Tobacco yellow crinkle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000892135.1 |
| Isolate | Cuba |
| Release date | 2015/2/22 |
| Submitter | Fiallo-Olive,E., Rivera-Bustamante,R.F., Martinez-Zubiaur,Y., Moriones,E., Navas-Castillo,J. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
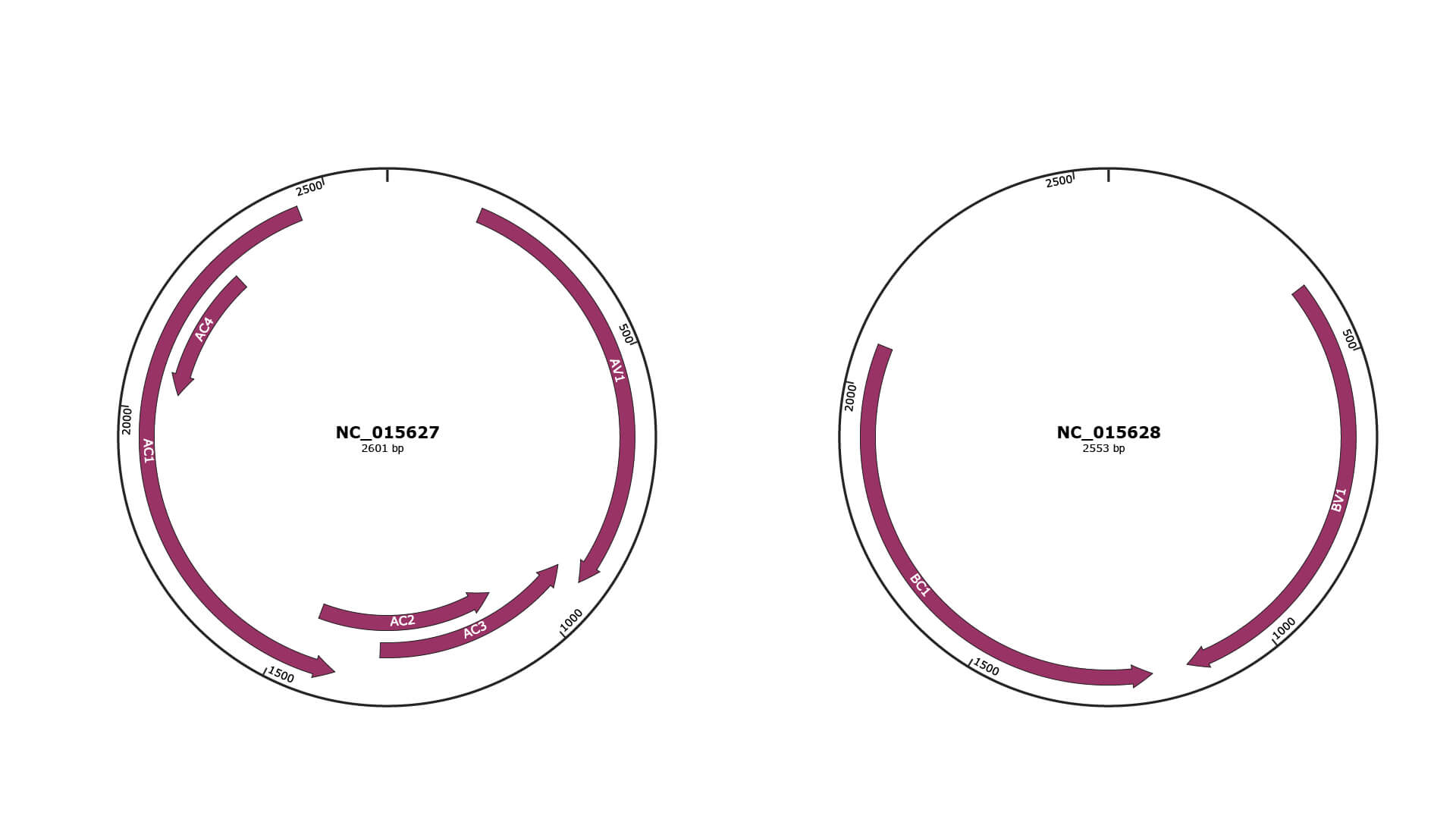
JBrowse
Genome
NC_015627
NC_015628
Gene Information
| NCBI Accession | YP_004564601.1 |
|---|---|
| Location | 164-919 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGTTCTATGGCCGGGACCTCTAAGGTGTCCCGCAATGCCAACTATTCACCCCGTACAGCTATGGGCCCTAAATTTGATAAGGCCGCTGCTTGGGTTAATAGGCCCATGTACAGGAAGCCCAGGATTTATCGGACGTTGAGAAGCCCAGATGTTCCAAGAGGCTGTGAAGGGCCTTGCAAAGTCCAGTCTTATGAGCAGCGGCATGATATTTCACATGTTGGCAAGGTGATGTGTATTTCGGACGTGACACGTGGTAATGGTATTACCCATCGTGTTGGCAAGCGTTTTTGCGTGAAGTCCGTGTACATTTTGGGCAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCATACCAACAGCGTCATGTTTTGGTTGGTCAGAGACAGGAGACCATATGGCACCCCTCAGGATTTTGGCCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGTTATCAAGTCATGCACAAGTTCTACGCAAAGGTTACAGGTGGACAGTATGCGAGTAACGAGCAGGCGTTAGTGAAGCGTTTCTGGAAGGTGAACAATTACGTGGTGTACAACCACCAAGAAGCAGGCAAATACGAGAATCATACGGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCCGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATATTAAATTAA |
| Protein Sequence | MPKRDAPWRSMAGTSKVSRNANYSPRTAMGPKFDKAAAWVNRPMYRKPRIYRTLRSPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPQDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
| NCBI Accession | YP_004564602.1 |
|---|---|
| Location | 916-1314 |
| Gene Name | AC3 |
| Protein Name | replication enhancement protein |
| Coding Region | ATGGATTCACGCACCGGGGAGAGCATCACTGCGGCTCAGGCAGAGAATTCCGTTTTTATCTGGGAGACTCCAAATCCCCTTTATTTCAAGATACACCACGTAGAGAACCCGTTGTACACGAGAACCAGGATCTACCACATCGAAGTCCGGTTCAATTACAACCTTCGGAAAGCGTTGGGTCTCCACAAAGCCTTCTTCAATTTCCAAGTTTGGACGACTTCGATGACAGCTTCTGGGCAGAGATATTTAAGTAGATTCAAATTACTTGTAATGTCTTATTTAGATAGTTTAGGCGTTATTGGTATAAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAAATCGTATGTAACTGATGTACTTGAGAATCATGAAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGESITAAQAENSVFIWETPNPLYFKIHHVENPLYTRTRIYHIEVRFNYNLRKALGLHKAFFNFQVWTTSMTASGQRYLSRFKLLVMSYLDSLGVIGINNVIRAVRFATDKSYVTDVLENHEIKFKIY |
| NCBI Accession | YP_004564603.1 |
|---|---|
| Location | 1061-1450 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCTAAATTCATCACCCTTGAAGCCCCCCTCTATCAAAGCACAGCACAGGATTGCTAAAAAAAGAGCTGTTCGTCGACGACGCATTGATTTGAACTGCGGGTGTTCTATCTTCCTCCACATCAACTGCGCAGATAATGGATTCACGCACCGGGGAGAGCATCACTGCGGCTCAGGCAGAGAATTCCGTTTTTATCTGGGAGACTCCAAATCCCCTTTATTTCAAGATACACCACGTAGAGAACCCGTTGTACACGAGAACCAGGATCTACCACATCGAAGTCCGGTTCAATTACAACCTTCGGAAAGCGTTGGGTCTCCACAAAGCCTTCTTCAATTTCCAAGTTTGGACGACTTCGATGACAGCTTCTGGGCAGAGATATTTAAGTAG |
| Protein Sequence | MLNSSPLKPPSIKAQHRIAKKRAVRRRRIDLNCGCSIFLHINCADNGFTHRGEHHCGSGREFRFYLGDSKSPLFQDTPRREPVVHENQDLPHRSPVQLQPSESVGSPQSLLQFPSLDDFDDSFWAEIFK |
| NCBI Accession | YP_004564604.1 |
|---|---|
| Location | 1392-2447 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCATCAGTTAAACGTTTTAGAATAAATGCCAAAAACTATTTCATCACTTATCCCAAGTGCTCTCTCACCAAAGAAGACGCACTTTCCCAATTACAAAACCTAAACACACCCGTTAACAAGAAGTTTATCAAGGTGTGCAGAGAGCTTCACGAGAATGGGGAGCCTCATCTCCATGTGCTCATACAATTCGAAGGGAAATATACATGCACGAATAACAGATTCTTCGACCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGCAATGGGGAGATTTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAATCTACTAACGATACATATGCCAAGGCGTTAAATGCCTCTTCTGCAGAAGAGGCACTGATGATAATCAAAGAAGAGCAGCCTCAACATTTTTTCCTTCAACATCATAATTTGGTTGCCAATGCTCATCGGATTTTTCAGAAGGCTCCGGAACCATGGGTTCCTCCGTTTCAACTCTCCTCCTTTACTAACGTTCCAGACGAGATGAGTTCATGGGCCGATGAGTATTTTGGTCGGAGTTCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATAATTGAAGGTGATTCTCGAACAGGCAAAACCATGTGGGCGCGTGCTTTAGGCCCACATAATTATTTGAGTGGTCACCTCGACTTCAATTCCAAGGTCTTCTCGAATGATGTGGAGTATAACGTCATTGATGACATTGCTCCGCATTATTTAAAGCTAAAGCACTGGAAAGAACTCATAGGGGCCCAAAGGGACTGGCAATCAAACTGTAAGTACGGCAAGCCAGTTCAAATTAAAGGTGGCATACCATCAATCGTGCTGTGCAATCCAGGAGAGGGGAGCAGTTATAAATGTTTCCTCGACAAAGAGGAAAATGCACCACTAAGAGCGTGGACTATTAAAAATGCTAAATTCATCACCCTTGAAGCCCCCCTCTATCAAAGCACAGCACAGGATTGCTAA |
| Protein Sequence | MPSVKRFRINAKNYFITYPKCSLTKEDALSQLQNLNTPVNKKFIKVCRELHENGEPHLHVLIQFEGKYTCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLQWGDFQIDGRSARGGCQSTNDTYAKALNASSAEEALMIIKEEQPQHFFLQHHNLVANAHRIFQKAPEPWVPPFQLSSFTNVPDEMSSWADEYFGRSSAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFSNDVEYNVIDDIAPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKCFLDKEENAPLRAWTIKNAKFITLEAPLYQSTAQDC |
| NCBI Accession | YP_004564605.1 |
|---|---|
| Location | 2033-2290 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGGAGCCTCATCTCCATGTGCTCATACAATTCGAAGGGAAATATACATGCACGAATAACAGATTCTTCGACCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGCAATGGGGAGATTTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAATCTACTAACGATACATATGCCAAGGCGTTAA |
| Protein Sequence | MGSLISMCSYNSKGNIHARITDSSTWSPQPGQHISIRTYRELNLAPTSSPTSTRTEIHCNGEISRSTAEVLEEAANLLTIHMPRR |
| NCBI Accession | YP_004564606.1 |
|---|---|
| Location | 371-1141 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttling protein |
| Coding Region | ATGTATCCTACGAAGTATAGGCGTGGGTCTTCATATAGTCAAAGACGATTTGTTGCACGTAATAATGGTTTAAAGCGTGCAACCTTTGTTAGACGCAATGATGGTAAACGTCGCAATGGCCCATTAAACAAGTCCTGTGACGAGCCCAAAATGTCGTCACAACGTATACATGAAAACCAATATGGCCCTGAATTTGTGATGTCTCATAATTCAGCAATATCAACGTTCATCAATTTTCCTGTGCTTGGTAAAACATCTCCTAACCGAAGCAGGTCGTATATTAAATTAAAGCGTTTATCATTTAAAGGAACCGTTAAGATTGAGCGTGTTCATGCCGATGTGAACATGGATGGACTAACTTCCAAGATAGAAGGTGTGTTCTCTCTTGTTATAGTTGTGGATCGCAAGCCTCATTTAAGCTCTTCTGGATGTTTGCACACATTCGATGAACTATTTGGTGCAAGAATCCACAGCCATGGGAACCTAGCCATTACACCCGCTTTAAAAGATCGTTATTATGTTCGACATGTTTTGAAGCGTGTATTGTCAGTGGAGAAAGATAGTGTAATGGTAGACCTGGAAGGATCGACACCGTTATCTACAAGGCGTTATAACTGTTGGTCCAATTTTAAGGATCTTGAACATGACTCATGTAACGGTGTTTATGCTAATATCAGCAAGAATGCCATTTTAGTTTATTATTGTTGGATGTCGGATGCAATTTCTAAGGCATCCACATTTGTATCTTATGACCTTGATTATGTGGGTTAA |
| Protein Sequence | MYPTKYRRGSSYSQRRFVARNNGLKRATFVRRNDGKRRNGPLNKSCDEPKMSSQRIHENQYGPEFVMSHNSAISTFINFPVLGKTSPNRSRSYIKLKRLSFKGTVKIERVHADVNMDGLTSKIEGVFSLVIVVDRKPHLSSSGCLHTFDELFGARIHSHGNLAITPALKDRYYVRHVLKRVLSVEKDSVMVDLEGSTPLSTRRYNCWSNFKDLEHDSCNGVYANISKNAILVYYCWMSDAISKASTFVSYDLDYVG |
| NCBI Accession | YP_004564607.1 |
|---|---|
| Location | 1202-2071 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGAATCTCAGTTAGCAAATCCTCCAAATGCGTTTAATTACATTGAGTCTCATAGAGACGAATATCAGCTGTCTCATGATCTAACTGACATTATCCTTCAATTTCCTTCCACGGCTGCTCAGTTAACTGCAAGGCTCAATCGTAGTTGTATGAAGATAGACCATTGCGTCATCGAATACAGGCAACAAGTCTCAATTAACGCAACAGGGTCGGTCATTGTAGAGATACATGACAAAAGAATGACGGACAATGAATCGTTACAAGCATCGTGGACGTTTCCCATAAGATGCAACATAGATCTCCATTATTTCTCGTCGTCATTCTTTTCGTTAAAAGACCCAATTCCATGGAAATTATACTACAGAGTGTCCGATACAAATGTACATCAACGAACACATTTTGCCAAATTCAAGGGCAAGTTGAAATTATCTACCGCTAAACACTCTGTAGATATACCCTTCCGGGCTCCCACGGTCAAGATTCATTCGAAACAGTTTTCGCACAAAGATGTCGACTTCTCGCATGTGGATTATGGACCGTGGGAAAGAAAAACCTTGAGCTCCACATCAATGTCCAGATTTGGGCTACCAGGCCCAATTGAATTAAAACCAGGTGAATCATGGGCCTCAAGGAGCACTATTGGGAGGACTCACACGGAGACGGAATCAGAAATACACCCATATAGAGAGCTCAATCGTCTAGGACCAAGCGTGCTAGACCCAGGTGATTCGGCGTCACAGGTCGGCTTACAGAGGGCCCAATCAAATATAACGATGTCCATGGCCCAATTAAACGACCTTGTTAGGACAACGGTCCAAGAGTGTATTAACAATAATTGTAATCCGTCACAACCCAAATCGTTGCAATAA |
| Protein Sequence | MESQLANPPNAFNYIESHRDEYQLSHDLTDIILQFPSTAAQLTARLNRSCMKIDHCVIEYRQQVSINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIHSKQFSHKDVDFSHVDYGPWERKTLSSTSMSRFGLPGPIELKPGESWASRSTIGRTHTETESEIHPYRELNRLGPSVLDPGDSASQVGLQRAQSNITMSMAQLNDLVRTTVQECINNNCNPSQPKSLQ |
References More References in PubMed
| 1 |
Ogawa T, et al. Virus Res. 2008 Nov;137(2):235-44. doi: 10.1016/j.virusres.2008.07.021. Epub 2008 Sep 13. PMID: 18722488 |
|---|---|
| 2 |
Dong J, et al. Viruses. 2023 Sep 21;15(9):1972. doi: 10.3390/v15091972. PMID: 37766378 |
| 3 |
Genome structure of tobacco necrosis virus strain A. Meulewaeter F, et al. Virology. 1990 Aug;177(2):699-709. doi: 10.1016/0042-6822(90)90536-z. PMID: 2371773 |
| 4 |
Hu J, et al. Sci Rep. 2023 Jun 20;13(1):10040. doi: 10.1038/s41598-023-37022-2. PMID: 37340012 |
| 5 |
The Role of 3'UTR of RNA Viruses on mRNA Stability and Translation Enhancement. Rasekhian M, et al. Mini Rev Med Chem. 2021;21(16):2389-2398. doi: 10.2174/1389557521666210217092305. PMID: 33596798 |
| 6 |
Malvastrum yellow vein Yunnan virus is amonopartite begomovirus. Jiang T, et al. Acta Virol. 2010;54(1):21-6. doi: 10.4149/av_2010_01_21. PMID: 20201610 |
| 7 |
Ishikawa M, et al. Mol Gen Genet. 1991 Nov;230(1-2):33-8. doi: 10.1007/BF00290647. PMID: 1745239 |
| 8 |
Sardo L, et al. Virus Res. 2011 Nov;161(2):170-80. doi: 10.1016/j.virusres.2011.07.021. Epub 2011 Aug 4. PMID: 21843560 |
| 9 |
Xiong Q, et al. Phytopathology. 2007 Apr;97(4):405-11. doi: 10.1094/PHYTO-97-4-0405. PMID: 18943280 |
| 10 |
Strawberry crinkle virus, a Cytorhabdovirus needing more attention from virologists. Posthuma KI, et al. Mol Plant Pathol. 2000 Nov 1;1(6):331-6. doi: 10.1046/j.1364-3703.2000.00041.x. PMID: 20572980 |