGCACTTTCTCAATTACAGAACCTACAGACTCCCACAAATAAAAAATTCATTAAAATCTGTAGAGAACTCCACGAAGATGGGGAACATCATCTCCACGTGCTTATCCAATTCGAGGGTAAATACAACTGCACAAATCAACGATTCTTCGACCTGGTATCCCCAACCCGGTCAGCACATTTCCATCCGAATGTACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGATAAGGACGGAGACACTCTCGAATGGGGAGAATTCCAAATTGACGGCAGATCTGCTAGAGGAGGCTGCCAAACAGCTAACGACGCAGCCGCCGAGGCATTAAATGCAGGTTCAACTGAAGCTGCTTTAGCTATAATTAAAGAAAAACTCCCAAAAGATTATATATTTCAATATCATAATTTAAAATCCAATTTAGATAGAATCTTCCAGGAACCTCCTGAAGTATATGTATCCCCTTTTTCTTCTTCTTCTTTTACTCAAGTTCCAGACGAACTTGAAGAGTGGGTGGCAGATAATATAAGAGATTCCGCTGCGCGGCCATGGAGACCCAAGAGTATAGTCTTAGAGGGTGACAGTCGGACCGGCAAAACTGTATGGGCCCGTTCTCTGGGTCCACATAATTATTTATGTGGGCACCTAGACTTAAGCCCAAAGGTGTACTCCAATAACGCATGGTATAACGTCATTGATGATGTCGACCCACATTATTTAAAGCATTTTAAAGAGCTGATGGGGGCCCAAAGAGACTGGCAAAGCAACACAAAATACGGAAAGCCAGTTCAAATTAAAGGGGGCATTCCCAGTATTTTCCTCTGCAATCCAGGGGCAACTTCATCATATAAGGAATTTCTAGACGAGGAAAAAAACAGAGCACTGAAGGCTTGGGCAGTAAAAAATGCGACCTTCGTCACCCTCACAGAGCCATTGTTCTCCAACGCCAATCAAGGTTCTCCACAAACAAGCCAAGAAGAAACCGATCAGGCGTAG |
| Protein Sequence | MPRAGRFSIKAKNYFLTYPQCSLTKKEALSQLQNLQTPTNKKFIKICRELHEDGEHHLHVLIQFEGKYNCTNQRFFDLVSPTRSAHFHPNVQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQTANDAAAEALNAGSTEAALAIIKEKLPKDYIFQYHNLKSNLDRIFQEPPEVYVSPFSSSSFTQVPDELEEWVADNIRDSAARPWRPKSIVLEGDSRTGKTVWARSLGPHNYLCGHLDLSPKVYSNNAWYNVIDDVDPHYLKHFKELMGAQRDWQSNTKYGKPVQIKGGIPSIFLCNPGATSSYKEFLDEEKNRALKAWAVKNATFVTLTEPLFSNANQGSPQTSQEETDQA |
| NCBI Accession | NP_958321.1 |
|---|---|
| Location | 2197-2454 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACATCATCTCCACGTGCTTATCCAATTCGAGGGTAAATACAACTGCACAAATCAACGATTCTTCGACCTGGTATCCCCAACCCGGTCAGCACATTTCCATCCGAATGTACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGATAAGGACGGAGACACTCTCGAATGGGGAGAATTCCAAATTGACGGCAGATCTGCTAGAGGAGGCTGCCAAACAGCTAACGACGCAGCCGCCGAGGCATTAA |
| Protein Sequence | MGNIISTCLSNSRVNTTAQINDSSTWYPQPGQHISIRMYRELNPAPTSSPISIRTETLSNGENSKLTADLLEEAAKQLTTQPPRH |
References More References in PubMed
| 1 |
Ouattara A, et al. Arch Virol. 2017 May;162(5):1427-1429. doi: 10.1007/s00705-017-3231-6. Epub 2017 Feb 4. PMID: 28161765 |
|---|---|
| 2 |
Díaz-Pendón JA, et al. Mol Plant Pathol. 2010 Jul;11(4):441-50. doi: 10.1111/j.1364-3703.2010.00618.x. PMID: 20618703 |
| 3 |
Chen LF, et al. Mol Plant Pathol. 2009 May;10(3):415-30. doi: 10.1111/j.1364-3703.2009.00541.x. PMID: 19400843 |
| 4 |
Zhou YC, et al. Arch Virol. 2008;153(4):693-706. doi: 10.1007/s00705-008-0042-9. Epub 2008 Feb 16. PMID: 18278427 |
| 5 |
Lett JM, et al. Arch Virol. 2009;154(3):535-40. doi: 10.1007/s00705-009-0313-0. Epub 2009 Feb 3. PMID: 19189198 |
| 6 |
Osei MK, et al. Plant Dis. 2008 Nov;92(11):1585. doi: 10.1094/PDIS-92-11-1585B. PMID: 30764452 |
| 7 |
First Report of a Begomovirus Associated with Tomato Yellow Leaf Curl Disease in Ethiopia. Shih SL, et al. Plant Dis. 2006 Jul;90(7):974. doi: 10.1094/PD-90-0974A. PMID: 30781051 |
| 8 |
Kon T, et al. J Gen Virol. 2009 Apr;90(Pt 4):1001-1013. doi: 10.1099/vir.0.008102-0. Epub 2009 Mar 4. PMID: 19264648 |
| 9 |
A new monopartite begomovirus infecting Melochia tomentosa in Burkina Faso. Ouattara A, et al. Arch Virol. 2024 Nov 7;169(12):240. doi: 10.1007/s00705-024-06167-4. PMID: 39510996 |
| 10 |
Name PE, et al. Viruses. 2025 Sep 7;17(9):1222. doi: 10.3390/v17091222. PMID: 41012650 |