Tobacco leaf curl Cuba virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002310935.1 |
| Isolate | Cuba |
| Release date | 2017/9/21 |
| Submitter | Chang-Sidorchuk,L., Gonzalez-Alvarez,H., Martinez-Zubiaur,Y., Navas-Castillo,J., Fiallo-Olive,E. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
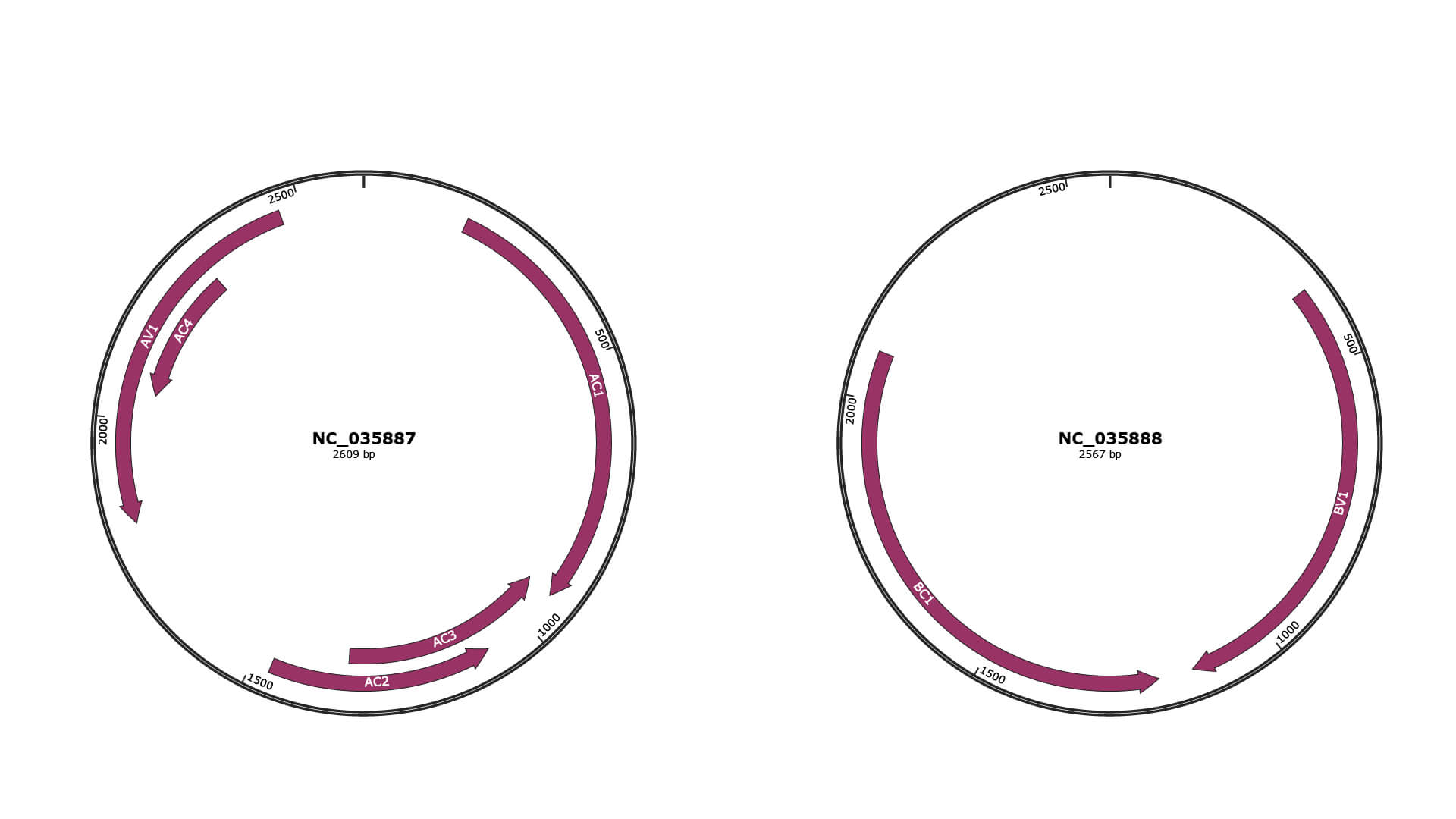
Genomic Organization
JBrowse
Genome
NC_035887
NC_035888
Gene Information
| NCBI Accession | YP_009428561.1 |
|---|---|
| Location | 182-937 |
| Gene Name | AC1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATGCCCCATGGCGCCCGATGGCAGGAACTTCGAAGGTAAGTCGCAATGCAAATTATTCTCCCCGTGCAGGTATTGGGCCAAGAATGAACAGGGCATCGGAATGGGTTAACAGGCCTATGTACAGGAAGCCCAGGATCTATCGGACGCTACGGACGCCCGACATTCCGAGAGGCTGTGAAGGCCCGTGCAAGGTCCAGTCCTATGAACAGCGCCACGATATCTCTCACGTGGGTAAGGTGATGTGTATATCTGATGTCACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATACTAGGTAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGCGTTATGTTCTGGTTGGTCAGAGACCGTCGACCGTATGGGACGCCTATGGATTTTGGACAGGTGTTCAACATGTTCGACAACGAACCCAGCACTGCCACGGTTAAGAACGATCTACGTGATCGTTACCAGGTTATGCACCGGTTCTATGGTAAGGTCACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATTGTCAGGCGATTCTGGAAGGTCAACAACTATGTCGTCTACAACCACCAGGAAGCTGCCAAGTACGAGAACCACACTGAGAACGCGCTGTTATTGTACATGGCATGTACACATGCCTCTAACCCCGTGTATGCAACTCTGAAGATTCGAATCTATTTTTATGATTCGATAATGAATTAA |
| Protein Sequence | MPKRDAPWRPMAGTSKVSRNANYSPRAGIGPRMNRASEWVNRPMYRKPRIYRTLRTPDIPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEQAIVRRFWKVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_009428562.1 |
|---|---|
| Location | 934-1332 |
| Gene Name | AC3 |
| Protein Name | REn |
| Coding Region | ATGGATTTACGCACCGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATATACAGAGTAGAGGATCTGCTATACACCAGAACAAGAGTGTACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGTTAGGTTTACGTATTTAGTTAATATGTATTTAGATCAGTTAGGAGTGATTTCCATTAACAATGTAATTAGAGCTGTTCGTTTTGCAACGGACAGATCGTATGTGAATTATGTACTGGAAAATCATTCAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDLRTGELITAHQAENGVYIWEIENPLYFKIYRVEDLLYTRTRVYHIQIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSTYLVRFTYLVNMYLDQLGVISINNVIRAVRFATDRSYVNYVLENHSIKFKIY |
| NCBI Accession | YP_009428563.1 |
|---|---|
| Location | 1079-1468 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGCGGTCTTCATCACCCTCACATCCTCCCTCTATCAAGATAGCACACAGGCAGGCCAAGAGGAGGGCAGTCAGGAGGAGACGCATTGATCTTAGGTGCGGGTGCTCCATATACTTCCATATAGACTGCACGGGACATGGATTTACGCACCGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATATACAGAGTAGAGGATCTGCTATACACCAGAACAAGAGTGTACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGTTAG |
| Protein Sequence | MRSSSPSHPPSIKIAHRQAKRRAVRRRRIDLRCGCSIYFHIDCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPIFQDIQSRGSAIHQNKSVPHPDTVQPQPEESVASPQSLPELPSLDDIDDSFWVNLFS |
| NCBI Accession | YP_009428564.1 |
|---|---|
| Location | 1817-2464 |
| Gene Name | AV1 |
| Protein Name | replication protein |
| Coding Region | ATGCCACGGAAGGGTTCTTCAATTGCTAATGCCAAAAACTATTTCCTTACTTATCCACAGTGTTCCCTTACCAAAGAGGAGGCACTTTCCCAATTAAAAAAACTAAATACTCCGGTGAACAAGAAGTTCATCAAAATCTGCAGAGAGCTCCATCAAGATGGGAAGCCTCATCTCCACGTGCTTATACAATTCGAGGGCAAATACAACTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCATCTCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTTGAATGGGGAAAGTTCCAGATTGACGGAAGAAGTGCTAGAGGAGGCTGCCAAACAACTAATGACACATATGCCAAGGCGTTGAATGCCTCCTCTGCTGAGGAAGCTCTGCAAATAATAAAAGAGGAACAGCCTCAACATTTTTTCCTTCAGCATCATAATTTGGTAGCAAATGCTCATCGGATCTTTCAAAAGGCTCCGGAACCATGGGTCCCTCCGTTTCAACTCTCCTCTTTCACTAACGTTCCTGAAGAGATGCAAGACTGGGCCGATGAGTATTTTGGAAGAGGTTCCGCTGCGCGGCCGGAAGACCAGTAA |
| Protein Sequence | MPRKGSSIANAKNYFLTYPQCSLTKEEALSQLKKLNTPVNKKFIKICRELHQDGKPHLHVLIQFEGKYNCTNNRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGKFQIDGRSARGGCQTTNDTYAKALNASSAEEALQIIKEEQPQHFFLQHHNLVANAHRIFQKAPEPWVPPFQLSSFTNVPEEMQDWADEYFGRGSAARPEDQ |
| NCBI Accession | YP_009428565.1 |
|---|---|
| Location | 2050-2307 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGAAGCCTCATCTCCACGTGCTTATACAATTCGAGGGCAAATACAACTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCATCTCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTTGAATGGGGAAAGTTCCAGATTGACGGAAGAAGTGCTAGAGGAGGCTGCCAAACAACTAATGACACATATGCCAAGGCGTTGA |
| Protein Sequence | MGSLISTCLYNSRANTTARITDSSIWSPHLGQHISIRTYRELNQAPTSSPTSTRTEIHLNGESSRLTEEVLEEAAKQLMTHMPRR |
| NCBI Accession | YP_009428566.1 |
|---|---|
| Location | 370-1140 |
| Gene Name | BV1 |
| Protein Name | NSP |
| Coding Region | ATGTATCCTTTGAGGAATAAACGTGGATCGTATTTTACTGCACGTCGATATTATCCACGTAATACATTTTCTAGGCGTCCATCTACTTCCAAGAAACAAGATGGGAAACGACGAGCTGTAAATACCAATAAGACGAATGACGAGCCGAAGATGTCAGCCCAACGCATACATGAGAATCAGTATGGGCCTGATTTTGTTATGGCCCATAATACTGCTATCTCGACCTTCATTAGTTACCCGGGCTTGGGTTCAACTTTACCCAACCGAAGCAGGTCCTATATTAAGTTGAAACAACTACGTTTCAAAGGGACCGTGAAGATTGAACGTGTTCAATCGGATCTGAACATGGATGGTTCTACCCCGAAGGTTGAAGGAGTCTTCTCCCTTGTTGTTGTTGTGGATCGTAAACCCCATGTTGGTCCTTCTGGCTGTCTACAATCATTTGACGAACTCTTTGGTGCAAGGATCCACAGCCATGGCAACCTCAACGTAACCTCTGCATTGAAAGATCGTTATTATATTCGACACGTTTGCAAACGTGTATTCTCAGTGGAGAAGGACACGTTGATGGTAGATGTGGAGGGATTCATTCCCCTCTCTAACAAGCGTTTCAATTGTTGGTCTACGTTCAAGGATCTTGATCGTGATTCATGCAAGGGTGTTTATGACAATATAAGCAAGAACGCCCTCTTAGTTTATTATTGTTGGATGTCGGATACGATGTCTACCGCATCTACCTTTGTATCGTTTGACCTTGATTATGTCGGTTGA |
| Protein Sequence | MYPLRNKRGSYFTARRYYPRNTFSRRPSTSKKQDGKRRAVNTNKTNDEPKMSAQRIHENQYGPDFVMAHNTAISTFISYPGLGSTLPNRSRSYIKLKQLRFKGTVKIERVQSDLNMDGSTPKVEGVFSLVVVVDRKPHVGPSGCLQSFDELFGARIHSHGNLNVTSALKDRYYIRHVCKRVFSVEKDTLMVDVEGFIPLSNKRFNCWSTFKDLDRDSCKGVYDNISKNALLVYYCWMSDTMSTASTFVSFDLDYVG |
| NCBI Accession | YP_009428567.1 |
|---|---|
| Location | 1200-2081 |
| Gene Name | BC1 |
| Protein Name | MP |
| Coding Region | ATGGATTCTCAGTTAGTTAATCCTCCTAACGCATTCAACTACATAGAGTCTCACCGGGACGAGTACCAGCTTTCACATGACCTAACTGAGATAATCCTGCAATTTCCTTCGACGGCGTCTCAGTTGACAGCTAGGCTCAGTCGTAGCTGTATGAAGATAGACCACTGCGTCATAGAATACAGGCAACAAGTTCCGATCAACGCCACGGGGACGGTAATAGTGGAGATCCACGATAAAAGAATGACGGACAATGAGTCCTTACAGGCGTCCTGGACTTATCCGATCAGGTGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCACTCAAAGACCCAATTCCATGGAAATTGTACTATCGCGTTTGCGATACAAATGTTCATCAAAGGACCCACTTTGCCAAGTTCAAGGGCAAGCTGAAATTGTCTACGGCGAAACACTCGGTCGACATTCCATTCCGGGCACCGACAGTCAAGATCCTGTCCAAACAGTTCACCGACAAAGACGTGGACTTCTCCCATGTCGACTATGGGAAATGGGAGAGGAAGCCCATAAGATGCGCATCAATGTCAAGACTTGGGCTAAGAGGCCCAATCGAGATTAGGCCTGGCGAGTCGTGGGCTTCTAGAAGTACAATAGGTACAGGCGCGTCAGACGCGGACTCAGAGATGGAGAACGAACTCCATCCATATAGACATCTAAACAGGCTGGGAACCAGCGTTCTAGACCCAGGAGAGTCTGCTTCGATCGTGGGGGCCCAAAGAGCGGGTTCCAACATAACAATGTCGATGGGCCAGTTGAACGAGTTAGTTAGGACAACTGTCCAAGAATGTATTAATAGTAATTGTCAGGCTTCTCAAGCCAAATCATTAAAATAA |
| Protein Sequence | MDSQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQASWTYPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRLGLRGPIEIRPGESWASRSTIGTGASDADSEMENELHPYRHLNRLGTSVLDPGESASIVGAQRAGSNITMSMGQLNELVRTTVQECINSNCQASQAKSLK |
References More References in PubMed
| 1 |
Rapid LAMP-Based Detection of Mixed Begomovirus Infections in Field-Grown Tomato Plants. Ruiz-Otaño Y, et al. Viruses. 2025 Dec 23;18(1):19. doi: 10.3390/v18010019. PMID: 41600784 |
|---|---|
| 2 |
Collins AM, et al. Virus Genes. 2009 Dec;39(3):387-95. doi: 10.1007/s11262-009-0401-y. Epub 2009 Sep 20. PMID: 19768650 |
| 3 |
Expression and antiviral application of exogenous lectin (griffithsin) in sweetpotatoes. Liu S, et al. Front Plant Sci. 2024 Jul 16;15:1421244. doi: 10.3389/fpls.2024.1421244. eCollection 2024. PMID: 39081525 |
| 4 |
Simmonds-Gordon RN, et al. Arch Virol. 2014 Oct;159(10):2815-8. doi: 10.1007/s00705-014-2112-5. Epub 2014 May 29. PMID: 24872185 |
| 5 |
Maliano MR, et al. PLoS One. 2021 Apr 28;16(4):e0250066. doi: 10.1371/journal.pone.0250066. eCollection 2021. PMID: 33909644 |
| 6 |
Ramos PL, et al. Arch Virol. 2003 Sep;148(9):1697-712. doi: 10.1007/s00705-003-0136-3. PMID: 14505083 |