Tomato leaf curl Arusha virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000868885.1 |
| Isolate |
Tanzania:Kilimanjaro |
| Release date |
2015/2/13 |
| Submitter |
Shih,S.L., Tsai,W.S., Green,S.K., Lee,L.M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
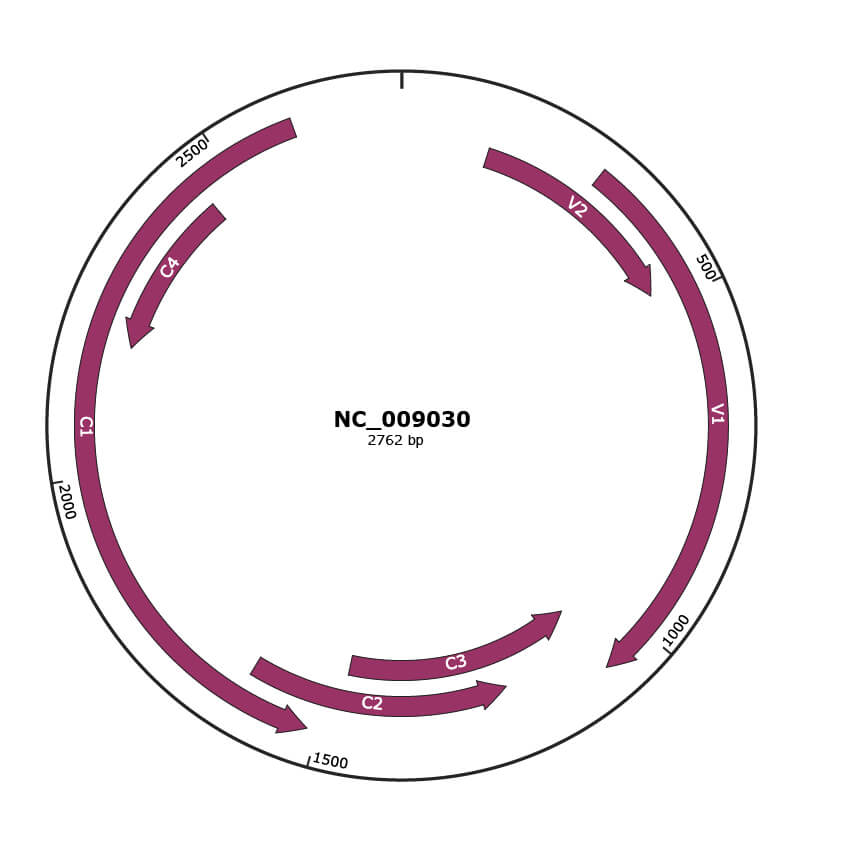
JBrowse
Genome
ACCGGATGGCCGCGCCCCCGAAAAAGCATGGACCCCCTTGAAATATACGGAGCCAATCAGATTGCAGCCTCAATGCTTAGTTAATTTTTTTTTTGTCTTTATATACTTGGCTGTTAAGTATTAAACGCCGTCATTATGTGGGATCCGTTGGTAAATGAGTTTCCGGAGTCTGTTCACGGGTTTCATTGTATGCTTGCCATAAAATATTTGCAGGCCGTTGAAGAGTCTTACGAGCCCAATACATTGGGCCACGATTTAATTAGAGATTTAATCTCTGTAGTTAGAGCCCGGGATTATGTCGAAGCGACCCGCCGATATAATCATTTCCACGCCCGCCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTATTCCAGCCGTGCTGCTGTCCCCATTGTCCCAGGCACAAGCAAACGCAGGTCATGGACGTACAGGCCCATGTATCGCAAGCCCAGAATGTATCGCATGTTCCGTAGTCCAGATGTTCCTCGGGGATGTGAGGGTCCCTGTAAGGTTCAGTCTTATGAGCAGAGGGATGATGTGAAGCACACCGGTATTGTTCGTTGTGTTAGTGATGTAACTAGAGGTAATGGAATTACTCATGGAGTAGGAAAACGGTTCTGCATTAAGTCCATATACATTTTAGGAAAAATATGGATGGATGAGAATATCAAGAAGCAGAATCATACTAATCAGGTCATGTTTTTTTTGGTCCGTGATAGAAGGCCCTATGGCCCAAGCCCAATGGATTTTGGGCAGGTGTTTAACATGTTTGATAATGAGCCCAGTACAGCCACTGTGAAGAATGATCTCCGAGACAGATATCAAGTTTTGCGGAAATTTCATGCAACTGTTGTCGGTGTCCCCTCTGGGATGAAAGAGCAGGCGTTACTTAAAAGATTTTTTAGAATTAATAATCATGTAGTTTATAATCATCAGGAGACTGCTAAGTATGAGAATCATACTGAGAATGCTCTGTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACGTTGAAAATACGTATCTATTTCTATGATTCAGTTGGGAATTAATAAAGTTTGAATTTTATATCATAATTTTGTTCCACCCATAAAGTGCCATTGATTACATCAAACAATACATATTCTATTGCTCTAATTACATTATTAATTGAAATTACACCAAGATTGTCTAAATATTTCCTAACTTGAGTCTTAAAGACTCTTAAGAAAAGACCAGTCTGAGGCTGTAAGGTTGTCCAGATCTTGAAGGCCATGAAACACTTGTGAATCCCCAGTTCCTTCCTTAGGTTGTGGTTGAATCGGATTTGTACTGTGATGATGTCGTGGTTGTAGTTGAACGGTCTCTTTGAGTGTTCCGTGATGCTGAAATATAGGGGATTGGCGATTTCCCAGGTATAGACGCCACTCTGTGCCTGATGCACAGTGATGAGTTCCCCGGTGCGTAAATCCATGGTTGCGACAGTTGAGCGACAAGTAGTACGAGCACCCGCAATTAAGGTCTATCCTCTTCCTCCGCTGAAGCCTCTGTTTGGCTGCTCTGTGTTGGACCTTGATGGGAACTTGAGTACAATGGCTGTTGGATGGTGAAGAAGACCGCATTTTTAATTGCCCAGGCCTTTAATGGTGCGTTCTTTTCCTCATCCAAGTACTCTTTATATGATGAAGTGGGTCCTGGATTGCAGAGGAAGATTGCCGGGATACCTCCTTTAATTTGAATTGGTTTCCCGTACTTTGTGTTGCTTTGCCAGTCCCTTTGTGCGCCCATGAATTCTTTAAAGTGCTTTAGATAATGAGGATCGACGTCATCAATGACGTTGTACCAAGCATTATTACTGTACACCTTTGGACTGAGGTCAAGATGACCACACAAATAATTGTGTGGTCCTAATGACCTAGCCCACATTGTCTTGCCGGTACGACTATCCCCTTCAATCACAATACTCATGGGTCTCAATGGCCGCGCAGCGGCAGTGACAACATTCTGTGCCGCCCACTCTTCAAGTTCCTCTGGAACTTGATCGAACGAAGAACATAAGAAAGGTGAAACATATTCCTCCAACGGAGGTGTAAAAATCCTATCTAAATTACTTTTCAAATTATGATACTGAAAAATAAAATCTTTAGGGAGTTTCTCCCTAATAATAGCCAGAGCGGCTTCAGCGGACCCTGCGTTTAATGCCTCGGCGCATGCGTCGTTAGCATTATGGCAGCCTCCTCTAGCACTTCTGCCGTCGATCTGGAATTCCCCCCATTCGAGTGCGTCTCCATCCTTGTCGATGTAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTGGTTGGGGATACCAGGTCGAAGAATCTGTTATTTTTGCAGTTGAATTTTCCTTCGAACTGAATAAGCACGTGGAGATGAGGCTCCCCATCTTCGTGTAGTTCTCTGCAAATTTTGATGAATTTTTTATTTGTTGGAGTATCAGTATTTAATAATTGAGATAGTGCTTCTTCTTTATTTAGAGAGCATTTGGGATAAGTGAGGAAATAATTTTTGGAATTTATTTGGAAACGCTTAGGAGGAGGCATGTTGGTCAATGGGTACCGATTGACTCACTTGGAATGCTTCTCCTGGTATATCGGTACCCAATATATAGTGGGTACCGAATGCCAGTATTGTAATAACAAAAAGTTACTCTACCCTTATTGTCAAATTGTTAAAGCGGTCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_001040008.1
|
|
Location
|
136-480 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGATCCGTTGGTAAATGAGTTTCCGGAGTCTGTTCACGGGTTTCATTGTATGCTTGCCATAAAATATTTGCAGGCCGTTGAAGAGTCTTACGAGCCCAATACATTGGGCCACGATTTAATTAGAGATTTAATCTCTGTAGTTAGAGCCCGGGATTATGTCGAAGCGACCCGCCGATATAATCATTTCCACGCCCGCCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTATTCCAGCCGTGCTGCTGTCCCCATTGTCCCAGGCACAAGCAAACGCAGGTCATGGACGTACAGGCCCATGTATCGCAAGCCCAGAATGTATCGCATGTTCCGTAG |
|
Protein Sequence
|
MWDPLVNEFPESVHGFHCMLAIKYLQAVEESYEPNTLGHDLIRDLISVVRARDYVEATRRYNHFHARLEGSSKAELRQPLFQPCCCPHCPRHKQTQVMDVQAHVSQAQNVSHVP |
|
NCBI Accession
|
YP_001040009.1
|
|
Location
|
296-1072 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCCGCCGATATAATCATTTCCACGCCCGCCTCGAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCTTATTCCAGCCGTGCTGCTGTCCCCATTGTCCCAGGCACAAGCAAACGCAGGTCATGGACGTACAGGCCCATGTATCGCAAGCCCAGAATGTATCGCATGTTCCGTAGTCCAGATGTTCCTCGGGGATGTGAGGGTCCCTGTAAGGTTCAGTCTTATGAGCAGAGGGATGATGTGAAGCACACCGGTATTGTTCGTTGTGTTAGTGATGTAACTAGAGGTAATGGAATTACTCATGGAGTAGGAAAACGGTTCTGCATTAAGTCCATATACATTTTAGGAAAAATATGGATGGATGAGAATATCAAGAAGCAGAATCATACTAATCAGGTCATGTTTTTTTTGGTCCGTGATAGAAGGCCCTATGGCCCAAGCCCAATGGATTTTGGGCAGGTGTTTAACATGTTTGATAATGAGCCCAGTACAGCCACTGTGAAGAATGATCTCCGAGACAGATATCAAGTTTTGCGGAAATTTCATGCAACTGTTGTCGGTGTCCCCTCTGGGATGAAAGAGCAGGCGTTACTTAAAAGATTTTTTAGAATTAATAATCATGTAGTTTATAATCATCAGGAGACTGCTAAGTATGAGAATCATACTGAGAATGCTCTGTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACGTTGAAAATACGTATCTATTTCTATGATTCAGTTGGGAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPYSSRAAVPIVPGTSKRRSWTYRPMYRKPRMYRMFRSPDVPRGCEGPCKVQSYEQRDDVKHTGIVRCVSDVTRGNGITHGVGKRFCIKSIYILGKIWMDENIKKQNHTNQVMFFLVRDRRPYGPSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVLRKFHATVVGVPSGMKEQALLKRFFRINNHVVYNHQETAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVGN |
|
NCBI Accession
|
YP_001040010.1
|
|
Location
|
1069-1473 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTTACGCACCGGGGAACTCATCACTGTGCATCAGGCACAGAGTGGCGTCTATACCTGGGAAATCGCCAATCCCCTATATTTCAGCATCACGGAACACTCAAAGAGACCGTTCAACTACAACCACGACATCATCACAGTACAAATCCGATTCAACCACAACCTAAGGAAGGAACTGGGGATTCACAAGTGTTTCATGGCCTTCAAGATCTGGACAACCTTACAGCCTCAGACTGGTCTTTTCTTAAGAGTCTTTAAGACTCAAGTTAGGAAATATTTAGACAATCTTGGTGTAATTTCAATTAATAATGTAATTAGAGCAATAGAATATGTATTGTTTGATGTAATCAATGGCACTTTATGGGTGGAACAAAATTATGATATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDLRTGELITVHQAQSGVYTWEIANPLYFSITEHSKRPFNYNHDIITVQIRFNHNLRKELGIHKCFMAFKIWTTLQPQTGLFLRVFKTQVRKYLDNLGVISINNVIRAIEYVLFDVINGTLWVEQNYDIKFKLY |
|
NCBI Accession
|
YP_001040011.1
|
|
Location
|
1214-1621 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcriptional activation protein |
|
Coding Region
|
ATGCGGTCTTCTTCACCATCCAACAGCCATTGTACTCAAGTTCCCATCAAGGTCCAACACAGAGCAGCCAAACAGAGGCTTCAGCGGAGGAAGAGGATAGACCTTAATTGCGGGTGCTCGTACTACTTGTCGCTCAACTGTCGCAACCATGGATTTACGCACCGGGGAACTCATCACTGTGCATCAGGCACAGAGTGGCGTCTATACCTGGGAAATCGCCAATCCCCTATATTTCAGCATCACGGAACACTCAAAGAGACCGTTCAACTACAACCACGACATCATCACAGTACAAATCCGATTCAACCACAACCTAAGGAAGGAACTGGGGATTCACAAGTGTTTCATGGCCTTCAAGATCTGGACAACCTTACAGCCTCAGACTGGTCTTTTCTTAAGAGTCTTTAA |
|
Protein Sequence
|
MRSSSPSNSHCTQVPIKVQHRAAKQRLQRRKRIDLNCGCSYYLSLNCRNHGFTHRGTHHCASGTEWRLYLGNRQSPIFQHHGTLKETVQLQPRHHHSTNPIQPQPKEGTGDSQVFHGLQDLDNLTASDWSFLKSL |
|
NCBI Accession
|
YP_001040012.1
|
|
Location
|
1515-2609 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTCCTCCTAAGCGTTTCCAAATAAATTCCAAAAATTATTTCCTCACTTATCCCAAATGCTCTCTAAATAAAGAAGAAGCACTATCTCAATTATTAAATACTGATACTCCAACAAATAAAAAATTCATCAAAATTTGCAGAGAACTACACGAAGATGGGGAGCCTCATCTCCACGTGCTTATTCAGTTCGAAGGAAAATTCAACTGCAAAAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGACGCACTCGAATGGGGGGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCATAATGCTAACGACGCATGCGCCGAGGCATTAAACGCAGGGTCCGCTGAAGCCGCTCTGGCTATTATTAGGGAGAAACTCCCTAAAGATTTTATTTTTCAGTATCATAATTTGAAAAGTAATTTAGATAGGATTTTTACACCTCCGTTGGAGGAATATGTTTCACCTTTCTTATGTTCTTCGTTCGATCAAGTTCCAGAGGAACTTGAAGAGTGGGCGGCACAGAATGTTGTCACTGCCGCTGCGCGGCCATTGAGACCCATGAGTATTGTGATTGAAGGGGATAGTCGTACCGGCAAGACAATGTGGGCTAGGTCATTAGGACCACACAATTATTTGTGTGGTCATCTTGACCTCAGTCCAAAGGTGTACAGTAATAATGCTTGGTACAACGTCATTGATGACGTCGATCCTCATTATCTAAAGCACTTTAAAGAATTCATGGGCGCACAAAGGGACTGGCAAAGCAACACAAAGTACGGGAAACCAATTCAAATTAAAGGAGGTATCCCGGCAATCTTCCTCTGCAATCCAGGACCCACTTCATCATATAAAGAGTACTTGGATGAGGAAAAGAACGCACCATTAAAGGCCTGGGCAATTAAAAATGCGGTCTTCTTCACCATCCAACAGCCATTGTACTCAAGTTCCCATCAAGGTCCAACACAGAGCAGCCAAACAGAGGCTTCAGCGGAGGAAGAGGATAGACCTTAA |
|
Protein Sequence
|
MPPPKRFQINSKNYFLTYPKCSLNKEEALSQLLNTDTPTNKKFIKICRELHEDGEPHLHVLIQFEGKFNCKNNRFFDLVSPTRSTHFHPNIQGAKSSSDVKSYIDKDGDALEWGEFQIDGRSARGGCHNANDACAEALNAGSAEAALAIIREKLPKDFIFQYHNLKSNLDRIFTPPLEEYVSPFLCSSFDQVPEELEEWAAQNVVTAAARPLRPMSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNNAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPAIFLCNPGPTSSYKEYLDEEKNAPLKAWAIKNAVFFTIQQPLYSSSHQGPTQSSQTEASAEEEDRP |
|
NCBI Accession
|
YP_001040013.1
|
|
Location
|
2195-2452 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTGCTTATTCAGTTCGAAGGAAAATTCAACTGCAAAAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGATGGAGACGCACTCGAATGGGGGGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCATAATGCTAACGACGCATGCGCCGAGGCATTAA |
|
Protein Sequence
|
MGSLISTCLFSSKENSTAKITDSSTWYPQPGQHISIRTFRELNQAPTSSPTSTRMETHSNGGNSRSTAEVLEEAAIMLTTHAPRH |