Sweet potato leaf curl Sichuan virus 1
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002823585.1 |
| Isolate |
China: Sichuan |
| Release date |
2018/8/25 |
| Submitter |
Liu,Q., Zhang,Z., Qiao,Q., Qin,Y., Zhang,D., Tian,Y., Wang,S., Wang,Y., Liu,Q.L., Zhang,Z.C., Qin,Y.H., Zhang,D.S., Tian,Y.T., Wang,Y.J. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
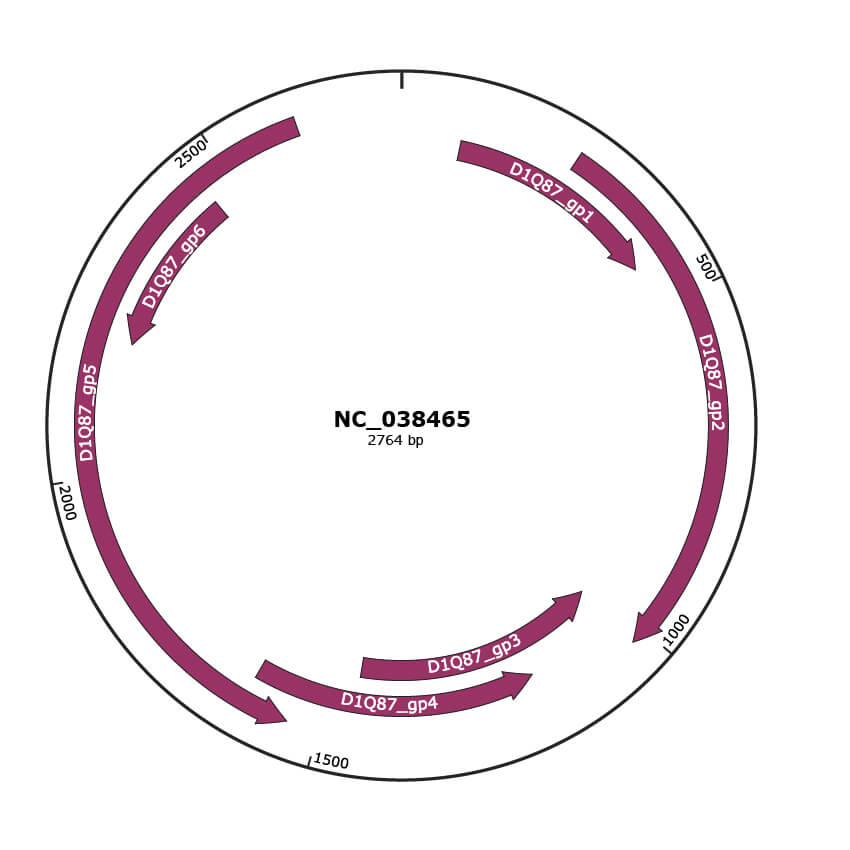
JBrowse
Genome
ACCGGTGCCCGCGCAAATTTTTAATGTGGGCCCCACGCGCTTTGCTTTAATCATTAAAAGCAGCGTCTTGTAGCATTCTTTGTCGCCAAGGATGGATTTGTGGGACCCACTGCAGAACCCTCTCCCTGATACTTTATACGGTTTTCGTTGTATGCTTTCTGTAAAATACCTGCAAGGTATTTTGAAGAAATACGAGCCAGGAACCTTAGGGTTCGAGCTCTGTTCGGAGCTAATCCGTATATTCAGAGTCAGGCAGTATGACAGGGCGAATTCCCGTTTCGCGGAGATTTCATCCCTATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCAGATGAAGAGAAGGAAGGGTGACCGCATCCCGAAGGGATGTGTGGGTCCTTGTAAGGTCCAGGACTATGAGTTCAAGATGGACGTTCCCCACACGGGAACGTTTGTCTGTGTCTCGGATTTTACAAGGGGAACTGGGCTTACCCATCGTTTGGGTAAGAGGGTGTGTATTAAGTCCATGGGTATTGACGGTAAAGTCTGGATGGACGACAACGTCGCCAAGAGAGACCATACCAACATTATTACTTACTGGTTGATTCGAGATAGGAGGCCCAATAAGGACCCATTGACGTTTGCACAGGCCTTTACTATGTATGATAATGAACCCACTACTGCTAAGATCCGTATGGATCTGAGAGATAGAATGCAGGTCTTGAAGAAATTCTCTGTTACTGTGTCTGGTGGGCCTTATAGCCACAAGGAGCAGGCGTTAGTTAGGAAGTTTTTTAAGAGTTTGTATAATCATGTTACTTATAATCATAAGGAAGAAGCTAAGTATGAAAATCATTTAGAAAATGCATTAATGTTGTATTCTGCTAGCAGTCATGCTAGCAATCCTGTATATCAGACCCTGCGTTGCAGGGCTTATTTCTATGATTCGCACAATAATTAATAAAGAAGTACTTTTATATCATCTTTGCAATCTATTACATCGACTTCTTCTACCCACAAGAACTCTTGTGGTAAATGTCTAATTACATAAACTAAGTTATACAATGAAAAATAACCTAAACTACTTAATTCATTACAAATACGCCATTTAAGGCGTGTCAAAATACCAGTCCAACTGTGAATAGCACCAGTCAGACGGGTTGAAATTATCCTGAACTGCAGGAATATCTTGTGGAAGCCCAGTTGCTTCATCTCGCGGTGGTTCACTTGCAGTTGGAACTTCATGATTGTTTTCCCCGCTTCGCTCCGGTGGGCGTATAAACACTTGAGGAAAAACGGTGCAGTCCGACCAATTGACATGGGGTTGTCGAAGAATTCGACTGCTCTCGTAGTCTGTGCATGACTTAGTAATTCCCCAGTGCGTGAATCCATTCTGGTACTTGCACTGAGGTGTGATGAAAGCTGAACAGCCGCACTGCTTCCACACTATCCTGGTCCTTTGCTCTGGTATGCGGCGTTTTTTTTTAGCCGCTGCGTGAATTGGCTCCTGAATTGGCGCCTTCCTCTTGTCTCCAGAATGGGCTTCTGACATTACAGAATACTGCGTTCTTGCAAGCCCACTGCCTCAGTGCGTCTTGTTCTGGCTTATCTAGCCAGGATTTAAATGATGATCCTTCGCCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAACTGGCTTCCCGTACTTTGTGTTTGATGGCCAGTCCCTCTGGGCCCCAATGAATTCCTTAAAGTGCTTTAGGTATTGGGGGTCGACGTCATCAATGACGTTGTACCACGCACTGTTACTGTACACTTTAGGGCTTAGATCTAAATGCCCACACAAATAATTGTGAGGACCCAAAGACCTGGCCCATACTGTTTTGCCTATTCTGCTTGGGCCTTCTATAACAATGGATATGGGTCTATCCGGCCGCGCAGCGGAATCCATGACATTTTCAGCGGCCCAATTGCTGATAATGTCAGGAACGGCATTAAAAGAAGAAGAAGAAAAAGGTGAAGAATATACAGAAGGAGGAGGAGAAAAAATCCTATCTAAATTATTATTAATATTATGGAATTGAAGAACAAAGTCTTTTGGACACAATTCCTTTATTATCTGTAACGCTTCAGATTTACACCCAGTATTTAATGCCTGGGCGTAAGCATCGTTAGCCGTTTGCTGACCTCCTCTAGCACTTCTTCCGTCGACCTGGAAGACTCCACTGTCAACAAAATCTTGGTCCTTCTCAATGTAGGCCTTGACATCGGACGAGGACTTTGCTGATTGGAAATTGGGGTGGTATTGTGTAGAGGAGTTGGGGTGAGTAAGGTCGAAGTGCCTGGGGTTTGTGAATTGGCACTTACCTTTGAATTGGATGAGAGCATGGAGGTGCAGGCTCCCATCCTGGTGTTTCTCTTGAGCAACTCGGATAAATAATTTATCAGAAGGGCATTGAATGCCCTTTAATAACTCAAGGACTGATTCTTTAGATAGGGGGCATTTTGGGTAAGTGAGGAATATATTTTTGGCTTGAAGTCTAAAGCCGGGTGCTCTCACCATGTTGACTTGGTCAATTGGAGTAACACCTTCCTGCCATGCAATTGGAGTAATGGAGTAGAATATATAGTGGTTGGATTTTCAGACCTCCATTTTGAAATTCAAATTCCGACAACTTTGGGCCCACAAAAGCGGGCACCGTATTAATATT
Gene Information
|
NCBI Accession
|
YP_009506501.1
|
|
Location
|
92-433 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGGATTTGTGGGACCCACTGCAGAACCCTCTCCCTGATACTTTATACGGTTTTCGTTGTATGCTTTCTGTAAAATACCTGCAAGGTATTTTGAAGAAATACGAGCCAGGAACCTTAGGGTTCGAGCTCTGTTCGGAGCTAATCCGTATATTCAGAGTCAGGCAGTATGACAGGGCGAATTCCCGTTTCGCGGAGATTTCATCCCTATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCAGATGAAGAGAAGGAAGGGTGA |
|
Protein Sequence
|
MDLWDPLQNPLPDTLYGFRCMLSVKYLQGILKKYEPGTLGFELCSELIRIFRVRQYDRANSRFAEISSLWGETGKTEAELRDSYRALHWECCPNCCPKLCPGFKRRPDEEKEG |
|
NCBI Accession
|
YP_009506502.1
|
|
Location
|
258-1022 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGACAGGGCGAATTCCCGTTTCGCGGAGATTTCATCCCTATGGGGGGAGACCGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCCTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCAGATGAAGAGAAGGAAGGGTGACCGCATCCCGAAGGGATGTGTGGGTCCTTGTAAGGTCCAGGACTATGAGTTCAAGATGGACGTTCCCCACACGGGAACGTTTGTCTGTGTCTCGGATTTTACAAGGGGAACTGGGCTTACCCATCGTTTGGGTAAGAGGGTGTGTATTAAGTCCATGGGTATTGACGGTAAAGTCTGGATGGACGACAACGTCGCCAAGAGAGACCATACCAACATTATTACTTACTGGTTGATTCGAGATAGGAGGCCCAATAAGGACCCATTGACGTTTGCACAGGCCTTTACTATGTATGATAATGAACCCACTACTGCTAAGATCCGTATGGATCTGAGAGATAGAATGCAGGTCTTGAAGAAATTCTCTGTTACTGTGTCTGGTGGGCCTTATAGCCACAAGGAGCAGGCGTTAGTTAGGAAGTTTTTTAAGAGTTTGTATAATCATGTTACTTATAATCATAAGGAAGAAGCTAAGTATGAAAATCATTTAGAAAATGCATTAATGTTGTATTCTGCTAGCAGTCATGCTAGCAATCCTGTATATCAGACCCTGCGTTGCAGGGCTTATTTCTATGATTCGCACAATAATTAA |
|
Protein Sequence
|
MTGRIPVSRRFHPYGGRPVRRRLNFETAIVPYTGNAVPIAARSYVPVSRGVQMKRRKGDRIPKGCVGPCKVQDYEFKMDVPHTGTFVCVSDFTRGTGLTHRLGKRVCIKSMGIDGKVWMDDNVAKRDHTNIITYWLIRDRRPNKDPLTFAQAFTMYDNEPTTAKIRMDLRDRMQVLKKFSVTVSGGPYSHKEQALVRKFFKSLYNHVTYNHKEEAKYENHLENALMLYSASSHASNPVYQTLRCRAYFYDSHNN |
|
NCBI Accession
|
YP_009506503.1
|
|
Location
|
1019-1453 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACTGGGGAATTACTAAGTCATGCACAGACTACGAGAGCAGTCGAATTCTTCGACAACCCCATGTCAATTGGTCGGACTGCACCGTTTTTCCTCAAGTGTTTATACGCCCACCGGAGCGAAGCGGGGAAAACAATCATGAAGTTCCAACTGCAAGTGAACCACCGCGAGATGAAGCAACTGGGCTTCCACAAGATATTCCTGCAGTTCAGGATAATTTCAACCCGTCTGACTGGTGCTATTCACAGTTGGACTGGTATTTTGACACGCCTTAAATGGCGTATTTGTAATGAATTAAGTAGTTTAGGTTATTTTTCATTGTATAACTTAGTTTATGTAATTAGACATTTACCACAAGAGTTCTTGTGGGTAGAAGAAGTCGATGTAATAGATTGCAAAGATGATATAAAAGTACTTCTTTATTAA |
|
Protein Sequence
|
MDSRTGELLSHAQTTRAVEFFDNPMSIGRTAPFFLKCLYAHRSEAGKTIMKFQLQVNHREMKQLGFHKIFLQFRIISTRLTGAIHSWTGILTRLKWRICNELSSLGYFSLYNLVYVIRHLPQEFLWVEEVDVIDCKDDIKVLLY |
|
NCBI Accession
|
YP_009506504.1
|
|
Location
|
1170-1613 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGTCAGAAGCCCATTCTGGAGACAAGAGGAAGGCGCCAATTCAGGAGCCAATTCACGCAGCGGCTAAAAAAAAACGCCGCATACCAGAGCAAAGGACCAGGATAGTGTGGAAGCAGTGCGGCTGTTCAGCTTTCATCACACCTCAGTGCAAGTACCAGAATGGATTCACGCACTGGGGAATTACTAAGTCATGCACAGACTACGAGAGCAGTCGAATTCTTCGACAACCCCATGTCAATTGGTCGGACTGCACCGTTTTTCCTCAAGTGTTTATACGCCCACCGGAGCGAAGCGGGGAAAACAATCATGAAGTTCCAACTGCAAGTGAACCACCGCGAGATGAAGCAACTGGGCTTCCACAAGATATTCCTGCAGTTCAGGATAATTTCAACCCGTCTGACTGGTGCTATTCACAGTTGGACTGGTATTTTGACACGCCTTAA |
|
Protein Sequence
|
MSEAHSGDKRKAPIQEPIHAAAKKKRRIPEQRTRIVWKQCGCSAFITPQCKYQNGFTHWGITKSCTDYESSRILRQPHVNWSDCTVFPQVFIRPPERSGENNHEVPTASEPPRDEATGLPQDIPAVQDNFNPSDWCYSQLDWYFDTP |
|
NCBI Accession
|
YP_009506505.1
|
|
Location
|
1546-2616 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGGTGAGAGCACCCGGCTTTAGACTTCAAGCCAAAAATATATTCCTCACTTACCCAAAATGCCCCCTATCTAAAGAATCAGTCCTTGAGTTATTAAAGGGCATTCAATGCCCTTCTGATAAATTATTTATCCGAGTTGCTCAAGAGAAACACCAGGATGGGAGCCTGCACCTCCATGCTCTCATCCAATTCAAAGGTAAGTGCCAATTCACAAACCCCAGGCACTTCGACCTTACTCACCCCAACTCCTCTACACAATACCACCCCAATTTCCAATCAGCAAAGTCCTCGTCCGATGTCAAGGCCTACATTGAGAAGGACCAAGATTTTGTTGACAGTGGAGTCTTCCAGGTCGACGGAAGAAGTGCTAGAGGAGGTCAGCAAACGGCTAACGATGCTTACGCCCAGGCATTAAATACTGGGTGTAAATCTGAAGCGTTACAGATAATAAAGGAATTGTGTCCAAAAGACTTTGTTCTTCAATTCCATAATATTAATAATAATTTAGATAGGATTTTTTCTCCTCCTCCTTCTGTATATTCTTCACCTTTTTCTTCTTCTTCTTTTAATGCCGTTCCTGACATTATCAGCAATTGGGCCGCTGAAAATGTCATGGATTCCGCTGCGCGGCCGGATAGACCCATATCCATTGTTATAGAAGGCCCAAGCAGAATAGGCAAAACAGTATGGGCCAGGTCTTTGGGTCCTCACAATTATTTGTGTGGGCATTTAGATCTAAGCCCTAAAGTGTACAGTAACAGTGCGTGGTACAACGTCATTGATGACGTCGACCCCCAATACCTAAAGCACTTTAAGGAATTCATTGGGGCCCAGAGGGACTGGCCATCAAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGCGAAGGATCATCATTTAAATCCTGGCTAGATAAGCCAGAACAAGACGCACTGAGGCAGTGGGCTTGCAAGAACGCAGTATTCTGTAATGTCAGAAGCCCATTCTGGAGACAAGAGGAAGGCGCCAATTCAGGAGCCAATTCACGCAGCGGCTAA |
|
Protein Sequence
|
MVRAPGFRLQAKNIFLTYPKCPLSKESVLELLKGIQCPSDKLFIRVAQEKHQDGSLHLHALIQFKGKCQFTNPRHFDLTHPNSSTQYHPNFQSAKSSSDVKAYIEKDQDFVDSGVFQVDGRSARGGQQTANDAYAQALNTGCKSEALQIIKELCPKDFVLQFHNINNNLDRIFSPPPSVYSSPFSSSSFNAVPDIISNWAAENVMDSAARPDRPISIVIEGPSRIGKTVWARSLGPHNYLCGHLDLSPKVYSNSAWYNVIDDVDPQYLKHFKEFIGAQRDWPSNTKYGKPVQIKGGIPTIFLCNPGEGSSFKSWLDKPEQDALRQWACKNAVFCNVRSPFWRQEEGANSGANSRSG |
|
NCBI Accession
|
YP_009506506.1
|
|
Location
|
2202-2459 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGAGCCTGCACCTCCATGCTCTCATCCAATTCAAAGGTAAGTGCCAATTCACAAACCCCAGGCACTTCGACCTTACTCACCCCAACTCCTCTACACAATACCACCCCAATTTCCAATCAGCAAAGTCCTCGTCCGATGTCAAGGCCTACATTGAGAAGGACCAAGATTTTGTTGACAGTGGAGTCTTCCAGGTCGACGGAAGAAGTGCTAGAGGAGGTCAGCAAACGGCTAACGATGCTTACGCCCAGGCATTAA |
|
Protein Sequence
|
MGACTSMLSSNSKVSANSQTPGTSTLLTPTPLHNTTPISNQQSPRPMSRPTLRRTKILLTVESSRSTEEVLEEVSKRLTMLTPRH |