Tomato golden mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000839565.1 |
| Release date | 2015/2/12 |
| Submitter | Hamilton,W.D., Stein,V.E., Coutts,R.H., Buck,K.W., Jeffrey,J.L., Pooma,W., Petty,I.T. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
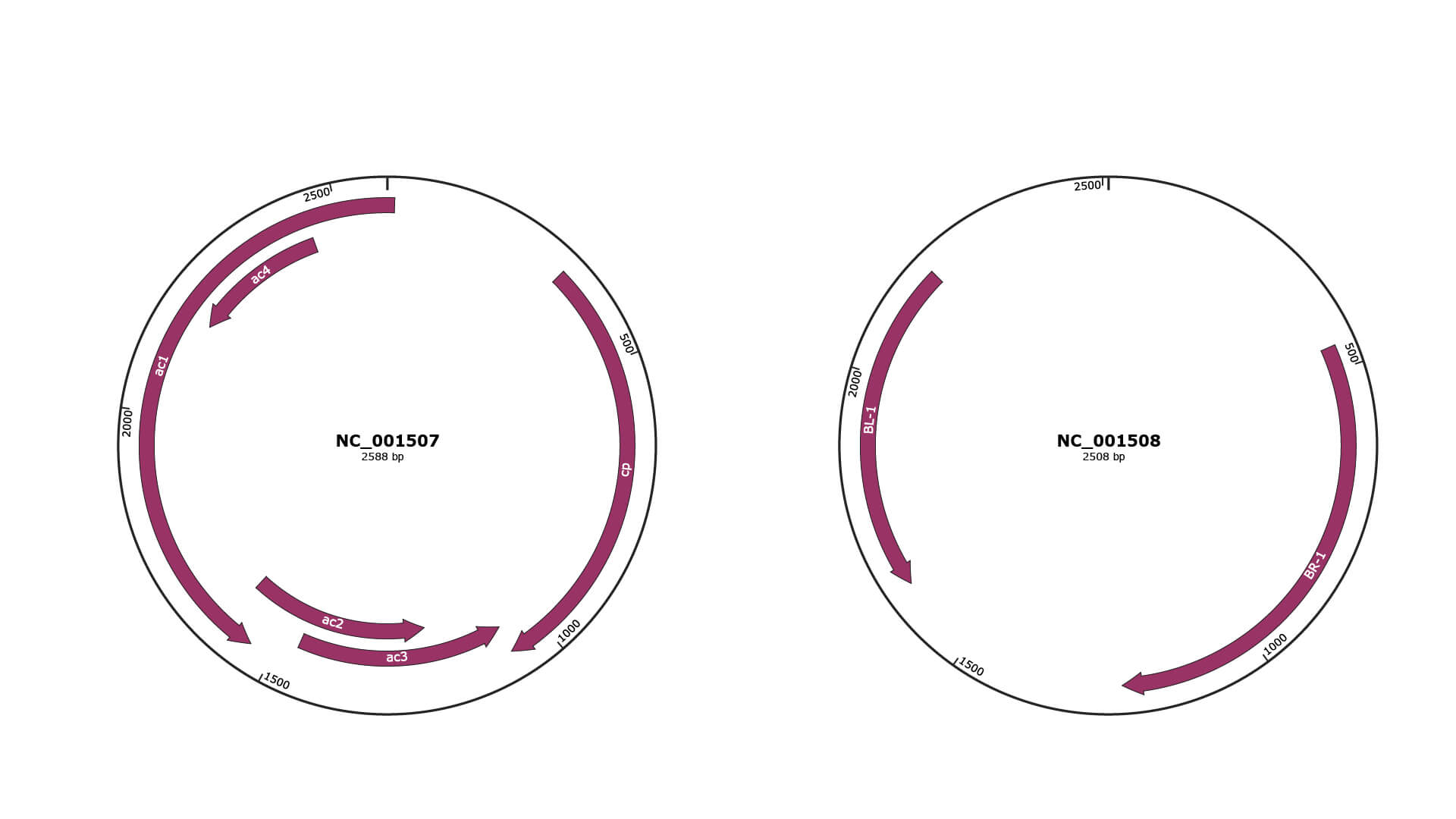
JBrowse
Genome
NC_001507
NC_001508
Gene Information
| NCBI Accession | NP_077735.1 |
|---|---|
| Location | 1543-2588,1-13 |
| Gene Name | ac1 |
| Protein Name | Rep |
| Coding Region | ATGCCATCGCATCCAAAACGGTTTCAAATAAATGCCAAAAATTATTTTCTTACATATCCTCAGTGCTCCTTGTCCAAAGAAGAATCACTTTCTCAATTACAAGCCCTAAACACTCCGATTAACAAAAAATTCATAAAAATCTGCAGAGAGCTTCATGAAGATGGGCAACCTCACCTCCACGTGCTTATTCAGTTCGAGGGAAAATACTGCTGCCAAAATCAACGATTCTTCGACCTGGTATCCCCAACAAGGTCAGCACATTTCCATCCAAACATTCAGAGAGCTAAATCGTCTTCCGACGTCAAGACGTACATCGACAAAGACGGAGATACTCTTGTATGGGGAGAATTCCAGGTCGACGGTCGAAGTGCTAGAGGAGGTTGCCAAACATCTAACGACGCTGCAGCAGAGGCGTTAAATGCTTCTTCCAAAGAAGAAGCCCTGCAGATAATTAGAGAGAAAATCCCAGAAAAATATTTATTTCAGTTCCACAATCTAAATAGCAATTTAGATAGGATATTTGATAAGACTCCTGAACCATGGCTTCCTCCGTTCCACGTCTCATCATTTACTAACGTGCCAGACGAGATGAGACAATGGGCTGAAAATTATTTTGGAAAGAGTTCCGCTGCGCGGCCGGAGAGACCTATTAGTATTATCATCGAGGGCGATAGTCGGACGGGAAAGACTATGTGGGCTCGTTCACTAGGCCCACATAATTATTTGAGCGGGCATTTGGATCTCAATTCTAGGGTTTACTCAAACAAGGTTGAGTATAACGTCATCGATGATGTCACACCGCAATATCTAAAGTTGAAACATTGGAAAGAACTCATTGGGGCCCAAAGAGATTGGCAGACTAACTGTAAATACGGAAAGCCAGTTCAAATTAAAGGAGGTATCCCGTCAATCGTGCTGTGCAATCCTGGAGAGGGTGCTAGCTATAAAGTTTTCCTCGACAAAGAGGAAAACACTCCACTAAAGAACTGGACTTTCCATAATGCGAAATTCGTCTTCCTCAACTCCCCCCTCTATCAAAGCTCAACACAGAGCAGCTAA |
| Protein Sequence | MPSHPKRFQINAKNYFLTYPQCSLSKEESLSQLQALNTPINKKFIKICRELHEDGQPHLHVLIQFEGKYCCQNQRFFDLVSPTRSAHFHPNIQRAKSSSDVKTYIDKDGDTLVWGEFQVDGRSARGGCQTSNDAAAEALNASSKEEALQIIREKIPEKYLFQFHNLNSNLDRIFDKTPEPWLPPFHVSSFTNVPDEMRQWAENYFGKSSAARPERPISIIIEGDSRTGKTMWARSLGPHNYLSGHLDLNSRVYSNKVEYNVIDDVTPQYLKLKHWKELIGAQRDWQTNCKYGKPVQIKGGIPSIVLCNPGEGASYKVFLDKEENTPLKNWTFHNAKFVFLNSPLYQSSTQSS |
| NCBI Accession | NP_041238.1 |
|---|---|
| Location | 327-1070 |
| Gene Name | cp |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCATGGCGTTTAATGGCGGGGACCTCAAAGGTTTCCCGCTCTGCTAATTATTCTCCTCGAGGAAGTTTGCCTAAGCGTGATGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGATCACTAAGAGGCCCCGATGTTCCTAAAGGATGTGAAGGGCCTTGTAAAGTCCAGTCATACGAGCAGCGTCATGATATTTCCCTAGTTGGGAAGGTCATGTGTATATCTGATGTGACACGTGGTAACGGTATTACCCACCGTGTTGGTAAGCGTTTCTGCGTTAAGTCTGTATATATCTTGGGCAAGATATGGATGGATGAGAACATCAAGTTGAAGAATCACACGAACAGTGTCATGTTCTGGTTGGTTAGGGATCGGAGACCTTATGGCACTCCTATGGATTTCGGACAAGTGTTCAACATGTTCGATAATGAGCCAAGTACTGCAACGGTAAAGAACGACCTACGGGATCGTTTCCAAGTGATCCACAGGTTTCACGCCAAGGTTACTGGTGGTCAATATGCCAGCAACGAGCAGGCTCTGGTTAGGAGATTCTGGAAGGTCAATAACAATGTCGTCTACAACCACCAGGAGGCAGGGAAATATGAGAATCATACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCGACGTTGAAAATTCGAATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MPKRDAPWRLMAGTSKVSRSANYSPRGSLPKRDAWVNRPMYRKPRIYRSLRGPDVPKGCEGPCKVQSYEQRHDISLVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVIHRFHAKVTGGQYASNEQALVRRFWKVNNNVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_077736.1 |
|---|---|
| Location | 1067-1465 |
| Gene Name | ac3 |
| Protein Name | REn protein |
| Coding Region | ATGGATTCACGCACAGGGGAACCTATCACTGTGCCTCAAGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTCTATTTCAAGATAATCAGCGTAGAGGATCCCCTCTACACCAACACCAGGATATACCACTTACAAATCAGGTTCAACCACAACCTGAGGAGAGCATTGGATCTCCACAAGGCATTTCTCAACTTCCAAGTATGGACGACATCGACGACAGCTTCTGGGAGAACTTATTTAAATAGATTTAAATACTTAGTGATGTTGTACCTTGAACAGTTAGGCGTTATATGTATTAACAATGTTATTAGAGCTGTTCGTTTCGCAACAGACAGATCATATATAACGCATGTACTCGAAAATCATTCAATAAAATATAAATTTTATTAA |
| Protein Sequence | MDSRTGEPITVPQAENGVYIWEITNPLYFKIISVEDPLYTNTRIYHLQIRFNHNLRRALDLHKAFLNFQVWTTSTTASGRTYLNRFKYLVMLYLEQLGVICINNVIRAVRFATDRSYITHVLENHSIKYKFY |
| NCBI Accession | NP_077737.1 |
|---|---|
| Location | 1212-1601 |
| Gene Name | ac2 |
| Protein Name | TrAP |
| Coding Region | ATGCGAAATTCGTCTTCCTCAACTCCCCCCTCTATCAAAGCTCAACACAGAGCAGCTAAACGAAGAGCTATTAGAAGGCGACGAATTGACCTGAACTGTGGCTGTTCCATATACATTCACATCGACTGCAGAAACAATGGATTCACGCACAGGGGAACCTATCACTGTGCCTCAAGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTCTATTTCAAGATAATCAGCGTAGAGGATCCCCTCTACACCAACACCAGGATATACCACTTACAAATCAGGTTCAACCACAACCTGAGGAGAGCATTGGATCTCCACAAGGCATTTCTCAACTTCCAAGTATGGACGACATCGACGACAGCTTCTGGGAGAACTTATTTAAATAG |
| Protein Sequence | MRNSSSSTPPSIKAQHRAAKRRAIRRRRIDLNCGCSIYIHIDCRNNGFTHRGTYHCASSREWRLYLGDNKSPLFQDNQRRGSPLHQHQDIPLTNQVQPQPEESIGSPQGISQLPSMDDIDDSFWENLFK |
| NCBI Accession | NP_077738.1 |
|---|---|
| Location | 2184-2447 |
| Gene Name | ac4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAGATGGGCAACCTCACCTCCACGTGCTTATTCAGTTCGAGGGAAAATACTGCTGCCAAAATCAACGATTCTTCGACCTGGTATCCCCAACAAGGTCAGCACATTTCCATCCAAACATTCAGAGAGCTAAATCGTCTTCCGACGTCAAGACGTACATCGACAAAGACGGAGATACTCTTGTATGGGGAGAATTCCAGGTCGACGGTCGAAGTGCTAGAGGAGGTTGCCAAACATCTAACGACGCTGCAGCAGAGGCGTTAA |
| Protein Sequence | MKMGNLTSTCLFSSRENTAAKINDSSTWYPQQGQHISIQTFRELNRLPTSRRTSTKTEILLYGENSRSTVEVLEEVAKHLTTLQQRR |
| NCBI Accession | NP_077114.1 |
|---|---|
| Location | 461-1231 |
| Gene Name | BR-1 |
| Protein Name | movement protein/nuclear shuttle |
| Coding Region | ATGTACTCAACAAAATATCGACGAGGATTTTTAGCTAATCAAGGACGGGGTTATCCTCGTCATTCAACTGGGAAACGTTCACGTAATGTTAGCCGCATAGATTTTAAACGTCGATCAAGTAAGTATGTTCATGGCAATGATGATAGCAAAATGGCAAACCAGCGTATACATGAGAACCAGTTTGGTCCAGAATTCGTTATGGTCCATAATACAGCCATATCTACGTTTATTACATTCCCCAGTCTTGGCAAGACTGAACCAAGCCGTTCAAGGTCATATATTAAGTTGAAACGTTTACGTTTCAAAGGTACTGTCAAGATTGAACGTGTGCACGTTGATCTTAGCATGGATGGGCCTTCTCCAAAGATTGAAGGCGTATTTTCTCTTGTTGTTGTAGTTGATCGGCAACCACATCTCAGTCCAACTGGATGTCTCCATACATTTGATGAGCTATTTGGCGCCAGGATCCATAGTCATGGAAATTTAGCTGTAAGTTCTGCGTTGAAGGACCGTTTTTACATACGGCATGTGTTTAAACGAGTGATATCCGTTGAGAAGGATTCTACGATGATTGACCTCGAAGGAATGACATCTTTTACTAATAGGCGTTTTAATTGTTGGTCAGCATTTAAGGATTTTGATCGACAAGCATGTAATGGAGTTTATGGCAACATAAGCAAGAACGCCATATTAGTTTACTATTGTTGGATGTCGGATATTGTGTCAAAGGCATCGACATTTGTATCATTTGACCTTGATTATGTCGGATGA |
| Protein Sequence | MYSTKYRRGFLANQGRGYPRHSTGKRSRNVSRIDFKRRSSKYVHGNDDSKMANQRIHENQFGPEFVMVHNTAISTFITFPSLGKTEPSRSRSYIKLKRLRFKGTVKIERVHVDLSMDGPSPKIEGVFSLVVVVDRQPHLSPTGCLHTFDELFGARIHSHGNLAVSSALKDRFYIRHVFKRVISVEKDSTMIDLEGMTSFTNRRFNCWSAFKDFDRQACNGVYGNISKNAILVYYCWMSDIVSKASTFVSFDLDYVG |
| NCBI Accession | NP_077115.1 |
|---|---|
| Location | 1638-2192 |
| Gene Name | BL-1 |
| Protein Name | cell-to-cell movement protein |
| Coding Region | ATGGATTCTCAGTTAGCTTGTCCCCCAAATGCATTCAATTACATTGAATCAAACCGAGATGAATATCAGTTATCTCATGACTTGACTGAGATAATCTTGCAGTTTCCGTCAACAGCTTCTCAATTAAGCGCCAGACTGAGCCGTAGCTGTATGAAGATAGACCACTGTGTGATTGAGTTCAGGCAACAGGTTCCGATAAACGCAACAGGATCCGTGGTCGTGGAGATTCATGACAAAAGAATGACTGACAATGAATCCTTACAAGCGTCATGGACTTTTCCGGTGAGATGCAATATAGATCTCCACTATTTCTCATCGTCGTTCTTCTCGCTCAAAGACCCAATCCCATGGAAACTATATTACAAAGTTTGCGACTCTAATGTTCACCAGAGGACTCATTTTGCGAAATTCAAAGGGAAGCTGAAATTATCGACAGCTAAACACTCCGTTGATATCCCTTTCCGGGCACCCACTGTCAAAATATTGTCCAAACAATTTACAGATAAAGATGTCGATTCAGCCACGTGGGATATGGGAAATGGGATAGAAAAATGA |
| Protein Sequence | MDSQLACPPNAFNYIESNRDEYQLSHDLTEIILQFPSTASQLSARLSRSCMKIDHCVIEFRQQVPINATGSVVVEIHDKRMTDNESLQASWTFPVRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDSNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDSATWDMGNGIEK |
References More References in PubMed
| 1 |
Sunter G, et al. Virology. 1993 Jul;195(1):275-80. doi: 10.1006/viro.1993.1374. PMID: 8317105 |
|---|---|
| 2 |
Cloned tomato golden mosaic virus back in tomatoes. Wyant PS, et al. Virus Res. 2012 Aug;167(2):397-403. doi: 10.1016/j.virusres.2012.05.021. Epub 2012 Jun 4. PMID: 22677771 |
| 3 |
Sunter G, et al. Virology. 2001 Jun 20;285(1):59-70. doi: 10.1006/viro.2001.0950. PMID: 11414806 |
| 4 |
Tomato golden mosaic virus A component DNA replicates autonomously in transgenic plants. Rogers SG, et al. Cell. 1986 May 23;45(4):593-600. doi: 10.1016/0092-8674(86)90291-6. PMID: 3708687 |
| 5 |
Hartitz MD, et al. Virology. 1999 Oct 10;263(1):1-14. doi: 10.1006/viro.1999.9925. PMID: 10544077 |
| 6 |
Hanley-Bowdoin L, et al. Proc Natl Acad Sci U S A. 1990 Feb;87(4):1446-50. doi: 10.1073/pnas.87.4.1446. PMID: 11607065 |
| 7 |
Agrobacterium-mediated inoculation of plants with tomato golden mosaic virus DNAs. Elmer JS, et al. Plant Mol Biol. 1988 May;10(3):225-34. doi: 10.1007/BF00027399. PMID: 24277516 |
| 8 |
Transient expression of heterologous RNAs using tomato golden mosaic virus. Hanley-Bowdoin L, et al. Nucleic Acids Res. 1988 Nov 25;16(22):10511-28. doi: 10.1093/nar/16.22.10511. PMID: 3205715 |
| 9 |
Gardiner WE, et al. EMBO J. 1988 Apr;7(4):899-904. doi: 10.1002/j.1460-2075.1988.tb02894.x. PMID: 16453835 |
| 10 |
Pooma W, et al. J Gen Virol. 1996 Aug;77 ( Pt 8):1947-51. doi: 10.1099/0022-1317-77-8-1947. PMID: 8760447 |