Tomato leaf curl Hsinchu virus
Basic Information
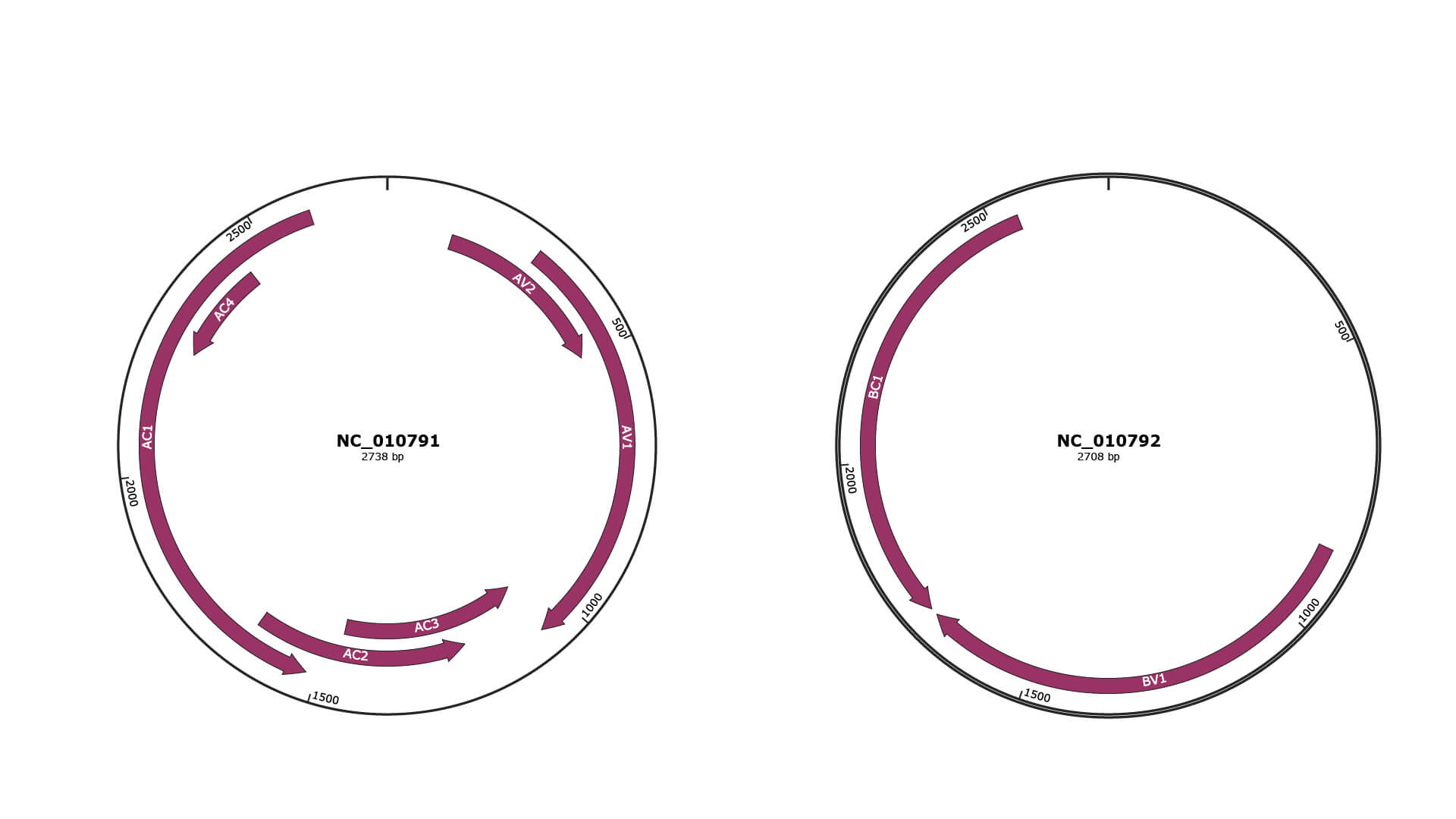
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTAGGCGGCCCCACCACGCACTCTTGTCCCCCACTCAGGACGCTCCCTCACAAGTTTATTTAGTGCGTGGTCCCCTTTAAATCACTTGGGCGCCAAGTTGTAGGCGCAAGATGTGGGATCCTTTGGTAAATGATTTCCCAGACACCGTACACGCTCTGCGTTGTATGTTAGCTATAAAATACTGTCAGCTGGTAGCAAATACATACGATCCGGATACGGTGGGATACGATCTAATACGTGATTTGATACTTGTCATACGTGCACGTAATTATGTCGAAGCGTCCCGCCGATATAGTGATTTCAACTCCCGCCTCCAAAGAACGCCGCCGGCTGAACTTCGACAGCCCCGGGATCAGCCGTGCCGCTGCCCCCACTGTCCTCGTCACAAACAGAAGGCGGGCTTGGACTTACAGGCCCATGTATCGCAAGCCCAGGATGTACAGGATGTTCAAAAGCCCAGATGTTCCACGTGGCTGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAAGCCCGTCATGATGTGGCCCATACTGGTAAGGTTATTTGTATTTCAGATGTCACTCGTGGTGGTGGGCTGACCCACCGAACAGGCAAGAGGTTCTGCGTGAAGTCCGTTTACGTATTGGGTAAGATCTGGATGGATGAGAATATCAAGGTTAAAAACCATACAAATACAGTCATGTTTTTTCTTGTTAGAGACAGGAGGCCGTATGGAACTCCCCAGGATTTTGGTCAGGTGTTCAACATGTATGACAATGAGCCCAGTACGGCCACTGTGAAGAACGATCTTAGAGATCGTTTTCAAGTGATACGTCGTTTTACTTCAACAGTTACTGGAGGCCAGTATGCGAGCAAGGAACAAGCCCTTGTCAAGAAATATATGAAGGTTAACGCTCAGGTGGTTTATAATCACCAGGAGGGTGGGAAATACGAGAATCATACTGAGAATGCTCTATTGTTGTATATGGCTTGTACACATTCTAGTAATCCCGTGTATGCAACTTTGAAAATCAGGATCTATTTTTATGATTCTGTCAGTAATTAATAAAGATTGAATTTTATTATATGTGATAACTCAGCATCAATTGTGCCGTCAAGTACATCGTACAATACATATCTAATGGCTCTAACAACATTGTTAATACTAATGATTCCTAAATTATTTAAATACTTAATACATTGATATCTAAATACATTTAAGAAACGCCAGGTCTGAGGACGTAAACGAGTCCAGATCCGGCAGGTCAGAAAACACTGGTGAATCCCCAACGCTTTCCTCAGGTTGTGGTTGAACTGGATCTGGAGTGTGATGATGTCCTTCCTTGTCAGGAATACATTCACGTCGTGGCGGACGATCTTGAAATATAGGGGATTTTTGACCGTCCAGGTATAGACGCCATTCTCTGCCTGAGTTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGCGAAGCGCATTCAAGTGCAAAGTAATATGTGCATCCGCACGGAAGGTCAACTCTACGTCTGCGAATAGCCTTCTTGGCTATTTTGTGTTGGACCTTGATTGGCACTTGAGTAGAGCGCTTCGGAGAGGAAGAAGAATTTTGCATTTTGTAATGCCCACCTTTTGAGAGCTGCATTCCGCTCCTCGTCTAAGTATTCTTTATAGGACGAAGTTGGGCCTGGATTGCAGAGGAAGATAGTGGGAATACCACCTTTAATTTGAATTGGTTTCCCGTATTTGGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTTAAGTAGTGGGGGTCTACATCATCAATCACGTTGTACCAGGCATCATTATTGTACACTCTTGGACTGAGGTCTAAGTGACCACATAGATAATTATGTGGCCCCAACGACCTGGCCCACATTGTTTTGCCAGTACGACTCTCGCCCTCGATTACAATGCTAATGGGTCTCCACGGCCGCGCAGCGGCATCTTTGATGTTATCTGCAACCCAGCACTCAATCTCCTCTGGGACTTGATCAAAGGACGATGATAAGAATGGACAATTAAATACCTCTACTGGGGGTGCAAATATTTTATCTAAATTGGCATTTAAATTATGAAACTGTAAAACATAATCTTTAGGAGCGAGCTCCTTAATTACATTAAGAGCCAGTAATTTGCTACCAGTGTTAATCGCCTGCGCGTAAGCGTCATTGGCTGATTGCTGACCCCCTCTTGCAGATCTGCCGTCTACCTGAAACTCTCCCCATTCGGCGGTGTCGCCGTCTTTTTCCATGTATTTTTTGACATCGGAGCTGGACTTAGCTCCCTGAATGTTTGGATGGAAATGTGTTGACCTGGTTGGGGATACCAGGTCGAAGAATCTGTTATTCTGGCATTTGTATTTTCCCTCGAATTGAATAAGAACATGGAGGTGAGGGCTTCCATCTTCATGAAGCTCTCTGCAAATTTTAATAAATTTTTTATTTGTTGGGGTTGAGAGGTTTAATAATTGGGAAAGTGCTTCCTCTTTGGAGAGAGGGCACTGAGGATATGTGAGAAAATAATTTTTAGCGTTTATTGTGAAACGCCTGGGAGGAGCCATGTTGACTTGGTCAATCGGGGATCAACCATCTATCCCATTCAATCGGGGAATGGGTCTCAATATATACTTGAGACCCTAATGGCATAAATGTAATTTTGGAATGAGTTAGAAATTCAATCGCGGCCATCCGTTTAATATT
TGATCAAGTCCCAGAGGAGATTGAATGCTGGGTTGCAGATATATTTATTATGTTAACATCATAACATTGAAATAAATTACAAACTACTGACCAACTAATCAATTCCCTATGGGTAATAAATGAACTTAATTAATAATTAAATATTGTGATGGTGTCCCTCATATTTATCAATTCATTTATGAACTTCAATTATTTTATATTTGGCCGCGCAGCGGCAGCGTCTTCGTTGATAGGACTATAATCAAATATATAAATCATTAATGTTAATCTGATAAACTTATCAGAAGTAGGTGAGATTGCAATATATCAGAAAGAAAATAAATTATATTTATTAATCTGTGTTTATTTTGCACGACGAGGCGTTTCCGCTCAGTTCGAAGTGTTTCCTCTCGGGAGAGAGCTATTGACTTGGTCAATCGGGGATCAACCATCTATCCCATTCAATCGGGGAATGGGGATCAATTTATACCTGATCCCCAAATGGCATAATTGTAATTTTGAAAATATTTTGAAATTTCATCGCGGCCATCCGTTTAATATTACCGGATGGCCGCGATTTTTTTTTAAAGTGGTCCCACCACGCACTCCTGTCCCTCGCTCAGGAGGCTTCCTCCCAGCTGTCCCCCACTAATTTTGGATTGCAGCGCTTTAATTTGAATGGGTTTCCCTCTAGGCGCTGCTGCTTCCACTCAGGACGCTCCTTCCCACTCAGTGCGCTCTCCGTAAATATCCCTGACATTAATGCATACGTGCATTCATCTTAACCGCTCTTAATGGACACGCGTCAGCCATTACGGGACTCATTTGAATCTTATTTTAATATATATAGGGATATTCTCTTGGTGTATCCGCATTGTGAAGTAAAATGAGAATCCCCATTAGATCTCCTGGTGGGTTTAATGTAGACCGGAGATTCACCGGTGGAGCTGTCTTCCGTCCGAATTATCCATATCGCCGATACTTCGGCAGACGGATTGGTCAGCGTGTATATGGCATGCCATACTCTAGTGGATCTCAACGTCCACGTGGTGTGCCTAATGCACGTCGCAACTTGTTTTCCGTTCATCCGGAAACAAGGAGAAAGACTCGGCAATCCATAGAGGAGGTGCAGGATGGTACAAATTACCTTCTCTGTAATAACACCTCTAAGGTGTCGTATCTTACGTACCCGGCGAAGTCTAGGTCGGAGTTCAGCAACCGGGTAGACTCATACATAAAGCTGTTAAGTTTGAGTGTATCTGGCTCTGTAATTGCCCGGCATTTGGACAGGTCGGAAGGTGCTTCCCGGAATGGAATACATGGCATATTCACGACGGTTATCGTGCGTGATAAAAAACCATGTCAGTTCTCTGCTGTGGATCCACTGATCCCATTTGCTGACGTGTTTGGACTGGAGACGGGCGCGTGTTCCACTTTGCGCGTGCGCGATCAGCATAGGGATAGATTTAGTTTAGTTTATCAGAAGAAGTGCGTGATTAATACCGCACTTCCAGAACATATTTTTAGATTTTCTTATAATGTTAGGTTTAATTCGTACCCAGTTTATGTAACATTTAAGGACACGGAGGATTCTGAACCTACTGGCCTCTATGGCAACGTGTCCAAGAATGCCCTGATAGTTTACTATGTGTGGCTGTGTGATGCCAATGTAACCTCTGAGATTCATGTAAAATATGATCTGCATTATATTGGATAAATAAAATCGCTTTTTATTTTATTGGCTTTACATTAGATGTTACATTACTGCCCTCCATACACAACTCTACAGTCTTTTTGATGATGTTTATGACATCATCATTTACAGTATTGGTGTTGCAAATAACTTCAGAAGCAGATGGGCCTGGGTCCAGTGTCCTGTCCTGTAACCTGTGCAGATTCCCATATGGTAGGTCCTCCTGTTCTTCATTCCCAACTGCACTAGCGGAGGCCCATGATTGTCCAGGTAGTATAGCTGGTGTTGTGTACCTGCTTGACTGGGACCGTAAATTCTTCAGTCCCTGTACAGGTCTCCTTGAAACCTGCGAGTGGGGCACTGACCAGAAATCAATGTTGGTCATGTTATATGCCTTGGACAGTATCTCGATCTTCGGGGATTTGAATTGTATCTCGGAGGACTGCTTAGCTGATGACATTTTCAGTTTTCCTTGCATCCTGCAGAAATGGACTCCGTCTACGACATTCGTGTCGTCTACCCTGTACATAACCTTCCAAGGATTTGGGTCTCTTGGTGAAAAATATGATGATGAGTAGTAGTGGATGTTGCAGTTACATCCAATTGGAATTGTAAACTCCGCCTGCTTGGAATCACCCTCGTATAACCTGGTATCGTGCATTTCTATAATGACATGCCCAGTGGCATTGACAGGAACCTGATTCCTATATTCAAGAACGACATGGTCTATCCTCAAGCACTTGCCCATAAGTTTTGACAATTTCTGTTCAATTGTGCTTGGGAATAACAGGGTTACCTCAGTTTTCTCACTGGATAGTTGGAATTCTGTCCTGTCAGACGTGGCATATGCCAGCGCACTTGAATTATCAGCCATGTTGTGATTGATGCATTGCTTGTTGGATTGGGCCTGCATTTATAATGGGCTACAGCCTTGCAGTGCACGAACTGGGCCTACCAGATTGAACAAATAAGTTCTGAGGCTTGGTTTATATTGGGCCACGTCATACGTGTACAGTCCATTCTTATCATCGTCCTT
Gene Information
|
NCBI Accession
|
YP_001936685.1
|
|
Location
|
132-500 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCTTTGGTAAATGATTTCCCAGACACCGTACACGCTCTGCGTTGTATGTTAGCTATAAAATACTGTCAGCTGGTAGCAAATACATACGATCCGGATACGGTGGGATACGATCTAATACGTGATTTGATACTTGTCATACGTGCACGTAATTATGTCGAAGCGTCCCGCCGATATAGTGATTTCAACTCCCGCCTCCAAAGAACGCCGCCGGCTGAACTTCGACAGCCCCGGGATCAGCCGTGCCGCTGCCCCCACTGTCCTCGTCACAAACAGAAGGCGGGCTTGGACTTACAGGCCCATGTATCGCAAGCCCAGGATGTACAGGATGTTCAAAAGCCCAGATGTTCCACGTGGCTGTGA |
|
Protein Sequence
|
MWDPLVNDFPDTVHALRCMLAIKYCQLVANTYDPDTVGYDLIRDLILVIRARNYVEASRRYSDFNSRLQRTPPAELRQPRDQPCRCPHCPRHKQKAGLDLQAHVSQAQDVQDVQKPRCSTWL |
|
NCBI Accession
|
YP_001936686.1
|
|
Location
|
292-1065 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGTCGAAGCGTCCCGCCGATATAGTGATTTCAACTCCCGCCTCCAAAGAACGCCGCCGGCTGAACTTCGACAGCCCCGGGATCAGCCGTGCCGCTGCCCCCACTGTCCTCGTCACAAACAGAAGGCGGGCTTGGACTTACAGGCCCATGTATCGCAAGCCCAGGATGTACAGGATGTTCAAAAGCCCAGATGTTCCACGTGGCTGTGAAGGCCCATGTAAGGTCCAGTCGTTTGAAGCCCGTCATGATGTGGCCCATACTGGTAAGGTTATTTGTATTTCAGATGTCACTCGTGGTGGTGGGCTGACCCACCGAACAGGCAAGAGGTTCTGCGTGAAGTCCGTTTACGTATTGGGTAAGATCTGGATGGATGAGAATATCAAGGTTAAAAACCATACAAATACAGTCATGTTTTTTCTTGTTAGAGACAGGAGGCCGTATGGAACTCCCCAGGATTTTGGTCAGGTGTTCAACATGTATGACAATGAGCCCAGTACGGCCACTGTGAAGAACGATCTTAGAGATCGTTTTCAAGTGATACGTCGTTTTACTTCAACAGTTACTGGAGGCCAGTATGCGAGCAAGGAACAAGCCCTTGTCAAGAAATATATGAAGGTTAACGCTCAGGTGGTTTATAATCACCAGGAGGGTGGGAAATACGAGAATCATACTGAGAATGCTCTATTGTTGTATATGGCTTGTACACATTCTAGTAATCCCGTGTATGCAACTTTGAAAATCAGGATCTATTTTTATGATTCTGTCAGTAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKERRRLNFDSPGISRAAAPTVLVTNRRRAWTYRPMYRKPRMYRMFKSPDVPRGCEGPCKVQSFEARHDVAHTGKVICISDVTRGGGLTHRTGKRFCVKSVYVLGKIWMDENIKVKNHTNTVMFFLVRDRRPYGTPQDFGQVFNMYDNEPSTATVKNDLRDRFQVIRRFTSTVTGGQYASKEQALVKKYMKVNAQVVYNHQEGGKYENHTENALLLYMACTHSSNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_001936687.1
|
|
Location
|
1062-1466 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAACTCAGGCAGAGAATGGCGTCTATACCTGGACGGTCAAAAATCCCCTATATTTCAAGATCGTCCGCCACGACGTGAATGTATTCCTGACAAGGAAGGACATCATCACACTCCAGATCCAGTTCAACCACAACCTGAGGAAAGCGTTGGGGATTCACCAGTGTTTTCTGACCTGCCGGATCTGGACTCGTTTACGTCCTCAGACCTGGCGTTTCTTAAATGTATTTAGATATCAATGTATTAAGTATTTAAATAATTTAGGAATCATTAGTATTAACAATGTTGTTAGAGCCATTAGATATGTATTGTACGATGTACTTGACGGCACAATTGATGCTGAGTTATCACATATAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITATQAENGVYTWTVKNPLYFKIVRHDVNVFLTRKDIITLQIQFNHNLRKALGIHQCFLTCRIWTRLRPQTWRFLNVFRYQCIKYLNNLGIISINNVVRAIRYVLYDVLDGTIDAELSHIIKFNLY |
|
NCBI Accession
|
YP_001936688.1
|
|
Location
|
1207-1641 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCAGCTCTCAAAAGGTGGGCATTACAAAATGCAAAATTCTTCTTCCTCTCCGAAGCGCTCTACTCAAGTGCCAATCAAGGTCCAACACAAAATAGCCAAGAAGGCTATTCGCAGACGTAGAGTTGACCTTCCGTGCGGATGCACATATTACTTTGCACTTGAATGCGCTTCGCATGGATTCACGCACAGGGGAACCCATCACTGCAACTCAGGCAGAGAATGGCGTCTATACCTGGACGGTCAAAAATCCCCTATATTTCAAGATCGTCCGCCACGACGTGAATGTATTCCTGACAAGGAAGGACATCATCACACTCCAGATCCAGTTCAACCACAACCTGAGGAAAGCGTTGGGGATTCACCAGTGTTTTCTGACCTGCCGGATCTGGACTCGTTTACGTCCTCAGACCTGGCGTTTCTTAAATGTATTTAG |
|
Protein Sequence
|
MQLSKGGHYKMQNSSSSPKRSTQVPIKVQHKIAKKAIRRRRVDLPCGCTYYFALECASHGFTHRGTHHCNSGREWRLYLDGQKSPIFQDRPPRRECIPDKEGHHHTPDPVQPQPEESVGDSPVFSDLPDLDSFTSSDLAFLKCI |
|
NCBI Accession
|
YP_001936689.1
|
|
Location
|
1520-2599 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGGCTCCTCCCAGGCGTTTCACAATAAACGCTAAAAATTATTTTCTCACATATCCTCAGTGCCCTCTCTCCAAAGAGGAAGCACTTTCCCAATTATTAAACCTCTCAACCCCAACAAATAAAAAATTTATTAAAATTTGCAGAGAGCTTCATGAAGATGGAAGCCCTCACCTCCATGTTCTTATTCAATTCGAGGGAAAATACAAATGCCAGAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAACACATTTCCATCCAAACATTCAGGGAGCTAAGTCCAGCTCCGATGTCAAAAAATACATGGAAAAAGACGGCGACACCGCCGAATGGGGAGAGTTTCAGGTAGACGGCAGATCTGCAAGAGGGGGTCAGCAATCAGCCAATGACGCTTACGCGCAGGCGATTAACACTGGTAGCAAATTACTGGCTCTTAATGTAATTAAGGAGCTCGCTCCTAAAGATTATGTTTTACAGTTTCATAATTTAAATGCCAATTTAGATAAAATATTTGCACCCCCAGTAGAGGTATTTAATTGTCCATTCTTATCATCGTCCTTTGATCAAGTCCCAGAGGAGATTGAGTGCTGGGTTGCAGATAACATCAAAGATGCCGCTGCGCGGCCGTGGAGACCCATTAGCATTGTAATCGAGGGCGAGAGTCGTACTGGCAAAACAATGTGGGCCAGGTCGTTGGGGCCACATAATTATCTATGTGGTCACTTAGACCTCAGTCCAAGAGTGTACAATAATGATGCCTGGTACAACGTGATTGATGATGTAGACCCCCACTACTTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAATACGGGAAACCAATTCAAATTAAAGGTGGTATTCCCACTATCTTCCTCTGCAATCCAGGCCCAACTTCGTCCTATAAAGAATACTTAGACGAGGAGCGGAATGCAGCTCTCAAAAGGTGGGCATTACAAAATGCAAAATTCTTCTTCCTCTCCGAAGCGCTCTACTCAAGTGCCAATCAAGGTCCAACACAAAATAGCCAAGAAGGCTATTCGCAGACGTAG |
|
Protein Sequence
|
MAPPRRFTINAKNYFLTYPQCPLSKEEALSQLLNLSTPTNKKFIKICRELHEDGSPHLHVLIQFEGKYKCQNNRFFDLVSPTRSTHFHPNIQGAKSSSDVKKYMEKDGDTAEWGEFQVDGRSARGGQQSANDAYAQAINTGSKLLALNVIKELAPKDYVLQFHNLNANLDKIFAPPVEVFNCPFLSSSFDQVPEEIECWVADNIKDAAARPWRPISIVIEGESRTGKTMWARSLGPHNYLCGHLDLSPRVYNNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEERNAALKRWALQNAKFFFLSEALYSSANQGPTQNSQEGYSQT |
|
NCBI Accession
|
YP_001936690.1
|
|
Location
|
2245-2448 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAAGATGGAAGCCCTCACCTCCATGTTCTTATTCAATTCGAGGGAAAATACAAATGCCAGAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAACACATTTCCATCCAAACATTCAGGGAGCTAAGTCCAGCTCCGATGTCAAAAAATACATGGAAAAAGACGGCGACACCGCCGAATGGGGAGAGTTTCAGGTAG |
|
Protein Sequence
|
MKMEALTSMFLFNSRENTNARITDSSTWYPQPGQHISIQTFRELSPAPMSKNTWKKTATPPNGESFR |
|
NCBI Accession
|
YP_001936691.1
|
|
Location
|
866-1696 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 |
|
Coding Region
|
ATGAGAATCCCCATTAGATCTCCTGGTGGGTTTAATGTAGACCGGAGATTCACCGGTGGAGCTGTCTTCCGTCCGAATTATCCATATCGCCGATACTTCGGCAGACGGATTGGTCAGCGTGTATATGGCATGCCATACTCTAGTGGATCTCAACGTCCACGTGGTGTGCCTAATGCACGTCGCAACTTGTTTTCCGTTCATCCGGAAACAAGGAGAAAGACTCGGCAATCCATAGAGGAGGTGCAGGATGGTACAAATTACCTTCTCTGTAATAACACCTCTAAGGTGTCGTATCTTACGTACCCGGCGAAGTCTAGGTCGGAGTTCAGCAACCGGGTAGACTCATACATAAAGCTGTTAAGTTTGAGTGTATCTGGCTCTGTAATTGCCCGGCATTTGGACAGGTCGGAAGGTGCTTCCCGGAATGGAATACATGGCATATTCACGACGGTTATCGTGCGTGATAAAAAACCATGTCAGTTCTCTGCTGTGGATCCACTGATCCCATTTGCTGACGTGTTTGGACTGGAGACGGGCGCGTGTTCCACTTTGCGCGTGCGCGATCAGCATAGGGATAGATTTAGTTTAGTTTATCAGAAGAAGTGCGTGATTAATACCGCACTTCCAGAACATATTTTTAGATTTTCTTATAATGTTAGGTTTAATTCGTACCCAGTTTATGTAACATTTAAGGACACGGAGGATTCTGAACCTACTGGCCTCTATGGCAACGTGTCCAAGAATGCCCTGATAGTTTACTATGTGTGGCTGTGTGATGCCAATGTAACCTCTGAGATTCATGTAAAATATGATCTGCATTATATTGGATAA |
|
Protein Sequence
|
MRIPIRSPGGFNVDRRFTGGAVFRPNYPYRRYFGRRIGQRVYGMPYSSGSQRPRGVPNARRNLFSVHPETRRKTRQSIEEVQDGTNYLLCNNTSKVSYLTYPAKSRSEFSNRVDSYIKLLSLSVSGSVIARHLDRSEGASRNGIHGIFTTVIVRDKKPCQFSAVDPLIPFADVFGLETGACSTLRVRDQHRDRFSLVYQKKCVINTALPEHIFRFSYNVRFNSYPVYVTFKDTEDSEPTGLYGNVSKNALIVYYVWLCDANVTSEIHVKYDLHYIG |
|
NCBI Accession
|
YP_001936692.1
|
|
Location
|
1710-2546 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 |
|
Coding Region
|
ATGGCTGATAATTCAAGTGCGCTGGCATATGCCACGTCTGACAGGACAGAATTCCAACTATCCAGTGAGAAAACTGAGGTAACCCTGTTATTCCCAAGCACAATTGAACAGAAATTGTCAAAACTTATGGGCAAGTGCTTGAGGATAGACCATGTCGTTCTTGAATATAGGAATCAGGTTCCTGTCAATGCCACTGGGCATGTCATTATAGAAATGCACGATACCAGGTTATACGAGGGTGATTCCAAGCAGGCGGAGTTTACAATTCCAATTGGATGTAACTGCAACATCCACTACTACTCATCATCATATTTTTCACCAAGAGACCCAAATCCTTGGAAGGTTATGTACAGGGTAGACGACACGAATGTCGTAGACGGAGTCCATTTCTGCAGGATGCAAGGAAAACTGAAAATGTCATCAGCTAAGCAGTCCTCCGAGATACAATTCAAATCCCCGAAGATCGAGATACTGTCCAAGGCATATAACATGACCAACATTGATTTCTGGTCAGTGCCCCACTCGCAGGTTTCAAGGAGACCTGTACAGGGACTGAAGAATTTACGGTCCCAGTCAAGCAGGTACACAACACCAGCTATACTACCTGGACAATCATGGGCCTCCGCTAGTGCAGTTGGGAATGAAGAACAGGAGGACCTACCATATGGGAATCTGCACAGGTTACAGGACAGGACACTGGACCCAGGCCCATCTGCTTCTGAAGTTATTTGCAACACCAATACTGTAAATGATGATGTCATAAACATCATCAAAAAGACTGTAGAGTTGTGTATGGAGGGCAGTAATGTAACATCTAATGTAAAGCCAATAAAATAA |
|
Protein Sequence
|
MADNSSALAYATSDRTEFQLSSEKTEVTLLFPSTIEQKLSKLMGKCLRIDHVVLEYRNQVPVNATGHVIIEMHDTRLYEGDSKQAEFTIPIGCNCNIHYYSSSYFSPRDPNPWKVMYRVDDTNVVDGVHFCRMQGKLKMSSAKQSSEIQFKSPKIEILSKAYNMTNIDFWSVPHSQVSRRPVQGLKNLRSQSSRYTTPAILPGQSWASASAVGNEEQEDLPYGNLHRLQDRTLDPGPSASEVICNTNTVNDDVINIIKKTVELCMEGSNVTSNVKPIK |