Tomato bright yellow mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002823865.1 |
| Isolate | Brazil |
| Release date | 2018/8/25 |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
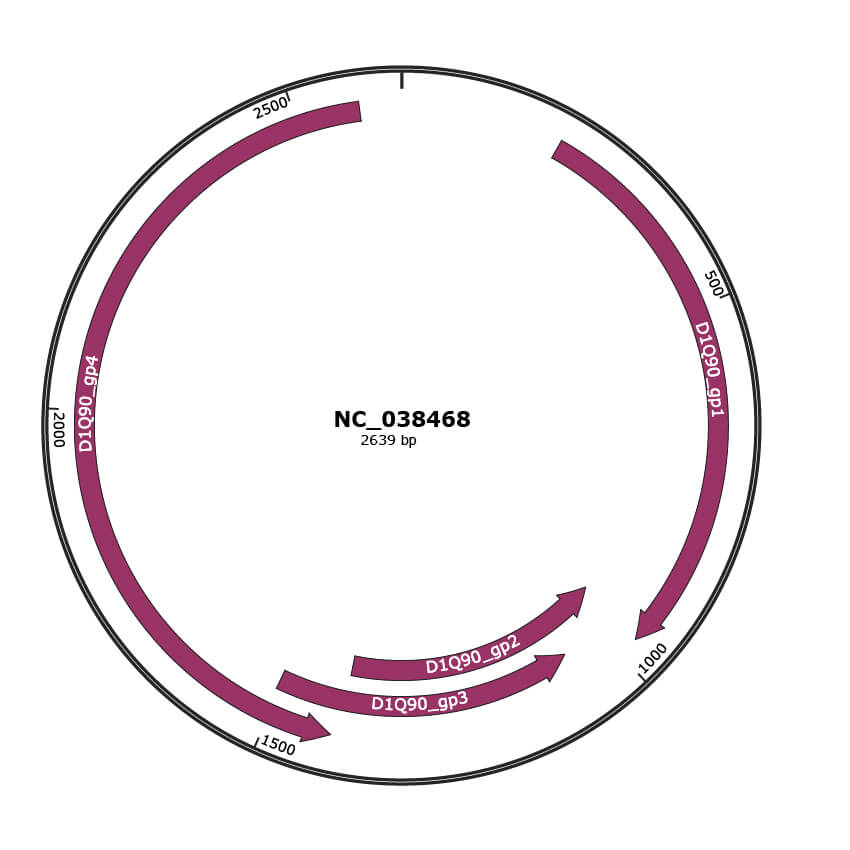
JBrowse
Genome
NC_038468
Gene Information
| NCBI Accession | YP_009506517.1 |
|---|---|
| Location | 216-971 |
| Protein Name | capsid protein |
| Coding Region | ATGCCGAAGCGGTATCCCCCATTCCGGACAACGGCGGGAATTTCCAAGATTTCCCGCTCTTCGAATATGTCTCCTCGTGGAGGTATCCGGCCCAAATTCGACAAGGCCGCTGAGTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGCACGTTGCGAAGCCCAGACATCCCGAGGGGTTGTGAAGGCCCTTGCAAGGTCCAATCGTTTGAGCAGCGTCATGACGTTTCGCACGTGGGGAAGGTGTTGTGTATTTCTGATGTGACACGGGGTAATGGTATTACTCACCGTGTCGGTAAACGTTTTTGTGTTAAGTCCGTCTATATACTAGGGAAGGTTTGGATGGACGATAATATTAAGCTGAAGAACCATACGAATAGCGTATTGTTCTGGTTAGTTAGGGATAGGAGGCCGTATGGTACCCCTATGGACTTCGGCCAGGTTTTTAATATGTATGATAACGAGCCCAGTACTGCCACCGTGAAGAACGATCTCCGGGATCGTATCCAAGTTATGCACAGGTTCTCCGCGAAGGTGACAGGTGGACAGTACGCCAGCAACGAGCAGGCCGTGGTGCGACGTTTCTGGAAGGTGTACAACCACGTTGTGTACAACCACCAAGAGGCCGCGAAGTACGAAATCCACACGGAGAACGCCCTGTTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTATATGCCACCCTCAAGATTCGGATCTATTTTTACGATTCGATCTTAAATTAA |
| Protein Sequence | MPKRYPPFRTTAGISKISRSSNMSPRGGIRPKFDKAAEWVNRPMYRKPRIYRTLRSPDIPRGCEGPCKVQSFEQRHDVSHVGKVLCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVLFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRIQVMHRFSAKVTGGQYASNEQAVVRRFWKVYNHVVYNHQEAAKYEIHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
| NCBI Accession | YP_009506518.1 |
|---|---|
| Location | 963-1403 |
| Protein Name | AL3 |
| Coding Region | ATGCTCAATCTACCTGCACATTCACTGCAGAGGACATGGATTCACGCACAGGGGAACGCATCACGCGACGTCAAGCGGAGAATGGCGTGTATACCTGGGAGGTGCAAAATCCCCTATATTTCAAGATCACCAACGTGGAGATTTTACTCCACGCCAACACGACGGTGTACCACATCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAGGCGTACCTCAACTTCCAAGTCTGGACGACTTCCCTTACGGCTTCTGGGACGACATATTTTTATTTATTTTTATTCTTGGTCAATATGTACTTTCTTAAATTTGGRGTTATTTCAATTTAGTTATGTTATTCGATCTGTTCAATTCGCAACAGACAGGACGTATGTTAACTCATGTACTCGAGGATCATTCAATAAAATTCAACATTTATTAATTTAA |
| Protein Sequence | MLNLPAHSLQRTWIHAQGNASRDVKRRMACIPGRCKIPYISRSPTWRFYSTPTRRCTTSRYGSTTTSGERWISTRRTSTSKSGRLPLRLLGRHIFIYFYSWSICTFLNLXLFQFSYVIRSVQFATDRTYVNSCTRGSFNKIQHLLI |
| NCBI Accession | YP_009506519.1 |
|---|---|
| Location | 1060-1506 |
| Protein Name | AL2 |
| Coding Region | ATGAAATTCGTCTTTCTCAACTCCCCCCTCTATCAAACCACAGCACAGAATTGCCAAGAAGAAGAGGGCAATCAGGAGACGACGAATTTTAGTTTAGTGCGGGATGCTCAATCTACCTGCACATTCACTGCAGAGGACATGGATTCACGCACAGGGGAACGCATCACGCGACGTCAAGCGGAGAATGGCGTGTATACCTGGGAGGTGCAAAATCCCCTATATTTCAAGATCACCAACGTGGAGATTTTACTCCACGCCAACACGACGGTGTACCACATCCAGATACGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAGGCGTACCTCAACTTCCAAGTCTGGACGACTTCCCTTACGGCTTCTGGGACGACATATTTTTATTTATTTTTATTCTTGGTCAATATGTACTTTCTTAAATTTGGRGTTATTTCAATTTAG |
| Protein Sequence | MKFVFLNSPLYQTTAQNCQEEEGNQETTNFSLVRDAQSTCTFTAEDMDSRTGERITRRQAENGVYTWEVQNPLYFKITNVEILLHANTTVYHIQIRFNHNLRRALDLHKAYLNFQVWTTSLTASGTTYFYLFLFLVNMYFLKFGVISI |
| NCBI Accession | YP_009506520.1 |
|---|---|
| Location | 1415-2584 |
| Protein Name | AL1 |
| Coding Region | ATGGGACTCCAGGACTCCAGCAAATATCACAGAAGTTGGGAGAGCTCCCTGGAGTCCTGGCACATATTTACAAAAATGCCACGACAACCTAATACATTTAGGCTGCAGGCAAGGAATATCTTCCTCACGTACCCGCAGTGCGATATAGAAAAACATGAGGTGCTTCAAATGCTTCAACTCCTCACTGGGACAGTCGTCAAACCCACATACATCGGGGTCGCCAGAGAGGAACACCAGATGGGCATCCTCACCTCCCCTGTCTCATACAATATCCGGAAAGTCAACATCAAGGATGCTAGATTTTTCGACCTTACTCACCCAAGACGGTCTGCCAATTTTCACCCAAACATCCAGGCAGCCAAAGACGCCAACGCCGTCAAGAATTACATCACCAGAGAGGGTGATTATTGTGAATCCGGACAATACAGAATTTCTGGCGGAACTAAGACAAATAAAGACGACGTCTATCACAACGCAATCAATGCCACATCTGCATCAGAGGCTCTTGCAATTATCCGGGCAGGAGATCCCAAGGCGTTCATCGTTCAACATCATAACATCAATGCGAATATTCAAAAGATATTCGCCAAATCTCCGGAGCCTTGGACTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCGGACGAGATGCAAGAGTGGGCGGATGATTATTTTGGTCGTCTTTCCGCTGCGCGGCCAGATTTTCATAATAGTCTCAGACCGGTATCCATCATCGTGGAGGGTGATTCAAGAACGGGCAAGACGATGTGGGCACGTGCTTTGGGGTCCCACAATTATTTGAGTGGACACCTGGATTTCAATGCTAGGGTTTATTCAAATGAAGTTGATTATAACGTCATTGATGACGTCCCTCCGCACTACTTAAAGATGAAGCACTGGAAAGAATTGATTGGGGCCCAAAGGGACTGGCAGTCAAATTGTAAATACGGAAAGCCGGTTCAAATTAAAGGTGGGATACCCTCAATCGTGCTTTGCAATCCAGGAGAGGGTGCCAGTTATAAAGAGTTCCTCGACAAAGAGGAGAATTTGTCACTCAAGAACTGGACACTCCACAATGAAATTCGTCTTTCTCAACTCCCCCCTCTATCAAACCACAGCACAGAATTGCCAAGAAGAAGAGGGCAATCAGGAGACGACGAATTTTAG |
| Protein Sequence | MGLQDSSKYHRSWESSLESWHIFTKMPRQPNTFRLQARNIFLTYPQCDIEKHEVLQMLQLLTGTVVKPTYIGVAREEHQMGILTSPVSYNIRKVNIKDARFFDLTHPRRSANFHPNIQAAKDANAVKNYITREGDYCESGQYRISGGTKTNKDDVYHNAINATSASEALAIIRAGDPKAFIVQHHNINANIQKIFAKSPEPWTPPFPLSSFTNVPDEMQEWADDYFGRLSAARPDFHNSLRPVSIIVEGDSRTGKTMWARALGSHNYLSGHLDFNARVYSNEVDYNVIDDVPPHYLKMKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKEFLDKEENLSLKNWTLHNEIRLSQLPPLSNHSTELPRRRGQSGDDEF |
References More References in PubMed
| 1 |
First Report of Artichoke yellow ringspot virus in Globe Artichoke in Turkey. Paylan IC, et al. Plant Dis. 2013 Oct;97(10):1388. doi: 10.1094/PDIS-04-13-0423-PDN. PMID: 30722161 |
|---|---|
| 2 |
Siddiqui SA, et al. Mol Plant Microbe Interact. 2008 Feb;21(2):178-87. doi: 10.1094/MPMI-21-2-0178. PMID: 18184062 |
| 3 |
Batista JG, et al. Arch Virol. 2022 Jul;167(7):1597-1602. doi: 10.1007/s00705-022-05410-0. Epub 2022 May 14. PMID: 35562613 |
| 4 |
Macroptilium yellow mosaic virus, a New Begomovirus Infecting Macroptilium lathyroides in Cuba. Ramos PL, et al. Plant Dis. 2002 Sep;86(9):1049. doi: 10.1094/PDIS.2002.86.9.1049B. PMID: 30818538 |
| 5 |
Gebre-Selassie K, et al. Plant Dis. 2002 Sep;86(9):1052. doi: 10.1094/PDIS.2002.86.9.1052C. PMID: 30818549 |
| 6 |
Detection of a Geminivirus Infecting Sweet Potato in the United States. Lotrakul P, et al. Plant Dis. 1998 Nov;82(11):1253-1257. doi: 10.1094/PDIS.1998.82.11.1253. PMID: 30845415 |
| 7 |
First Report of Tomato ringspot virus in Butterfly Bush (Buddleia davidii). Hughes PL, et al. Plant Dis. 2003 Jan;87(1):102. doi: 10.1094/PDIS.2003.87.1.102B. PMID: 30812689 |
| 8 |
David N, et al. Plant Dis. 2010 Jan;94(1):130. doi: 10.1094/PDIS-94-1-0130B. PMID: 30754413 |