Tomato leaf curl Java virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000842305.1 |
| Isolate | Indonesia |
| Release date | 2015/2/12 |
| Submitter | Kon,T., Hidayat,S.H., Hase,S., Takahashi,H., Ikegami,M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
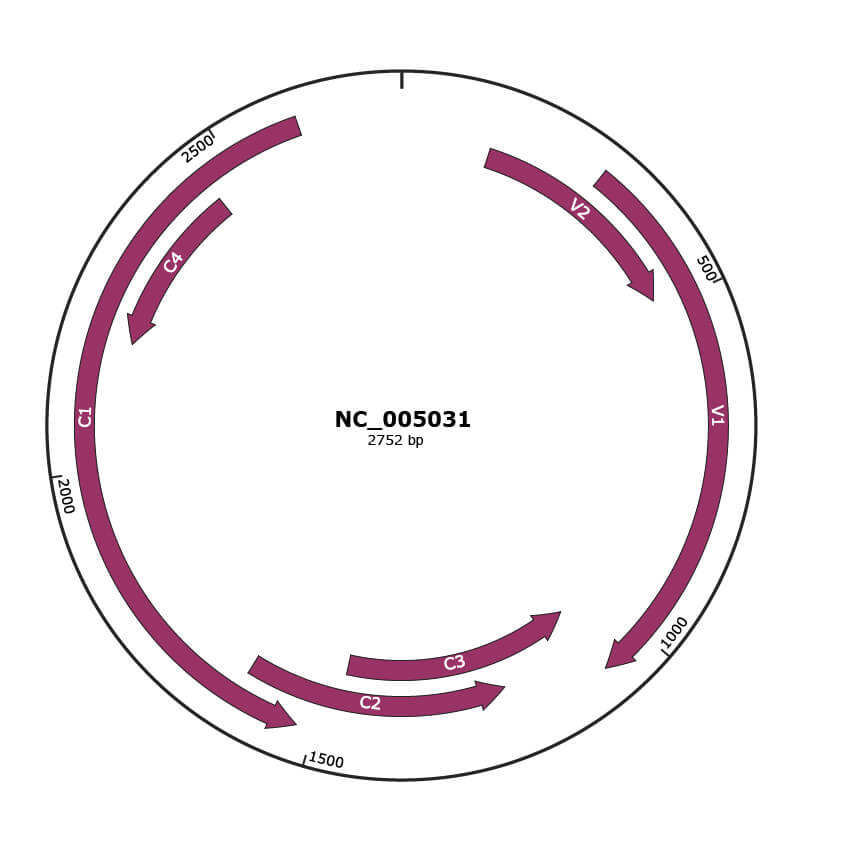
JBrowse
Genome
NC_005031
Gene Information
| NCBI Accession | NP_871716.1 |
|---|---|
| Location | 137-487 |
| Gene Name | V2 |
| Protein Name | V2 protein |
| Coding Region | ATGTGGGATCCCCTCGTAAACGAATTCCCAGAGACTGTTCACGGTCTACGGTGTATGCTAGCCGTAAAATATCTTCAATTAGTTGAAGCTACGTATTCTCCTGATACGATTGGGTACGATCTTGTACGCGATTTAATTTCAGTAATTCGTGCTCGCAATTATGTCGAAGCGTCCCGCCGATATAGTCATTTCCACTCCCGCCTCGAAGGTACGTCGTCGTCTGAACTTCGACACACCCGCGATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAGAAGGACATGGACCAACAGGCCCATGTATCGCAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLVNEFPETVHGLRCMLAVKYLQLVEATYSPDTIGYDLVRDLISVIRARNYVEASRRYSHFHSRLEGTSSSELRHTRDEPCCCPHCPRHQQKKDMDQQAHVSQAQNVQNVQKP |
| NCBI Accession | NP_871717.1 |
|---|---|
| Location | 297-1070 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGTCCCGCCGATATAGTCATTTCCACTCCCGCCTCGAAGGTACGTCGTCGTCTGAACTTCGACACACCCGCGATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACCAACAAAAGAAGGACATGGACCAACAGGCCCATGTATCGCAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGATGTGCCCAAAGGTTGTGAAGGCCCATGTAAGGTCCAGTCTTTTGAGTCTAGACACGATGTTAGTCACGTGGGTAAGGTCTGTTGTATAACTGACGTCACTAGGGGTTTAGGTTTGACACATAGGACGGGTAAGAGGTTTTGCGTTAAGTCCGTCTACATAATGGGCAAGGTCTGGATGGATGAGAATATCAAGACCAAGAATCACACTAACACAGTTATGTTTTTTCTAGTCCGTGATCGAAGACCTTATTCAAGTCCTCAGGATTTTGGTCAGGTGTTTAACATGTATGACAATGAGCCAAGTACAGCTACTGTCAAGAACGATATGCGAGATCGTTTTCAGGTCTTACGGAAATTCACATCAACTGTTACTGGTGGTCAGTATGCATGCAAGGAGCAGTCTCTCGTCAAACGTTTTTTTAGAGTTAATAATCATGTAGTTTATAATCATCAAGAGGCGGGAAAGTATGAGAACCATACTGAGAACGCTCTTTTATTATATATGGCTTGTACTCATGCCAGTAACCCAGTGTATGCTACTTTGAAAATCAGAATCTATTTCTATGATTCTGTTCAAAATTAA |
| Protein Sequence | MSKRPADIVISTPASKVRRRLNFDTPAMSRAAAPTVLVTNKRRTWTNRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSFESRHDVSHVGKVCCITDVTRGLGLTHRTGKRFCVKSVYIMGKVWMDENIKTKNHTNTVMFFLVRDRRPYSSPQDFGQVFNMYDNEPSTATVKNDMRDRFQVLRKFTSTVTGGQYACKEQSLVKRFFRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
| NCBI Accession | NP_871718.1 |
|---|---|
| Location | 1067-1471 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTTACGCACAGGGGAATTACTCACTGCAACTCAATGCGAGAGTGGCGTGTATACCTGGACGATCAAAAATCCCCTCTATTTCAAGATAATCAAGCACCACGAGAGAATATTCAACACCAACCACGACGTCATAACGATCCGAATACAGTTCAATCACAACCTGAGGAAAGCGTTGGGAATACACCAGTGTTTTCTGATCTTCCAGATCTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTATTTAGGGTTCAATGTATGAAATATTTAGATAATTTGGGTGTAATTAGTATTAACAATGTAATTAGAGCATGTGATCATGTTTTATGGGATGTATTGGAAAACACAGAATATGTAACACAATCTCATATAATAAAATTTAATCTTTATTAA |
| Protein Sequence | MDLRTGELLTATQCESGVYTWTIKNPLYFKIIKHHERIFNTNHDVITIRIQFNHNLRKALGIHQCFLIFQIWTRLQPQTWRFLRVFRVQCMKYLDNLGVISINNVIRACDHVLWDVLENTEYVTQSHIIKFNLY |
| NCBI Accession | NP_871719.1 |
|---|---|
| Location | 1212-1619 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCAGAATTCGTCACCCTCAACAGCCCATTGTACTCAGGTACCAATCAAAGTGCAACACAGAATAGCCAAGAGGAGGCCAGTTCGCAGGCGTAGAATTGATCTAACGTGCGGGTGTTCTTACTACTTCGGAATAGACTGTGCAAATCATGGATTTACGCACAGGGGAATTACTCACTGCAACTCAATGCGAGAGTGGCGTGTATACCTGGACGATCAAAAATCCCCTCTATTTCAAGATAATCAAGCACCACGAGAGAATATTCAACACCAACCACGACGTCATAACGATCCGAATACAGTTCAATCACAACCTGAGGAAAGCGTTGGGAATACACCAGTGTTTTCTGATCTTCCAGATCTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTATTTAG |
| Protein Sequence | MQNSSPSTAHCTQVPIKVQHRIAKRRPVRRRRIDLTCGCSYYFGIDCANHGFTHRGITHCNSMREWRVYLDDQKSPLFQDNQAPRENIQHQPRRHNDPNTVQSQPEESVGNTPVFSDLPDLDSLTTSDLAFLKSI |
| NCBI Accession | NP_871720.1 |
|---|---|
| Location | 1525-2607 |
| Gene Name | C1 |
| Protein Name | replication initiation protein |
| Coding Region | ATGGCACCTCCCAAACGTTTTTTAATAAATGCCAAAAATTATTTCCTCACATACCCACAGTGCTCTCTCACTAAAGAAGAAGCACTTTCCCAATTACAAAACCTAAACACCCCAACAAATAAAAAATTCATCAAAATCTGCAGAGAACTCCATGAAGATGGGAGCCCTCATCTGCACGTGCTTATCCAGTTCGAAGGGAAATTCAAGTGCCAAAATAACAGATTCTTCGACCTTACATCCCCTACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCTTATATCGACAAGGACGGAGACACACTGGAATGGGGAGAATTCCAGGTCGACGGAAGAAGTGCTCGAGGAGGTCAACAGACGGCTAACGACACAGCTGCAAAGGCCCTAAATTCAGGTTCAGCCGAAGCAGCTTTAGCTATTATTAGAGAGGAGCTCCCTAAAGATTTTATTTTTCAATATCATAATATTAAAGCTAATTTAGATAGGATTTTTACACCTCGTGCAGAGGTTTTTGTTTGTCCATTTCTTTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAGTGCTGGGTTTCCGAAAACGTAAGGGATGCCGCTGCGCGGCCATGGAGACCTGTTAGTATTGTCATAGAGGGTGAGAGCCGTACAGGGAAGACGATGTGGGCTCGTTCTTTAGGCCCACATAATTATTTGTGCGGTCATTTAGATCTGAGCCCAAAGGTATACAGCAATGATGCCTGGTACAACGTCATTGATGACGTCGACCCCCACTACTTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAGTACGGGAAACCAATTCAAATTAAAGGTGGAATCCCAACTATCTTCCTTTGCAATCCAGGCCCAACATCATCATATAAAGAGTACTTGGACGAAGAGAAGAATTCGGCATTAAAAGAGTGGGCTATAAAGAATGCAGAATTCGTCACCCTCAACAGCCCATTGTACTCAGGTACCAATCAAAGTGCAACACAGAATAGCCAAGAGGAGGCCAGTTCGCAGGCGTAG |
| Protein Sequence | MAPPKRFLINAKNYFLTYPQCSLTKEEALSQLQNLNTPTNKKFIKICRELHEDGSPHLHVLIQFEGKFKCQNNRFFDLTSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQVDGRSARGGQQTANDTAAKALNSGSAEAALAIIREELPKDFIFQYHNIKANLDRIFTPRAEVFVCPFLSSSFDQVPEELECWVSENVRDAAARPWRPVSIVIEGESRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKNSALKEWAIKNAEFVTLNSPLYSGTNQSATQNSQEEASSQA |
| NCBI Accession | NP_871721.1 |
|---|---|
| Location | 2193-2456 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGAAGATGGGAGCCCTCATCTGCACGTGCTTATCCAGTTCGAAGGGAAATTCAAGTGCCAAAATAACAGATTCTTCGACCTTACATCCCCTACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCTTATATCGACAAGGACGGAGACACACTGGAATGGGGAGAATTCCAGGTCGACGGAAGAAGTGCTCGAGGAGGTCAACAGACGGCTAACGACACAGCTGCAAAGGCCCTAA |
| Protein Sequence | MKMGALICTCLSSSKGNSSAKITDSSTLHPLPGQHISIRTFRELNQAPTSSLISTRTETHWNGENSRSTEEVLEEVNRRLTTQLQRP |
References More References in PubMed
| 1 |
Complete Genome Sequence of Tomato Leaf Curl New Delhi Virus from Luffa in Indonesia. Wilisiani F, et al. Microbiol Resour Announc. 2019 Apr 11;8(15):e01605-18. doi: 10.1128/MRA.01605-18. PMID: 30975814 |
|---|---|
| 2 |
Kesumawati E, et al. Arch Virol. 2019 Sep;164(9):2379-2383. doi: 10.1007/s00705-019-04316-8. Epub 2019 Jun 15. PMID: 31203434 |
| 3 |
Díaz-Pendón JA, et al. Mol Plant Pathol. 2010 Jul;11(4):441-50. doi: 10.1111/j.1364-3703.2010.00618.x. PMID: 20618703 |
| 4 |
Koeda S, et al. Plant Dis. 2020 Dec;104(12):3221-3229. doi: 10.1094/PDIS-03-20-0613-RE. Epub 2020 Oct 12. PMID: 33044916 |
| 5 |
First Report of Tomato leaf curl New Delhi virus Infecting Cucumber in Central Java, Indonesia. Mizutani T, et al. Plant Dis. 2011 Nov;95(11):1485. doi: 10.1094/PDIS-03-11-0196. PMID: 30731770 |
| 6 |
Sharma P, et al. Virology. 2010 Jan 5;396(1):85-93. doi: 10.1016/j.virol.2009.10.012. Epub 2009 Nov 6. PMID: 19896687 |
| 7 |
Suppressor of RNA silencing encoded by the monopartite tomato leaf curl Java begomovirus. Kon T, et al. Arch Virol. 2007;152(7):1273-82. doi: 10.1007/s00705-007-0957-6. Epub 2007 Mar 26. PMID: 17385070 |
| 8 |
Shahid MS, et al. Viruses. 2014 Jan 14;6(1):189-200. doi: 10.3390/v6010189. PMID: 24424499 |
| 9 |
Kon T, et al. Arch Virol. 2007;152(6):1147-57. doi: 10.1007/s00705-006-0928-3. Epub 2007 Feb 12. PMID: 17294343 |
| 10 |
Sakata JJ, et al. Arch Virol. 2008;153(12):2307-13. doi: 10.1007/s00705-008-0254-z. Epub 2008 Nov 18. PMID: 19015934 |