Tomato leaf curl Iran virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000845745.1 |
| Isolate | Iran: Iranshahr |
| Release date | 2015/2/12 |
| Submitter | Behjatnia,A., Izadpanah,K., Dry,I.B., Rezaian,A. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
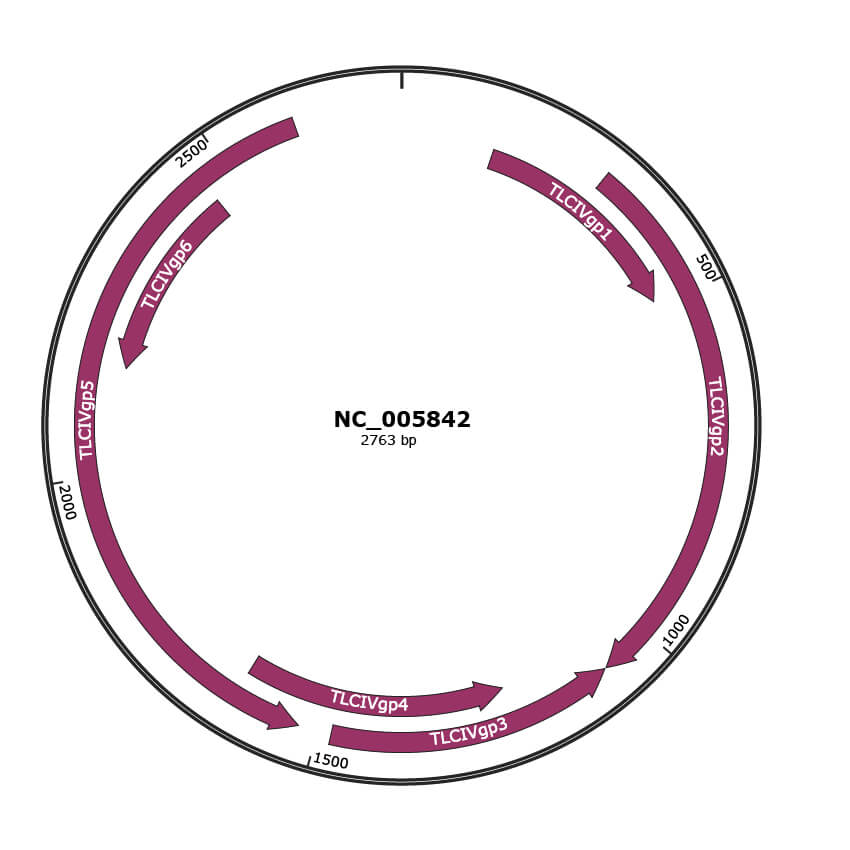
JBrowse
Genome
NC_005842
Gene Information
| NCBI Accession | YP_006422.1 |
|---|---|
| Location | 143-490 |
| Protein Name | V1 protein |
| Coding Region | ATGTGGGATCCATTGTTAAACGAGTTTCCCGAAACCGTTCACGGTTTTAGATGTATGTTAGCAGTTAAATATCTGCAGTTAGCAGAAAAGACTTATTCCCCTGACACATTAGGTTACGATTTAATTAGGGATTTAATTTCAGTAATTAGGGCTAGAAATTATGTCGAAGCGTCCAGCAGATATAATCATTTCCACGCCCGTTTCGAAGGTACGCCGTCGTCTCAGCTTCGACAGCCCATATGTGAACCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAGGCAAAGGCATGGGCGAACAGGCCCATGTACCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPETVHGFRCMLAVKYLQLAEKTYSPDTLGYDLIRDLISVIRARNYVEASSRYNHFHARFEGTPSSQLRQPICEPCCCPHCPRHQGKGMGEQAHVPEAQNVQDVQKP |
| NCBI Accession | YP_006423.1 |
|---|---|
| Location | 303-1073 |
| Protein Name | V2 protein |
| Coding Region | ATGTCGAAGCGTCCAGCAGATATAATCATTTCCACGCCCGTTTCGAAGGTACGCCGTCGTCTCAGCTTCGACAGCCCATATGTGAACCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAGGCAAAGGCATGGGCGAACAGGCCCATGTACCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCCAAGGGATGTGAAGGCCCATGTAAGGTCCAATCTTTCGATGCTAAGAACGATATTGGTCATATGGGTAAGGTTATATGTTTGTCTGATGTCACGAGGGGAATGGGTTTGACCCATCGAGTAGGGAAACGTTTCTGTGTGAAGTCTTTGTATTTTGTCGGCAAGATTTGGATGGACGAGAACATCAAAACCAAGAACCATACTAATACTGTTTTGTTCTGGATTGTGAGAGACAGGCGTCCTACAGGAACCCCAAATGATTTCCAACAAGTGTTCAATGTTTATGATAATGAGCCTTCTACGGCTACTGTGAAGAACGACCAGCGTGATCGTTTTCAGGTGCTGAGGAGGTTTCAAGCAACAGTCACAGGCGGTCAATATGCTGCTAAGGAACAAGCTATAATTAGGAAGTTCTATCGTGTTAATAACTATGTGGTTTATAATCATCAAGAAGCTGGGAAGTATGAGAATCACACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACTTTGAAAGTTAGGAGTTACTTCTACGATTCTGTAACAAATTAA |
| Protein Sequence | MSKRPADIIISTPVSKVRRRLSFDSPYVNRAAAPIVRVTKAKAWANRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSFDAKNDIGHMGKVICLSDVTRGMGLTHRVGKRFCVKSLYFVGKIWMDENIKTKNHTNTVLFWIVRDRRPTGTPNDFQQVFNVYDNEPSTATVKNDQRDRFQVLRRFQATVTGGQYAAKEQAIIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
| NCBI Accession | YP_006424.1 |
|---|---|
| Location | 1076-1480 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAAGCAGAGAATGGCGTGTTTATCTGGGAGATTCAAAATCCCCTATATTTCAAGATAACAGAACACCACAACCGGCCATTCCTGATGAACCAAGACATCATCACCGTCCAAGTACAGTTCAATCACAACCTGAGGAAAGTGTTGGGGATACACAAATGTTTCCTAGTCTACCGAATCTGGATGACATCACAGCCTCCGACTGGTCGTTTCTTAAGGGTATTTAAGACCCAAATACTTAAGTATTTAAATAATTTAAGAGTTATAAGTATTAACAATGTAAATAGAGCAGTTGATCATGTATTATGGAATGTATTACACCACGTTGTATATGTAGACCAATCATATTCAATAAAATTCAATCTTTATTAA |
| Protein Sequence | MDSRTGELITAAQAENGVFIWEIQNPLYFKITEHHNRPFLMNQDIITVQVQFNHNLRKVLGIHKCFLVYRIWMTSQPPTGRFLRVFKTQILKYLNNLRVISINNVNRAVDHVLWNVLHHVVYVDQSYSIKFNLY |
| NCBI Accession | YP_006425.1 |
|---|---|
| Location | 1221-1625 |
| Protein Name | C2 protein |
| Coding Region | ATGCGATCTTCGTCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAACACAGGCTAGCCAAGAGAGGGACCAGGCGTCGACGAGTTGATCTACCGTGTGGCTGCTCTTACTTCATAGCATTAGCCTGCCACGACCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAAGCAGAGAATGGCGTGTTTATCTGGGAGATTCAAAATCCCCTATATTTCAAGATAACAGAACACCACAACCGGCCATTCCTGATGAACCAAGACATCATCACCGTCCAAGTACAGTTCAATCACAACCTGAGGAAAGTGTTGGGGATACACAAATGTTTCCTAGTCTACCGAATCTGGATGACATCACAGCCTCCGACTGGTCGTTTCTTAAGGGTATTTAA |
| Protein Sequence | MRSSSPSKAHSTQVPIKVQHRLAKRGTRRRRVDLPCGCSYFIALACHDHGFTHRGTHHCSSSREWRVYLGDSKSPIFQDNRTPQPAIPDEPRHHHRPSTVQSQPEESVGDTQMFPSLPNLDDITASDWSFLKGI |
| NCBI Accession | YP_006426.1 |
|---|---|
| Location | 1528-2613 |
| Protein Name | C1 protein |
| Coding Region | ATGGCAGCCCCCAATCGGTTTAAAATAAATGCCAAAAATTATTTTCTCACTTTTCCCAAATGCTCTCTAACTAAAGAAGAGGCACTTTCCCAATCATTAAATCTACAAACACCCACTTCCAAAAAATTTATTAGAATTTGCAGAGAGCTTCATGAAGATGGGACTCCTCACTTGCATGTGCTCATCCAGTTCGAAGGAAAGTTCCAGTGCAAAAACAACAGATTCTTCGACCTCACATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGTTCAAGCGATGTCAAATCCTATATGGAAAAAGACGGAGACGTCATTGATCATGGAGTTTTCCAAGTCGATGGACGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAAGCTCAGGCCCTCAATATACTGAAGGAGAAAGCTCCTAGAGACTTTCTACTTCAATTTCATAATTTAAATTCAAATTTAGATAGATATTTTCAGGAGCCACCAGCTCCTTATGTTTCACCTTTTTCTTCCTCTTCATTCGATCAAGTTCCAGTAGAACTTGAAGAGTGGGCTTGCGAAAATATTGCCGATACCACTGCGCGGCCCATTAGGCCCATAAGTATTGTTATTGAGAGTGATAGTCGTACTGGTAAAACAATGTGGGCTAGGTCGTTGGGTCCACATAATTATCTATGTGGTCATCTAGACCTTAGCCCAAAAATCTACAGTAATGATGCCTGGTACAACATCATTGATGACGTCGATCCCCACTATCTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGAGAATGGCAATCAAATACAAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCCAACTCCAGTTATAAAGAGTTCTTGGATGAAGACAAGAATTTTGCACTTAAAAACTGGGCTTTGAAGAATGCGATCTTCGTCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAACACAGGCTAGCCAAGAGAGGGACCAGGCGTCGACGAGTTGA |
| Protein Sequence | MAAPNRFKINAKNYFLTFPKCSLTKEEALSQSLNLQTPTSKKFIRICRELHEDGTPHLHVLIQFEGKFQCKNNRFFDLTSPTRSAHFHPNIQGAKSSSDVKSYMEKDGDVIDHGVFQVDGRSARGGCQSANDAYAEAINSGSKAQALNILKEKAPRDFLLQFHNLNSNLDRYFQEPPAPYVSPFSSSSFDQVPVELEEWACENIADTTARPIRPISIVIESDSRTGKTMWARSLGPHNYLCGHLDLSPKIYSNDAWYNIIDDVDPHYLKHFKEFMGAQREWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEDKNFALKNWALKNAIFVTLEGPLYSGSNQSATQASQERDQASTS |
| NCBI Accession | YP_006427.1 |
|---|---|
| Location | 2163-2462 |
| Protein Name | C4 protein |
| Coding Region | ATGAAGATGGGACTCCTCACTTGCATGTGCTCATCCAGTTCGAAGGAAAGTTCCAGTGCAAAAACAACAGATTCTTCGACCTCACATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGTTCAAGCGATGTCAAATCCTATATGGAAAAAGACGGAGACGTCATTGATCATGGAGTTTTCCAAGTCGATGGACGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAAGCTCAGGCCCTCAATATACTGA |
| Protein Sequence | MKMGLLTCMCSSSSKESSSAKTTDSSTSHPQPGQHISIRTFRELRVQAMSNPIWKKTETSLIMEFSKSMDDQLEEVANLPTTHMPRQSIQGPKLRPSIY |
References More References in PubMed
| 1 |
Al-Matroushi AR, et al. Cell Mol Biol (Noisy-le-grand). 2024 Nov 27;70(11):101-108. doi: 10.14715/cmb/2024.70.11.15. PMID: 39707774 |
|---|---|
| 2 |
Virus-induced CRISPR-Cas9 system improved resistance against tomato yellow leaf curl virus. Ghorbani Faal P, et al. Mol Biol Rep. 2020 May;47(5):3369-3376. doi: 10.1007/s11033-020-05409-3. Epub 2020 Apr 15. PMID: 32297291 |
| 3 |
Azaryan A, et al. Plant Physiol Biochem. 2024 Dec;217:109271. doi: 10.1016/j.plaphy.2024.109271. Epub 2024 Nov 4. PMID: 39504658 |
| 4 |
First Report of Tomato leaf curl Palampur virus on Bitter Gourd in Pakistan. Ali I, et al. Plant Dis. 2010 Feb;94(2):276. doi: 10.1094/PDIS-94-2-0276A. PMID: 30754274 |
| 5 |
Natural Occurrence of Tomato leaf curl New Delhi virus in Iranian Cucurbit Crops. Yazdani-Khameneh S, et al. Plant Pathol J. 2016 Jun;32(3):201-8. doi: 10.5423/PPJ.OA.10.2015.0210. Epub 2016 Jun 1. PMID: 27298595 |
| 6 |
Ongoing geographical spread of Tomato yellow leaf curl virus. Mabvakure B, et al. Virology. 2016 Nov;498:257-264. doi: 10.1016/j.virol.2016.08.033. Epub 2016 Sep 15. PMID: 27619929 |
| 7 |
Complete sequences of tomato leaf curl Palampur virus isolates infecting cucurbits in Iran. Heydarnejad J, et al. Arch Virol. 2009;154(6):1015-8. doi: 10.1007/s00705-009-0389-6. Epub 2009 May 8. PMID: 19424773 |
| 8 |
No Evidence for Seed Transmission of Tomato Yellow Leaf Curl Sardinia Virus in Tomato. Tabein S, et al. Cells. 2021 Jul 2;10(7):1673. doi: 10.3390/cells10071673. PMID: 34359841 |
| 9 |
Esmaeili M, et al. Virus Genes. 2015 Dec;51(3):408-16. doi: 10.1007/s11262-015-1250-5. Epub 2015 Oct 3. PMID: 26433951 |
| 10 |
Localized surface plasmon resonance biosensing of tomato yellow leaf curl virus. Razmi A, et al. J Virol Methods. 2019 May;267:1-7. doi: 10.1016/j.jviromet.2019.02.004. Epub 2019 Feb 13. PMID: 30771384 |