Sweet potato leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000864705.1 |
| Isolate | USA |
| Release date | 2015/2/13 |
| Submitter | Lotrakul,P., Valverde,R.A., Clark,C.A., Sim,J., De La Torre,R. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
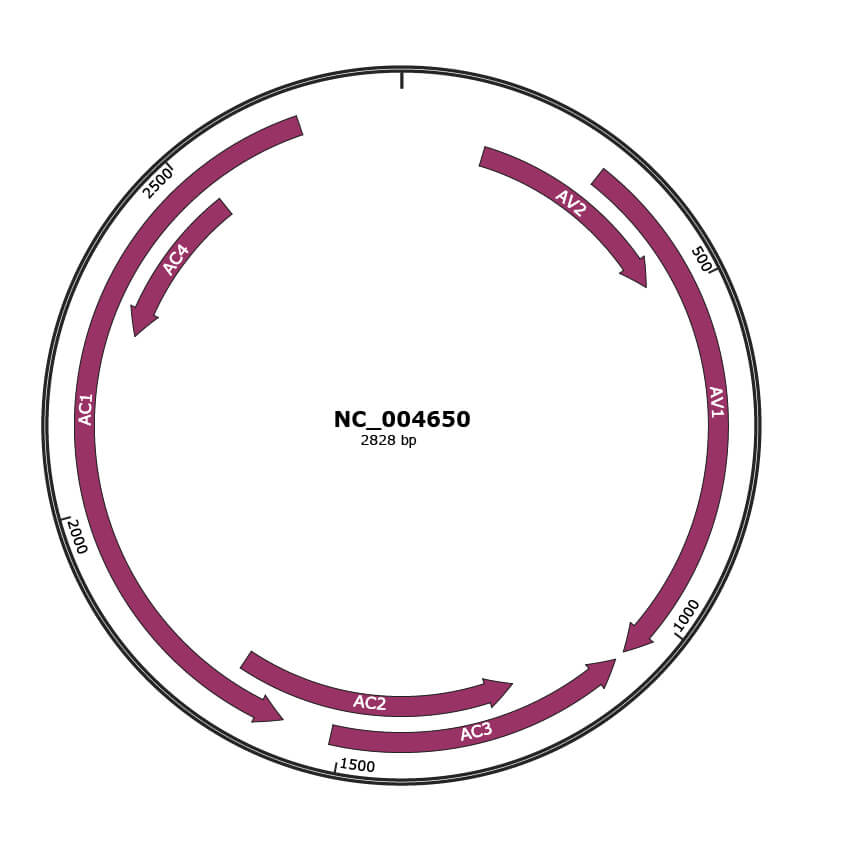
JBrowse
Genome
NC_004650
Gene Information
| NCBI Accession | NP_808840.1 |
|---|---|
| Location | 132-476 |
| Gene Name | AV2 |
| Protein Name | precoat protein AV2 |
| Coding Region | ATGGCTGAATTGTGGGACCCTTTGCAGAACCCACTACCAGATACTTTATACGGTTTTAGGTGTATGCTATCCGTAAAATACTTGCAAAGTATTTTGAAGAAATACGAGCCAGGAACCTTAGGGTTCGAGCTCTGTTCGGAGTTAATCCGTATATTCAGAGTCAGGCAGTATGACAGGGCGAATGCGCGTTTCGCCGAGATTTCATCCATATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCGGATGAAGAGAAGGAGGGGTGA |
| Protein Sequence | MAELWDPLQNPLPDTLYGFRCMLSVKYLQSILKKYEPGTLGFELCSELIRIFRVRQYDRANARFAEISSIWGETGKTEAELRDSYRALHWECCPNCCPKLCPGFKRRPDEEKEG |
| NCBI Accession | NP_808841.1 |
|---|---|
| Location | 301-1065 |
| Gene Name | AV1 |
| Protein Name | coat protein AV1 |
| Coding Region | ATGACAGGGCGAATGCGCGTTTCGCCGAGATTTCATCCATATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCGGATGAAGAGAAGGAGGGGTGACCGCATCCCGAAGGGATGTGTGGGTCCCTGTAAGGTCCAGGACTATGAGTTCAAGATGGACGTTCCCCACACGGGAACGTTTGTCTGTGTCTCGGATTTTACAAGGGGTACTGGGCTTACCCATCGCCTGGGTAAGCGTGTTTGTGTGAAGTCCATGGGTATAGATGGGAAGGTCTGGATGGATGATAATGTGGCCAAGAGAGATCACACCAATATCATCACGTATTGGTTGATTCGTGACAGAAGGCCCAATAAGGATCCGCTGAACTTTGGCCAGATCTTCACCATGTACGACAATGAGCCCACTACTGCTAAGATCCGAATGGATCTGAGGGATAGAATGCAGGTCTTGAAGAAGTTTTCTGTTACAGTTTCAGGAGGTCCATACAGCCACAAGGAGCAGGCATTAATTAGGAAGTTTTTTAAGGGTTTGTATAATCATGTTACTTACAATCACAAGGAAGAAGCTAAGTATGAGAATCAATTAGAGAATGCACTTATGCTGTATAGTGCTAGCAGTCATGCTAGTAATCCTGTGTATCAGACCCTGCGTTGCAGGGCTTATTTCTATGATTCGCATAATAATTAA |
| Protein Sequence | MTGRMRVSPRFHPYGGRPVRRRLNFETAIVPYTGNAVPIAARSYVPVSRGVRMKRRRGDRIPKGCVGPCKVQDYEFKMDVPHTGTFVCVSDFTRGTGLTHRLGKRVCVKSMGIDGKVWMDDNVAKRDHTNIITYWLIRDRRPNKDPLNFGQIFTMYDNEPTTAKIRMDLRDRMQVLKKFSVTVSGGPYSHKEQALIRKFFKGLYNHVTYNHKEEAKYENQLENALMLYSASSHASNPVYQTLRCRAYFYDSHNN |
| NCBI Accession | NP_808842.1 |
|---|---|
| Location | 1081-1515 |
| Gene Name | AC3 |
| Protein Name | AC3 |
| Coding Region | ATGGATTCACGCACAGGGGAATCAATAAGTCATGCTCAGACTACGAGAGCAGTCGAATTCGACACCAACCCCATGTCTGTGGGTCGGACTGCACCGTTCCATCTCAGAATAATGTATGTCCACGAGAGCACACAGGGGAGAACCATCCTCAAATTCCAGCTGAGGGTGAACTACAGGGAAAGGAGGCAACTGGGATTCCACAAGATCTTCCTCCAATTCCGGATCTTGACGACCCGTCTAACTGGTGCTATTCACAGTTGGACTGGTATTTTGGAACGCCTTAAATGGCGCATATGTAATGAATTAGCAAATTTAGGGTTTTTTAGTTTAGTTAATTTAGTTTTTGTTATTAGATATCTTCCAAGAGTATGTTCTTGGATAGATGAATTAGATACTGTAGATTGTAATGATGATGTAAAGGTATTACTCTATTAA |
| Protein Sequence | MDSRTGESISHAQTTRAVEFDTNPMSVGRTAPFHLRIMYVHESTQGRTILKFQLRVNYRERRQLGFHKIFLQFRILTTRLTGAIHSWTGILERLKWRICNELANLGFFSLVNLVFVIRYLPRVCSWIDELDTVDCNDDVKVLLY |
| NCBI Accession | NP_808843.1 |
|---|---|
| Location | 1232-1678 |
| Gene Name | AC2 |
| Protein Name | transactivator protein AC2 |
| Coding Region | ATGTCCAATCCCCTTTCTGGGTACAAGAGGAAGTGTCCCATTCAGGAGCCACTGCACACAGAGGCGAAGAAGGCCAAGAGGAAAGTTCCTGAACAGAGGACGAGGATAGTGTGGAAGGGTTGCGGCTGTTCAGCCTTCATAACAACAACCTGCAAGTACCAGCATGGATTCACGCACAGGGGAATCAATAAGTCATGCTCAGACTACGAGAGCAGTCGAATTCGACACCAACCCCATGTCTGTGGGTCGGACTGCACCGTTCCATCTCAGAATAATGTATGTCCACGAGAGCACACAGGGGAGAACCATCCTCAAATTCCAGCTGAGGGTGAACTACAGGGAAAGGAGGCAACTGGGATTCCACAAGATCTTCCTCCAATTCCGGATCTTGACGACCCGTCTAACTGGTGCTATTCACAGTTGGACTGGTATTTTGGAACGCCTTAA |
| Protein Sequence | MSNPLSGYKRKCPIQEPLHTEAKKAKRKVPEQRTRIVWKGCGCSAFITTTCKYQHGFTHRGINKSCSDYESSRIRHQPHVCGSDCTVPSQNNVCPREHTGENHPQIPAEGELQGKEATGIPQDLPPIPDLDDPSNWCYSQLDWYFGTP |
| NCBI Accession | NP_808844.1 |
|---|---|
| Location | 1587-2681 |
| Gene Name | AC1 |
| Protein Name | replication initiation protein AC1 |
| Coding Region | ATGGCTCCTCCAAAACGTTTTAAAATTCAGGCCAAAAATTATTTTATTACTTATCCACGCTGTTCTCTCTCAAAAGAGGACTGCCTAGCCCAACTCCTAAATATACAAACACCCAGCAACAAAAAATATATACACGTAGCAAGAGAACTGCACGAGGATGGGGAACCTCACCTCCATGTGTTGGTGCAGTTCGAAGGCAAATTCGTCTGCACAAATAGCAGATTCTTCGATCTGGTCTCACCGAACAGATCGAATCACTTTCACCCCAACATCCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACGTCGATAAGGACGGGGATACCATCACCTGGGGTGAATTCCAGGTCGACGGCAGATCTGCTAGAGGAGGCCAGCAGACTGCTAACGACGCAGCCGCAGAGGCTCTAAACGCAGGTTCTAAAGAAGCTGCGTTGCAAATAATCAGGGAGAAACTCCCTGAAAAATATTTATTTCAATTTCATAATTTAGTTAGTAATTTAGATAGGATTTTTTCTCCTCCACCTTCTGTATATTCTTCCCCTTTTTCGTCTTCTTCTTTCAATGCCGTTCCTGACATTATCAGCGACTGGGCCGCTGAAAATGTCATGGATTCCGCTGCGCGGCCGGATAGACCCATTTCCATTGTTATTGAAGGCCCAAGCAGAATAGGCAAAACAGTATGGGCCAGGTCTTTGGGCCCTCACAATTATTTGTGTGGGCATTTAGATCTAAGCCCAAAAGTATACAGCAACAGTGCTTGGTATAACGTCATTGATGACGTCAACCCCCAATACCTAAAGCACTTTAAGGAATTCATGGGGGCCCAGAAGGACTGGCAATCCAACTGTAAATACGGAAAGCCAGTTCGAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGAGAGGGATCCTCATTTAAACTCTGGTTGGACAAACCAGAGCAAGGAGCACTCAAGAATTGGGCAACAGCAAACGCTATATTCTGCGATGTCCAATCCCCTTTCTGGGTACAAGAGGAAGTGTCCCATTCAGGAGCCACTGCACACAGAGGCGAAGAAGGCCAAGAGGAAAGTTCCTGA |
| Protein Sequence | MAPPKRFKIQAKNYFITYPRCSLSKEDCLAQLLNIQTPSNKKYIHVARELHEDGEPHLHVLVQFEGKFVCTNSRFFDLVSPNRSNHFHPNIQGAKSSSDVKSYVDKDGDTITWGEFQVDGRSARGGQQTANDAAAEALNAGSKEAALQIIREKLPEKYLFQFHNLVSNLDRIFSPPPSVYSSPFSSSSFNAVPDIISDWAAENVMDSAARPDRPISIVIEGPSRIGKTVWARSLGPHNYLCGHLDLSPKVYSNSAWYNVIDDVNPQYLKHFKEFMGAQKDWQSNCKYGKPVRIKGGIPTIFLCNPGEGSSFKLWLDKPEQGALKNWATANAIFCDVQSPFWVQEEVSHSGATAHRGEEGQEESS |
| NCBI Accession | NP_808845.1 |
|---|---|
| Location | 2267-2524 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGGAACCTCACCTCCATGTGTTGGTGCAGTTCGAAGGCAAATTCGTCTGCACAAATAGCAGATTCTTCGATCTGGTCTCACCGAACAGATCGAATCACTTTCACCCCAACATCCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACGTCGATAAGGACGGGGATACCATCACCTGGGGTGAATTCCAGGTCGACGGCAGATCTGCTAGAGGAGGCCAGCAGACTGCTAACGACGCAGCCGCAGAGGCTCTAA |
| Protein Sequence | MGNLTSMCWCSSKANSSAQIADSSIWSHRTDRITFTPTSRELNPAPMSSPTSIRTGIPSPGVNSRSTADLLEEASRLLTTQPQRL |
References More References in PubMed
| 1 |
Andreason SA, et al. Plants (Basel). 2024 May 2;13(9):1267. doi: 10.3390/plants13091267. PMID: 38732482 |
|---|---|
| 2 |
Development of novel detection system for sweet potato leaf curl virus using recombinant scFv. Cho SH, et al. Sci Rep. 2020 May 15;10(1):8039. doi: 10.1038/s41598-020-64996-0. PMID: 32415170 |
| 3 |
First Report of Sweet potato leaf curl virus in Peru. Fuentes S, et al. Plant Dis. 2003 Jan;87(1):98. doi: 10.1094/PDIS.2003.87.1.98C. PMID: 30812710 |
| 4 |
Andreason SA, et al. Plants (Basel). 2021 Jan 12;10(1):139. doi: 10.3390/plants10010139. PMID: 33445460 |
| 5 |
Villalba A, et al. Front Plant Sci. 2024 Mar 18;15:1357611. doi: 10.3389/fpls.2024.1357611. eCollection 2024. PMID: 38562562 |
| 6 |
Virus Incidence of Sweet Potato in Korea from 2011 to 2014. Kim J, et al. Plant Pathol J. 2017 Oct;33(5):467-477. doi: 10.5423/PPJ.OA.08.2016.0167. Epub 2017 Oct 1. PMID: 29018310 |
| 7 |
Bi H, et al. Front Plant Sci. 2017 Sep 27;8:1689. doi: 10.3389/fpls.2017.01689. eCollection 2017. PMID: 29021807 |
| 8 |
Luan YS, et al. Virus Genes. 2007 Oct;35(2):379-85. doi: 10.1007/s11262-007-0084-1. Epub 2007 Feb 21. PMID: 17318425 |
| 9 |
Detection of Sweet potato virus 2 in Sweet Potato in New Zealand. Perez-Egusquiza Z, et al. Plant Dis. 2009 Apr;93(4):427. doi: 10.1094/PDIS-93-4-0427B. PMID: 30764237 |
| 10 |
Choi E, et al. Acta Virol. 2012;56(3):187-98. doi: 10.4149/av_2012_03_187. PMID: 23043598 |