Bean white chlorosis mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000910695.1 |
| Isolate | Venezuela |
| Release date | 2015/2/22 |
| Submitter | Fiallo-Olive,E., Marquez-Martin,B., Hassan,I., Chirinos,D.T., Geraud-Pouey,F., Navas-Castillo,J., Moriones,E., Chirinos,D. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
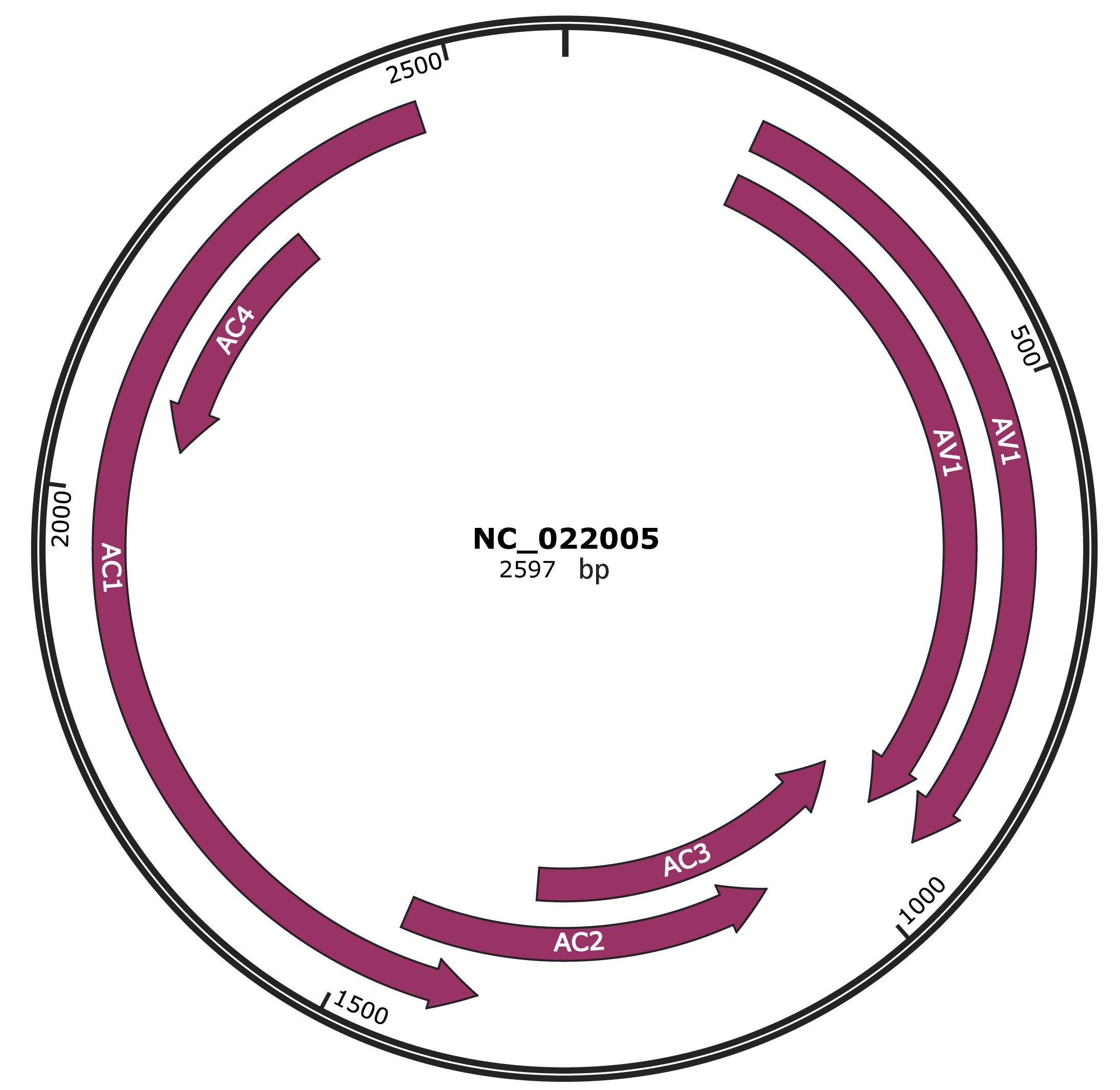
JBrowse
Genome
NC_022005
ACCGGATGGCCGCGCGATTTTTTCTGCCCCTCCGCTTTAATTCGAATTAAAGCGTGCTGCTTTCGTTTCGTCCAATGATATTGCGTCTGACGAGCTTAGATATTTGCAACAACTTGGGCGCTAAGTTGTTGGGTCAAGATTATAAATTAAAGCAGCACGGCCCACTGCCTTTAACTCAAAATGCCTAAGCGCGATCTCCCATGGCGCGCAATGCCTGGAACATCAAAGGTTAGTCGCAATGCTAACTACTCTCCACGTGCAGGTGGTGGCTCGAAATTGAGTAGGGCCTCTGAGTGGGTTAACAGGCCCATGTATATGAAGCCCAGGATTTATCGGACGCTGAGGACTCCAGATGTGCCCAGAGGCTGTGAAGGTCCTTGTAAGGTCCAGTCATATGAACAGCGTCACGATATTTCACATGTCGGGAAGGTCATGTGTATCTCTGATGTCACACGTGGCAATGGCATCACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTTGGTAAGATCTGGATGGATGAGAATATCAAGCTGAAGAACCACACCAACAGCGTTATGTTCTGGCTGGTCAGGGACCGTAGACCGTATGGAACGCCCATGGATTTCGGTCAGGTATTCAACATGTTCGACAACGAGCCCAGCACTGCCACGGTCAAGAACGATCTCCGTGATCGTTATCAAGTTATGCACAAGTTCTATGGTAAGGTGACAGGTGGACAGTATGCAAGTAACGAGCAGGCAATCGTCAAGCGTTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTATGAGAATCACACTGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTTTATGCAACGCTTAAGATTCGAATCTATTTTTATGATTCGATTATGAATTAATAAATTTTGAATTTTATTGAATGATCTTCCACGACATAATTTACATACGATCTGTCTGTTGCGAAACGAACAGCCCTAATTACGTTGTTAATGGAAATAACACCCAATCGATCTAAGTACATATGAACTAAACGCTTAAATCTATTCAAATAAGTCGACCCAGAAGCTGTCAGGGATATCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATCCAATGCTTTCCTGAGGTTGTGGTTGAACCGTATTTGCACGCTGTATATCCTGGTGTTCGTGAAGAGTGGGTCCTCTACCTTGTATAGTTTGAAATAAAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCCGCCTGAGGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGTCCTGTGCAGCCTATGTGGAAGTATATGGAGCAACCGCACTCCAGATCAATGCGGCGTCGTCTGACTGACCTCTTCTTGGCCTCCCTGTGTTTCTTCTTGATAGAGGGGGGAGTCGAGGGTGATGAAGACCGCATTCTTCAGGGTCCAGTTCCTGATGCCTGTGTTTTCCTCTTTGTTGAGGAAATCTTTATAACTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATCCCTCCTTTAATGACAACTGGCTTGCCGTACTTGCAATTTGACTGCCATTTCTTTTGGGCCCAAAAAAGTTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACATCATCAATGACGTTATACTCCACTTCGTCCGAGTACACTCTGGAATTGAAGTCTAGGTGTCCACTAAGATAATTATGTGGGCCTAATGATCGAGCCCACATCGTCTTTCCTGTTCTTGAATCACCTTCGACTATGAGACTTAATGGTCTTTCTGGCCGCGCAGCGGGACTCTTTCCAAAATAATCATCTGCCCATTCTTGCATCTCGTCGGGAACGTTAGTGAAAGAGGAGAGTGGAAACGGAGGAGTCCATGGCTCCGGAGGCTTTTGGAATATTCTGGTTGCGTTAGCAACCAGGTTGTGATGTTGAAGGAAGAAATGTTGCGGTTGTTCTTCCTTTATTATTTGCAGAGCTGCCTCTGCTGATCCTGCATTTAACGCTTTAGCATATGTGTCGTTAGCAGATTGCTGACCTCCTCTAGCAGATCTGCCGTCGATCTGGAACTGTCCCCATTCAACTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTTATTCGTGCACTGGTATTTTCCTTCGAACTGGATGAGCACATGTAGATGAGGTTGCCCATCTTCGTGAAATTCTCTGCAGATCTTGATGAATTTCTTGTTAACAGGAGTTGCTAGGTTTTGTATTTGGGAAAGTGCCTCTTCTTTGGTAAGAGAGCACTGGGGATAAGTGAGGAAATAGTTCTTGGATTGAACTCTAAATTTCTTAGGCGGTGGCATTTTAGTAATAAGAAGGGGTACTCCAGTTGAGCTCCCTCAAAACTTGCTCATGCAATTGGAGTATTGGAGTACTATATATACTATAACTCTCAATCTCGGTTTTGGAACACGTGGCGGCCATCCGTATAATATT
Gene Information
| NCBI Accession | YP_008400122.1 |
|---|---|
| Location | 181-936 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATCTCCCATGGCGCGCAATGCCTGGAACATCAAAGGTTAGTCGCAATGCTAACTACTCTCCACGTGCAGGTGGTGGCTCGAAATTGAGTAGGGCCTCTGAGTGGGTTAACAGGCCCATGTATATGAAGCCCAGGATTTATCGGACGCTGAGGACTCCAGATGTGCCCAGAGGCTGTGAAGGTCCTTGTAAGGTCCAGTCATATGAACAGCGTCACGATATTTCACATGTCGGGAAGGTCATGTGTATCTCTGATGTCACACGTGGCAATGGCATCACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTTGGTAAGATCTGGATGGATGAGAATATCAAGCTGAAGAACCACACCAACAGCGTTATGTTCTGGCTGGTCAGGGACCGTAGACCGTATGGAACGCCCATGGATTTCGGTCAGGTATTCAACATGTTCGACAACGAGCCCAGCACTGCCACGGTCAAGAACGATCTCCGTGATCGTTATCAAGTTATGCACAAGTTCTATGGTAAGGTGACAGGTGGACAGTATGCAAGTAACGAGCAGGCAATCGTCAAGCGTTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTATGAGAATCACACTGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTTTATGCAACGCTTAAGATTCGAATCTATTTTTATGATTCGATTATGAATTAA |
| Protein Sequence | MPKRDLPWRAMPGTSKVSRNANYSPRAGGGSKLSRASEWVNRPMYMKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_008400123.1 |
|---|---|
| Location | 933-1331 |
| Gene Name | AC3 |
| Protein Name | replication enhancement protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTTTATTTCAAACTATACAAGGTAGAGGACCCACTCTTCACGAACACCAGGATATACAGCGTGCAAATACGGTTCAACCACAACCTCAGGAAAGCATTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGATATCCCTGACAGCTTCTGGGTCGACTTATTTGAATAGATTTAAGCGTTTAGTTCATATGTACTTAGATCGATTGGGTGTTATTTCCATTAACAACGTAATTAGGGCTGTTCGTTTCGCAACAGACAGATCGTATGTAAATTATGTCGTGGAAGATCATTCAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGELITAPQAENGVYIWEIENPLYFKLYKVEDPLFTNTRIYSVQIRFNHNLRKALDLHKAYLNFQVWTISLTASGSTYLNRFKRLVHMYLDRLGVISINNVIRAVRFATDRSYVNYVVEDHSIKFKIY |
| NCBI Accession | YP_008400124.1 |
|---|---|
| Location | 1078-1467 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCGGTCTTCATCACCCTCGACTCCCCCCTCTATCAAGAAGAAACACAGGGAGGCCAAGAAGAGGTCAGTCAGACGACGCCGCATTGATCTGGAGTGCGGTTGCTCCATATACTTCCACATAGGCTGCACAGGACATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTTTATTTCAAACTATACAAGGTAGAGGACCCACTCTTCACGAACACCAGGATATACAGCGTGCAAATACGGTTCAACCACAACCTCAGGAAAGCATTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGATATCCCTGACAGCTTCTGGGTCGACTTATTTGAATAG |
| Protein Sequence | MRSSSPSTPPSIKKKHREAKKRSVRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPLFQTIQGRGPTLHEHQDIQRANTVQPQPQESIGSPQSLPELPSLDDIPDSFWVDLFE |
| NCBI Accession | YP_008400125.1 |
|---|---|
| Location | 1379-2464 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCACCGCCTAAGAAATTTAGAGTTCAATCCAAGAACTATTTCCTCACTTATCCCCAGTGCTCTCTTACCAAAGAAGAGGCACTTTCCCAAATACAAAACCTAGCAACTCCTGTTAACAAGAAATTCATCAAGATCTGCAGAGAATTTCACGAAGATGGGCAACCTCATCTACATGTGCTCATCCAGTTCGAAGGAAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACAGTTGAATGGGGACAGTTCCAGATCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCTAACGACACATATGCTAAAGCGTTAAATGCAGGATCAGCAGAGGCAGCTCTGCAAATAATAAAGGAAGAACAACCGCAACATTTCTTCCTTCAACATCACAACCTGGTTGCTAACGCAACCAGAATATTCCAAAAGCCTCCGGAGCCATGGACTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCCGACGAGATGCAAGAATGGGCAGATGATTATTTTGGAAAGAGTCCCGCTGCGCGGCCAGAAAGACCATTAAGTCTCATAGTCGAAGGTGATTCAAGAACAGGAAAGACGATGTGGGCTCGATCATTAGGCCCACATAATTATCTTAGTGGACACCTAGACTTCAATTCCAGAGTGTACTCGGACGAAGTGGAGTATAACGTCATTGATGATGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAACTTTTTTGGGCCCAAAAGAAATGGCAGTCAAATTGCAAGTACGGCAAGCCAGTTGTCATTAAAGGAGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGTTATAAAGATTTCCTCAACAAAGAGGAAAACACAGGCATCAGGAACTGGACCCTGAAGAATGCGGTCTTCATCACCCTCGACTCCCCCCTCTATCAAGAAGAAACACAGGGAGGCCAAGAAGAGGTCAGTCAGACGACGCCGCATTGA |
| Protein Sequence | MPPPKKFRVQSKNYFLTYPQCSLTKEEALSQIQNLATPVNKKFIKICREFHEDGQPHLHVLIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGQFQIDGRSARGGQQSANDTYAKALNAGSAEAALQIIKEEQPQHFFLQHHNLVANATRIFQKPPEPWTPPFPLSSFTNVPDEMQEWADDYFGKSPAARPERPLSLIVEGDSRTGKTMWARSLGPHNYLSGHLDFNSRVYSDEVEYNVIDDVAPHYLKLKHWKELFWAQKKWQSNCKYGKPVVIKGGIPSIVLCNPGEGASYKDFLNKEENTGIRNWTLKNAVFITLDSPLYQEETQGGQEEVSQTTPH |
| NCBI Accession | YP_008400126.1 |
|---|---|
| Location | 2050-2307 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGCAACCTCATCTACATGTGCTCATCCAGTTCGAAGGAAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACAGTTGAATGGGGACAGTTCCAGATCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCTAACGACACATATGCTAAAGCGTTAA |
| Protein Sequence | MGNLIYMCSSSSKENTSARITDSSIWSPQPGQHISIRTYRELNQAPTSSPTSTRTEIQLNGDSSRSTADLLEEVSNLLTTHMLKR |
References More References in PubMed
| 1 |
Complete genome sequences of two novel begomoviruses infecting common bean in Venezuela. Fiallo-Olivé E, et al. Arch Virol. 2013 Mar;158(3):723-7. doi: 10.1007/s00705-012-1545-y. Epub 2012 Nov 21. PMID: 23178970 |
|---|---|
| 2 |
Al-Shahwan IM, et al. Saudi J Biol Sci. 2017 Sep;24(6):1336-1343. doi: 10.1016/j.sjbs.2016.02.022. Epub 2016 Mar 2. PMID: 28855829 |
| 3 |
First Report of Alfalfa mosaic virus in Kura Clover (Trifolium amgibuum) in Wisconsin. Piñeyro MJ, et al. Plant Dis. 2002 Jun;86(6):695. doi: 10.1094/PDIS.2002.86.6.695A. PMID: 30823257 |