Tomato latent virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_003029065.1 |
| Isolate | Cuba: open field near Havana |
| Release date | 2018/8/26 |
| Submitter | Fuentes,A., Carlos,N., Ruiz,Y., Callard,D., Sanchez,Y., Ochagavia,M.E., Seguin,J., Malpica-Lopez,N., Hohn,T., Lecca,M.R., Perez,R., Doreste,V., Rehrauer,H., Farinelli,L., Pujol,M., Pooggin,M.M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
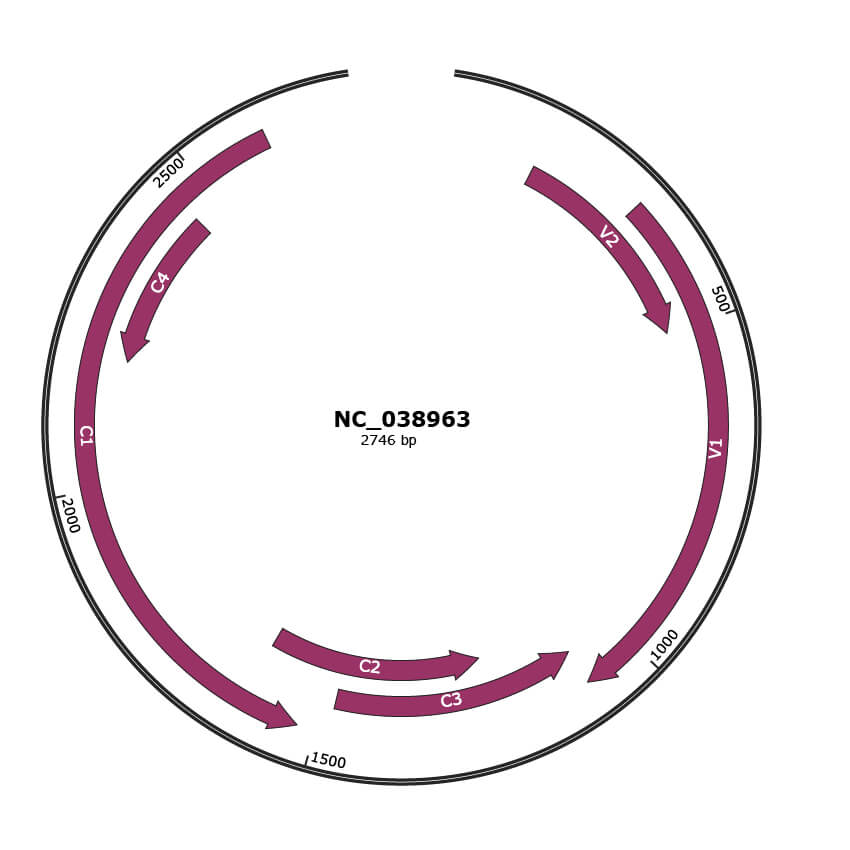
JBrowse
Genome
NC_038963
Gene Information
| NCBI Accession | YP_009508305.1 |
|---|---|
| Location | 149-499 |
| Gene Name | V2 |
| Protein Name | pre-coat protein V2 |
| Coding Region | ATGTGGGATCCACTTCTAAATGAATTTCCTGAATCTGTTCACGGATTTCGTTGTATGTTAGCTATTAAATATTTGCAGTCCGTTGAGGAAACTTACGAGCCCAATACATTGGGCCACGATTTAATTAGGGATCTTATATCTGTTGTAAGGGCCCGTGACTATGTCGAAGCGACCAGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAACCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGACGATCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPESVHGFRCMLAIKYLQSVEETYEPNTLGHDLIRDLISVVRARDYVEATRRYNHFHARLEGSPKAELRQPIQQPCCCPHCPRHKQATIMDVQAHVPKAQNIQNVSKP |
| NCBI Accession | YP_009508306.1 |
|---|---|
| Location | 309-1085 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGGCGATATAATCATTTCCACGCCCGTCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAACCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGACGATCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGATGTTCCCCGTGGATGTGAAGGCCCATGTAAAGTCCAGTCTTATGAGCAGCGGGATGATATTAAGCACACTGGTGTTGTTCGTTGTGTTAGTGATGTTACTCGTGGATCTGGAATTACTCACAGAGTCGGTAAGAGGTTCTGTGTTAAATCGATATATTTTTTAGGTAAAGTCTGGATGGATGAAAATATCAAGAAGCAGAATCACACTAATCAGGTCATGTTCTTTTTGGTCCGTGATAGAAGGCCCTATGGAAGCAGTCCAATGGATTTTGGACAGGTTTTTAATATGTTCGATAATGAGCCCAGTACCGCAACTGTGAAGAATGATTTGCGTGATAGGTTTCAAGTGATGAGGAAATTTCATGCTACAGTTATTGGTGGGCCCTCTGGAATGAAAGAACAGGCATTAGTTAAGAGATTTTTTAAAATTAACAGTCATGTAACGTATAATCATCAGGAGGCAGCCAAGTACGAGAACCATACTGAAAACGCCTTGTTATTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCAACTATGAAAATACGCATCTATTTCTATGATTCCATCATGAATTAA |
| Protein Sequence | MSKRPGDIIISTPVSKVRRRLNFDSPYSNRAAVPIVQGTNKRRSWTYRPMYRKPRIYRMYRSPDVPRGCEGPCKVQSYEQRDDIKHTGVVRCVSDVTRGSGITHRVGKRFCVKSIYFLGKVWMDENIKKQNHTNQVMFFLVRDRRPYGSSPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMRKFHATVIGGPSGMKEQALVKRFFKINSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATMKIRIYFYDSIMN |
| NCBI Accession | YP_009508307.1 |
|---|---|
| Location | 1082-1480 |
| Gene Name | C3 |
| Protein Name | replication enhancer |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACAGAGTAGAGGACCCGTTGTACACCAAGACAAGGGTGTACCACGTACAGATACGGTTCAATCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGGTCAACTTATTTAGCTAGGTTTAGGCACTTAGTCAACCTGTACCTAGATCAGTTAGGCGTGATTTCCATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAGAGCGTATGTAAATTATGTACTGGAAGATCACTCAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGELITAHQAENGVYIWEIENPLYFRIYRVEDPLYTKTRVYHVQIRFNHNLRRALHLHKAYLNFQVWTTSTTASGSTYLARFRHLVNLYLDQLGVISINNVIRAVRFATDRAYVNYVLEDHSIKFKFY |
| NCBI Accession | YP_009508308.1 |
|---|---|
| Location | 1227-1616 |
| Gene Name | C2 |
| Protein Name | transcriptional transactivator |
| Coding Region | ATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGACACACAGGCAGGCCAAGAGGAGGGCCATCAGGAGGAGACGGATTGATCTGGAGTGCGGGTGCTCCATCTACTTCCACATAGGCTGTACGGGACATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACAGAGTAGAGGACCCGTTGTACACCAAGACAAGGGTGTACCACGTACAGATACGGTTCAATCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGGTCAACTTATTTAGCTAG |
| Protein Sequence | MRSSSPSQPPSIKKTHRQAKRRAIRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPLFQDIQSRGPVVHQDKGVPRTDTVQSQPEESVASPQSLPELPSLDDIDDSFWVNLFS |
| NCBI Accession | YP_009508309.1 |
|---|---|
| Location | 1528-2613 |
| Gene Name | C1 |
| Protein Name | replication initiator protein |
| Coding Region | ATGCCACGAAAGGGTTCTTTCTCAGTTAAAGCCAAAAACTATTTCCTCACTTATCCGCAGTGTTCCTTAACCAAAGAGGAGACACTTTCCCAATTACAAAACCTAAAAACTCCGGTGAACAAGAAGTTCATCAAAATCTGCAAAGAGCTCCACGAAAATGGGGAGCCTCATCTCCATGTGCTCATCCAGTTCGAGGGAAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTGTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATGTCGAGAAGGACGGGGACACAATCGAATGGGGAGTGTTCCAGGTCGACGGAAGAAGTGCTCGGGGCGGTCAGCAAACAGCTAATGACGCAGCCGCCGAGGCATTAAACTCTGGAACAAAGGAGGCGGCCCTGAAAATCATCAGGGAGAAGCTACCGGAGAAGTATCTCTTTCAGTTCCACAACCTATCCAGTAACCTAGATAGGATTTTCAGTGAGGCTCCGGAGCCATGGTCTCCTCCGTTTCCCCTCTCCTCTTTCACTAACGTTCCTGACGAGATGCAAGAGTGGGCGGACGGTTATTTTGGGAGGGGTTCCGCTGCGCGGCCAGAAAGACCATTAAGTCTAATAGTCGAAGGTGACTCGAGGACAGGGAAGACGATGTGGGCTCGTGCGTTAGGCCCACATAACTATCTCAGTGGACATCTGGACTTCAATACTCGAGTCTATTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGAGGTATCCCTTCAATCGTGCTTTGCAATCCGGGTGAGGGTGCCAGCTATAAAGAGTTCCTAGACAAAGAGGAAAACATAGGTCTCAGGAACTGGACCATCAAGAATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGACACACAGGCAGGCCAAGAGGAGGGCCATCAGGAGGAGACGGATTGA |
| Protein Sequence | MPRKGSFSVKAKNYFLTYPQCSLTKEETLSQLQNLKTPVNKKFIKICKELHENGEPHLHVLIQFEGKYNCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYVEKDGDTIEWGVFQVDGRSARGGQQTANDAAAEALNSGTKEAALKIIREKLPEKYLFQFHNLSSNLDRIFSEAPEPWSPPFPLSSFTNVPDEMQEWADGYFGRGSAARPERPLSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNTRVYSNEVEYNVIDDVAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKEFLDKEENIGLRNWTIKNAIFITLTAPLYQEDTQAGQEEGHQEETD |
| NCBI Accession | YP_009508310.1 |
|---|---|
| Location | 2199-2456 |
| Gene Name | C4 |
| Protein Name | C4 |
| Coding Region | ATGGGGAGCCTCATCTCCATGTGCTCATCCAGTTCGAGGGAAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTGTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATGTCGAGAAGGACGGGGACACAATCGAATGGGGAGTGTTCCAGGTCGACGGAAGAAGTGCTCGGGGCGGTCAGCAAACAGCTAATGACGCAGCCGCCGAGGCATTAA |
| Protein Sequence | MGSLISMCSSSSRESTTARITDSSIWCPQPGQHISIRTYRELNPAPTSSPMSRRTGTQSNGECSRSTEEVLGAVSKQLMTQPPRH |
References More References in PubMed
| 1 |
First Report of Spinach latent virus in Tomato in New Zealand. Lebas BSM, et al. Plant Dis. 2007 Feb;91(2):228. doi: 10.1094/PDIS-91-2-0228A. PMID: 30781015 |
|---|---|
| 2 |
Spinach latent virus Infecting Tomato in Virginia, United States. Vargas-Asencio J, et al. Plant Dis. 2013 Dec;97(12):1663. doi: 10.1094/PDIS-05-13-0529-PDN. PMID: 30716862 |
| 3 |
VASUDEVA RS, et al. Curr Sci. 1947 Nov;16(11):348-50. PMID: 18918150 |
| 4 |
Favara GM, et al. Phytopathology. 2019 Mar;109(3):480-487. doi: 10.1094/PHYTO-06-18-0203-R. Epub 2019 Jan 8. PMID: 30204547 |
| 5 |
RNA Silencing-Mediated Apple Latent Spherical Virus Vaccine in Plants. Li C, et al. Methods Mol Biol. 2019;2028:273-288. doi: 10.1007/978-1-4939-9635-3_16. PMID: 31228121 |
| 6 |
To Be Seen or Not to Be Seen: Latent Infection by Tobamoviruses. Ilyas R, et al. Plants (Basel). 2022 Aug 21;11(16):2166. doi: 10.3390/plants11162166. PMID: 36015469 |
| 7 |
Molecular characterisation of the full-length genome of olive latent virus 1 isolated from tomato. Hasiów-Jaroszewska B, et al. J Appl Genet. 2011 May;52(2):245-7. doi: 10.1007/s13353-010-0020-2. Epub 2010 Dec 23. PMID: 21181333 |
| 8 |
Mullineaux PM, et al. Plant Mol Biol. 1985 Mar;5(2):125-31. doi: 10.1007/BF00020095. PMID: 24306572 |
| 9 |
Distribution of Tomato spotted wilt virus in dahlia plants. Asano S, et al. Lett Appl Microbiol. 2017 Apr;64(4):297-303. doi: 10.1111/lam.12720. PMID: 28129432 |
| 10 |
First Report of Tomato mosaic virus on Hibiscus rosa-sinensis in China. Huang JG, et al. Plant Dis. 2004 Jun;88(6):683. doi: 10.1094/PDIS.2004.88.6.683C. PMID: 30812606 |