Bitter gourd yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_014884275.1 |
| Isolate | India |
| Release date | 2021/6/1 |
| Submitter | Manivannan,K., Renukadevi,P., Malathi,V.G., Balakrishnan,N., Karthikeyan,G. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
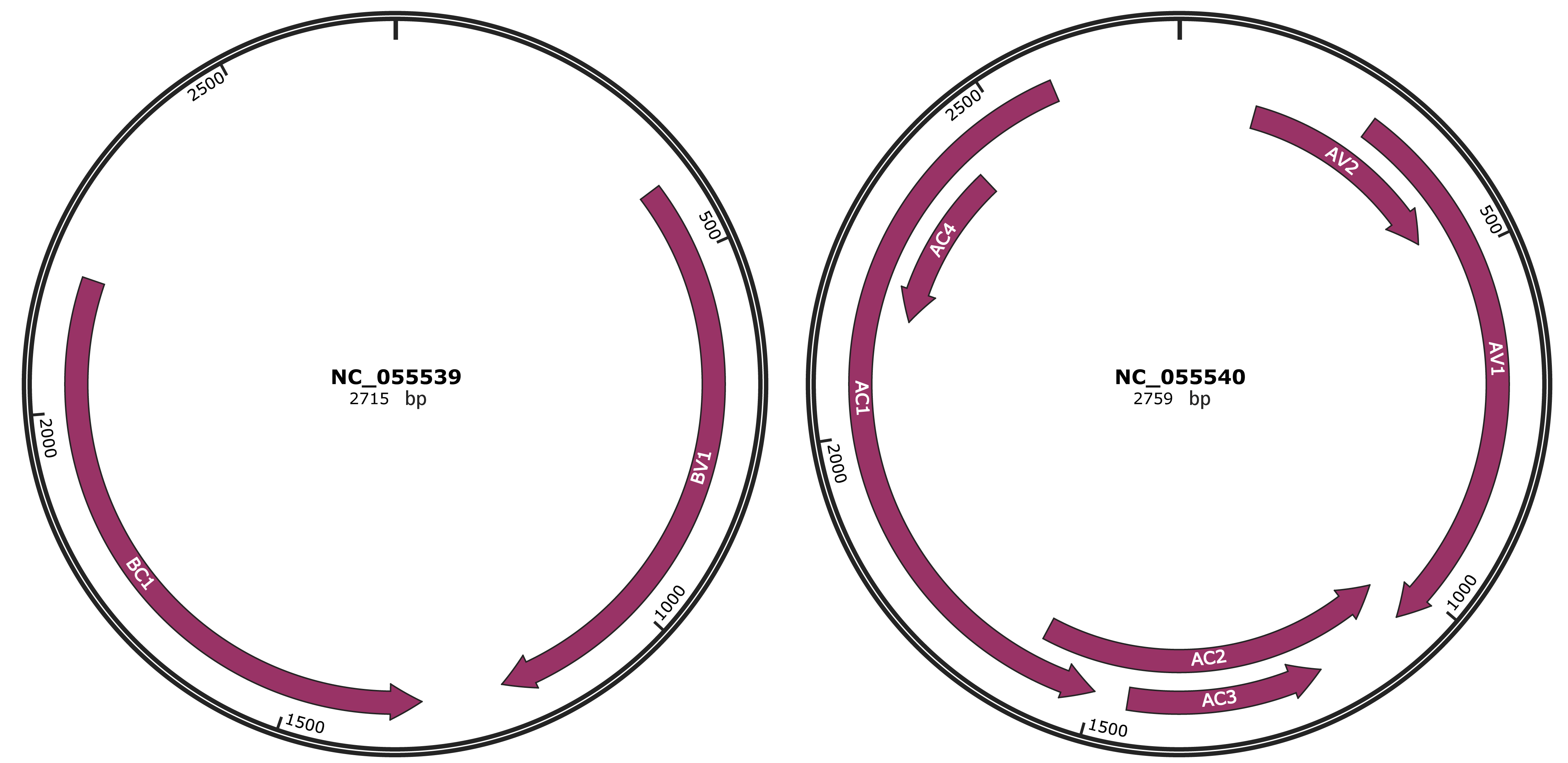
JBrowse
Genome
NC_055539
NC_055540
Gene Information
| NCBI Accession | YP_010087323.1 |
|---|---|
| Location | 401-1210 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGGCAATTGGGAACTATACGAAGACGCCCCCCAAGGGCTACGGTGTCCGTAATTATCGTAATTACGGACGGACATATCAGTTTCGAACTCTGAAGAACTGGCGACGGCCTGAAGGACGTTCTCTCCGATGGTTTCGTCGACCTTCGAAAGCTGTGGTCGACCTCTTTGGCGACGATTCGAGTAGGCAATTCCGGCCTAAGGAATTGACGGAGGTTCAACGTGGAACGGACTATGTCGTGTCCAACAACCGTTACGTAACTACTTATGTTACGTACCCCAGCAAGACCCGAATCGGAACGAGCAACCGCACGACATCGTTCATTAGAGTGAACGGCCTGAAGATGTCTGGGACTGTGTCCGTGCGATCTACTGGAATGGAGACGGATGTCGACAGCGTGCATGTCCCGTTTGGCTTGATGTCGATTGTTGTCGTCCGAGACAAGAAGCCCAAGCTGTATTCCGGTGCACAGCCGCTTATGCCGTTCGTGGAGCTGTTTGGTTCCGTTGAATCGTGCAAGGGCACTTTGAAGGTGGCCGATCAGCACAGAGATAGGTTTATTTTGTTGAGGCAGACGTCCTTCATGGTGACGGGTCTTCATGGGACGGCCATGAAGAGATTTAATGTTAGCAACTGCATTCCTTCGTCATACAACACGTGGGTCACGTTCAAGGACGAAGATGAGAACAATTGCACCGGTCAATATTCTAATACGGCGCGAAATGCGCTGCTTGTTTATTATGTTTGGTTGAGCGACGTCCCGTCGCATGCGGAAGTCTATAGCAACCTAACGTTGAATTATGTGGGGTAG |
| Protein Sequence | MAIGNYTKTPPKGYGVRNYRNYGRTYQFRTLKNWRRPEGRSLRWFRRPSKAVVDLFGDDSSRQFRPKELTEVQRGTDYVVSNNRYVTTYVTYPSKTRIGTSNRTTSFIRVNGLKMSGTVSVRSTGMETDVDSVHVPFGLMSIVVVRDKKPKLYSGAQPLMPFVELFGSVESCKGTLKVADQHRDRFILLRQTSFMVTGLHGTAMKRFNVSNCIPSSYNTWVTFKDEDENNCTGQYSNTARNALLVYYVWLSDVPSHAEVYSNLTLNYVG |
| NCBI Accession | YP_010087324.1 |
|---|---|
| Location | 1322-2179 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGTCGACGAGCAAGAGATACGAGAGCGGTGCGATTGGCGTGCTTCCTGGAGGATACATCAACTCAGAGCGAGTTGAGTACGCCCTAACAAACGATGCTACGGACGTGGTCCTGTCCTTTCCTTCAATGTTCGAACAGAAACTCAGCCAGCTTCGCAACCGGTGCATGAAGATAGACCACGTCGTCCTGGAGTATCGGAATCAGGTTCCGATAAACGCCCTTGGTCACGTCGTCATCGAAATTCACGACATGCGGTTGACAGAGGGCGACACCAAGCAGGCCGAATTCACGATTCCGATCAAATGCAACTGTAATCTGCACTACTACTCCTCCTCCTATTTCTCGATACGGGATAAAAACCCGTGGAGGGTCGAATACAGAGTGGAAGACACGAACGTGGTGAACGGCGTGCACTTCTGCAAGATCATGGGAAAGCTGCGGCTATCTTCTGCCAAACATTCCACAGACGTGGAATTCAAGCCGCCAAAGATAGAAATCCTAAGCAAAGAGTTCACCGTGAACGACATAGACTTCTGGGCCGTGGGTGCCAAGGCCCAATCAAGACGTCTGGTCGAAGGTGCAACCCTAACGGGCCTTCGCTCCAACTCCATGCGCGTTCCACACCTATCAATCAGGCCCAACGAGTCTTGGGCCAGCAGATCCGAAGTTGGGACCGGGTCCAGTTCCAGCAGGCCCTATCAAGGCCTGAACGCGCTGGACGACAACGCCATCGACCCTGGCCAGTCAGCATCACAAGTCGGAAGCTTCACGAAACACGACATAACAGAATTAATATCCAAAACAGTCGAACATTGTATACGATCTAATATCAACGCACCTGTAACAAAGGCCATTTAG |
| Protein Sequence | MSTSKRYESGAIGVLPGGYINSERVEYALTNDATDVVLSFPSMFEQKLSQLRNRCMKIDHVVLEYRNQVPINALGHVVIEIHDMRLTEGDTKQAEFTIPIKCNCNLHYYSSSYFSIRDKNPWRVEYRVEDTNVVNGVHFCKIMGKLRLSSAKHSTDVEFKPPKIEILSKEFTVNDIDFWAVGAKAQSRRLVEGATLTGLRSNSMRVPHLSIRPNESWASRSEVGTGSSSSRPYQGLNALDDNAIDPGQSASQVGSFTKHDITELISKTVEHCIRSNINAPVTKAI |
| NCBI Accession | YP_010087325.1 |
|---|---|
| Location | 120-458 |
| Gene Name | AV2 |
| Protein Name | pre coat protein |
| Coding Region | ATGTGGGATCCACTTTTGCACGCGTTCCCTGACACCGTGCACGGCTTGCGTTGTATGCTAGCCGTAAAATACCTGCAGGAGGTTGAGAAGACGTATTCGCCGGATACGGTCGGATACGACTGGGTGCGCGACTTGATCCTTGTCGTTCGCGGCAGGAACTATGTCGAATCGAAAAGCAGATATCATCATTTCAACGCCCGCCTCGAAGGCACGCCGACGTCTGAATTTCGACAGCCCCTATGCGGCCCGTGCAGTTGTCCCCATTGTCCGAGGCACAAAGGCAAGGGTATGGGCCAACAGGCCCATGAACAGAAAGCCCAGGATCTACCGAATGTTTAG |
| Protein Sequence | MWDPLLHAFPDTVHGLRCMLAVKYLQEVEKTYSPDTVGYDWVRDLILVVRGRNYVESKSRYHHFNARLEGTPTSEFRQPLCGPCSCPHCPRHKGKGMGQQAHEQKAQDLPNV |
| NCBI Accession | YP_010087326.1 |
|---|---|
| Location | 280-1050 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAATCGAAAAGCAGATATCATCATTTCAACGCCCGCCTCGAAGGCACGCCGACGTCTGAATTTCGACAGCCCCTATGCGGCCCGTGCAGTTGTCCCCATTGTCCGAGGCACAAAGGCAAGGGTATGGGCCAACAGGCCCATGAACAGAAAGCCCAGGATCTACCGAATGTTTAGAAGCCCAGATGTACCACGGGGCTGTGAAGGCCCGTGTAAGGTACAGTCTTTCGAGTCCAGGCATGACGTGGCCCATATTGGGAAGGTGATGTGCGTTAGTGACGTGACGCGCGGGACCGGGCTGACGCATCGTGTCGGCAAGCGTTTCTGTGTCAAGTCTGTGTACGTGCTGGGTAAGGTGTGGATGGACGAGAACATCAAGACCAAAAATCACACAAATACTGTCATGTTCTTCCTTGTTCGTGGTAGGAGGCCTATTGACAAGCCTCAGGATTTCAGCGAGGTCTTCAACATGTTTGACAACGAGCCTAGCAGGGCTACCGTGATGAACATGCATCGTGATCGATATCAGGTTTTACGGAATTCACACACGACCGTGACGGGAGGAACGTATGCGTGCAGCCGGCACGCACTAGTTAGGAAGTTTATTAGGGTTAATAACTATGTTGTTTACAACCAACAAGAAGCGGGCAAGTATGAGAATCCCACAGACAATGCCCTTATGTTGTACATGGCGTCGACGCCGCATTCTAATCCTGTATATGCAACGCTGAAGATCCGGATCTATTTTTATGATTCGGTGTCCAATTAA |
| Protein Sequence | MSNRKADIIISTPASKARRRLNFDSPYAARAVVPIVRGTKARVWANRPMNRKPRIYRMFRSPDVPRGCEGPCKVQSFESRHDVAHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKVWMDENIKTKNHTNTVMFFLVRGRRPIDKPQDFSEVFNMFDNEPSRATVMNMHRDRYQVLRNSHTTVTGGTYACSRHALVRKFIRVNNYVVYNQQEAGKYENPTDNALMLYMASTPHSNPVYATLKIRIYFYDSVSN |
| NCBI Accession | YP_010087327.1 |
|---|---|
| Location | 1047-1595 |
| Gene Name | AC2 |
| Protein Name | transcription activator protein |
| Coding Region | ATGCGCTCTTCATCACCCTCGAAGGTCCCCTCTATTCCGGCGGGAATCAAGGCGCAACACCGGAAGTGCAAGAGAGCAATCCGACGCAGGCGGATTGACTTGAAGTGCGGCTGCTCGTACTACTACTCCATCGACTGCCACGACCATGGATTCACGCACAGGGGAGTACATCACTGCAACTCAAGCAGAGAATGGCGCGTTTATCTGGACGGTACCAAATCCCCTCTATTTCAAGATAACAGACCACGCAGTCCGTCCGTCTTTCAGCCAACAGGACATCATAACAATCGAAATCAGATTCAACCACAACCTGAGGAGAGCTCTGCAGATTCACAAGTGTTTTCTAACCTACAAGGTCTGGACTGGTTTACAGCCTCAGACCTGGCTTTTTTTGAGGGTATTCAGGACGCAGTCCTGAAATATCTGGACATGTTAGGAGTAGTCAGCCTAAACAATGTAATTAGGGCAGTAGACCATGTTTTGTGGAACGTTATCCACAAAACAGAATATGTAGACCGCACTTATTCAATAAAATTCAATGTTTATTAA |
| Protein Sequence | MRSSSPSKVPSIPAGIKAQHRKCKRAIRRRRIDLKCGCSYYYSIDCHDHGFTHRGVHHCNSSREWRVYLDGTKSPLFQDNRPRSPSVFQPTGHHNNRNQIQPQPEESSADSQVFSNLQGLDWFTASDLAFFEGIQDAVLKYLDMLGVVSLNNVIRAVDHVLWNVIHKTEYVDRTYSIKFNVY |
| NCBI Accession | YP_010087328.1 |
|---|---|
| Location | 1178-1450 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAGTACATCACTGCAACTCAAGCAGAGAATGGCGCGTTTATCTGGACGGTACCAAATCCCCTCTATTTCAAGATAACAGACCACGCAGTCCGTCCGTCTTTCAGCCAACAGGACATCATAACAATCGAAATCAGATTCAACCACAACCTGAGGAGAGCTCTGCAGATTCACAAGTGTTTTCTAACCTACAAGGTCTGGACTGGTTTACAGCCTCAGACCTGGCTTTTTTTGAGGGTATTCAGGACGCAGTCCTGA |
| Protein Sequence | MDSRTGEYITATQAENGAFIWTVPNPLYFKITDHAVRPSFSQQDIITIEIRFNHNLRRALQIHKCFLTYKVWTGLQPQTWLFLRVFRTQS |
| NCBI Accession | YP_010087329.1 |
|---|---|
| Location | 1498-2583 |
| Gene Name | AC1 |
| Protein Name | replication initiation protein |
| Coding Region | ATGCCTCGTCTCAAGAAATTTCTAGTGAGTGCCAAAAATGTTTTCCTCACTTTCCCAAAATGCCCTCTTTCAAAAGACACGATGCTTGAACTTCTTAAAAATATAGAGTGCCCTTCGGATAAATTATTCATACGAGTTGCGCAAGAGAGACACCAAGATGGGTCTCTGCACATCCACGCTCTTCTCCAGTTCAAGGGTAAGGCCCAGTTCAGAAACCCCAGACACTTCGATGTCACTCACCCTAATTGCTCCGCCACCTTCCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCCGACGTTAAGTCATACATCGAGAAGGACGGTGATTACATCGACTGGGGTGTGTTTCAGATCGATGGACGATCTGCTCGAGGAGGTCAACAGACAGCTCACGATGCGGCAGCAGAGGCCCTAAATTCTGGTTCCGTGGAAGACGCACTTGCAATCCTTCGGGAAAAGCTCCCGAAGGACTTCCTATTCCAGTATCACAATTTAAAGGCCAATCTCGAACGGATTTTTTCAACTCCGTTAGAGCCGTTTGTTTCTCCTTATTCATTGAATTCATTCGATCTCGTTCCGCCAGAACTCGTCGATTGGGTGTCAAATAACGTTTGCAGTGCCGCTGCGCGGCCATTTAGACCCATAAGTATAGTTATCGAGGGTGATAGTAGAACGGGCAAGACAATGTGGGCGCGTTCACTGGGAACGCACAACTATCTCTGCGGGCATCTAGATCTCAGTCCCAAGATCTATTCCAACGATGCTTGGTACAACGTCATTGATGACGTCGACCCGCACTATCTAAAGCACTTCAAAGAGTTCATGGGGGCCCAGCGTGACTGGCAAAGCAACACGAAATACGGAAAGCCAGTCCACATAAAAGGCGGCATTCCCACTATCTTCCTCTGCAATCCAGGACCTAGCTCCAGCTATATAGAATATCTGGAAGAAGAAAAGAACGCCGCACTCAAAGCCTGGGTTCTGAAGAATGCGCTCTTCATCACCCTCGAAGGTCCCCTCTATTCCGGCGGGAATCAAGGCGCAACACCGGAAGTGCAAGAGAGCAATCCGACGCAGGCGGATTGA |
| Protein Sequence | MPRLKKFLVSAKNVFLTFPKCPLSKDTMLELLKNIECPSDKLFIRVAQERHQDGSLHIHALLQFKGKAQFRNPRHFDVTHPNCSATFHPNFQGAKSSSDVKSYIEKDGDYIDWGVFQIDGRSARGGQQTAHDAAAEALNSGSVEDALAILREKLPKDFLFQYHNLKANLERIFSTPLEPFVSPYSLNSFDLVPPELVDWVSNNVCSAAARPFRPISIVIEGDSRTGKTMWARSLGTHNYLCGHLDLSPKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVHIKGGIPTIFLCNPGPSSSYIEYLEEEKNAALKAWVLKNALFITLEGPLYSGGNQGATPEVQESNPTQAD |
| NCBI Accession | YP_010087330.1 |
|---|---|
| Location | 2169-2426 |
| Gene Name | AC4 |
| Protein Name | symptom determinant protein |
| Coding Region | ATGGGTCTCTGCACATCCACGCTCTTCTCCAGTTCAAGGGTAAGGCCCAGTTCAGAAACCCCAGACACTTCGATGTCACTCACCCTAATTGCTCCGCCACCTTCCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCCGACGTTAAGTCATACATCGAGAAGGACGGTGATTACATCGACTGGGGTGTGTTTCAGATCGATGGACGATCTGCTCGAGGAGGTCAACAGACAGCTCACGATGCGGCAGCAGAGGCCCTAA |
| Protein Sequence | MGLCTSTLFSSSRVRPSSETPDTSMSLTLIAPPPSTQTSRELSPAPTLSHTSRRTVITSTGVCFRSMDDLLEEVNRQLTMRQQRP |
References More References in PubMed
| 1 |
Rout BM, et al. 3 Biotech. 2025 Jul;15(7):214. doi: 10.1007/s13205-025-04383-6. Epub 2025 Jun 16. PMID: 40535111 |
|---|---|
| 2 |
Ahsan M, et al. Plants (Basel). 2023 Oct 8;12(19):3503. doi: 10.3390/plants12193503. PMID: 37836243 |
| 3 |
First Report of Tomato leaf curl Palampur virus on Bitter Gourd in Pakistan. Ali I, et al. Plant Dis. 2010 Feb;94(2):276. doi: 10.1094/PDIS-94-2-0276A. PMID: 30754274 |
| 4 |
Renukadevi P, et al. 3 Biotech. 2024 Aug;14(8):184. doi: 10.1007/s13205-024-04009-3. Epub 2024 Jul 26. PMID: 39070236 |
| 5 |
Kiran GVNSM, et al. 3 Biotech. 2021 Dec;11(12):500. doi: 10.1007/s13205-021-02975-6. Epub 2021 Nov 17. PMID: 34881163 |
| 6 |
Sandra N, et al. Front Plant Sci. 2024 May 14;15:1376284. doi: 10.3389/fpls.2024.1376284. eCollection 2024. PMID: 38807782 |
| 7 |
Raj SK, et al. Int J Food Sci Nutr. 2005 May;56(3):185-92. doi: 10.1080/09637480500103946. PMID: 16009633 |
| 8 |
Seed Transmission of Begomoviruses: A Potential Threat for Bitter Gourd Cultivation. Gomathi Devi R, et al. Plants (Basel). 2023 Mar 21;12(6):1396. doi: 10.3390/plants12061396. PMID: 36987084 |
| 9 |
A new seed-transmissible begomovirus in bitter gourd (Momordica charantia L.). Manivannan K, et al. Microb Pathog. 2019 Mar;128:82-89. doi: 10.1016/j.micpath.2018.12.036. Epub 2018 Dec 21. PMID: 30583019 |
| 10 |
Sivagnanapazham K, et al. 3 Biotech. 2026 Aug;16(8):345. doi: 10.1007/s13205-026-04962-1. Epub 2026 Jul 20. PMID: 42482923 |