Sunn hemp leaf distortion virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000884115.1 |
| Isolate |
India: Barrackpore |
| Release date |
2015/2/22 |
| Submitter |
Das,A., Ghosh,R., Paul,S., Das,S., Palit,P., Acharyya,S., Ghosh,S.K., Roy,A. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
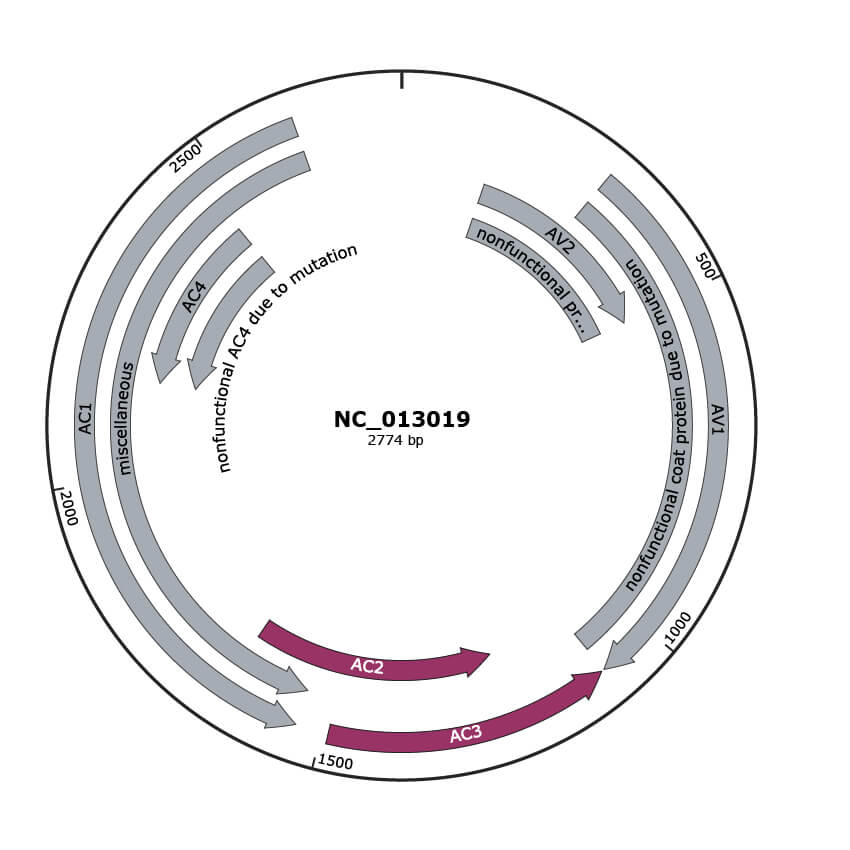
JBrowse
Genome
ACCGGATGGCCGCGCAAATTTTTAAAGTGGTCCCCCCCACTAACTCATGTCGCGTAACACGTGGACGAATGAAATGAGCTCCTCGTGGCTTAATTATTTTGTGGTCCCCTATTTAAACTTCCGCAGCAAGTAGTGCATTCCGCACTATGTGGGGATCCATTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTACATGTCTGTTAGCAGTTATATATCTCCAGTTAGTAGAAAAGACTTATTCTCCTCACACATTAGGGCACGATTTAATTTGGGATTTAATTTCAGTAATTACGGCAAGAAATTATGTCGAAGCGACCAGCAGATATATTCATTTCCACGCCCGCTTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCCCATATGTGTGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAAAGCATGGGCGAACAGGCCCACGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTCCTAGGAGGATGTGAAGGCCCATGTAAGGTCCAGTCTTTTGAGTCCAGACATGATATTCAGCATATAGGTAAAGTCATGTGTGTCAGTGATGTTACGCGTGGAACTGGGCTGACCCATCGAGTGGGTAAAAGGTTTTGTGTTAAATCTGTTTATGTCTTGGGTAAGATCTGGATGGACGAAAATATTAAGACCAAAAATCACACGAATAGTGTGATGTTTTTTTTAGTTAGGGATCGTAGACCTGTGGATAAACCTCAAGATTTTGGAGAGGTTTTTAACATGTTTGATAATGAGCCCAGTACGGCTACTGTGAAGAATGTTCATCGTGATAGGTATCAAGTTCTTCGGAAGTGGCATGCAACTGTGACTGGTGGACAATATGCGTCAAAGGAACAAGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATTTAATAATTATGTTGTTTATAACCAGCAAGAAGCTGGCAAGTATGAGAATCATTCTGAGAATGCGTTATTGTTGTATATGGCATGTACTCATGCCTCTAACCCAGTGTATGCTACTTTGGAGATACGGATCTATTTCTATGATTCCGTAACAAATTAATAAATATTAAATGTTATTGAATAAGATTGGTCTACATATACAATATGTTGTAATACATTCCATAATACATGATCAACTGCACGATTTACATTATTAATACTGATAATTCCTAAATTATCTAAATATTTAAATACTTCAGTCTTTAAGACCCAAAAGAAACGACCAGTCTGAGGCTGTGAAGACATCCAGATTCGGTAGAATAGGAAACAGTTGTGAATCCCCAGTGCTTTCCTTAGGTTGTGATTGAACTGTATTCGGACGGTTCTTGTATCTTGGTTGATGAGAAATGGACGGTTCTGGTGCTCGAGTATCTTGAAATAAAGGGGATTTTGAATCTCCCAGATAAACACGCCAATCTCTGCTTGAGCTGCAGTGATGAGTTCCCCGGTGCGTGAATCCATGATCGTGGACAGGCGAGTGGTATGAAATATGAATATCCACAAGGGAGTCAAACACGTCGACGTCTGGTCCCCTTCTTGGGTAGCCTGTGCTGCACTTTGATTGGTACCTGAGTAGAGTGGGCCTTCGAGGGTGACGAAGATCGCATTCTGTAAAGCCCATTTTTTAAGTGCGCTATTTTTCTCTTCATCCAAGAACTCTTTATAGCTTGAGTTGGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAACTGGCTTTCCGTATTTCGTGTTGCTTTGCCAGTCCCTTTGGGCCCCGATGAATTCCTTAAAGTGCTTGAAATAATCCGGATCAACGTCATCAATGACGTTGTACCACGCATCATTATTGTAGACCTTAGGACTAAGGTCAAAGTGACCACACAGGTAATTATGTGGACCCAAAGACCTAGCCCACGTGGTCTTCCCCGTTCTACTATCACCCTCTGTGACAATACGCTTGGGTCTGAAAGTCCGCGCAGCGGCACACACCACTTTCTCAGCAGCCCATTCTTCAAGTTCCTCTGGAACTTGGTCAAAAGAAGAAGAAGAAAAAGGAGAAATATATTCCTCGATAGGAGGAGTAAATATTCTATCAAAATTAGCAGATAGATTATGAAATTGTAATACACAATCTTTAGGTGCTGATTCCTGCAAGACTGTAAGAGCCTCTGACGTACTGCCTGCGATAAGTGCTGCGGCGTAAGCGGCATTGGCTGTCTGTTGACCCCCTCTTGCAGATCTTCCATCGATCTGAAACTCTCCCCCAGTCGAGGGTGTCTCCCGTCCTTCTCCAGGTAGGACTTGACGTCCGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGATCTGGTTGGGGATACCAGGTCGAAGAATCTGTTATTCTGGCACTTGTATTTCCCCTCGAACTGGATGAGCACGTGAAGATGAGGTTCCCCATTTTCAAGAAGCTCTCTGCAGATCTTGATGTATTTTTTATTTGTTGGGGTTTGTAGGTTTTGAAATTGGGAAAGTGCTTCCTCTTTAGTAAGAGAGCATTTCGGATAAGTGAGAAAATAATTTTTAGAGTTAATGAGGAAACGCTTGGGAGGCATGTTGACTAAAATAGAGGACCCGATTGACCGCTCTTGCAACTCTCCCCTGTATATTGGGTCTCAATATATAGTGAGACCCAAATGGCATATTCGTAATTTGGTAAAGGAATTCAAAATTTACACGCTCCAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_003084141.1
|
|
Location
|
1086-1490 |
|
Gene Name
|
AC3 |
|
Protein Name
|
transcription enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGCAGCTCAAGCAGAGATTGGCGTGTTTATCTGGGAGATTCAAAATCCCCTTTATTTCAAGATACTCGAGCACCAGAACCGTCCATTTCTCATCAACCAAGATACAAGAACCGTCCGAATACAGTTCAATCACAACCTAAGGAAAGCACTGGGGATTCACAACTGTTTCCTATTCTACCGAATCTGGATGTCTTCACAGCCTCAGACTGGTCGTTTCTTTTGGGTCTTAAAGACTGAAGTATTTAAATATTTAGATAATTTAGGAATTATCAGTATTAATAATGTAAATCGTGCAGTTGATCATGTATTATGGAATGTATTACAACATATTGTATATGTAGACCAATCTTATTCAATAACATTTAATATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAEIGVFIWEIQNPLYFKILEHQNRPFLINQDTRTVRIQFNHNLRKALGIHNCFLFYRIWMSSQPQTGRFFWVLKTEVFKYLDNLGIISINNVNRAVDHVLWNVLQHIVYVDQSYSITFNIY |
|
NCBI Accession
|
YP_003084142.1
|
|
Location
|
1225-1650 |
|
Gene Name
|
AC2 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGGCTTTACAGAATGCGATCTTCGTCACCCTCGAAGGCCCACTCTACTCAGGTACCAATCAAAGTGCAGCACAGGCTACCCAAGAAGGGGACCAGACGTCGACGTGTTTGACTCCCTTGTGGATATTCATATTTCATACCACTCGCCTGTCCACGATCATGGATTCACGCACCGGGGAACTCATCACTGCAGCTCAAGCAGAGATTGGCGTGTTTATCTGGGAGATTCAAAATCCCCTTTATTTCAAGATACTCGAGCACCAGAACCGTCCATTTCTCATCAACCAAGATACAAGAACCGTCCGAATACAGTTCAATCACAACCTAAGGAAAGCACTGGGGATTCACAACTGTTTCCTATTCTACCGAATCTGGATGTCTTCACAGCCTCAGACTGGTCGTTTCTTTTGGGTCTTAAAGACTGA |
|
Protein Sequence
|
MGFTECDLRHPRRPTLLRYQSKCSTGYPRRGPDVDVFDSLVDIHISYHSPVHDHGFTHRGTHHCSSSRDWRVYLGDSKSPLFQDTRAPEPSISHQPRYKNRPNTVQSQPKESTGDSQLFPILPNLDVFTASDWSFLLGLKD |