Sweet potato leaf curl Sichuan virus 2
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000912175.1 |
| Isolate |
China |
| Release date |
2015/2/22 |
| Submitter |
Liu,Q.L., Zhang,Z.C., Qiao,Q., Qin,Y.H., Zhang,D.S., Tian,Y.T., Wang,S., Wang,Y.J. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
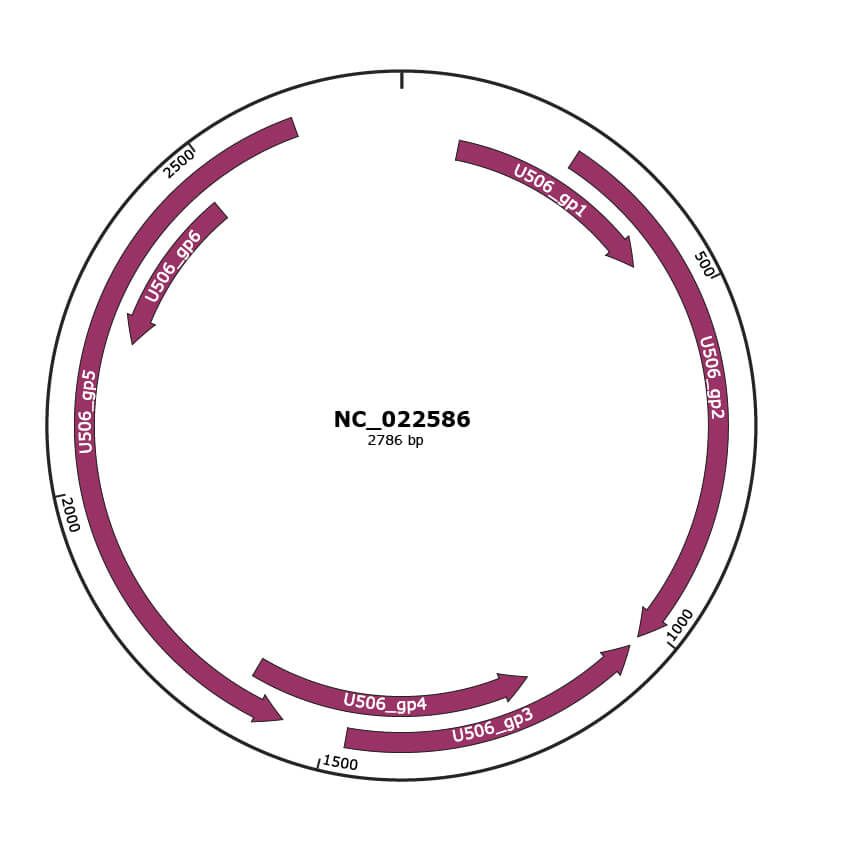
JBrowse
Genome
ACCGGTGCCCGCGCCCCTTTTATTGTGGACCCCACACGCTTTGCTTTAATTATTTAAAGGAGTTTCTGTTGAATACTTTGTCGCCAAGAATGGAGTTGTGGGACCCACTCCAGAACCCTCTCCCAGATACTTTATACGGTTTCCGGTGTATGCTTTCTGTAAAATACCTGCAAGGTATTTTGAAGAAATACGAGCCAGGAACCCTAGGGTTCGAGCTCTGTTCGGAGTTAATCCGTATTTTCAGGGTCAGGCAGTATGACCGGGCGAATTCCCGTTTCGCGGAGATTTCATCCATATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTACGGATGAAGAGAAAGAGGGGTGATCGCATTCCGAAGGGATGCGTTGGACCCTGTAAGGTACAGGACTACGAATTCAAGATGGATGTCCCACACAGTGGGACCTTTGTCTGTGTCTCTGATTTTACTAGGGGTACTGGGCTTACCCATCGTTTGGGTAAGAGGGTGTGCATTAAGTCCATGGGCATTGATGGTAAGGTCTGGATGGATGACAATGTCGCCAAAAGAGACCACACCAACATCATCACTTACTGGTTGATCCGTGATAGAAGGCCCAATAAGGACCCATTAACATTTAGTCAGGCCTTTACTATGTATGATAATGAGCCCACTACTGCTAAGATCCGAATGGATCTGAGAGATAGAATGCAGGTCTTGAAGAAGTTTTCTGTTACAGTTTCAGGAGGTCCATACAGCCACAAGGAGCAGGCATTAATTAGGAAGTTTTTTAAGGGTTTGTATAATCATGTTACTTACAACCACAAGGAAGAAGCTAAGTATGAGAATCAATTAGAGAATGCACTTATGCTGTATAGTGCTAGCAGTCATGCTAGTAATCCTGTGTATCAGACCCTGCGTTGCAGGGTTTATTTCTATGATTCGCACAATAATTAATAAAATTGTTCTTTCATTAATATAGTAGTGTTTTTACATCATCTTTGCAGTCAATTACATCTACTTCTTCTACCCACAAGAACTTGTGAGGTAAATTCCTAATTACATAAACTAAGTTATACAATGAAAAATAACCTAAACTACTTAATTCATTACAAATACACCATTTAAGGCGTGTCAAAATACCAGTCCAACTGTGAATAGCACCAGTCAGACGGGTTGAAATTATCCTGAACTGCAGGAATATCTTGTGGAAGCCCAGTTGCTTCCTCTCGCGGTGGTTCACTTGCAGTTGGAACTTCAGGATTGTTTTCCCCGCTTCGCTCCGGTGGGCGTATAAACACTTGAGGAAAAACGGTGCAGTCCGACCAATTGACATGGGGTTGTCGAAGAATTCGACTGCTCTCGTAGTCTGTGCATGACTTAGTAATTCCCCAGTGCGTGAATCCATTCTGGTACTTGCACTGAGGTGTGATGAAAGCTGAACAGCCGCACTGCTTCCACACTATCCTGGTCCTTTGCTCTGGTATGCGGCGTTTTTTTTTAGCCGCTGCGTGAATTGGCTCCTGAATTGGCGCCTTCCTCTTGTCTCCAGAATGGGCTTCTGACATTACAGAATACTGCGTTCTTACAAGCCCACTGCCTCAGTGCGTCTTGTTCTGTCTTATCTAGCCAGGATTTAAATGATGATCCTTCGCCTGGATTGCAAAGGAAGATAGTGGGAATTCCACCTTTAATTTGAACTGGCTTCCCGTACTTTGTGTTGGATTGCCAGTCCTTCTGGGCCCCAATGAATTCCTTAAAGTGCTTTAGGTATTGGGGGTCGACGTCATCAATGACGTTGTACCAAGCACTATTACTGTACACTCTTGGATTCAGGTCCAAGTGCCCACATAGATAATTATGTGGACCTAAAGACCGAGCCCAAACTGTTTTACCTATCCTACTTGGCCCTTCTATTACAATACTAATGGGCCTATCCGGCCGCGCAGCGGCATCCTTGATGTTATCAGCAGCCCAATTGCTGATAATATCAGGTACATTATTAAAAGAAGAAGATAAAAACGGAGAAGTATAAACTTCTACAGGAGGAGAAAAAATTCTATCTAAATTATTATTAATATTATGGAATTGTAGAACAAAATCTTTTGGGCACAATTCCTTAATAATTTGTAAGGCTTCAGCCTTATTCCCAGCATTTAATGCCTGAGCGTAGGCTTCATTAGCCGTCTGTTGACCGCCTCTAGCAGATCTGCCGTCGATCTGGAACTCACCCCAGGTGAGTGTATCCCCGTCCTTCTCGACGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGGATGTTGGGGTGAAAATGGGCTGACCTTGTTGGGGACACGAGGTCGAAGAATCTTTGATTCGTGCACCTGAATTTCCCCTCGAACTGCACAAGCATGTGGAGGTGAGGTTCCCCATTCTCGTGTAACTCTCTGGCTATATGGATATATTTTTTATTTGTGGGGGTTTGGATATTTAATAATTGCTGTAATGCCTCCTCCTTAGAGAGAGAACATCGGGGATAGGTGAGAAAATAGTTTTTAGAGTTAATCTGGAACTTCTTTGGAGCTGCCATCTGTATTGGTACCCTCTAAAAACCTATGGGTATCGGTACATTGGTACCCATTTATACTTGGGTACCAAATGGCATAATGGTAATTTGATTAACTTTAATTTGAAATTCGAAATCCTATTGGTCCGCCAATAAAGCGGGCACCGTTTAATATT
Gene Information
|
NCBI Accession
|
YP_008691084.1
|
|
Location
|
90-431 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGGAGTTGTGGGACCCACTCCAGAACCCTCTCCCAGATACTTTATACGGTTTCCGGTGTATGCTTTCTGTAAAATACCTGCAAGGTATTTTGAAGAAATACGAGCCAGGAACCCTAGGGTTCGAGCTCTGTTCGGAGTTAATCCGTATTTTCAGGGTCAGGCAGTATGACCGGGCGAATTCCCGTTTCGCGGAGATTTCATCCATATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTACGGATGAAGAGAAAGAGGGGTGA |
|
Protein Sequence
|
MELWDPLQNPLPDTLYGFRCMLSVKYLQGILKKYEPGTLGFELCSELIRIFRVRQYDRANSRFAEISSIWGETGKTEAELRDSYRALHWECCPNCCPKLCPGFKRRTDEEKEG |
|
NCBI Accession
|
YP_008691085.1
|
|
Location
|
256-1020 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGACCGGGCGAATTCCCGTTTCGCGGAGATTTCATCCATATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTACGGATGAAGAGAAAGAGGGGTGATCGCATTCCGAAGGGATGCGTTGGACCCTGTAAGGTACAGGACTACGAATTCAAGATGGATGTCCCACACAGTGGGACCTTTGTCTGTGTCTCTGATTTTACTAGGGGTACTGGGCTTACCCATCGTTTGGGTAAGAGGGTGTGCATTAAGTCCATGGGCATTGATGGTAAGGTCTGGATGGATGACAATGTCGCCAAAAGAGACCACACCAACATCATCACTTACTGGTTGATCCGTGATAGAAGGCCCAATAAGGACCCATTAACATTTAGTCAGGCCTTTACTATGTATGATAATGAGCCCACTACTGCTAAGATCCGAATGGATCTGAGAGATAGAATGCAGGTCTTGAAGAAGTTTTCTGTTACAGTTTCAGGAGGTCCATACAGCCACAAGGAGCAGGCATTAATTAGGAAGTTTTTTAAGGGTTTGTATAATCATGTTACTTACAACCACAAGGAAGAAGCTAAGTATGAGAATCAATTAGAGAATGCACTTATGCTGTATAGTGCTAGCAGTCATGCTAGTAATCCTGTGTATCAGACCCTGCGTTGCAGGGTTTATTTCTATGATTCGCACAATAATTAA |
|
Protein Sequence
|
MTGRIPVSRRFHPYGGRPVRRRLNFETAIVPYTGNAVPIAARSYVPVSRGVRMKRKRGDRIPKGCVGPCKVQDYEFKMDVPHSGTFVCVSDFTRGTGLTHRLGKRVCIKSMGIDGKVWMDDNVAKRDHTNIITYWLIRDRRPNKDPLTFSQAFTMYDNEPTTAKIRMDLRDRMQVLKKFSVTVSGGPYSHKEQALIRKFFKGLYNHVTYNHKEEAKYENQLENALMLYSASSHASNPVYQTLRCRVYFYDSHNN |
|
NCBI Accession
|
YP_008691086.1
|
|
Location
|
1037-1471 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACTGGGGAATTACTAAGTCATGCACAGACTACGAGAGCAGTCGAATTCTTCGACAACCCCATGTCAATTGGTCGGACTGCACCGTTTTTCCTCAAGTGTTTATACGCCCACCGGAGCGAAGCGGGGAAAACAATCCTGAAGTTCCAACTGCAAGTGAACCACCGCGAGAGGAAGCAACTGGGCTTCCACAAGATATTCCTGCAGTTCAGGATAATTTCAACCCGTCTGACTGGTGCTATTCACAGTTGGACTGGTATTTTGACACGCCTTAAATGGTGTATTTGTAATGAATTAAGTAGTTTAGGTTATTTTTCATTGTATAACTTAGTTTATGTAATTAGGAATTTACCTCACAAGTTCTTGTGGGTAGAAGAAGTAGATGTAATTGACTGCAAAGATGATGTAAAAACACTACTATATTAA |
|
Protein Sequence
|
MDSRTGELLSHAQTTRAVEFFDNPMSIGRTAPFFLKCLYAHRSEAGKTILKFQLQVNHRERKQLGFHKIFLQFRIISTRLTGAIHSWTGILTRLKWCICNELSSLGYFSLYNLVYVIRNLPHKFLWVEEVDVIDCKDDVKTLLY |
|
NCBI Accession
|
YP_008691087.1
|
|
Location
|
1188-1631 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGTCAGAAGCCCATTCTGGAGACAAGAGGAAGGCGCCAATTCAGGAGCCAATTCACGCAGCGGCTAAAAAAAAACGCCGCATACCAGAGCAAAGGACCAGGATAGTGTGGAAGCAGTGCGGCTGTTCAGCTTTCATCACACCTCAGTGCAAGTACCAGAATGGATTCACGCACTGGGGAATTACTAAGTCATGCACAGACTACGAGAGCAGTCGAATTCTTCGACAACCCCATGTCAATTGGTCGGACTGCACCGTTTTTCCTCAAGTGTTTATACGCCCACCGGAGCGAAGCGGGGAAAACAATCCTGAAGTTCCAACTGCAAGTGAACCACCGCGAGAGGAAGCAACTGGGCTTCCACAAGATATTCCTGCAGTTCAGGATAATTTCAACCCGTCTGACTGGTGCTATTCACAGTTGGACTGGTATTTTGACACGCCTTAA |
|
Protein Sequence
|
MSEAHSGDKRKAPIQEPIHAAAKKKRRIPEQRTRIVWKQCGCSAFITPQCKYQNGFTHWGITKSCTDYESSRILRQPHVNWSDCTVFPQVFIRPPERSGENNPEVPTASEPPREEATGLPQDIPAVQDNFNPSDWCYSQLDWYFDTP |
|
NCBI Accession
|
YP_008691088.1
|
|
Location
|
1564-2634 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGGCAGCTCCAAAGAAGTTCCAGATTAACTCTAAAAACTATTTTCTCACCTATCCCCGATGTTCTCTCTCTAAGGAGGAGGCATTACAGCAATTATTAAATATCCAAACCCCCACAAATAAAAAATATATCCATATAGCCAGAGAGTTACACGAGAATGGGGAACCTCACCTCCACATGCTTGTGCAGTTCGAGGGGAAATTCAGGTGCACGAATCAAAGATTCTTCGACCTCGTGTCCCCAACAAGGTCAGCCCATTTTCACCCCAACATCCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAGGACGGGGATACACTCACCTGGGGTGAGTTCCAGATCGACGGCAGATCTGCTAGAGGCGGTCAACAGACGGCTAATGAAGCCTACGCTCAGGCATTAAATGCTGGGAATAAGGCTGAAGCCTTACAAATTATTAAGGAATTGTGCCCAAAAGATTTTGTTCTACAATTCCATAATATTAATAATAATTTAGATAGAATTTTTTCTCCTCCTGTAGAAGTTTATACTTCTCCGTTTTTATCTTCTTCTTTTAATAATGTACCTGATATTATCAGCAATTGGGCTGCTGATAACATCAAGGATGCCGCTGCGCGGCCGGATAGGCCCATTAGTATTGTAATAGAAGGGCCAAGTAGGATAGGTAAAACAGTTTGGGCTCGGTCTTTAGGTCCACATAATTATCTATGTGGGCACTTGGACCTGAATCCAAGAGTGTACAGTAATAGTGCTTGGTACAACGTCATTGATGACGTCGACCCCCAATACCTAAAGCACTTTAAGGAATTCATTGGGGCCCAGAAGGACTGGCAATCCAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGTGGAATTCCCACTATCTTCCTTTGCAATCCAGGCGAAGGATCATCATTTAAATCCTGGCTAGATAAGACAGAACAAGACGCACTGAGGCAGTGGGCTTGTAAGAACGCAGTATTCTGTAATGTCAGAAGCCCATTCTGGAGACAAGAGGAAGGCGCCAATTCAGGAGCCAATTCACGCAGCGGCTAA |
|
Protein Sequence
|
MAAPKKFQINSKNYFLTYPRCSLSKEEALQQLLNIQTPTNKKYIHIARELHENGEPHLHMLVQFEGKFRCTNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYVEKDGDTLTWGEFQIDGRSARGGQQTANEAYAQALNAGNKAEALQIIKELCPKDFVLQFHNINNNLDRIFSPPVEVYTSPFLSSSFNNVPDIISNWAADNIKDAAARPDRPISIVIEGPSRIGKTVWARSLGPHNYLCGHLDLNPRVYSNSAWYNVIDDVDPQYLKHFKEFIGAQKDWQSNTKYGKPVQIKGGIPTIFLCNPGEGSSFKSWLDKTEQDALRQWACKNAVFCNVRSPFWRQEEGANSGANSRSG |
|
NCBI Accession
|
YP_008691089.1
|
|
Location
|
2220-2477 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAACCTCACCTCCACATGCTTGTGCAGTTCGAGGGGAAATTCAGGTGCACGAATCAAAGATTCTTCGACCTCGTGTCCCCAACAAGGTCAGCCCATTTTCACCCCAACATCCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAGGACGGGGATACACTCACCTGGGGTGAGTTCCAGATCGACGGCAGATCTGCTAGAGGCGGTCAACAGACGGCTAATGAAGCCTACGCTCAGGCATTAA |
|
Protein Sequence
|
MGNLTSTCLCSSRGNSGARIKDSSTSCPQQGQPIFTPTSRELNPAPTSSPTSRRTGIHSPGVSSRSTADLLEAVNRRLMKPTLRH |