Tomato interveinal chlorosis virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002823985.1 |
| Isolate | Brazil: Pernambuco |
| Release date | 2018/8/25 |
| Submitter | Albuquerque,L.C., Varsani,A., Fernandes,F.R., Pinheiro,B., Martin,D.P., de Tarso Oliveira Ferreira,P., Lemos,T.O., Inoue-Nagata,A.K., Martins,D.P., Ferreira,P.T.O. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
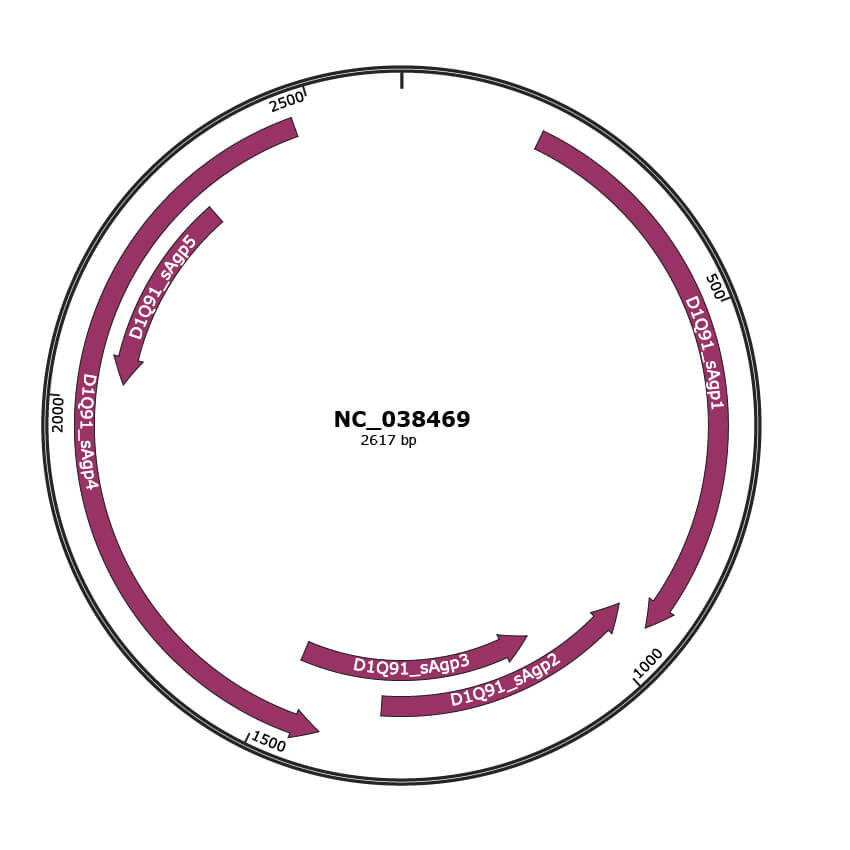
JBrowse
Genome
NC_038469
Gene Information
| NCBI Accession | YP_009506521.1 |
|---|---|
| Location | 188-943 |
| Protein Name | V1 |
| Coding Region | ATGCCTAAGCGCGATGCCCCATGGCGCCACATGGCAGGTACGTCTAAGATTAGCCGGGTCGCTAATTATTCTCCTCGTGCAGGAGTTGGGCCACGATCCAACAAGGCCTCTGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATATATCGGATGTACAGGACCCCCGATGTTCCAAGAGGCTGTGAAGGCCCATGTAAAGTCCAGTCGTATGAGCAGCGTCACGATATATCCCATGTTGGTAAGGTGATGTGCGTCTCCGACGTGACAAGAGGTAATGGTATTACCCACCGTGTAGGGAAGCGTTTTTGTGTTAAGTCCGTTTATATTTTAGGTAAGGTATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGTGTTATGTTCTGGCTGGTCAGAGACCGTAGACCCTATGGGACTCCTATGGACTTCGGCCAAGTTTTTAACATGTTTGACAATGAGCCCAGTACTGCCACGGTCAAGAACGATCTTCGTGATCGTTACCAAGTTATGCATAAATTCTATGCTAAGGTGACAGGTGGACAATACGCAAGCAATGAACAAGCGCTGGTCAAGCGTTTCTGGAGGGTCAACAATCACGTGGTGTACAATCATCAAGAAGCCGGGAAATACGAGAATCATACGGAGAACGCACTATTATTGTATATGGCATGTACTCATGCCTCGAACCCTGTGTATGCGACTTTAAAAATTCGGATCTATTTCTATGATTCGATAATAAATTAA |
| Protein Sequence | MPKRDAPWRHMAGTSKISRVANYSPRAGVGPRSNKASEWVNRPMYRKPRIYRMYRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCVSDVTRGNGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIIN |
| NCBI Accession | YP_009506522.1 |
|---|---|
| Location | 940-1338 |
| Protein Name | C3 |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTGTATACCTGGGAGATATCAAATCCCCTATATTTCAAGATGTACAATGTGGAGGACCTACTCTACACGAGGACGAGAGTCTACCACGTCCAGATACGGTTCAACCACAACCTGCGGAGAGTGTTGGGTCTCCACAAGGCTTATCTCAACTTCCAAGTTTGGACGACATCCCTGAGAGCTTCTGGGATGAGATATTTAAGTAGATTTAAATTTCTTGTTCAGTTGTATCTAGATCAATTAGGCGTTATTTCAGTTAATAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAAATCATATGTTCATGATGTACTAGAGAATCATTCAATAAAATTCAACATTTATTAA |
| Protein Sequence | MDSRTGELITAHQAENGVYTWEISNPLYFKMYNVEDLLYTRTRVYHVQIRFNHNLRRVLGLHKAYLNFQVWTTSLRASGMRYLSRFKFLVQLYLDQLGVISVNNVIRAVRFATDKSYVHDVLENHSIKFNIY |
| NCBI Accession | YP_009506523.1 |
|---|---|
| Location | 1085-1477 |
| Protein Name | C2 |
| Coding Region | ATGCGCAATTCGTCTTTCTCAACTCCCCCCTCTATCAAAGTTCAACATCGGGCAGCTAAAAGAAAGAGGGCAACACGACGAAGACGAATTGATCTACAGTGCGGGTGCTCCATATACGTTCACATCCACTGCGCAGGGCATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTGTATACCTGGGAGATATCAAATCCCCTATATTTCAAGATGTACAATGTGGAGGACCTACTCTACACGAGGACGAGAGTCTACCACGTCCAGATACGGTTCAACCACAACCTGCGGAGAGTGTTGGGTCTCCACAAGGCTTATCTCAACTTCCAAGTTTGGACGACATCCCTGAGAGCTTCTGGGATGAGATATTTAAGTAG |
| Protein Sequence | MRNSSFSTPPSIKVQHRAAKRKRATRRRRIDLQCGCSIYVHIHCAGHGFTHRGTHHCTSGREWRVYLGDIKSPIFQDVQCGGPTLHEDESLPRPDTVQPQPAESVGSPQGLSQLPSLDDIPESFWDEIFK |
| NCBI Accession | YP_009506524.1 |
|---|---|
| Location | 1419-2474 |
| Protein Name | C1 |
| Coding Region | ATGCCACTCCCGAAACGATTTCGTTTAAATGCCAAAAACTATTTCCTCACTTATCCTAAGTGTTCTCTTTCGAAAGAAGAAGCACTTTCCCAACTCTTAGCCTTAACAATACCAGTCAATAAACTATTCGTTCGTGTTGCGAGAGAATTACACGAAGATGGGCAACCTCATCTGCACGTCCTCATACAGTTCGAAGGAAAATACCAGTGCACGAACGAACGATTGTTCGACCTTGTATCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGCAGCTAAGAGCTCGTCAGATGTCAAGGCATACGTGGAGAAAGACGGAGACTTCGTTGATCATGGAGTTTTCCAGATCGATGGAAGATCAGCTAGAGGAGGTCAGCAATCTGCCAACGACACGTATGCCAAGGTTCTTAACGCAGGATCAGTCATGGAGGCCCTCAATATATTAAAGGAGGAACAGCCAAAAGATTATGTTCTTCAGCATCATAATATTCGTTCGAATTTAGAGCGTATATTTGCAAAGGCTCCAGAACCGTGGGTTCCTCCGTTTCCCCTCTCGTCGTTCACTAACGTGCCTGTCGAGATGCAATCTTGGGCACATGACTATTTCGGAAGGGATGCCGCTGCGCGGCCGGAGAGGCCTATCAGTATAATAATCGAGGGTGATTCAAGGACAGGGAAGACCATGTGGGCACGTGCATTAGGGTCCCACAATTACTTGAGCGGTCACCTCGATTTCAATTCAAAGGTGTATTCAAACGATGTGCAGTATAACGTCATTGATGATGTCGCACCGCACTATCTAAAGTTAAAGCACTGGAAAGAACTTATCGGGGCCCAAAGGGACTGGCAATCAAACTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGTATCCCATGCATCGTGCTTTGCAATCCTGGCGAGGGGGCCAGTTATAAATCTTTCCTCGACAAAGAGGAAAACTCAGCATTAAATAATTGGACAAAGCACAATGCGCAATTCGTCTTTCTCAACTCCCCCCTCTATCAAAGTTCAACATCGGGCAGCTAA |
| Protein Sequence | MPLPKRFRLNAKNYFLTYPKCSLSKEEALSQLLALTIPVNKLFVRVARELHEDGQPHLHVLIQFEGKYQCTNERLFDLVSPTRSAHFHPNIQAAKSSSDVKAYVEKDGDFVDHGVFQIDGRSARGGQQSANDTYAKVLNAGSVMEALNILKEEQPKDYVLQHHNIRSNLERIFAKAPEPWVPPFPLSSFTNVPVEMQSWAHDYFGRDAAARPERPISIIIEGDSRTGKTMWARALGSHNYLSGHLDFNSKVYSNDVQYNVIDDVAPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPCIVLCNPGEGASYKSFLDKEENSALNNWTKHNAQFVFLNSPLYQSSTSGS |
| NCBI Accession | YP_009506525.1 |
|---|---|
| Location | 2024-2317 |
| Protein Name | C4 |
| Coding Region | ATGGGCAACCTCATCTGCACGTCCTCATACAGTTCGAAGGAAAATACCAGTGCACGAACGAACGATTGTTCGACCTTGTATCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGCAGCTAAGAGCTCGTCAGATGTCAAGGCATACGTGGAGAAAGACGGAGACTTCGTTGATCATGGAGTTTTCCAGATCGATGGAAGATCAGCTAGAGGAGGTCAGCAATCTGCCAACGACACGTATGCCAAGGTTCTTAACGCAGGATCAGTCATGGAGGCCCTCAATATATTAA |
| Protein Sequence | MGNLICTSSYSSKENTSARTNDCSTLYPQQGQHISIRTFRQLRARQMSRHTWRKTETSLIMEFSRSMEDQLEEVSNLPTTRMPRFLTQDQSWRPSIY |
References More References in PubMed
| 1 |
Tomato chlorosis virus, an emergent plant virus still expanding its geographical and host ranges. Fiallo-Olivé E, et al. Mol Plant Pathol. 2019 Sep;20(9):1307-1320. doi: 10.1111/mpp.12847. Epub 2019 Jul 2. PMID: 31267719 |
|---|---|
| 2 |
Complete genomic analysis of tomato chlorosis virus isolates from Sichuan and Chongqing, China. Yang X, et al. Virology. 2025 Mar;604:110447. doi: 10.1016/j.virol.2025.110447. Epub 2025 Feb 11. PMID: 39961259 |
| 3 |
First Report of Tomato chlorosis virus in China. Zhao RN, et al. Plant Dis. 2013 Aug;97(8):1123. doi: 10.1094/PDIS-12-12-1163-PDN. PMID: 30722472 |
| 4 |
First Report of Tomato chlorosis virus Infecting Tomato Crops in Brazil. Barbosa JC, et al. Plant Dis. 2008 Dec;92(12):1709. doi: 10.1094/PDIS-92-12-1709C. PMID: 30764310 |
| 5 |
First Report of Tomato chlorosis virus in Israel. Segev L, et al. Plant Dis. 2004 Oct;88(10):1160. doi: 10.1094/PDIS.2004.88.10.1160A. PMID: 30795260 |
| 6 |
Navas-Hermosilla E, et al. Front Microbiol. 2021 Jul 26;12:693457. doi: 10.3389/fmicb.2021.693457. eCollection 2021. PMID: 34381428 |
| 7 |
First Report of Tomato chlorosis virus Infecting Tomato in Sudan. Fiallo-Olivé E, et al. Plant Dis. 2011 Dec;95(12):1592. doi: 10.1094/PDIS-08-11-0631. PMID: 30731991 |
| 8 |
First Report of Tomato chlorosis virus Infecting Tomato Crops in Uruguay. Arruabarrena A, et al. Plant Dis. 2014 Oct;98(10):1445. doi: 10.1094/PDIS-11-13-1153-PDN. PMID: 30703967 |
| 9 |
First Report of Tomato chlorosis virus in Puerto Rico. Wintermantel WM, et al. Plant Dis. 2001 Feb;85(2):228. doi: 10.1094/PDIS.2001.85.2.228B. PMID: 30831949 |
| 10 |
First Report of Tomato chlorosis virus Infecting Tomato in Georgia. Sundaraj S, et al. Plant Dis. 2011 Jul;95(7):881. doi: 10.1094/PDIS-02-11-0122. PMID: 30731721 |