Tomato leaf curl Bangladesh virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000840445.1 |
| Isolate | Bangladesh |
| Release date | 2015/2/12 |
| Submitter | Shih,S.L., Tsai,W.S., Nakhla,M.K., Maxwell,D.P., Rashid,M.H., Green,S.K. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
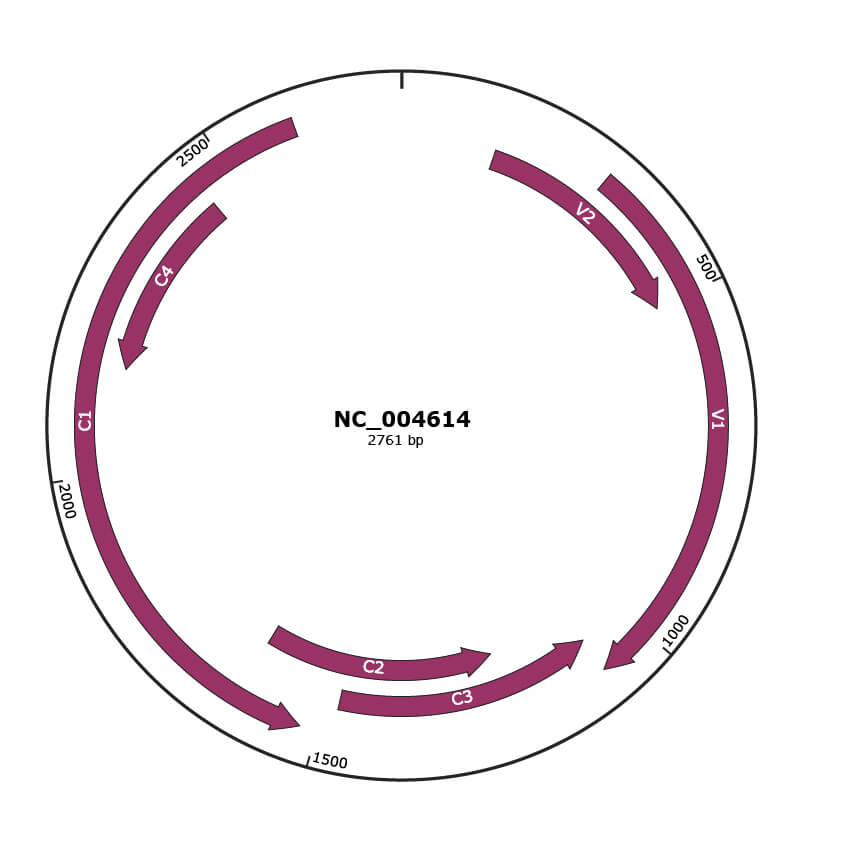
JBrowse
Genome
NC_004614
Gene Information
| NCBI Accession | NP_803245.1 |
|---|---|
| Location | 146-502 |
| Gene Name | V2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCTTTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTAGATGTATGTTAGCAGTTAAATATCTTCAGTTAGTAGAAAAGACTTATTCTCCCGACACATTAGGGTACGATTTAATTAGGGATTTAATTTCAGTCATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAGAGCATGGGCCAACAGGCCCATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTCCCTAG |
| Protein Sequence | MWDPLVNEFPETVHGFRCMLAVKYLQLVEKTYSPDTLGYDLIRDLISVIRARNYVEATSRYNHFHARFEGTPPSQLRQPICEPCCCPHCPRHQSKSMGQQAHEQEAQDVQDVQKSRCP |
| NCBI Accession | NP_803246.1 |
|---|---|
| Location | 306-1076 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAGAGCATGGGCCAACAGGCCCATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTCCCTAGAGGCTGTGAAGGCCCATGTAAGGTGCAGTCCTTTGAGTCTAGACATGACATTCAGCATATAGGTAAAGTCATGTGTGTCAGTGATGTTACTCGTGGGACTGGGCTGACCCATCGAGTGGGTAAAAGGTTTTGTGTTAAGTCTGTGTATGTTTTGGGTAAGATATGGATGGACGAAAATATTAAGACCAAGAATCACACCAATAGTGTGATGTTTTTTCTTGTTAGGGATCGTAGGCCTGTTGATAAACCCCAAGACTTTGGAGAAGTGTTTAACATGTTTGATAATGAGCCCAGTACGGCTACTGTGAAGAATGTGCATCGTGACAGGTATCAAGTGCTTCGGAAATGGCATGCAACTGTTACTGGTGGACAGTATGCGTCTAAGGAACAAGCTCTCGTGAAGAAGTTTGTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAAGCTGGCAAGTATGAGAATCATTCTGAGAATGCGTTAATGTTGTATATGGCATGTACACATGCCTCTAACCCAGTGTATGCTACTTTGAAGATACGGATCTATTTCTATGATTCCGTAACAAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFDSPYASRAAAPIVRVTKARAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDIQHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | NP_803247.1 |
|---|---|
| Location | 1073-1477 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCACGCACCGGGGAACCCATCACTGCAGCTCAAGCAGTGAATGGCGTGTTTACCTGGGAGATTCAAAATCCACTCTATTTCAAGATAACAGAGCACCACAACAGGCCATTCCTGACAAACAGAGACATCATCATCATCCAACTTCAGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTCCTAGTCTACCGAATCTGGATGACTTCACAGCCTCAGACTGGTCGTTTCTTAAGAGTCTTTAAGACTCAAGTGTTTAAATATTTAGATAATTTAGGAGTTATCAGTATTAATAATGTAATTCGTGCAGTTGATCATGTATTATGGGATGTATTAGAACATATTGTATATGTAGACCAATCTTATTCAATAAAATTCAATATTTATTAA |
| Protein Sequence | MDSRTGEPITAAQAVNGVFTWEIQNPLYFKITEHHNRPFLTNRDIIIIQLQFNHNLRKALGIHKCFLVYRIWMTSQPQTGRFLRVFKTQVFKYLDNLGVISINNVIRAVDHVLWDVLEHIVYVDQSYSIKFNIY |
| NCBI Accession | NP_803248.1 |
|---|---|
| Location | 1218-1622 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCGATCTTCGTCACCCTCGAAGGCGCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAAGATAGCCAAGAAGGGGACCAGGCGTCGTCGTGTTGATCTCCCTTGTGGATGTTCATACTTTATAGCACTAGCCTGCCACGATCATGGATTCACGCACCGGGGAACCCATCACTGCAGCTCAAGCAGTGAATGGCGTGTTTACCTGGGAGATTCAAAATCCACTCTATTTCAAGATAACAGAGCACCACAACAGGCCATTCCTGACAAACAGAGACATCATCATCATCCAACTTCAGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTCCTAGTCTACCGAATCTGGATGACTTCACAGCCTCAGACTGGTCGTTTCTTAAGAGTCTTTAA |
| Protein Sequence | MRSSSPSKAHSTQVPIKVQHKIAKKGTRRRRVDLPCGCSYFIALACHDHGFTHRGTHHCSSSSEWRVYLGDSKSTLFQDNRAPQQAIPDKQRHHHHPTSVQSQPEESVGDTQMFPSLPNLDDFTASDWSFLKSL |
| NCBI Accession | NP_803249.1 |
|---|---|
| Location | 1525-2610 |
| Gene Name | C1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCTCAACCGAAACGTTTCCAAATATATGCTAAAAATTATTTCTTAACATATCCACAATGTTCTCTTACTAAAGAAGAGGCACTTTCCCAAATAAAAAACCTCGCCACACCTACTAATAAATTATTCATTCGCGTTTCACGGGAACTGCACGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGAAAATTCAAGTGTCAGAACAACAGATTCTTCGACCTGGTTTCCACAACCAGGTCAGCAAATTTCCATCCGAACATTCAGGGAGCTAAGAGCGCGTCAGATGTCAAAGCCTATGTGGAGAAAGACGGAGACTTCATTGATTTTGGAGTTTTCCAGATCGATGGCAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAGGCTGCGGCCCTCAATATTTTAAGGGAGAAGGCTCCCAAAGATTTTGTATTACAGTTTCATAATTTAAATGCTAATTTAGATAGGATTTTTACACCTCCGGTGGAGGTTTATGTTTCTCCTTTTAATTCATCTTCTTTTGATCAAGTTCCGGAGGAACTTGAAGAATGGGCTGCCGAGAACGTTGTCAGTGCCGCTGCGCGGCCTTTAAGACCCATAAGTATAGTGATAGAGGGTGATAGTCGAACGGGGAAGACGATGTGGGCCAGATCACTGGGACCGCATAACTATTTGTGTGGTCATCTAGACCTTAGCCCAAAGGTGTACAATAATGAGGCCTGGTTCAACATCATAGATGACGTCGATCCCCACTACCTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGGGACTGGCAATCAAATACAAAATACGGAAAGCCAGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCCAATTCAAGTTATAAAGAGTTCTTGGATGAAGAGAAGAATGCTGCACTCAAGAATTGGGCTTTAAAGAATGCGATCTTCGTCACCCTCGAAGGCGCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAAGATAGCCAAGAAGGGGACCAGGCGTCGTCGTGTTGA |
| Protein Sequence | MPQPKRFQIYAKNYFLTYPQCSLTKEEALSQIKNLATPTNKLFIRVSRELHENGEPHLHVLIQFEGKFKCQNNRFFDLVSTTRSANFHPNIQGAKSASDVKAYVEKDGDFIDFGVFQIDGRSARGGCQSANDAYAEAINSGSKAAALNILREKAPKDFVLQFHNLNANLDRIFTPPVEVYVSPFNSSSFDQVPEELEEWAAENVVSAAARPLRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYNNEAWFNIIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNAALKNWALKNAIFVTLEGALYSGSNQSAAQDSQEGDQASSC |
| NCBI Accession | NP_803250.1 |
|---|---|
| Location | 2160-2453 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGAAAATTCAAGTGTCAGAACAACAGATTCTTCGACCTGGTTTCCACAACCAGGTCAGCAAATTTCCATCCGAACATTCAGGGAGCTAAGAGCGCGTCAGATGTCAAAGCCTATGTGGAGAAAGACGGAGACTTCATTGATTTTGGAGTTTTCCAGATCGATGGCAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCCAAGGCTGCGGCCCTCAATATTTTAA |
| Protein Sequence | MGNLIFTCSSSSKENSSVRTTDSSTWFPQPGQQISIRTFRELRARQMSKPMWRKTETSLILEFSRSMADQLEEVANLPTTHMPRQSIQGPRLRPSIF |
References More References in PubMed
| 1 |
Vo TTB, et al. Microorganisms. 2023 Dec 1;11(12):2907. doi: 10.3390/microorganisms11122907. PMID: 38138051 |
|---|---|
| 2 |
Mastrochirico M, et al. Plants (Basel). 2023 Jun 21;12(13):2399. doi: 10.3390/plants12132399. PMID: 37446959 |
| 3 |
Vignesh S, et al. Front Microbiol. 2023 Oct 26;14:1268333. doi: 10.3389/fmicb.2023.1268333. eCollection 2023. PMID: 37965544 |
| 4 |
First Report of Tomato leaf curl New Delhi virus Infecting Tomato in Bangladesh. Maruthi MN, et al. Plant Dis. 2005 Sep;89(9):1011. doi: 10.1094/PD-89-1011C. PMID: 30786642 |
| 5 |
Hamim I, et al. Arch Virol. 2019 Jun;164(6):1661-1665. doi: 10.1007/s00705-019-04235-8. Epub 2019 Apr 4. PMID: 30949815 |
| 6 |
Development of a New Molecular Marker for the Resistance to Tomato Yellow Leaf Curl Virus. Nevame AYM, et al. Biomed Res Int. 2018 Jul 17;2018:8120281. doi: 10.1155/2018/8120281. eCollection 2018. PMID: 30105248 |
| 7 |
Krishnan N, et al. Physiol Mol Biol Plants. 2025 Aug;31(8):1363-1374. doi: 10.1007/s12298-025-01570-w. Epub 2025 Mar 7. PMID: 41080515 |
| 8 |
Varun P, et al. 3 Biotech. 2018 May;8(5):243. doi: 10.1007/s13205-018-1254-7. Epub 2018 May 8. PMID: 29744275 |
| 9 |
Molecular Characterization of Tomato and Chili Leaf Curl Begomoviruses from Pakistan. Shih SL, et al. Plant Dis. 2003 Feb;87(2):200. doi: 10.1094/PDIS.2003.87.2.200A. PMID: 30812928 |
| 10 |
Prasad KSUD, et al. Virusdisease. 2024 Sep;35(3):484-495. doi: 10.1007/s13337-024-00891-w. Epub 2024 Sep 16. PMID: 39464737 |