Tomato chlorotic leaf distortion virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000894835.3 |
| Isolate | Venezuela |
| Release date | 2016/8/8 |
| Submitter | Zambrano,K., Geraud-Pouey,F., Chirinos,D., Romay,G., Marys,E., Geraud,F. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
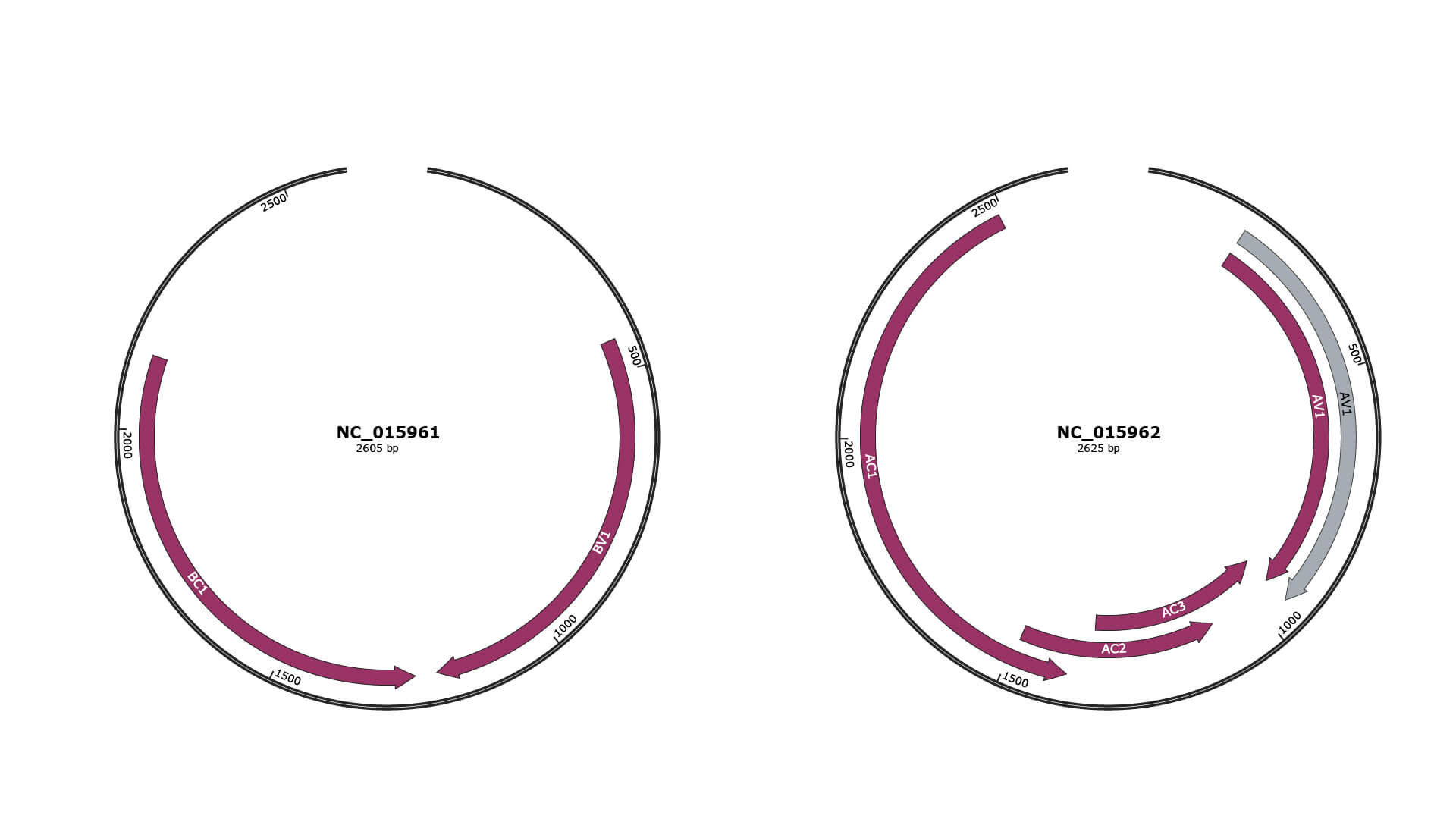
JBrowse
Genome
NC_015961
NC_015962
Gene Information
| NCBI Accession | YP_004821540.1 |
|---|---|
| Location | 442-1212 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTTCTCTGTTAGGTACAGACGTGGAGCCTACCACAGTCAACCACGTGGACAAACACGTCAGCCTATGTTTAAAAGGCAGGCCCATGTTAAACGCAATGATGGCAGGCGTCGAGCGACCCAGAATCTGAAGGCCTCTGATGAGCCCAAGATGACTGCCCAGCGGATTCACGAGAACCAGTACGGTTCGGAGTTTATGATGGCCCACAATACAGCCATATCCACTTTCATCAGCTACCCTGAGTTATGCAAAGCCCAACCGAACCGAACTAGGTCGTACATCAAGTTGAAACGGCTGCGTTTCAAGGGAACTGTGAAGATTGAACGTGTTGCCACTGACGTCAGCATGGATGGTTATGGCCCCAAGACGGAAGGGGTATTCACAATGGTCATAGTTGTTGACCGCAAACCGCATTTGCCTGCGTCTGGGTGCCTGCCAACCTTCGATGAACTCTTCGGTGCAAGAATCCACAGCCATGGTAACTTGGCCGTATCTCCTTCACTGAAAGACCGTTTCTACATACGCCACGTGTTGAAGCGAGTATTGTCCGTGGAGAAGGACAGTCTGATGGTAGACGTGGAAGGATCAACTGCCCTGTCTAATAGGCGTTTTAATTGTTGGTCTAGTTTTAAGGACCTTGATGTTGAGTCACGTAAGGGTGTTTATGACAACATAAGCAAGAACGCCCTGTTAGTTTATTACTGTTGGATGTCTGACACCGTGTCCAAGGCATCGACATTTGTATCGTTTGACCTCGATTATATCGGGTGA |
| Protein Sequence | MFSVRYRRGAYHSQPRGQTRQPMFKRQAHVKRNDGRRRATQNLKASDEPKMTAQRIHENQYGSEFMMAHNTAISTFISYPELCKAQPNRTRSYIKLKRLRFKGTVKIERVATDVSMDGYGPKTEGVFTMVIVVDRKPHLPASGCLPTFDELFGARIHSHGNLAVSPSLKDRFYIRHVLKRVLSVEKDSLMVDVEGSTALSNRRFNCWSSFKDLDVESRKGVYDNISKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
| NCBI Accession | YP_004821541.1 |
|---|---|
| Location | 1252-2133 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGAATCTCAGTTAGTTAATCCTCCCAGTGCTTTCAACTACATTGAGTCCCATCGAGACGAGTATCAGCTTTCCCATGACTTAACTGAGATATTCCTCCAATTTCCATCAACGGCGGCTCAATTGACGGCGAGGCTTAGTCGGAGCTGTATGAAAATCGACCATTGCGTCATCGAATACAGGCAACAGGTACCCATAAACGCCACCGGGACGGTAATTGTGGAGATTCACGACCGGAGACTGACTGACAACGAGTCTTTACAGGCATCGTGGACTTTTCCGATCAGGTGCAACATAGATCTCCACTATTTTTCATCGTCCTTCTTCTCCTTGAAGGACCCGATTCCATGGAAACTCTACTACAGAGTGTGCGACACGAACGTCCAGCAGCAGACCCACTTCACGAAATTCAAGGGGAAGCTGAAACTGTCGACGGCGAAACATTCCGTCGACATCCCGTTCAGAGCACCGACTGTAAAAATCCACTCCAAACAATTCACAGAGAAGGACGTGGATTTCTCACACGTGGACTACGGACGATGGGAAAGGAAGACATTGAGATGCGCGTCCATGTCTCGTGTTGGGCTCAGAGGCCCAATTGAAATTAGGCCTGGTGAATCATGGGCTTCAAGGAGCGCAGTTGGCATTGGCCCATCGGACGCGGACTCCGAGACGGAGAACGAGATCCACCCATACAGAGAGCTGCACAGGCTCGGGTCAAGCGCAATAGATCCGGGTGAGTCTGCATCCATGGTGGGGGCGAGAAGGGCAGAGTCCAACATTACGATGTCGGTGGCCCAATTAAACGAACTAGTAAGGACTACGGTCCAAGAATGTATTAAGAGCAATTGTAGTGGGGCACAGCCCAAGAACTTGAAATAA |
| Protein Sequence | MESQLVNPPSAFNYIESHRDEYQLSHDLTEIFLQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDRRLTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVQQQTHFTKFKGKLKLSTAKHSVDIPFRAPTVKIHSKQFTEKDVDFSHVDYGRWERKTLRCASMSRVGLRGPIEIRPGESWASRSAVGIGPSDADSETENEIHPYRELHRLGSSAIDPGESASMVGARRAESNITMSVAQLNELVRTTVQECIKSNCSGAQPKNLK |
| NCBI Accession | YP_004821542.1 |
|---|---|
| Location | 192-947 |
| Gene Name | AV1 |
| Protein Name | capsid protein |
| Coding Region | ATGCCTAAGCGCGATCTCCCATGGCGCGCGATGCCCGGTACGTCAAAGGTCACCCGCAATGCGAATTACTCCCCACGCGCACGCATCGGCCCAACAACGAACAGGGCCACGGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGAATATATCGGACGCTAAGGACTCCCGATGTTCCAAGAGGTTGTGAAGGCCCGTGTAAGGTCCAGTCTTATGAACAGCGTCACGATATTGCTCACACTGGTAAGGTGATGTGTATTTCCGATGTGACACGTGGCAATGGTATTACCCACCGTGTTGGTAAGCGTTTCTGTGTTAAGTCCGTATACATATTAGGCAAGGTGTGGATGGATGACAACATCAAGTTGAAGAACCACACTAACAGCGTTATGTTCTGGTTAGTTAGGGACCGGAGACCGTATGGCACTCCTATGGATTTTGGACAGGTATTTAATATGTTTGATAATGAGCCCAGCACTGCCACCGTTAAGAACGATCTCCGTGATCGTTACCAGGTGATGAAGAAGTTCTATGCCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTCTGGTCAAGCGTTTCTGGAAGGTCAACAATTATGTGGTGTACAACCACCAGGAGGCTGGGAAGTATGAGAATCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACCCATGCCTCTAACCCCGTGTATGCAACCCTTAAGATTCGGATCTACTTCTACGATTCGATAATGAATTAA |
| Protein Sequence | MPKRDLPWRAMPGTSKVTRNANYSPRARIGPTTNRATEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDIAHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMKKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_004821543.1 |
|---|---|
| Location | 944-1342 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAATTCATCAATGCGCGTCAAGCAGAGAATGGCGTTTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATTTCCCAGGTAGAGGACATGCCATACACCAGAACGAGGGTGTACCACCTCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAATTTCCAAGTCTGGACGACATCCCTGAAAGCTTCTGGGAAGACTTATTTGTTTAGGTTTAGGCATTTAGTTATGATGTATTTAGATCAGTTAGGCGTAATTTCCCTTAACAATGTAATTAGAGCTGTACGATACGCCACCGACAAGGCGTACGTCAATCATGTACTAGAAAATCATTCAATAAAATTCAAACTTTATTAA |
| Protein Sequence | MDSRTGEFINARQAENGVYIWEITNPLYFKISQVEDMPYTRTRVYHLQIRFNHNLRRALHLHKAYLNFQVWTTSLKASGKTYLFRFRHLVMMYLDQLGVISLNNVIRAVRYATDKAYVNHVLENHSIKFKLY |
| NCBI Accession | YP_004821544.1 |
|---|---|
| Location | 1089-1493 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCTGTCTTCATCACACTCGACTCCCCCCTGTATCAAGAAGAGACACAGGCAGGCCAAGAAGAAACAGCCCAAGAGGAGAGCCATCAGGAGACGGCGTCTTGACTGGGGGTGCAATTGCACAGCTTACGTAGACATAAACTGCAGAGATCATGGATTCACGCACAGGGGAATTCATCAATGCGCGTCAAGCAGAGAATGGCGTTTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATTTCCCAGGTAGAGGACATGCCATACACCAGAACGAGGGTGTACCACCTCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAATTTCCAAGTCTGGACGACATCCCTGAAAGCTTCTGGGAAGACTTATTTGTTTAG |
| Protein Sequence | MLSSSHSTPPCIKKRHRQAKKKQPKRRAIRRRRLDWGCNCTAYVDINCRDHGFTHRGIHQCASSREWRLYLGDNKSPVFQDFPGRGHAIHQNEGVPPPDTVQPQPQESVASPQSLPEFPSLDDIPESFWEDLFV |
| NCBI Accession | YP_004821545.1 |
|---|---|
| Location | 1390-2490 |
| Gene Name | AC1 |
| Protein Name | REP protein |
| Coding Region | ATGCCACCGCCTAAGAAATTTAGAATTAACTCCAAAAACTATTTCCTCACTTATCCCCAGTGCTCTCTTACTAAAGAAGAAGCACTTTCCCAATTACAAAACCTAAAAACCCCAGTAAACAAGAAGTTCATCAAAATCTGCAGAGAGCTTCACGAGAATGGGGAGCCTCATCTCCACATACTCATCCAGTTCGAGGGGAAGTACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGMTAAATCAAGCTCGGACGTTAAGTCCTACATCGACAAGGATGGAGACACCATTGAATGGGGAGAATTCCAGATCGACGGCAGATCTGCAAGAGGAGGTCAGCAAACAGTCAACGATACATACGCAAAGGCGTTGAATGCTGCCTCTGCCGAGCAAGCTCTGCAAATCATAAAGGAAGAACAACCACAACATTTCTTCCTTCAACACCACAACCTGGTTGCTAACGCAACCAGAATATTCAAGAAGGCTCCGGAACCGTGGGTCCCTCCGTTTCGTCTCTCCTCTTTCACTAACGTTCCGGACGAGATGCAAGAGTGGGCCGATAGTTATTTTGGGCTTGATTCCGCTGCGCGGCCAAATCGTCCAATAAGTCTCATAGTTGAGGGTGATTCAAGAACAGGCAAGACGATGTGGGCTCGTGCCTTAGGCCCACATAATTATCTGAGTGGACACCTGGACTTCAACTCAAAGGTTTACTCGAACGAAGTGGAATATAACGTCATTGATGACGTCTCTCCGCAATACTTAAAGTTGAAGCACTGGAAAGAGCTCCTTGGGGCCCAAAAAGACTGGCAGTCAAATTGCAAGTACGGGAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTCTGCAATCCAGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACGCATCCCTCAGGAACTGGACACTCAAGAATGCTGTCTTCATCACACTCGACTCCCCCCTGTATCAAGAAGAGACACAGGCAGGCCAAGAAGAAACAGCCCAAGAGGAGAGCCATCAGGAGACGGCGTCTTGA |
| Protein Sequence | MPPPKKFRINSKNYFLTYPQCSLTKEEALSQLQNLKTPVNKKFIKICRELHENGEPHLHILIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGXKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGQQTVNDTYAKALNAASAEQALQIIKEEQPQHFFLQHHNLVANATRIFKKAPEPWVPPFRLSSFTNVPDEMQEWADSYFGLDSAARPNRPISLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVYSNEVEYNVIDDVSPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENASLRNWTLKNAVFITLDSPLYQEETQAGQEETAQEESHQETAS |
References More References in PubMed
| 1 |
Martins TP, et al. Arch Virol. 2021 Nov;166(11):3217-3220. doi: 10.1007/s00705-021-05220-w. Epub 2021 Sep 8. PMID: 34498121 |
|---|---|
| 2 |
Zambrano K, et al. Arch Virol. 2011 Dec;156(12):2263-6. doi: 10.1007/s00705-011-1093-x. Epub 2011 Aug 19. PMID: 21853328 |
| 3 |
Disease complex associated with begomoviruses infecting squash and cucumber in Saudi Arabia. Amer MA, et al. Cell Mol Biol (Noisy-le-grand). 2024 Nov 27;70(11):58-63. doi: 10.14715/cmb/2024.70.11.8. PMID: 39707780 |
| 4 |
First Report of Tomato mosaic virus on Hibiscus rosa-sinensis in China. Huang JG, et al. Plant Dis. 2004 Jun;88(6):683. doi: 10.1094/PDIS.2004.88.6.683C. PMID: 30812606 |
| 5 |
Spinach latent virus Infecting Tomato in Virginia, United States. Vargas-Asencio J, et al. Plant Dis. 2013 Dec;97(12):1663. doi: 10.1094/PDIS-05-13-0529-PDN. PMID: 30716862 |
| 6 |
First Report of Tomato ringspot virus Infecting Pepper in Iran. Sokhansanj Y, et al. Plant Dis. 2012 Dec;96(12):1828. doi: 10.1094/PDIS-07-12-0664-PDN. PMID: 30727266 |
| 7 |
First Report of Tomato severe rugose virus in Chili Pepper in Brazil. Bezerra-Agasie IC, et al. Plant Dis. 2006 Jan;90(1):114. doi: 10.1094/PD-90-0114C. PMID: 30786504 |
| 8 |
First Report of Parietaria mottle virus on Tomato in Spain. Aramburu J. Plant Dis. 2001 Nov;85(11):1210. doi: 10.1094/PDIS.2001.85.11.1210C. PMID: 30823185 |
| 9 |
First Report of a Tospovirus on Sunflower (Helianthus annus L.) from India. Subbaiah KV, et al. Plant Dis. 2000 Dec;84(12):1343. doi: 10.1094/PDIS.2000.84.12.1343B. PMID: 30831882 |
| 10 |
First Report of Tomato spotted wilt virus in Brugmansia suaveolens in Korea. Choi SK, et al. Plant Dis. 2014 Sep;98(9):1283. doi: 10.1094/PDIS-02-14-0173-PDN. PMID: 30699655 |