Tomato leaf curl Cebu virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000875005.1 |
| Isolate |
Philippines: Cebu |
| Release date |
2015/2/13 |
| Submitter |
Tsai,W.S., Shih,S.L., Venkatesan,S.G., Aquino,M.U., Green,S.K., Kenyon,L., Jan,F.J., Aquino,M., Huang,Y.C., Jan,F.-J. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
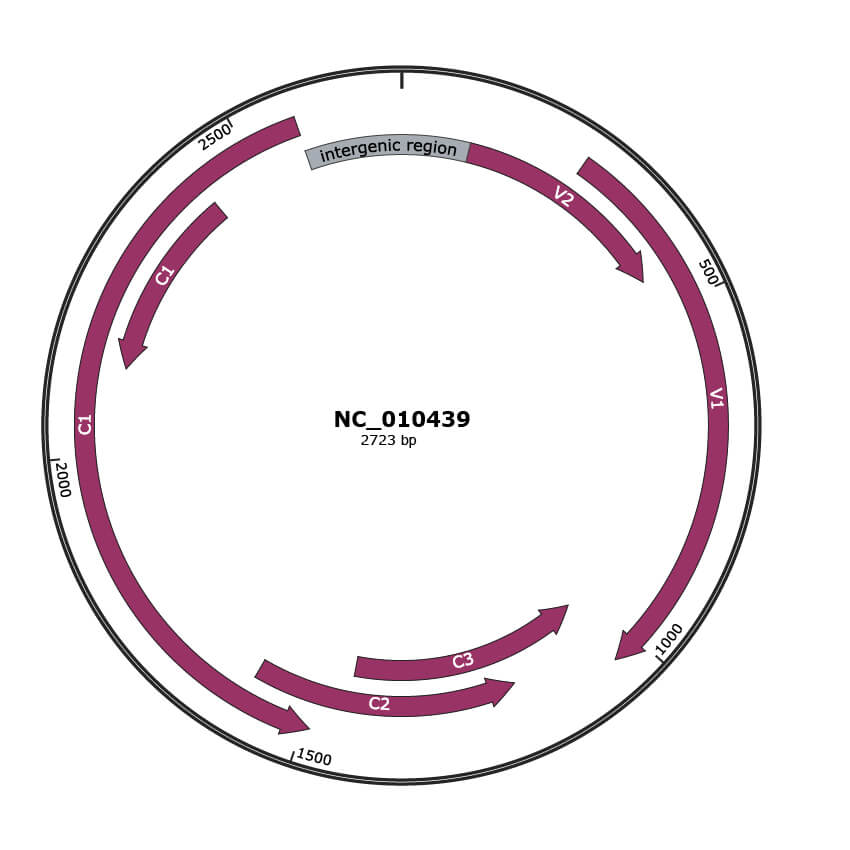
JBrowse
Genome
ACCGTGGGACGCGCCTTTTTTTTAACCAATCATATTGGACCTTGACAGCTATTTAAAGTGCATTCTGCACCATAAAAGAGTTTTCTTTATAGGTAATGGCGAACATGTGGGATCCTCTAGTTCATCCTTTCCCTGAAAGCTTGCACGGCTTTAGATGTATGCTTGCCATCAAATATCTTCAAAGCTTACAGGGCAAATATTCTCCGGATACTGTTGGGCATGAGTTTTTGAAAGATTTTATATGTATTTTGCGTAGTAGGAATTATGCCGAAGCGTTCAATAGATACAGTGACGTCGTTGCCAATGTCTATAACACGACGGAGACTCAATTACGGGAGTCAGTTCAGTCTCCCTGCCTCTGTCCCCACTGTCCCAGACATGTCTTACAAGCGAAGGTCGTGGACTTACAGGCCCATGTATCGCAAGCCCAAGATGTACAGAATGTATAGAAGCCGTGATGTTCCTCGTGGGTGTGAAGGCCCGTGTAAGGTTCAGTCCTATGAGCAGCGCCATGATATAGTTCATGTGGGTAAGGTCATATGTGTTTCTGACGTCACTCGTGGTAACGGGCTTACACATCGTGTTGGAAAGAGGTTTTGTGTAAAGTCTGTGTATGTGTTGGGGAAGGTCTGGATGGATGAGAACATCAAGACTAAAAATCACACTAACACTGTCATGTTTTTTTTAGTGCGTGATAGGAGGCCATATGGGTCTCCCCAGGATTTTGGTCAGGTTTTTAACATGTATGATAATGAGCCTAGTACTGCCACTGTAAAAAATGATAATAGAGATCGATTCCAAGTTCTTCGTAGATTTCAAGCTACTGTAACGGGAGGTCAGTATGCAAGCAAGGAGCAAGCAATAGTTAAGAAGTTCATGAAGATTAACAACCATGTCACTTACAATCATCAGGAGGCTGCGAAGTACGATAACCACACAGAAAATGCTTTGTTGTTATATATGGCATGTACTCATGCTAGTAATCCAGTGTATGCTACGTTGAAGATCAGAATCTATTTCTATGATTCTGTTCAAAATTAATAAATATTGAATTTTATTATATGAGAAATTTGTACATCGATTGTTTTTTCAAGTACATCGTATAGTACATAGTCGAATGCCCTAATTACATTGTTTATGCTAATAACTCCTAAACTATCTAAATATTTCATACAATGATATTTAAATACTCTTAAGAAACGCCAAGTCTGAGGACGTAAACGAGTCCAGATTTTGCAGATCAGAAAACATTGATGTATTCCCAACGCTTTCCTCAGGTTGTGGTTGAACTGTATTTGTACCGTTATGATGTCGTGGTTCCTCAGGAACGGCCTCTTGTCGTGTTGGGATATCTTGAAATAGAGGGGATTTGTTATCATCCAGGTATATACGCCATTCTCTGCCTGAGCTGCAGTGATGAGTTCCCCTGTGCGAGAATCCATATGACGCACAATTAAGTCCTAAATAGTAAGAGCAGCCGCACGGAAGATCAATTCTCCGCCTGCGTATCGGTCTCTTCTTGGCTATTTTGTGTTGGACTTTGATGGGAACTTGAGTACAATGGTTGTGTGATGGTGATGAATTCTGCATTTTTTAGTGCCCAATTTTTGAGTTCCCTATTTTTGTCCTCATCCAAGTACTCTTTATACGATGATGTAGGACCAGGATTGCAGAGGAAGATAGTGGGTATTCCACCTTTAATTTGAATTGGTTTCCCGTACTTCGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATGAACTCTTTAAAATGCTTTAGATAATGCGGATCAACGTCATCAATGACGTTATACCAAGCATCATTGCTGTAAACCTTTGGGCTTAGGTCCAAATGTCCGCATAGATAATTGTGTTGGCCCAGAGATCTAGCCCACATCGTCTTTCCTGTTCTACTATTGCCTTCTATTACAATACTTATGGGCCTCCAAGGCCGCGCAGCGGCATCCCTGACATTCTCGGAAACCCATTCTTCAAGTTCTTTTGGAACTTGATCGAAAGAAGAAGGAAGAAAAGGACAAACAAAAACCTCTAAAGGAGGTGCAAAAATTCTATCTAAATTCGCATTTAAATTGTGAAATTGTAAAATATAATCTTTAGGGGCTAATTCTCTAATTACATTAAGAGCCTCCGACTTACTTCCTGTGTTAATTGCTTTGGCGTAAGCATCATTGGCTGTTTGTTGACCCCCTCTAGCAGATCTTCCGTCGACCTGAAACTCACCCCATTCGACGGTGTCTCCGTCTTTATCAATATAGGATTTGACGTCGGAGCTTGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGATCTGGTTGGGGATACCAAATCGAAGAATCGTTGATTCGTGCATCTGTATTTCCCCTCGAACTGGATGAGCACATGGAGATGAGGGCTCCCATCTTCGTGCAGTTCTCTGCAGATCTTGATGAATTTTTTATTTGTTGGTGTTTCTAGGTTTTGTAATTGGGTAAGGGTTTCCTCTTTAGTAAGAGAGCATTTGGGATATGTAAGAAAATAATTTTTGGCATTTATTTGGAATTTTCTGGGAGGTGCCATTTGACTTAGTCAATGGGTACCAATTGAGAGGATTTCATTCTACTCAGGGTATCGGTACATTGGTACCTATATATACTTGGTTACCTAAAGGGCATTACTGTAAATTTTTTCAGGTTTCACACGCGTCCCACGTATAGTTAATATT
Gene Information
|
NCBI Accession
|
YP_001718618.1
|
|
Location
|
105-449 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCTCTAGTTCATCCTTTCCCTGAAAGCTTGCACGGCTTTAGATGTATGCTTGCCATCAAATATCTTCAAAGCTTACAGGGCAAATATTCTCCGGATACTGTTGGGCATGAGTTTTTGAAAGATTTTATATGTATTTTGCGTAGTAGGAATTATGCCGAAGCGTTCAATAGATACAGTGACGTCGTTGCCAATGTCTATAACACGACGGAGACTCAATTACGGGAGTCAGTTCAGTCTCCCTGCCTCTGTCCCCACTGTCCCAGACATGTCTTACAAGCGAAGGTCGTGGACTTACAGGCCCATGTATCGCAAGCCCAAGATGTACAGAATGTATAG |
|
Protein Sequence
|
MWDPLVHPFPESLHGFRCMLAIKYLQSLQGKYSPDTVGHEFLKDFICILRSRNYAEAFNRYSDVVANVYNTTETQLRESVQSPCLCPHCPRHVLQAKVVDLQAHVSQAQDVQNV |
|
NCBI Accession
|
YP_001718619.1
|
|
Location
|
265-1041 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCGAAGCGTTCAATAGATACAGTGACGTCGTTGCCAATGTCTATAACACGACGGAGACTCAATTACGGGAGTCAGTTCAGTCTCCCTGCCTCTGTCCCCACTGTCCCAGACATGTCTTACAAGCGAAGGTCGTGGACTTACAGGCCCATGTATCGCAAGCCCAAGATGTACAGAATGTATAGAAGCCGTGATGTTCCTCGTGGGTGTGAAGGCCCGTGTAAGGTTCAGTCCTATGAGCAGCGCCATGATATAGTTCATGTGGGTAAGGTCATATGTGTTTCTGACGTCACTCGTGGTAACGGGCTTACACATCGTGTTGGAAAGAGGTTTTGTGTAAAGTCTGTGTATGTGTTGGGGAAGGTCTGGATGGATGAGAACATCAAGACTAAAAATCACACTAACACTGTCATGTTTTTTTTAGTGCGTGATAGGAGGCCATATGGGTCTCCCCAGGATTTTGGTCAGGTTTTTAACATGTATGATAATGAGCCTAGTACTGCCACTGTAAAAAATGATAATAGAGATCGATTCCAAGTTCTTCGTAGATTTCAAGCTACTGTAACGGGAGGTCAGTATGCAAGCAAGGAGCAAGCAATAGTTAAGAAGTTCATGAAGATTAACAACCATGTCACTTACAATCATCAGGAGGCTGCGAAGTACGATAACCACACAGAAAATGCTTTGTTGTTATATATGGCATGTACTCATGCTAGTAATCCAGTGTATGCTACGTTGAAGATCAGAATCTATTTCTATGATTCTGTTCAAAATTAA |
|
Protein Sequence
|
MPKRSIDTVTSLPMSITRRRLNYGSQFSLPASVPTVPDMSYKRRSWTYRPMYRKPKMYRMYRSRDVPRGCEGPCKVQSYEQRHDIVHVGKVICVSDVTRGNGLTHRVGKRFCVKSVYVLGKVWMDENIKTKNHTNTVMFFLVRDRRPYGSPQDFGQVFNMYDNEPSTATVKNDNRDRFQVLRRFQATVTGGQYASKEQAIVKKFMKINNHVTYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_001718620.1
|
|
Location
|
1038-1442 |
|
Gene Name
|
C3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAACTCATCACTGCAGCTCAGGCAGAGAATGGCGTATATACCTGGATGATAACAAATCCCCTCTATTTCAAGATATCCCAACACGACAAGAGGCCGTTCCTGAGGAACCACGACATCATAACGGTACAAATACAGTTCAACCACAACCTGAGGAAAGCGTTGGGAATACATCAATGTTTTCTGATCTGCAAAATCTGGACTCGTTTACGTCCTCAGACTTGGCGTTTCTTAAGAGTATTTAAATATCATTGTATGAAATATTTAGATAGTTTAGGAGTTATTAGCATAAACAATGTAATTAGGGCATTCGACTATGTACTATACGATGTACTTGAAAAAACAATCGATGTACAAATTTCTCATATAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAENGVYTWMITNPLYFKISQHDKRPFLRNHDIITVQIQFNHNLRKALGIHQCFLICKIWTRLRPQTWRFLRVFKYHCMKYLDSLGVISINNVIRAFDYVLYDVLEKTIDVQISHIIKFNIY |
|
NCBI Accession
|
YP_001718621.1
|
|
Location
|
1183-1590 |
|
Gene Name
|
C2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCAGAATTCATCACCATCACACAACCATTGTACTCAAGTTCCCATCAAAGTCCAACACAAAATAGCCAAGAAGAGACCGATACGCAGGCGGAGAATTGATCTTCCGTGCGGCTGCTCTTACTATTTAGGACTTAATTGTGCGTCATATGGATTCTCGCACAGGGGAACTCATCACTGCAGCTCAGGCAGAGAATGGCGTATATACCTGGATGATAACAAATCCCCTCTATTTCAAGATATCCCAACACGACAAGAGGCCGTTCCTGAGGAACCACGACATCATAACGGTACAAATACAGTTCAACCACAACCTGAGGAAAGCGTTGGGAATACATCAATGTTTTCTGATCTGCAAAATCTGGACTCGTTTACGTCCTCAGACTTGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQNSSPSHNHCTQVPIKVQHKIAKKRPIRRRRIDLPCGCSYYLGLNCASYGFSHRGTHHCSSGREWRIYLDDNKSPLFQDIPTRQEAVPEEPRHHNGTNTVQPQPEESVGNTSMFSDLQNLDSFTSSDLAFLKSI |
|
NCBI Accession
|
YP_001718622.1
|
|
Location
|
1490-2578 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGCACCTCCCAGAAAATTCCAAATAAATGCCAAAAATTATTTTCTTACATATCCCAAATGCTCTCTTACTAAAGAGGAAACCCTTACCCAATTACAAAACCTAGAAACACCAACAAATAAAAAATTCATCAAGATCTGCAGAGAACTGCACGAAGATGGGAGCCCTCATCTCCATGTGCTCATCCAGTTCGAGGGGAAATACAGATGCACGAATCAACGATTCTTCGATTTGGTATCCCCAACCAGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAATCCTATATTGATAAAGACGGAGACACCGTCGAATGGGGTGAGTTTCAGGTCGACGGAAGATCTGCTAGAGGGGGTCAACAAACAGCCAATGATGCTTACGCCAAAGCAATTAACACAGGAAGTAAGTCGGAGGCTCTTAATGTAATTAGAGAATTAGCCCCTAAAGATTATATTTTACAATTTCACAATTTAAATGCGAATTTAGATAGAATTTTTGCACCTCCTTTAGAGGTTTTTGTTTGTCCTTTTCTTCCTTCTTCTTTCGATCAAGTTCCAAAAGAACTTGAAGAATGGGTTTCCGAGAATGTCAGGGATGCCGCTGCGCGGCCTTGGAGGCCCATAAGTATTGTAATAGAAGGCAATAGTAGAACAGGAAAGACGATGTGGGCTAGATCTCTGGGCCAACACAATTATCTATGCGGACATTTGGACCTAAGCCCAAAGGTTTACAGCAATGATGCTTGGTATAACGTCATTGATGACGTTGATCCGCATTATCTAAAGCATTTTAAAGAGTTCATGGGGGCCCAAAGAGACTGGCAAAGCAACACGAAGTACGGGAAACCAATTCAAATTAAAGGTGGAATACCCACTATCTTCCTCTGCAATCCTGGTCCTACATCATCGTATAAAGAGTACTTGGATGAGGACAAAAATAGGGAACTCAAAAATTGGGCACTAAAAAATGCAGAATTCATCACCATCACACAACCATTGTACTCAAGTTCCCATCAAAGTCCAACACAAAATAGCCAAGAAGAGACCGATACGCAGGCGGAGAATTGA |
|
Protein Sequence
|
MAPPRKFQINAKNYFLTYPKCSLTKEETLTQLQNLETPTNKKFIKICRELHEDGSPHLHVLIQFEGKYRCTNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGEFQVDGRSARGGQQTANDAYAKAINTGSKSEALNVIRELAPKDYILQFHNLNANLDRIFAPPLEVFVCPFLPSSFDQVPKELEEWVSENVRDAAARPWRPISIVIEGNSRTGKTMWARSLGQHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKNRELKNWALKNAEFITITQPLYSSSHQSPTQNSQEETDTQAEN |
|
NCBI Accession
|
YP_001718623.1
|
|
Location
|
2131-2421 |
|
Gene Name
|
C1 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCATGTGCTCATCCAGTTCGAGGGGAAATACAGATGCACGAATCAACGATTCTTCGATTTGGTATCCCCAACCAGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAATCCTATATTGATAAAGACGGAGACACCGTCGAATGGGGTGAGTTTCAGGTCGACGGAAGATCTGCTAGAGGGGGTCAACAAACAGCCAATGATGCTTACGCCAAAGCAATTAACACAGGAAGTAAGTCGGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MGALISMCSSSSRGNTDARINDSSIWYPQPDQHISIQTFRELNQAPTSNPILIKTETPSNGVSFRSTEDLLEGVNKQPMMLTPKQLTQEVSRRLLM |