Tomato leaf curl Comoros virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_001430535.1 |
| Isolate | Mayotte:Dembeni |
| Release date | 2015/11/3 |
| Submitter | Delatte,H., Martin,D.P., Naze,F., Goldbach,R., Reynaud,B., Peterschmitt,M., Lett,J.M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
JBrowse
Genome
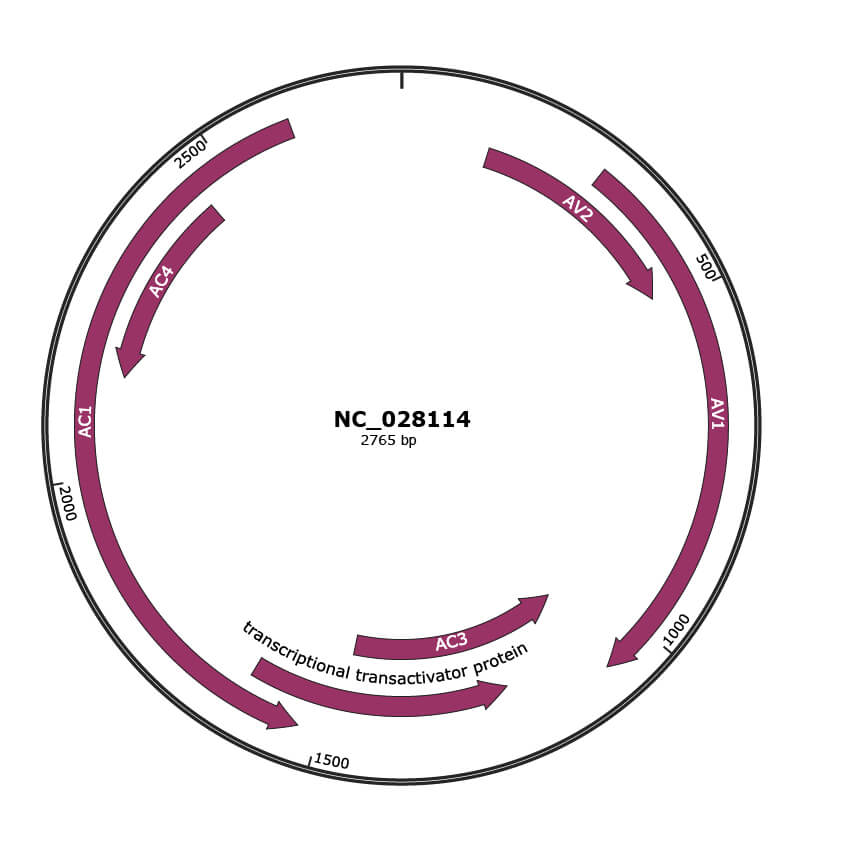
NC_028114
Gene Information
| NCBI Accession | YP_009174971.1 |
|---|---|
| Location | 136-486 |
| Gene Name | AV2 |
| Protein Name | putative AV2 protein |
| Coding Region | ATGTGGGATCCACTCTTGAACGAGTTCCCAGACTCTGTTCACGGTTTTCGTTGTATGCTAGCTATCAAATATTTGCAGGCCATTGAGCAAACCTATGAGCCCAACACTTTGGGCCACGAATTGATCCGTGATCTCATCTCCGTCGTTAGAGCTCGTGATTATGTCGAAGCGACCCGCCGATATAATCATTTCCACGCCCGCCTCGAAGGTGCGTCGGAGACTGAACTTCGACAGCCCTTATACCAGCCGTGCTGTTGTCCCCATTGTCCCAGGCACAAGCAGACGTCGGTCATGGACGTACAGGCCCATGTATCGAAAGCCCAGGACGTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPDSVHGFRCMLAIKYLQAIEQTYEPNTLGHELIRDLISVVRARDYVEATRRYNHFHARLEGASETELRQPLYQPCCCPHCPRHKQTSVMDVQAHVSKAQDVQNVQKP |
| NCBI Accession | YP_009174972.1 |
|---|---|
| Location | 296-1072 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCCGCCGATATAATCATTTCCACGCCCGCCTCGAAGGTGCGTCGGAGACTGAACTTCGACAGCCCTTATACCAGCCGTGCTGTTGTCCCCATTGTCCCAGGCACAAGCAGACGTCGGTCATGGACGTACAGGCCCATGTATCGAAAGCCCAGGACGTACAGAATGTACAGAAGCCCTGACGTTCCAAAGGGTTGTGAAGGCCCATGTAAGGTCCAGTCTTATGAGCAGAGGGATGATGTTAAGCATACTGGTATTGTTCGTTGTGTTAGTGATGTTACGCGTGGTCCGGGAATTACTCATAGGGTTGGCAAGAGGTTCTGTGTTAAGTCCATTTACATTTTAGGGAAAATATGGATGGATGAAAATATCAAGAAGCAGAATCACACTAATCAGGTTATGTTTTTTTTAGTTCGTGATAGAAGGCCTTACGGTGCAGCCCCAATGGATTTTGGGCAGGTGTTTAACATGTTTGATAACGAGCCCAGTACAGCTACGGTGAAGAATGATTTGAGAGACAGGTACCAGGTTTTGCGGAAGTTTCATGCAACTGTTGTAGGTGGTCCCTCTGGGATGAAGGAACAGGCGTTAGTTAAGAGGTTTTTTAGGATTAATAGTCATGTAACTTATAATCATCAGGAAGCAGCTAAGTATGAGAACCATACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAATCCAGTGTATGCTACTCTTAAGATACGGATCTACTTCTATGATTCGGTCGGCAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFDSPYTSRAVVPIVPGTSRRRSWTYRPMYRKPRTYRMYRSPDVPKGCEGPCKVQSYEQRDDVKHTGIVRCVSDVTRGPGITHRVGKRFCVKSIYILGKIWMDENIKKQNHTNQVMFFLVRDRRPYGAAPMDFGQVFNMFDNEPSTATVKNDLRDRYQVLRKFHATVVGGPSGMKEQALVKRFFRINSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVGN |
| NCBI Accession | YP_009174973.1 |
|---|---|
| Location | 1069-1473 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCTCGCACAGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTATATTTCAAGATTATCGACCACGACAACCGGCCATTCAACATGCCCCACGACATCATATCAGTCCAGATAAGATTCAACCACAACCTGAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCAGGGTCTGGACGAGCTTACAGCCTCAGACTGGTCTTTTCTTAAGCGTATTTAGGAATCACGTTCTTAAATATTTAGATAGATTAGGAGTTATTTCAATTAATAATGTAATCAGAGCAGTTGATCATGTATTATACGATGTAATTCTAAAGACACTTCAAGTCGACGAGAATCATGAAATAAAATTTAATATTTATTAA |
| Protein Sequence | MDSRTGELITAAQAQSGVFIWEIQNPLYFKIIDHDNRPFNMPHDIISVQIRFNHNLRKELGIHKCFLNFRVWTSLQPQTGLFLSVFRNHVLKYLDRLGVISINNVIRAVDHVLYDVILKTLQVDENHEIKFNIY |
| NCBI Accession | YP_009174974.1 |
|---|---|
| Location | 1214-1621 |
| Gene Name | transcriptional transactivator protein |
| Protein Name | AC2 |
| Coding Region | ATGCAACATTCGTCACCCTCCACGAGCCACTCTACTCAACTGCCAATCAAAGTCCAGCACAGAATAGCCAAGAAGAAGGCAGTGAGGCGTAGAAGAGTCGATCTCGACTGCGGCTGCTCATACTATCTACACATCAACTGCATCGATCATGGATTCTCGCACAGGGGAACTCATCACTGCAGCTCAAGCACAGAGTGGCGTGTTTATCTGGGAGATACAAAATCCCCTATATTTCAAGATTATCGACCACGACAACCGGCCATTCAACATGCCCCACGACATCATATCAGTCCAGATAAGATTCAACCACAACCTGAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCAGGGTCTGGACGAGCTTACAGCCTCAGACTGGTCTTTTCTTAAGCGTATTTAG |
| Protein Sequence | MQHSSPSTSHSTQLPIKVQHRIAKKKAVRRRRVDLDCGCSYYLHINCIDHGFSHRGTHHCSSSTEWRVYLGDTKSPIFQDYRPRQPAIQHAPRHHISPDKIQPQPEEGTGDSQMFSQLQGLDELTASDWSFLKRI |
| NCBI Accession | YP_009174975.1 |
|---|---|
| Location | 1530-2609 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCGAGAGCCGGTCGTTTCAGCATCAAAGCCAAAAATTATTTCCTCACTTATCCCAAATGCTCTCTCACTAAAGAGGAAGCACTTTCCCAAATAAGAGCCCTTCAAACCCCAGTAAATAAGCTATTTATCAAAATCTGCAGAGAGCTCCACGAGAATGGGGAACCTCATATGCATGCCCTCATTCAATTCGAGGGAAAATACAATAGTACCAATCAACGATTCTTCGACCTTACTTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGACACCCTCGAATGGGGAGAATTTCAGATCGATGGACGATCTGCAAGGGGGGGACAACAATCAGCCAATGACGCTTACGCCGCAGCTCTTAACACAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAATTAGCACCAAAAGATTTTGTGTTGCAATTTCATAATTTAAATAGTAATTTAGATAGGATTTTTCAGGAGCCACCGGCTCCTTATGTTTCTCCTTTTTTATCTTCTTCTTTTACTCAAGTTCCGGAACAACTTGAAGAGTGGGTTTCCGAGAACGTCATGGATGCCGCTGCGCGGCCATGGAGGCCGAATAGTATAGTAATTGAGGGTGATAGTCGTACCGGCAAAACAATGTGGGCCAGATCATTAGGACCTCACAATTATCTGTGCGGTCATCTTGACCTGAGCCCCAAGGTGTACAGCAATGATGCGTGGTACAACGTCATTGATGACGTAGATCCGCATTATCTGAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAATACAAAGTACGGGAAGCCAATTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGCCCGACATCCTCATATAAAGAATATCTGGACGAGGATAAAAATGCACCCCTGAAAGCCTGGGCATTAAAAAATGCAACATTCGTCACCCTCCACGAGCCACTCTACTCAACTGCCAATCAAAGTCCAGCACAGAATAGCCAAGAAGAAGGCAGTGAGGCGTAG |
| Protein Sequence | MPRAGRFSIKAKNYFLTYPKCSLTKEEALSQIRALQTPVNKLFIKICRELHENGEPHMHALIQFEGKYNSTNQRFFDLTSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQSANDAYAAALNTGSKSEALRVIKELAPKDFVLQFHNLNSNLDRIFQEPPAPYVSPFLSSSFTQVPEQLEEWVSENVMDAAARPWRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKNAPLKAWALKNATFVTLHEPLYSTANQSPAQNSQEEGSEA |
| NCBI Accession | YP_009174976.1 |
|---|---|
| Location | 2150-2452 |
| Gene Name | AC4 |
| Protein Name | putative AC4 protein |
| Coding Region | ATGGGGAACCTCATATGCATGCCCTCATTCAATTCGAGGGAAAATACAATAGTACCAATCAACGATTCTTCGACCTTACTTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGACACCCTCGAATGGGGAGAATTTCAGATCGATGGACGATCTGCAAGGGGGGGACAACAATCAGCCAATGACGCTTACGCCGCAGCTCTTAACACAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAATTAG |
| Protein Sequence | MGNLICMPSFNSRENTIVPINDSSTLLPQAGQHISIRTFRELNPAPTSSPTSTRTETPSNGENFRSMDDLQGGDNNQPMTLTPQLLTQAVSQRLLESLRN |
References More References in PubMed
| 1 |
A New Tomato leaf curl virus from Mayotte. Lett JM, et al. Plant Dis. 2004 Jun;88(6):681. doi: 10.1094/PDIS.2004.88.6.681B. PMID: 30812598 |
|---|---|
| 2 |
Molecular Characterization of a Begomovirus Associated with Tomato Leaf Curl Disease in Uganda. Shih SL, et al. Plant Dis. 2006 Feb;90(2):246. doi: 10.1094/PD-90-0246A. PMID: 30786424 |
| 3 |
Within-host dynamics of the emergence of Tomato yellow leaf curl virus recombinants. Urbino C, et al. PLoS One. 2013;8(3):e58375. doi: 10.1371/journal.pone.0058375. Epub 2013 Mar 5. PMID: 23472190 |
| 4 |
Tomato leaf curl Mahe virus: a novel tomato-infecting monopartite begomovirus from the Seychelles. Scussel S, et al. Arch Virol. 2018 Dec;163(12):3451-3453. doi: 10.1007/s00705-018-4007-3. Epub 2018 Sep 3. PMID: 30178119 |
| 5 |
Thierry M, et al. Arch Virol. 2012 Mar;157(3):545-50. doi: 10.1007/s00705-011-1199-1. Epub 2011 Dec 21. PMID: 22187103 |
| 6 |
Martin DP, et al. PLoS Pathog. 2011 Sep;7(9):e1002203. doi: 10.1371/journal.ppat.1002203. Epub 2011 Sep 15. PMID: 21949649 |
| 7 |
Péréfarres F, et al. Virol J. 2011 Aug 5;8:389. doi: 10.1186/1743-422X-8-389. PMID: 21819593 |