Sweet potato leaf curl Canary virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000884435.1 |
| Isolate | Spain |
| Release date | 2015/2/22 |
| Submitter | Lozano,G., Trenado,H.P., Valverde,R.A., Navas-Castillo,J. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
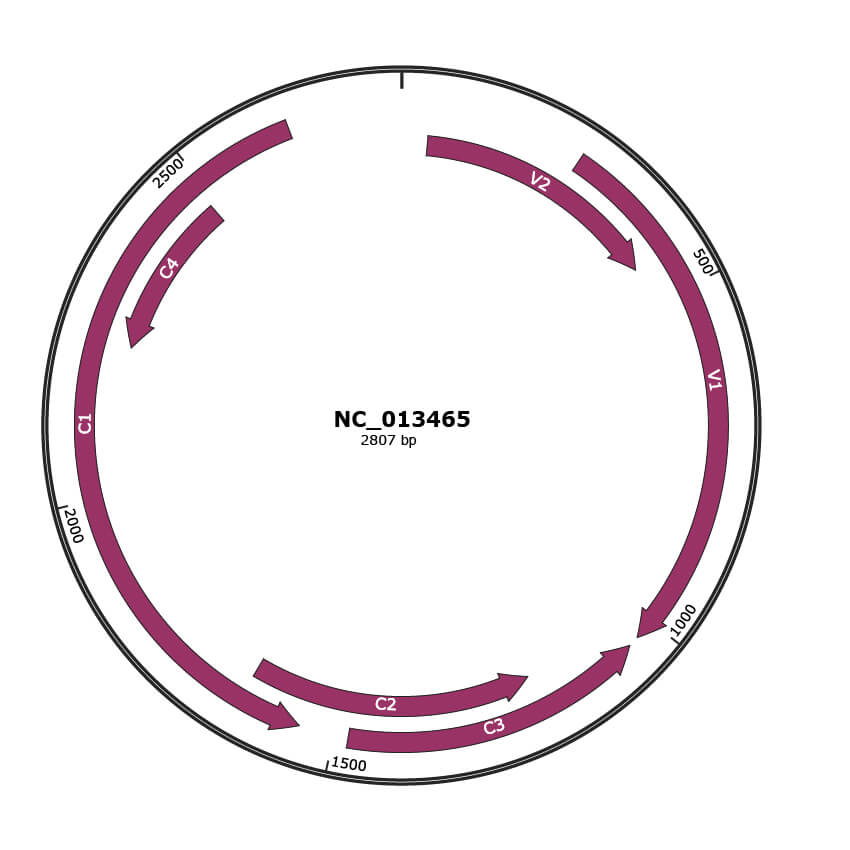
JBrowse
Genome
NC_013465
ACCGGTGCCCGCCGCGCCCCCTTTTGTGGGCCCCACAAAGAATGATGACATTGCTTTATAAGGACCAATCAGGTTGCCGTGCTTGGCGCCCAAGTATGGCTGAAATGTGGGACCCTCTTCAGAACCCACTACCAGATACTTTATACGGTTTCAGGTGTATGCTTTCCGTTAAATACCTACAAGGTATTTTGAAGAAATACGAGCCAGGAACCCTAGGGTTCGAGCTCTGTTCGGAGTTAATCCGTATATTCAGGGTCAGGCAGTATGACAGGGCGAATTCGCGTTTCGCCGAGATATCATCCCTATGGGGGGAGACAGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCTTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCGGATGAAGAGAAGGAGGGGTGACCGCATCCCTAAGGGATGTGTTGGTCCCTGTAAGATCCAGGACTATGAGTTCAAAATGGACGTTCCCCACACGGGAACGTTTGTCTGTGTCTCGGATTTTACAAGGGGTACAGGGCTTACCCATCGCCTGGGTAAGCGTGTTTGTATTAAGTCCATGGGTATAGATGGGAAGGTATGGATGGATGACAATGTGGCTAAGAGAGATCACACCAATATCATCACGTATTGGTTGATTCGTGATAGAAGGCCCAATAAGGATCCGCTGAACTTTGGCCAGATCTTCACTATGTACGACAATGAGCCCACTACTGCTAAGATCCGAATGGATCTGAGGGATAGAATGCAAGTCTTGAAGAAGTTCTCTGTTACAGTTTCAGGAGGTCCATACAGCCACAAGGAACAGGCATTAATTAGGAAGTTTTTTAAGGGTTTGTATAATCATGTTACTTATAATCATAAGGAAGAAGCTAAGTATGAGAATCAGTTAGAGAATGCTTTGATGTTGTATAGTGCTAGCAGTCATGCTAGCAATCCTGTGTATCAGACCCTGCGTTGCAGGGCTTATTTCTATGATTCGCACAATAATTAATAAACTTTTATTTTATTAATACATTAATACCTTTACATCATCATTGCAGTCTACATTATCTATTTCATCTATCCAAGAACATACTCTTGGAAGATATCTAATAACAAAAACTAAATTAACTAAACTAAAAAAACCCAAATTTGCTATTTCATTACATATGCGCCATTTAAGGCGTTCCAAAATACCAGTCCAACTGTGAATAGCACCAGTTAGACGGGTCGTCAAGATCCGGAATTGGAGGAATATCTTGTGGAATCCCAGTTGCCTCCTTTCCCTGTAGTTGACTCTCAGCTGGAATTTGAGGATGGTTCTCCCCTGTGTGCTCTCGTGGACATACATAATTCTGAGATGGAATGGTGCAGTCCGACCCACAGACATGGGGTTGGTGTCGAATTCGACTGCTCTCGTAGTCTGAGCATGACTTAGTGATTCCCCTGTGCGTGAATCCATGCTGGTACTTGCAGGTTGTGGTGATGAAGGCTGAACAGCCGCAACCCTTCCACACTATCCTTGTCCTTGGTTCAGGAGCTTTCCTCTTGGCCTTCTTCGCTGCTGCGTGTGATGGCTCCTGCTCCGGACACTTCCTCTTGTACCCAGAAAGGGGATTGGACATCGCAGAATATTGCGTTCTTTAATGCCCAATTCTTTAGAGCTTCTTGTTCTGGTTTATCTAACCAGAGTTTAAATGAAGAGCCCTCTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAACTGGCTTCCCGTATTTACAGTTTGATTGCCAGTCCTTCTGGGCCCCCATGAATTCCTTAAAGTGCTTTAGGTATTGGGGGTTGACGTCATCAATGACGTTATACCAAGCACTGTTGCTGTATACTTTTGGGCTTAGATCTAAATGCCCACACAAATAATTGTGAGGGCCCAAAGACCTGGCCCACACTGTTTTGCCTATTCTGCTTGGGCCTTCAATAACAATTGATATAGGTCTATCCGGCCGCGCAGCGGAATCCATGACATTTTCAGCGGCCCAATCGCTGATAATGTCAGGAACATTATTGAAAGAAGAAGAAGAAAAAGGGGAACAATATACAGCAGGAGGAGGAGAAAAAATCCTATCTAAATTTGAAACTAAATTATGATATTGAAAAATATATTTTTCAGGGAGTTTCTCCCTTATTATTTGTAACGCAGCTTCTTTAGAACCTGCGTTTAATGCCTCTGCGGCAGCGTCGTTAGCAGTCTGCTGACCTCCTCTAGCAGATCTGCCGTCGATCTGGAATTCACCCCAGTCGAGGTAGTCTCCGTCCTTCTCGATGTATGACTTGACATCCGAGGAGGACTTAGCTGCCTGGAAATTTGGATGGAATTGGGAGGAGTTATGTGGATGATGTAGGTCGAAATGTCGTGGGTTTTTGAACTCTGCTTTCCCCTTGAACTGGATGAGAACATGGAGATGCAATGACCCATCTTGGTGTTTCTCTTGGCTAACTCTGATAAACAGTTTATCCGACGGGCAATGGGTGGCCCTTAATTGCTCAAGCGCTTGCTCTTTAGATAAAGAACATTTGGGGTATGTTAAGAAAATATTTTTGGCTTGGACTCTAAACCCTTGCTTACGTGGCATTTTGAATCGGAGGCTCTCAAAGCTCTACGGAATTGGAGGATTTGGAGGACTATATATAGTGAGCCTCCAAATGACATTTTGGTAATTTAGAAGATCCTTTTACCTTTAATTCAAATTCCGACATGTCTGGGACCACCAAAAGGCGGGCACCGTATTAATATT
Gene Information
| NCBI Accession | YP_003288769.1 |
|---|---|
| Location | 42-440 |
| Gene Name | V2 |
| Protein Name | MP |
| Coding Region | ATGATGACATTGCTTTATAAGGACCAATCAGGTTGCCGTGCTTGGCGCCCAAGTATGGCTGAAATGTGGGACCCTCTTCAGAACCCACTACCAGATACTTTATACGGTTTCAGGTGTATGCTTTCCGTTAAATACCTACAAGGTATTTTGAAGAAATACGAGCCAGGAACCCTAGGGTTCGAGCTCTGTTCGGAGTTAATCCGTATATTCAGGGTCAGGCAGTATGACAGGGCGAATTCGCGTTTCGCCGAGATATCATCCCTATGGGGGGAGACAGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCTTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCGGATGAAGAGAAGGAGGGGTGA |
| Protein Sequence | MMTLLYKDQSGCRAWRPSMAEMWDPLQNPLPDTLYGFRCMLSVKYLQGILKKYEPGTLGFELCSELIRIFRVRQYDRANSRFAEISSLWGETGKTEAELRDSYRALHWECCPNCCPKLCPGFKRRPDEEKEG |
| NCBI Accession | YP_003288770.1 |
|---|---|
| Location | 265-1029 |
| Gene Name | V1 |
| Protein Name | CP |
| Coding Region | ATGACAGGGCGAATTCGCGTTTCGCCGAGATATCATCCCTATGGGGGGAGACAGGTAAGACGGAGGCTGAACTTCGAGACAGCTATCGTGCCTTACACTGGGAATGCTGTCCCAATTGCTGCCCGAAGCTATGTCCCGGTTTCAAGAGGCGTCCGGATGAAGAGAAGGAGGGGTGACCGCATCCCTAAGGGATGTGTTGGTCCCTGTAAGATCCAGGACTATGAGTTCAAAATGGACGTTCCCCACACGGGAACGTTTGTCTGTGTCTCGGATTTTACAAGGGGTACAGGGCTTACCCATCGCCTGGGTAAGCGTGTTTGTATTAAGTCCATGGGTATAGATGGGAAGGTATGGATGGATGACAATGTGGCTAAGAGAGATCACACCAATATCATCACGTATTGGTTGATTCGTGATAGAAGGCCCAATAAGGATCCGCTGAACTTTGGCCAGATCTTCACTATGTACGACAATGAGCCCACTACTGCTAAGATCCGAATGGATCTGAGGGATAGAATGCAAGTCTTGAAGAAGTTCTCTGTTACAGTTTCAGGAGGTCCATACAGCCACAAGGAACAGGCATTAATTAGGAAGTTTTTTAAGGGTTTGTATAATCATGTTACTTATAATCATAAGGAAGAAGCTAAGTATGAGAATCAGTTAGAGAATGCTTTGATGTTGTATAGTGCTAGCAGTCATGCTAGCAATCCTGTGTATCAGACCCTGCGTTGCAGGGCTTATTTCTATGATTCGCACAATAATTAA |
| Protein Sequence | MTGRIRVSPRYHPYGGRQVRRRLNFETAIVPYTGNAVPIAARSYVPVSRGVRMKRRRGDRIPKGCVGPCKIQDYEFKMDVPHTGTFVCVSDFTRGTGLTHRLGKRVCIKSMGIDGKVWMDDNVAKRDHTNIITYWLIRDRRPNKDPLNFGQIFTMYDNEPTTAKIRMDLRDRMQVLKKFSVTVSGGPYSHKEQALIRKFFKGLYNHVTYNHKEEAKYENQLENALMLYSASSHASNPVYQTLRCRAYFYDSHNN |
| NCBI Accession | YP_003288771.1 |
|---|---|
| Location | 1045-1479 |
| Gene Name | C3 |
| Protein Name | C3 |
| Coding Region | ATGGATTCACGCACAGGGGAATCACTAAGTCATGCTCAGACTACGAGAGCAGTCGAATTCGACACCAACCCCATGTCTGTGGGTCGGACTGCACCATTCCATCTCAGAATTATGTATGTCCACGAGAGCACACAGGGGAGAACCATCCTCAAATTCCAGCTGAGAGTCAACTACAGGGAAAGGAGGCAACTGGGATTCCACAAGATATTCCTCCAATTCCGGATCTTGACGACCCGTCTAACTGGTGCTATTCACAGTTGGACTGGTATTTTGGAACGCCTTAAATGGCGCATATGTAATGAAATAGCAAATTTGGGTTTTTTTAGTTTAGTTAATTTAGTTTTTGTTATTAGATATCTTCCAAGAGTATGTTCTTGGATAGATGAAATAGATAATGTAGACTGCAATGATGATGTAAAGGTATTAATGTATTAA |
| Protein Sequence | MDSRTGESLSHAQTTRAVEFDTNPMSVGRTAPFHLRIMYVHESTQGRTILKFQLRVNYRERRQLGFHKIFLQFRILTTRLTGAIHSWTGILERLKWRICNEIANLGFFSLVNLVFVIRYLPRVCSWIDEIDNVDCNDDVKVLMY |
| NCBI Accession | YP_003288772.1 |
|---|---|
| Location | 1196-1642 |
| Gene Name | C2 |
| Protein Name | C2 |
| Coding Region | ATGTCCAATCCCCTTTCTGGGTACAAGAGGAAGTGTCCGGAGCAGGAGCCATCACACGCAGCAGCGAAGAAGGCCAAGAGGAAAGCTCCTGAACCAAGGACAAGGATAGTGTGGAAGGGTTGCGGCTGTTCAGCCTTCATCACCACAACCTGCAAGTACCAGCATGGATTCACGCACAGGGGAATCACTAAGTCATGCTCAGACTACGAGAGCAGTCGAATTCGACACCAACCCCATGTCTGTGGGTCGGACTGCACCATTCCATCTCAGAATTATGTATGTCCACGAGAGCACACAGGGGAGAACCATCCTCAAATTCCAGCTGAGAGTCAACTACAGGGAAAGGAGGCAACTGGGATTCCACAAGATATTCCTCCAATTCCGGATCTTGACGACCCGTCTAACTGGTGCTATTCACAGTTGGACTGGTATTTTGGAACGCCTTAA |
| Protein Sequence | MSNPLSGYKRKCPEQEPSHAAAKKAKRKAPEPRTRIVWKGCGCSAFITTTCKYQHGFTHRGITKSCSDYESSRIRHQPHVCGSDCTIPSQNYVCPREHTGENHPQIPAESQLQGKEATGIPQDIPPIPDLDDPSNWCYSQLDWYFGTP |
| NCBI Accession | YP_003288773.1 |
|---|---|
| Location | 1551-2645 |
| Gene Name | C1 |
| Protein Name | REP |
| Coding Region | ATGCCACGTAAGCAAGGGTTTAGAGTCCAAGCCAAAAATATTTTCTTAACATACCCCAAATGTTCTTTATCTAAAGAGCAAGCGCTTGAGCAATTAAGGGCCACCCATTGCCCGTCGGATAAACTGTTTATCAGAGTTAGCCAAGAGAAACACCAAGATGGGTCATTGCATCTCCATGTTCTCATCCAGTTCAAGGGGAAAGCAGAGTTCAAAAACCCACGACATTTCGACCTACATCATCCACATAACTCCTCCCAATTCCATCCAAATTTCCAGGCAGCTAAGTCCTCCTCGGATGTCAAGTCATACATCGAGAAGGACGGAGACTACCTCGACTGGGGTGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGTCAGCAGACTGCTAACGACGCTGCCGCAGAGGCATTAAACGCAGGTTCTAAAGAAGCTGCGTTACAAATAATAAGGGAGAAACTCCCTGAAAAATATATTTTTCAATATCATAATTTAGTTTCAAATTTAGATAGGATTTTTTCTCCTCCTCCTGCTGTATATTGTTCCCCTTTTTCTTCTTCTTCTTTCAATAATGTTCCTGACATTATCAGCGATTGGGCCGCTGAAAATGTCATGGATTCCGCTGCGCGGCCGGATAGACCTATATCAATTGTTATTGAAGGCCCAAGCAGAATAGGCAAAACAGTGTGGGCCAGGTCTTTGGGCCCTCACAATTATTTGTGTGGGCATTTAGATCTAAGCCCAAAAGTATACAGCAACAGTGCTTGGTATAACGTCATTGATGACGTCAACCCCCAATACCTAAAGCACTTTAAGGAATTCATGGGGGCCCAGAAGGACTGGCAATCAAACTGTAAATACGGGAAGCCAGTTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGAGAGGGCTCTTCATTTAAACTCTGGTTAGATAAACCAGAACAAGAAGCTCTAAAGAATTGGGCATTAAAGAACGCAATATTCTGCGATGTCCAATCCCCTTTCTGGGTACAAGAGGAAGTGTCCGGAGCAGGAGCCATCACACGCAGCAGCGAAGAAGGCCAAGAGGAAAGCTCCTGA |
| Protein Sequence | MPRKQGFRVQAKNIFLTYPKCSLSKEQALEQLRATHCPSDKLFIRVSQEKHQDGSLHLHVLIQFKGKAEFKNPRHFDLHHPHNSSQFHPNFQAAKSSSDVKSYIEKDGDYLDWGEFQIDGRSARGGQQTANDAAAEALNAGSKEAALQIIREKLPEKYIFQYHNLVSNLDRIFSPPPAVYCSPFSSSSFNNVPDIISDWAAENVMDSAARPDRPISIVIEGPSRIGKTVWARSLGPHNYLCGHLDLSPKVYSNSAWYNVIDDVNPQYLKHFKEFMGAQKDWQSNCKYGKPVQIKGGIPTIFLCNPGEGSSFKLWLDKPEQEALKNWALKNAIFCDVQSPFWVQEEVSGAGAITRSSEEGQEESS |
| NCBI Accession | YP_003288774.1 |
|---|---|
| Location | 2231-2488 |
| Gene Name | C4 |
| Protein Name | C4 |
| Coding Region | ATGGGTCATTGCATCTCCATGTTCTCATCCAGTTCAAGGGGAAAGCAGAGTTCAAAAACCCACGACATTTCGACCTACATCATCCACATAACTCCTCCCAATTCCATCCAAATTTCCAGGCAGCTAAGTCCTCCTCGGATGTCAAGTCATACATCGAGAAGGACGGAGACTACCTCGACTGGGGTGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGTCAGCAGACTGCTAACGACGCTGCCGCAGAGGCATTAA |
| Protein Sequence | MGHCISMFSSSSRGKQSSKTHDISTYIIHITPPNSIQISRQLSPPRMSSHTSRRTETTSTGVNSRSTADLLEEVSRLLTTLPQRH |
References More References in PubMed
| 1 |
Diversity of Sweepoviruses Infecting Sweet Potato in China. Liu Q, et al. Plant Dis. 2017 Dec;101(12):2098-2103. doi: 10.1094/PDIS-04-17-0524-RE. Epub 2017 Oct 9. PMID: 30677378 |
|---|---|
| 2 |
Ferro CG, et al. Microorganisms. 2021 May 10;9(5):1018. doi: 10.3390/microorganisms9051018. PMID: 34068583 |
| 3 |
Trenado HP, et al. PLoS One. 2011;6(11):e27329. doi: 10.1371/journal.pone.0027329. Epub 2011 Nov 2. PMID: 22073314 |