Tomato common mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000879555.1 |
| Isolate | Brazil |
| Release date | 2015/2/22 |
| Submitter | Castillo-Urquiza,G.P., Beserra,J.E. Jr., Bruckner,F.P., Lima,A.T., Varsani,A., Alfenas-Zerbini,P., Murilo Zerbini,F., Beserra,J.E.A. Jr., Lima,A.T.M., Zerbini,P.A., Zerbini,F.M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
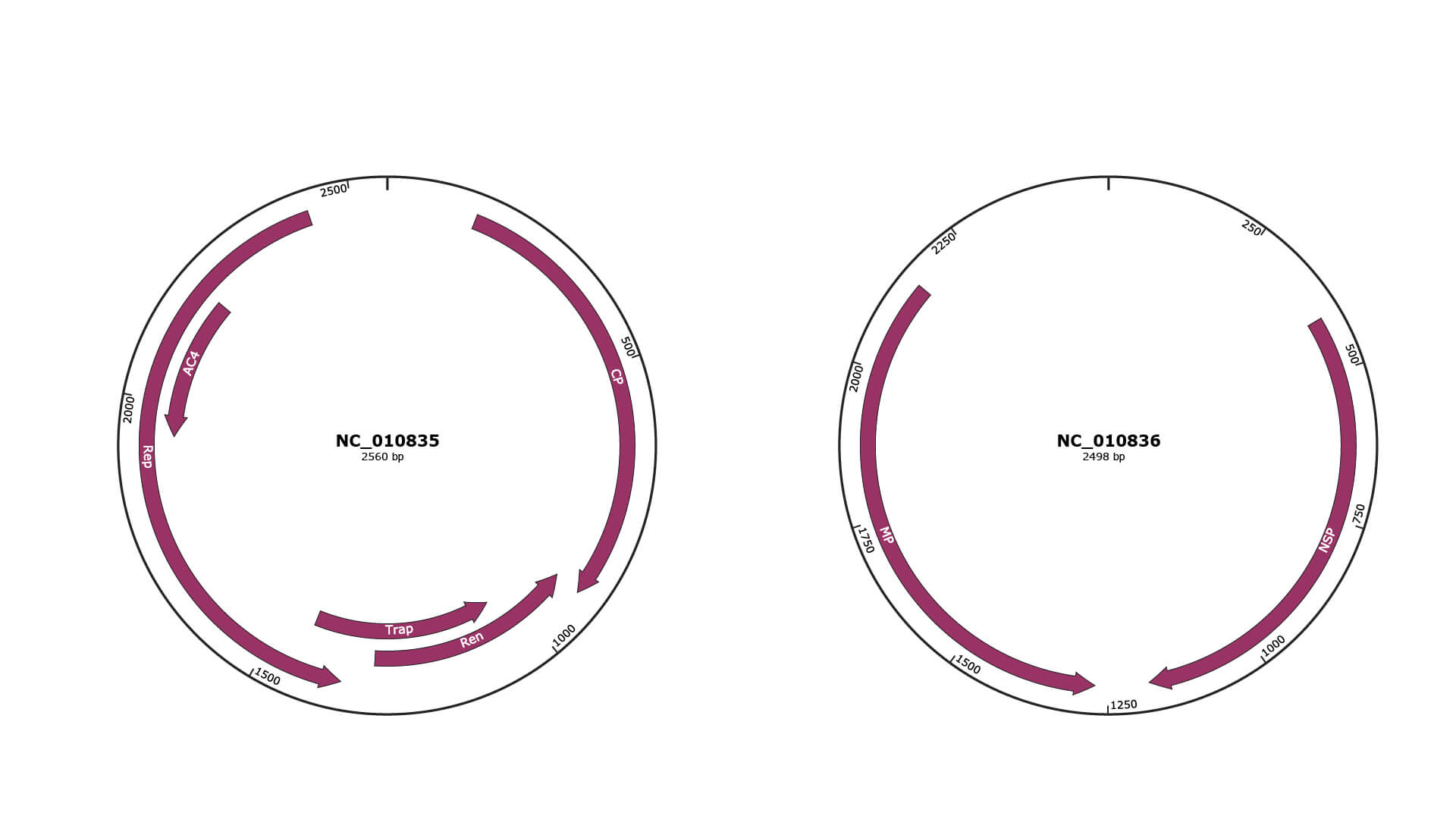
JBrowse
Genome
NC_010835
NC_010836
Gene Information
| NCBI Accession | YP_001960952.1 |
|---|---|
| Location | 153-908 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATGCCCCATGGCCCCACAGGGCACCTTCGACGAAGATTAGCCGTTCAGCTAATTTCTCCCCTCGTTCGGGAACTGGGCCTGGGCCTAGCAAAGCCGCTGAATGGGTGAATAGGCCCATGTACAGGAAGCCCAGGATATACAGAACTATGAGAACGCCCGACGTTCCTAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAACGCCACGATATTTCCCATACTGGGAAGGTGATGTGCATATCAGACGTCACACGTGGCAACGGAATTACCCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTATATTCTAGGAAAGATTTGGATGGACGAGAACATCAAGTTGAAAAACCATACGAACAGTGCTATGTTCTGGTTGGTCAGAGACCGAAGACCATATGGCACCCCTATGGATTTTGGCCAAGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCAACCGTGAAGAACGATCTACGTGATCGTTTCCAGGTTATGCATAAGTTCTATGCCAAGGTCACGGGTGGACAATATGCTAGCAATGAGCAGGCGCTGGTCAAGCGGTTCTGGAGGGTCAACAATCATGTGGTCTACAATCATCAAGAAGCCGGGAAGTATGAGAATCACACGGAGAACGCGCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACTTTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MPKRDAPWPHRAPSTKISRSANFSPRSGTGPGPSKAAEWVNRPMYRKPRIYRTMRTPDVPRGCEGPCKVQSYEQRHDISHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSAMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_001960953.1 |
|---|---|
| Location | 905-1303 |
| Gene Name | Ren |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACGCATCACTGTGCGTCAGGCAGAGAATGGCGTCTATATATGGGAGCTAACAAATCCCCTTTATTTCAAGATGTACCAAGTAGAGGACATCCGGTACACCAGGACCAGAGTGTACCATGTCCAAATAAGGTTCAACCACAACCTGAGGAGAGCACTGGGTCTCCACAAGGCATTTCTCAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGACGACTTACTTAAATAGATTTAAATATTTAGTAATGTTGTATATTGATCAGTTAGGAGTCATTTCAGTTAATAATGTAATTAGAGCTGTTCGCTTTGCAACAGACAGATCATATGTAAATGCTGTACTTGAAAATCATTCAATAAAATTTAAATTATATTAA |
| Protein Sequence | MDSRTGERITVRQAENGVYIWELTNPLYFKMYQVEDIRYTRTRVYHVQIRFNHNLRRALGLHKAFLNFQVWTTSLTASGTTYLNRFKYLVMLYIDQLGVISVNNVIRAVRFATDRSYVNAVLENHSIKFKLY |
| NCBI Accession | YP_001960954.1 |
|---|---|
| Location | 1050-1436 |
| Gene Name | Trap |
| Protein Name | trans-activating protein |
| Coding Region | ATGCTAAATTCATCATCCTCAACTCCCCCCTCTATCAAACTACGGCACAGGATTGCGAAGAGAGCACCTCGACGTAGAAGGATAGACCTAAACTGTGGCTGCTCTTTGTACGTCAACCTCAACTGCAGTAACTATGGATTCACGCACAGGGGAACGCATCACTGTGCGTCAGGCAGAGAATGGCGTCTATATATGGGAGCTAACAAATCCCCTTTATTTCAAGATGTACCAAGTAGAGGACATCCGGTACACCAGGACCAGAGTGTACCATGTCCAAATAAGGTTCAACCACAACCTGAGGAGAGCACTGGGTCTCCACAAGGCATTTCTCAACTTCCAAGTCTGGACGACATCCCTGACAGCTTCTGGGACGACTTACTTAAATAG |
| Protein Sequence | MLNSSSSTPPSIKLRHRIAKRAPRRRRIDLNCGCSLYVNLNCSNYGFTHRGTHHCASGREWRLYMGANKSPLFQDVPSRGHPVHQDQSVPCPNKVQPQPEESTGSPQGISQLPSLDDIPDSFWDDLLK |
| NCBI Accession | YP_001960955.1 |
|---|---|
| Location | 1360-2427 |
| Gene Name | Rep |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACGGAACCCTAATATATTCAGATTAACGGCGAGAAACATATTTCTCACATATCCACAGTGCGATATACCAAAAGATGAAGCTCTTCAAATGCTTCAATCTCTTCCATGGTCAGTCGTCAAACCCACATATATACGAGTCGCCAGAGAGGAACACTCCGACGGATTCCCCCATCTTCACTGTCTTGTCCAACTCTCCGGAAAATCGAATATCAAGGATGTTAGGTTTTTCGACCTCACTCACCCCAGACGGTCTACCGGATTTCACCCAAATGTTCAGGCAGCCAAAGACACCAATGCAGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGACAGTACAAGGTGTCTGGGGGAACAAAGGCAAATAAAGACGACGTGTACCACAACGCCGTCAATGCATCTTCTCCGGGAGAGGCTCTCGACATTATCAGGGCCGGAGACCCCAAGACTTTCCTCGTCAACTATCACAATGTGAAGGCTAATCTAGAGAGGATCTTCCAAAAAGCTCCGGCACCGTGGGTTCCTCCGTTTCCCCTCTCCTCATTCACTAACGTGCCCGACGAGATGCAAGAATGGGCTGATGATTATTTTGGAAGGGATGCAGCTGCGCGGCCTATCAGACCTATAAGTATTGTCATCGAGGGTAATAGTCGGACGGGGAAGACGATGTGGGCGCGTGCACTTGGCCCACATAACTATCTAAGTGGACACCTGGATTTCAATTCTAGGGTTTACTCAAACGATGTACTGTATAACGTCATTGATGACGTCTCTCCGCATTACTTAAAGTTAAAGCACTGGAAAGAATTGATTGGGGCCCAAATAGATTGGCAATCAAATTGTAAGTACGGAAAGCCAGTTCAAATTAAAGGGGGTATCCCATCAATCGTGCTCTGCAATCCTGGAGAGGGGGCCAGCTATAAAGATTTCCTAGCCAAAGAGGAAAACGCATCTCTCAAGTCGTGGACACTCCATAATGCTAAATTCATCATCCTCAACTCCCCCCTCTATCAAACTACGGCACAGGATTGCGAAGAGAGCACCTCGACGTAG |
| Protein Sequence | MPRNPNIFRLTARNIFLTYPQCDIPKDEALQMLQSLPWSVVKPTYIRVAREEHSDGFPHLHCLVQLSGKSNIKDVRFFDLTHPRRSTGFHPNVQAAKDTNAVKNYITKEGDYCESGQYKVSGGTKANKDDVYHNAVNASSPGEALDIIRAGDPKTFLVNYHNVKANLERIFQKAPAPWVPPFPLSSFTNVPDEMQEWADDYFGRDAAARPIRPISIVIEGNSRTGKTMWARALGPHNYLSGHLDFNSRVYSNDVLYNVIDDVSPHYLKLKHWKELIGAQIDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLAKEENASLKSWTLHNAKFIILNSPLYQTTAQDCEESTST |
| NCBI Accession | YP_001960956.1 |
|---|---|
| Location | 1938-2207 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGTTAGGTTTTTCGACCTCACTCACCCCAGACGGTCTACCGGATTTCACCCAAATGTTCAGGCAGCCAAAGACACCAATGCAGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGACAGTACAAGGTGTCTGGGGGAACAAAGGCAAATAAAGACGACGTGTACCACAACGCCGTCAATGCATCTTCTCCGGGAGAGGCTCTCGACATTATCAGGGCCGGAGACCCCAAGACTTTCCTCGTCAACTATCACAATGTGA |
| Protein Sequence | MLGFSTSLTPDGLPDFTQMFRQPKTPMQSRITSPKKVIIVNPDSTRCLGEQRQIKTTCTTTPSMHLLRERLSTLSGPETPRLSSSTITM |
| NCBI Accession | YP_001960957.1 |
|---|---|
| Location | 411-1181 |
| Gene Name | NSP |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATTTCTCTAAAAATAAGCGTAGTTGGGCGTCTACTAATCGACGTCTATCCTCACGATATTTTACCTCTAAAAGGTCAATTAGCTTGTTACGTAATGATGGTAAACGTCGAGTGGATATTTCTAGCAAATTCCAGGAAGAAATTAAGATGTCGTCGCATCGAATACATGAAACACAATATGGGCCTGAATTTGTATTAGGTAATAATTCGGCGATATCCACATTTATTACGTATCCTTGTCTTGGCAAGACAGAGCCCAGTCGTACGAGGTCATATATCAAATTAAAACGCCTGCGTTTTAACGGCACTGTTAAAATTGAACGTGCACATACAGATGTGAATATGAATGGGATACCTCCCAAGATTGATGGAGTATTTACTATTGTCGTTGTTATCGATCGAAAACCGCACTTGACCTCTGCTGGTGGTCTCTATACATTCGACGAGCTGTTTGGTGCTAGGATTCACAGTCATGGAAATTTGGCAATAACTCCATTGTTAAAGGATCGTTTTTACATCCGTCATGTCGTCAAACGTGTGTTGTCCGTGGAGAAGGATACGACTATGATTGATCTTGATGGGACGACAACATTGTCTAATAGGCGCTATAACTGTTGGGCTAATTTTAGGGACCTTGATCATGACTCATGTAATGGTATTTATGCAAATATTTGCAAGAACGCCATATTAGTCTATTATTGTTGGATGTCTGATACAGTGTCCAAGGCATCTACATTTGTGTCATTTGACCTAGATTATGTTGGATAA |
| Protein Sequence | MYFSKNKRSWASTNRRLSSRYFTSKRSISLLRNDGKRRVDISSKFQEEIKMSSHRIHETQYGPEFVLGNNSAISTFITYPCLGKTEPSRTRSYIKLKRLRFNGTVKIERAHTDVNMNGIPPKIDGVFTIVVVIDRKPHLTSAGGLYTFDELFGARIHSHGNLAITPLLKDRFYIRHVVKRVLSVEKDTTMIDLDGTTTLSNRRYNCWANFRDLDHDSCNGIYANICKNAILVYYCWMSDTVSKASTFVSFDLDYVG |
| NCBI Accession | YP_001960958.1 |
|---|---|
| Location | 1272-2153 |
| Gene Name | MP |
| Protein Name | movement protein |
| Coding Region | ATGAATTCTCAGTTAGTTGTTCCTCCAAATGCTTTTAATTATGTTGAATCACACCGGGATGAATATCAGCTGTCTCATGACTTGACTGAAATTGTTCTACAATTTCCTTCTACGGCATCTCAAATAAGTGCTAAACTTAGTCGCAGCTGTATGAAAATCGACCATTGTGTCATTGAATACAGACAGCAAGTGCCTATAAATGCAACTGGGTCTGTCATAGTTGAAATTCATGACAAACGAATGACAGACAACGAGTCATTGCAGGCGTCATGGACTTTCCCTCTTAGATGTAACATAGACTTACATTATTTCTCAGCGTCTTTCTTCTCGCTTAAAGACCCCATTCCATGGAAACTATACTACAGGGTTAGCGATACAAACGTACATCAAAGAACACATTTCGCAAAATTCAAGGGCAAGTTAAAACTATCCACAGCTAAACACTCTGTAGATATCCCTTTCCGGGCACCCACAGTGAAGATATTGTCGAAGCAGTTTTCAGACAAGGATATCGACTTTGCTCATGTTGGGTTCGGAAAATGGGAGAGAAAATTAGTCAGATGTGCTTCGACTAACAATTTTGGGCCTTCGGGCCCAATAGAAATTAAGGCTGGAGAATCATGGGCCTCCAGAAGTACAGTTGGTATTAGCAACTCTTGTATGGACTCCGAAAAGAGCAACGATCTCAATCCATATAGGGACCTAAACAGATTGGGCACAACATTTCTCGACCCAGGTGAATCAGCTTCAATCGTTGCGGCACAAAGGACGCAGTCTAACATTACATTGTCGTTAGCCCAGTTAAATGATATTGTTAGGACAACTGTCCAAGAATGTATTAACACCAATTGTACACCTTCGGAACCAAAGTCTTTGAAATAA |
| Protein Sequence | MNSQLVVPPNAFNYVESHRDEYQLSHDLTEIVLQFPSTASQISAKLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPLRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSDKDIDFAHVGFGKWERKLVRCASTNNFGPSGPIEIKAGESWASRSTVGISNSCMDSEKSNDLNPYRDLNRLGTTFLDPGESASIVAAQRTQSNITLSLAQLNDIVRTTVQECINTNCTPSEPKSLK |
References More References in PubMed
| 1 |
The phylogeographic history of tomato mosaic virus in Eurasia. Xu Y, et al. Virology. 2021 Feb;554:42-47. doi: 10.1016/j.virol.2020.12.009. Epub 2020 Dec 24. PMID: 33360588 |
|---|---|
| 2 |
Tomato Brown Rugose Fruit Virus: Survival and Disinfection Efficacy on Common Glasshouse Surfaces. Skelton A, et al. Viruses. 2023 Oct 11;15(10):2076. doi: 10.3390/v15102076. PMID: 37896853 |
| 3 |
First Report of Tomato mosaic virus on Common Sow Thistle in Iran. Hashemi SS, et al. Plant Dis. 2014 Aug;98(8):1164. doi: 10.1094/PDIS-03-14-0220-PDN. PMID: 30708804 |
| 4 |
Pepino Mosaic Virus: A Globally Important Tomato Pathogen and a Rising Model in Molecular Virology. Úbeda JR, et al. Mol Plant Pathol. 2026 Jan;27(1):e70211. doi: 10.1111/mpp.70211. PMID: 41603498 |
| 5 |
Nogueira AM, et al. Viruses. 2023 Oct 11;15(10):2074. doi: 10.3390/v15102074. PMID: 37896851 |
| 6 |
First Report of Pepino mosaic virus on Tomato in Spain. Jordá C, et al. Plant Dis. 2001 Dec;85(12):1292. doi: 10.1094/PDIS.2001.85.12.1292C. PMID: 30831819 |
| 7 |
Tiberini A, et al. Plants (Basel). 2022 Feb 11;11(4):489. doi: 10.3390/plants11040489. PMID: 35214821 |
| 8 |
Resistance Against Melon Chlorotic Mosaic Virus and Tomato Leaf Curl New Delhi Virus in Melon. Romay G, et al. Plant Dis. 2019 Nov;103(11):2913-2919. doi: 10.1094/PDIS-02-19-0298-RE. Epub 2019 Aug 20. PMID: 31436474 |
| 9 |
Potato yellow mosaic virus: a synonym of tomato yellow mosaic virus. Morales FJ, et al. Arch Virol. 2001;146(11):2249-53. doi: 10.1007/s007050170035. PMID: 11765926 |
| 10 |
First Report of Tomato mottle mosaic virus Infection of Pepper in China. Li YY, et al. Plant Dis. 2014 Oct;98(10):1447. doi: 10.1094/PDIS-03-14-0317-PDN. PMID: 30703948 |